溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
高可用與存儲的結合
之前我們做好了fence,今天將高可用和存儲結合起來。
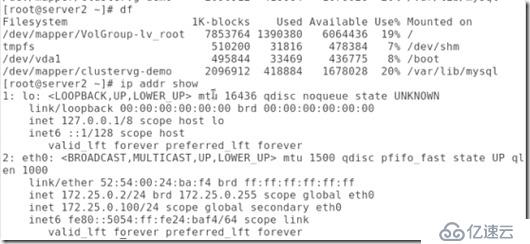
試驗主機:172.25.0.2 172.25.0.3 172.25.0.251(做數據輸出端)
第一部分:
##在做實驗之前,需要將luci打開,并且查看集群狀態:
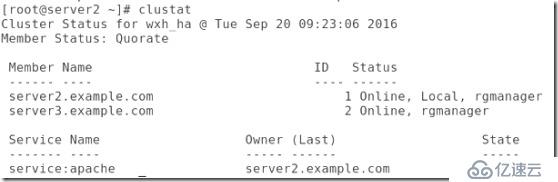
##將集群的apach關閉:
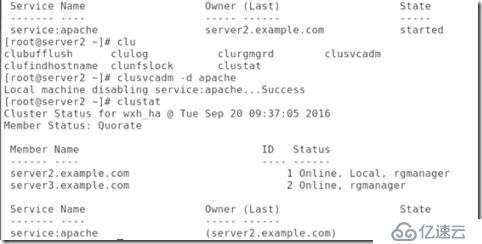
##查看ip發現沒有vip:
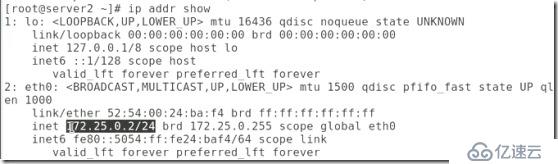
##檢測server2的apache(也就是看他開啟再關閉是否正常):


##確定集群的apache是關閉的:
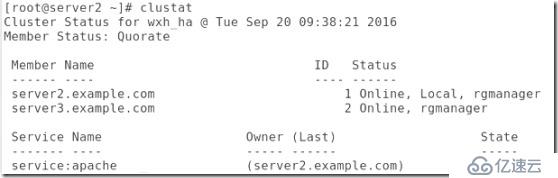
##以上做法也不知道意義何在,且往下看
##增加存儲,存貯在哪都可以,這里是將instructor這臺主機的/dev/vol0/demo邏輯卷作為存貯空間,因為之前做實驗這里邊有數據,所以我們將它清空:
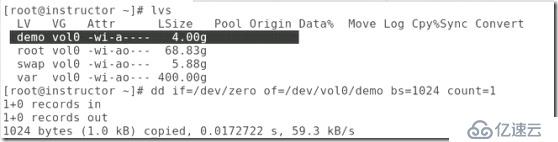
##這里是用scsi做為存貯類型用到iscsi協議,所以先查詢需要的軟件,可以用rpm -qa |grep ##也可以用yum list ##

##在數據輸出端(也就是做存儲的機子)安裝scsi,對應服務為tgtd,在集群節點中安裝iscsi協議,服務名稱是iscsi:

##編輯配置文件:

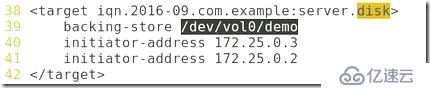
##開啟服務:

##查看進程,只能有兩個tgtd,這是正確的,這就需要每次在編輯配置文件時需要將tgtd關閉,這也是經常出的問題。
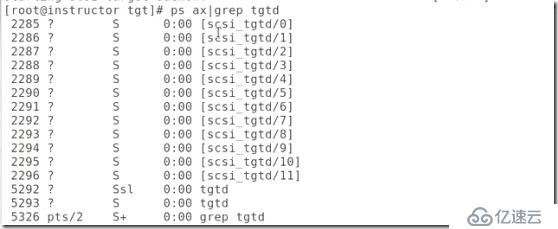
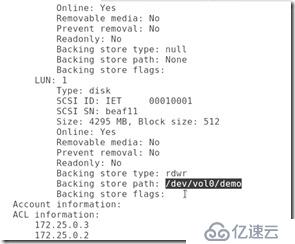
##查看配置信息:

##在兩個節點上安裝iscsi:


##默認iscsi是開機自啟的:

##發現目標(target),后面的ip就是做存儲的主機ip。

##登入節點:

#這個時候用fdisk -l查看會發現多了一塊磁盤:
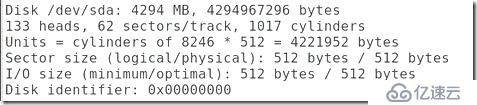
##從節點上卸載iscsi:

#再用fdisk -l就找不到那塊共享的磁盤
#卸載后就可以將這個節點上的緩存刪除,否則每次開啟iscsi都會自動登陸這個磁盤:

#再次發現和登陸:

#創建分區,類型為8e邏輯卷:

#查詢,sda1的類型是8e:

#查看clvmd服務,這是對集群中邏輯卷管理的服務,確定開啟:
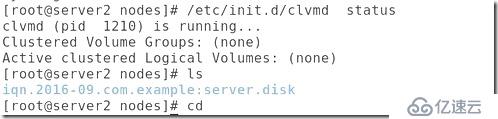
##在節點2創建邏輯卷,

##會發現現在節點3同步過來了,說明clvmd起作用了,他就是來管理邏輯卷的:

##當然了,節點2也會同步過來的:

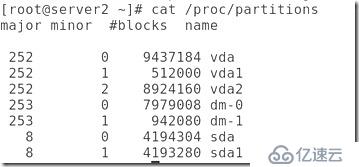
##查看怎么創建集群vg:
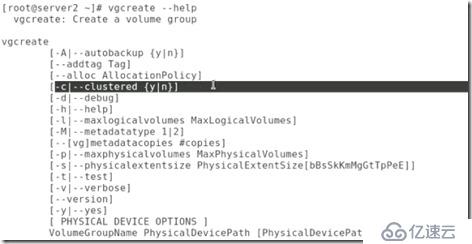
##將剛剛創建的pv用作集群vg:

##查看我們剛剛創建的vg:

##用clustervg創建lv,名字叫demo:

##當然所做的一切都會在節點3中有相應體現。
##然后就是將集群邏輯卷格式化:
##然后就是在節點3中進行掛載到/mnt,在/mnt中寫下首頁,內容為www.westos.org。再卸載,當然首頁將保存到磁盤中,如果換到http發布目錄中將可以通過web訪問。

##然后將邏輯卷(存儲)添加到資源中:

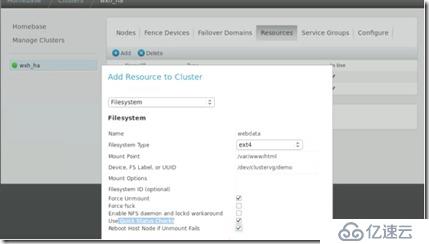
##有時會因為超時的原因在你保存之后會退出lusi,這時只需要重新登錄,再次填寫相關內容就好。
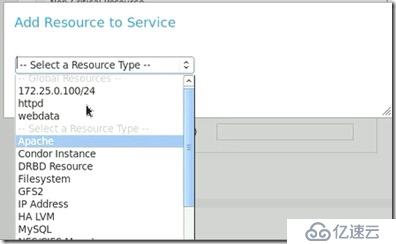
##有了資源我們需要將它和http聯系起來,這就要在服務選項中的http下面增加資源,選擇webdata:
##這時候會多一個文件系統:
##我們這里是將http服務于存儲整合,所以需要http服務,如果沒有的話,當然需要自己先增加一個資源,然后再添加到papache中。
##查看現在的集群狀態,并將集群的apache打開:
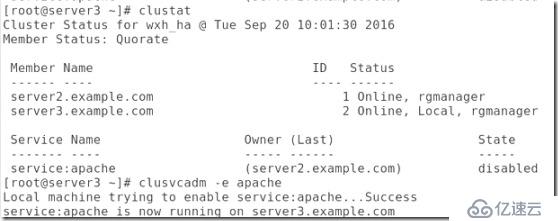
##當然也可以在圖形中打開:
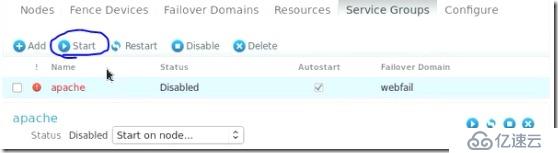
##現在是apache打開了,Apache下面包括資源vip,存儲,http服務,當然這三者的打開順序也應該是這樣,顯示vip,然后指存儲,最后才是http服務,這也是為啥在我們往Apache中添加資源時先將之前的http服務停掉,在添加完存儲之后再將http服務加上:
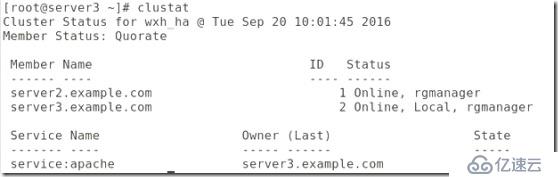
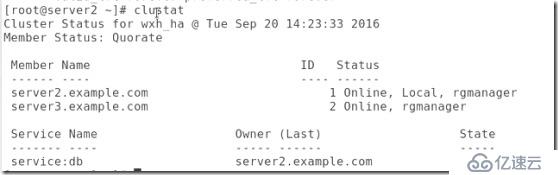
##查看集群是否管理了資源:
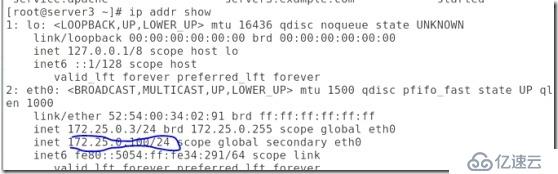
#vip添加上了。
##http也打開了,磁盤也實現了掛載:
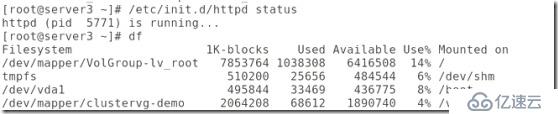
##網頁也能夠訪問了:

##現在將Apache手動交給連一個節點,當參數忘了,可以用clusvcadm --help查看相關參數:

##使用-r -m 可以實現節點的轉換:

##轉換完成后節點二就會將vip添加,實現自動掛載,并且開啟http服務,相反的節點3上會將相同的服務關閉,也就是說高可用集群同時只有一個在工作,解決的是單點故障。

第二部分:
##displayvg clustervg:

##給集群邏輯卷擴展分區這里加的511就相當于加入2G這樣更精確,現在邏輯卷就會有4G大小:

##擴展完成后,發現掛載的磁盤實際并沒有刷新,這就需要刷新一下:
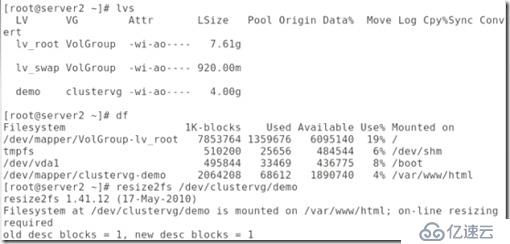
##df 默認顯示的是塊的大小,df -h顯示的是真實大小:
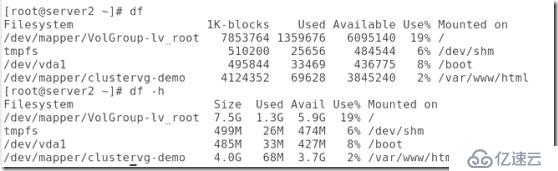
##從集群中刪除Apache:

##將節點2邏輯卷掛載在/mnt,并復制passwd目錄進去:
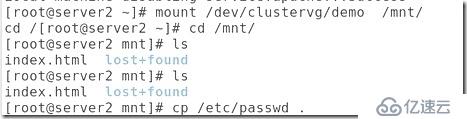
##在節點3上掛載,并且追加westos進去,但是,在節點3中只能看到自己的追加,并不能看到之前的文件:

##然后將兩邊都卸載。再掛載,在節點2中卻只能看到在節點3中追加的westos,并不能看到之前的文件:

##這說明集群同一時間只能有一個節點接管存儲,這是文件呢系統的原因,所以我們就用到了gfs2文件系統,也叫做可擴展的分布式文件系統(也叫做全局文件系統),可以實現多個節點同時掛載在同一文件系統,保證數據的同步性,說到同步我們需要知道,在RHCS套件中是css在處理文件系統的同步:
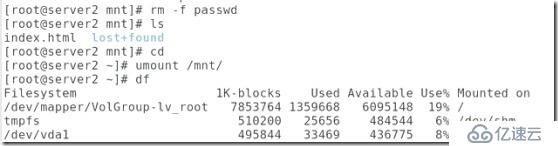
##檢查邏輯卷的文件系統的正確性。
fsck(file system check)用來檢查和維護不一致的文件系統。若系統掉電或磁盤發生問題,可利用fsck命令對文件系統進行檢查。

##將邏輯卷縮小,當然也可以不做這一步:
resize2fs命令被用來增大或者收縮未加載的“ext2/ext3”文件系統的大小。如果文件系統是處于mount狀態下,那么它只能做到擴容,前提條件是內核支持在線resize。,linux kernel 2.6支持在mount狀態下擴容但僅限于ext3文件系統。

##在查看大小,確實縮小了:

##當然這樣并沒有縮小邏輯卷還是用另一種方法來縮小吧:

##再刪除邏輯卷,再創建邏輯卷:

##當然這些都是說明集群中邏輯卷的擴展,縮小,新建,這一步可以不做的。
##現在我們就擁有了一個2G的新的邏輯卷:

##補充一下裸設備與文件系統的區別:
裸設備到文件系統,格式化的才叫文件系統。
自己對裸設備的理解,。沒有經過格式化的磁盤分區,操作系統不對其進行管理,而是應用程序直接管理,所以I/O效率更高,正因為這樣對于讀寫頻繁的數據庫等應用程序可以用裸設備,這樣可以極大的提高性能。
文件系統是對一個存儲設備上的數據和元數據進行組織的機制。文件系統的工作就是維護文件在磁盤上的存放,記錄文件占用了哪幾個扇區。另外扇區的使用情況也要記錄在磁盤上。文件系統在讀寫文件時,首先找到文件使用的扇區號,然后從中讀出文件內容。如果要寫文件,文件系統首先找到可用扇區,進行數據追加。同時更新文件扇區使用信息。在掛載后就可以將掛載點當做一個新的文件系統。
fsck是如何工作的:通常情況下,當 Linux 系統啟動時,首先運行fsck,由它掃描/etc/fstab 文件中列出的所有本地文件系統。fsck 的工作就是確保要裝載的文件系統的元數據是處于可使用的狀態。當系統關閉時,fsck又把所有的緩沖區數據轉送到磁盤,并確保文件系統被徹底卸載,以保證系統下次啟動時能夠正常使用。
##得到最恰當的塊大小:

##查看幫助:
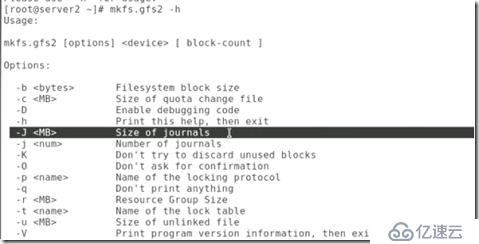
##然后就是對邏輯卷的再次格式化:
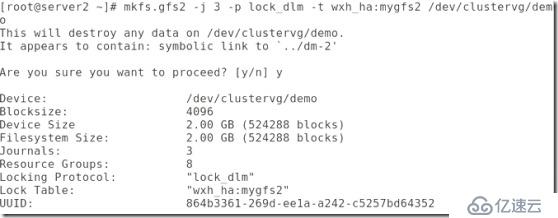
##然后就是兩個節點都掛載:


##然后在節點2的中寫一個首頁:
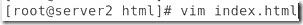

##這會同步到節點三中:

##當然在節點3的首頁中增加一行,也會在節點2中同步:

##要想實現文件系統的永久掛載,查看UUID,然后將掛載信息添加到/etc/fstable:



##當然在節點3中也要做相同的掛載

##把service group中之前的那個ext3文件系統刪除,再在資源中增加一個新的文件系統:

##上面這一步是不是可以改為只是把service group中的文件系統刪除,而不增加另一個文件系統,這樣在重新開啟Apache是否會自動添加???
##查看iscsi狀態,是開啟的.
##查看系統中的可掛載設備和pv:
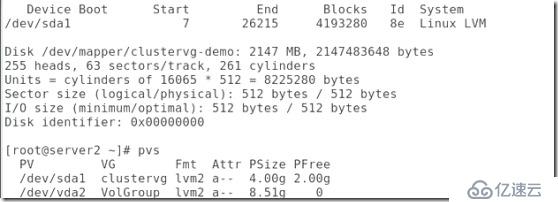
##當然,做完,最好能先卸載掉,查看是否 能夠自動掛載:

##現在開啟Apache:


##就可以訪問了:

第三部分 將Apache換成數據庫:
##首先將apache刪除:
##當然也可以用命令刪除,然后安裝MySQL:

##進入MySQl目錄,將MySQL打開:

##當然節點3上也要安裝:

##檢查存儲,因為我們要將資源交給集群管理,所以我們要將存儲資源關閉:


##并且將邏輯卷掛載到MySQL的發布目錄中:

##然后將邏輯卷掛載到/mnt上,并且將MySQL發布目錄中的所有數據移動到/mnt下,然后從/mnt下面卸載:

##這樣MySQL中就沒有文件,文件被保存到邏輯卷中,然后再用mount -a,就實現邏輯卷到數據庫默認目錄的掛載:

##這樣數據庫的配置文件就有回來了。
##將數據庫的apache的首頁文件刪除,并打開數據庫:

##當然最后還是要關閉的將它交給集群,我們在這里的一番折騰只是檢測存儲與MySQL都沒有錯誤,可以正常使用:

##節點3中也要做相同的工作:




##為數據庫增加資源,還是添加一個腳本,這里腳本是只需要輸入名字,和啟動的路徑這樣就可以讓集群來管理開關了:
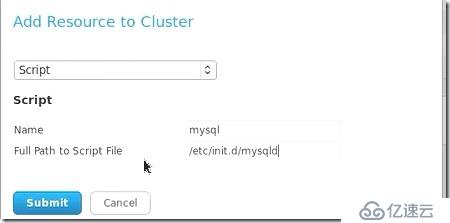
##查看集群,發現并沒有將數據庫加進來:

##這就需要將資源加進服務:

##Run exclusive:意思是這個服務獨占集群,當然不能這樣了。然后就是將我們的資源vip和數據庫加進來:
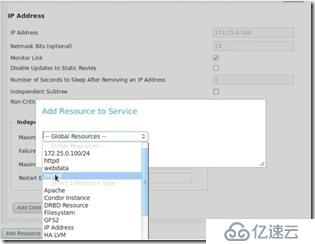
##在查看集群,發現就將數據庫服務加進來了:
##現在就可以登錄數據庫了:

##將數據庫服務轉交給節點3:

##現在邏輯卷掛載到了節點3,vip也轉移到了節點3:


##在節點三登錄數據庫:
##刪除集群數據庫:

##在兩個節點中都將存儲卸載:

##之前所做沒有將存儲加進去:
邏輯卷的掛載是我們手動掛載的,現在將gfs資源加進MySQL服務就可以實現自動掛載了:
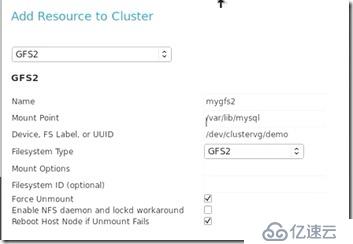
##然后在DB服務中將之前增加的數據庫先刪了,再添加存儲和數據庫,因為集群在啟動服務中的資源時,是按照資源的順序的,而在數據庫之前必須要有存儲。
##現在DB服務是關閉的,我們將只需將DB服務打開,就可以自動調配其他的資源,包括資源的開啟,當一個存儲有問題會自動跳到另一臺機子上等:

##已經實現了存儲的自動掛載:

##將DB服務轉交給節點2:

##存儲和vip都轉移到了節點2:
##至此,我們就完成了數據庫的服務的高可用,就解決了數據庫的單點故障。
第四部分:圖形修改對應進程:
##將DB服務關閉并且刪除,將gfs2資源刪除:

第五部分:不用圖形的高可用集群(不用luci的高可用集群)pacemake。
##在rhcl7之后就沒有了luci,就不能借助圖形來管理集群了,下面就來介紹費圖形界面的高可用集群管理。
##首先將之前在rhcl6中做的都給刪除,包括將節點從集群中脫離并刪除:

##還有cman,rgmanager

##還有modclusterd
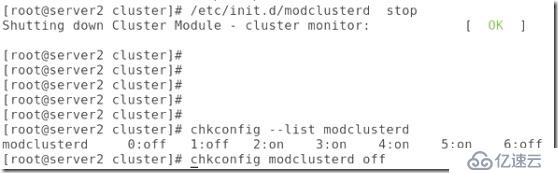
##還有iscsi,關閉,啟動項也關閉:

##在安裝scsi的機子上,檢查iscsi的情況:

##將scsi關閉:

##兩個節點安裝pacemake:


##若用新的虛擬機,需要安裝heartbeat、drbd、mysql-server、httpd
##安裝完pacemake后將會有一個控制心跳的配置文件目錄:

##編輯配置文件:
#原始的例子內容:
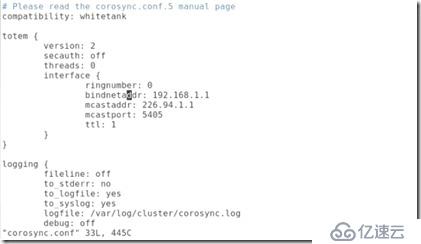
##修改后的配置文件其實就修改了兩處,一個是將綁定的網絡地址改為集群的網絡地址,在最后一行增加服務:
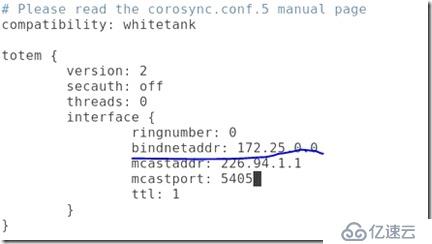
............................................

##上述修改的目的:


#當最后的ver設置為1的時候,插件打不開pacemake的守護進程,這里我們還是設置為0,表示可以打開pacemaker的守護進程,通過組件調動而不是腳本。
Plugin:插件
Daemons:是守護進程的意思,代表在后臺運行而沒有終端或者運行的shell與其結合的進程。
##可以到官網下載關于pacmake的官方文檔:

##將修改后的配置文件復制到節點3.

##開啟心跳服務:


##這里的報錯是因為stonish的原因,默認stonish是開啟的這樣verify時會報錯,并且也不能commit,所以在配置之前需要將stonish關閉:

##然后需要安裝連個包,最好先安裝pssh在安裝crm,,因為第二個是第一個的依賴性,當然也可以一起安裝,但是需要安裝兩遍:


##然后將兩個包拷貝給節點3,安裝:

##然后就可以用crm服務了:
因為之前coroysnc的原因這里節點指直接加進去的,如果沒有加進去可以用edit加進去,也可以重啟coroysnc,這樣就加進去了。

##然后切換到資源管理模塊:
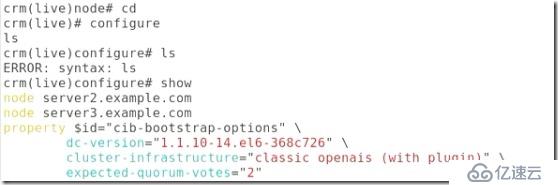
##將stonish關閉:

##這樣檢測語法就不會有錯了:

##不管在哪邊增加策略,兩邊都會同步的:
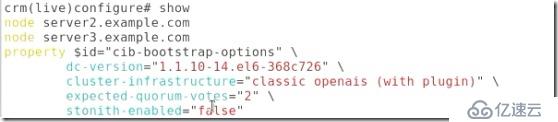
##定義資源:
例子:
crm(live)configure# primitive webvip ocf:heartbeat:IPaddr params ip=172.16.12.100 op monitor interval=30s timeout=20s on-fail=restart
//定義一個主資源名稱為webvip,資源代理類別為ocf:heartbeat,資源代理為IPaddr。params:指定定義的參數 ,op代表動作,monitor設置一個監控,每30s檢測一次,超時時間為20s,一旦故障就重啟
#增加一個vip資源:

##也可以用edit編輯配置文件:

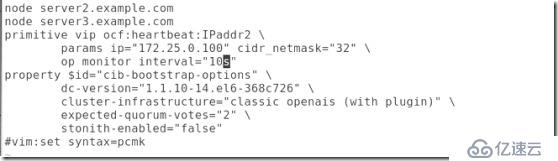
##在0.251這臺機子上是可以ping通增加的資源的:

##對參數的解釋:
crm_verify -LV 檢測配置信息
crm_mon 監控主機狀態
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





