溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章給大家分享的是有關ThinkPHP數據庫操作之存儲過程、數據集、分布式數據庫的示例分析的內容。小編覺得挺實用的,因此分享給大家做個參考,一起跟隨小編過來看看吧。
存儲過程
5.0支持存儲過程,如果我們定義了一個數據庫存儲過程 sp_query ,可以使用下面的方式調用:
$result = Db::query('call sp_query(8)');返回的是一個二維數組,也可以使用參數綁定,例如:
$result = Db::query('call sp_query(?)',[8]);
// 或者命名綁定$result = Db::query('call sp_query(:id)',['id'=>8]);數據集
數據庫的查詢結果也就是數據集,默認的配置下,數據集的類型是一個二維數組,我們可以配置成數據集類,就可以支持對數據集更多的對象化操作,需要使用數據集類功能,可以配置數據庫的resultset_type 參數如下:
return [ // 數據庫類型 'type' => 'mysql', // 數據庫連接DSN配置 'dsn' => '', // 服務器地址 'hostname' => '127.0.0.1', // 數據庫名 'database' => 'thinkphp', // 數據庫用戶名 'username' => 'root', // 數據庫密碼 'password' => '', // 數據庫連接端口 'hostport' => '', // 數據庫連接參數 'params' => [], // 數據庫編碼默認采用utf8 'charset' => 'utf8', // 數據庫表前綴 'prefix' => 'think_', // 數據集返回類型 'resultset_type' => 'collection',];
返回的數據集對象是 think\Collection ,提供了和數組無差別用法,并且另外封裝了一些額外的方法。可以直接使用數組的方式操作數據集對象,例如:
// 獲取數據集
$users = Db::name('user')->select();
// 直接操作第一個元素
$item = $users[0];
// 獲取數據集記錄數
$count = count($users);
// 遍歷數據集
foreach($users as $user){ echo $user['name']; echo $user['id'];
}需要注意的是,如果要判斷數據集是否為空,不能直接使用 empty 判斷,而必須使用數據集對象的isEmpty 方法判斷,例如:
$users = Db::name('user')->select();if($users->isEmpty()){ echo '數據集為空';
}Collection 類包含了下列主要方法:
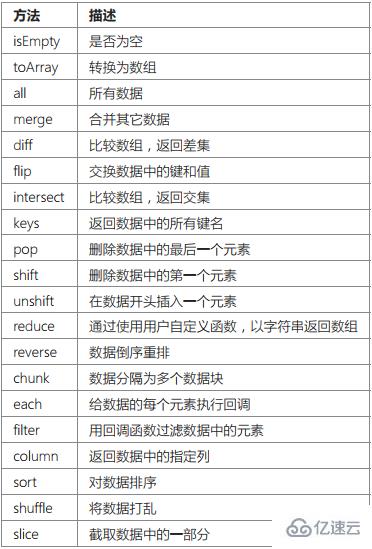
如果只是個別數據的查詢需要返回數據集對象,則可以使用
Db::name('user') ->fetchClass('\think\Collection') ->select();分布式數據庫
ThinkPHP內置了分布式數據庫的支持,包括主從式數據庫的讀寫分離,但是分布式數據庫必須是相同的數據庫類型。
配置 database.deploy 為1 可以采用分布式數據庫支持。如果采用分布式數據庫,定義數據庫配置信息的方式如下:
//分布式數據庫配置定義 return [ // 啟用分布式數據庫 'deploy' => 1, // 數據庫類型 'type' => 'mysql', // 服務器地址 'hostname' => '192.168.1.1,192.168.1.2', // 數據庫名 'database' => 'demo', // 數據庫用戶名 'username' => 'root', // 數據庫密碼 'password' => '', // 數據庫連接端口 'hostport' => '',]
連接的數據庫個數取決于 hostname 定義的數量,所以即使是兩個相同的IP也需要重復定義,但是其他的參數如果存在相同的可以不用重復定義,例如:
'hostport'=>'3306,3306'
和
'hostport'=>'3306'
等效。
'username'=>'user1', 'password'=>'pwd1',
和
'username'=>'user1,user1', 'password'=>'pwd1,pwd1',
等效。
還可以設置分布式數據庫的讀寫是否分離,默認的情況下讀寫不分離,也就是每臺服務器都可以進行讀寫操作,對于主從式數據庫而言,需要設置讀寫分離,通過下面的設置就可以:
'rw_separate' => true,
在讀寫分離的情況下,默認第一個數據庫配置是主服務器的配置信息,負責寫入數據,如果設置了 master_num參數,則可以支持多個主服務器寫入。其它的都是從數據庫的配置信息,負責讀取數據,數量不限制。每次連接從服務器并且進行讀取操作的時候,系統會隨機進行在從服務器中選擇。
還可以設置 slave_no 指定某個服務器進行讀操作。
如果從數據庫連接錯誤,會自動切換到主數據庫連接。
調用模型的CURD操作的話,系統會自動判斷當前執行的方法的讀操作還是寫操作,如果你用的是原生SQL,那么需要注意系統的默認規則: 寫操作必須用模型的execute方法,讀操作必須用模型的query方法,否則會發生主從讀寫錯亂的情況。
注意:主從數據庫的數據同步工作不在框架實現,需要數據庫考慮自身的同步或者復制機制。
感謝各位的閱讀!關于“ThinkPHP數據庫操作之存儲過程、數據集、分布式數據庫的示例分析”這篇文章就分享到這里了,希望以上內容可以對大家有一定的幫助,讓大家可以學到更多知識,如果覺得文章不錯,可以把它分享出去讓更多的人看到吧!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





