溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
怎么在MySQL中通過配置雙主避免數據回環沖突?針對這個問題,這篇文章詳細介紹了相對應的分析和解答,希望可以幫助更多想解決這個問題的小伙伴找到更簡單易行的方法。
如果主庫觸發SQL語句:
insert into test_data(name) values(‘aa');
那么Master1生成binlog,推送數據變化到Master2,在Master2上面生成relay log,然后交由sql thread進行變更重放,反之也是類似的流程,整個流程可以這樣描述。
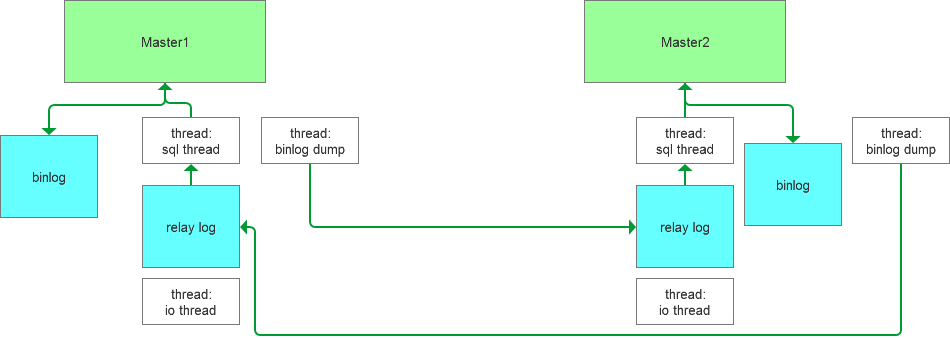
如果Master2消費了relay的數據,然后會產生binlog(log_slave_updates默認開啟),這個時候產生的binlog會繼續推送到Master1消費,然后來來回回推送,一套insert語句就無窮無盡了,顯然這種設計是不合理的,MySQL也肯定不會這么做。
那么問題的關鍵的部分就是:Master2是否推送了先前的binlog到Master1?
a) 如果推送了,Master1是如何過濾,避免后續無限循環
b) 如果沒有推送,Master2是如何過濾的
如果要理解這個過程,我們就需要模擬測試,查看數據流轉過程中的binlog情況,可以參考這個流程。
1) Master1的binlog
2) Master2的 relay log
3) Master的binlog
很快就部署好了一套主從環境,然后添加change master to 就快速搭建好了一套測試的雙主環境。
為了盡可能看到完整的binlog事件信息,我們開啟參數binlog_rows_query_log_events
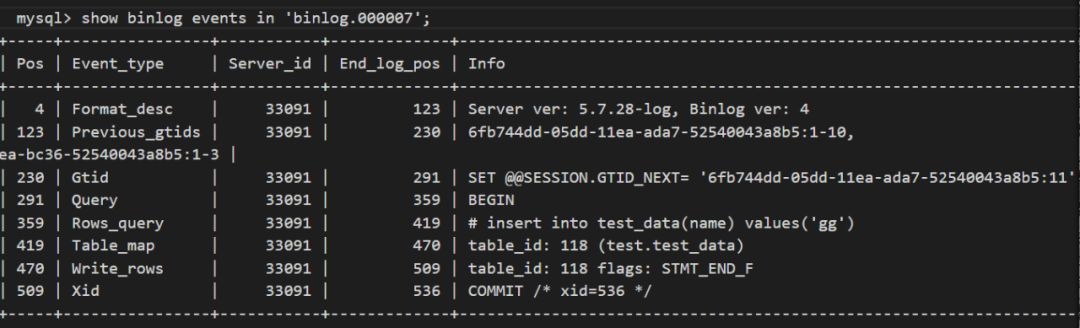
在Master1觸發語句:
insert into test_data(name) values(‘gg');
得到的binlog事件如下,可以清楚的看到相關的SQL語句。
在Master2端,我們查看binlog的情況,在開啟binlog_rows_query_log_events的前提下會看到明顯少了事件:Rows_query.
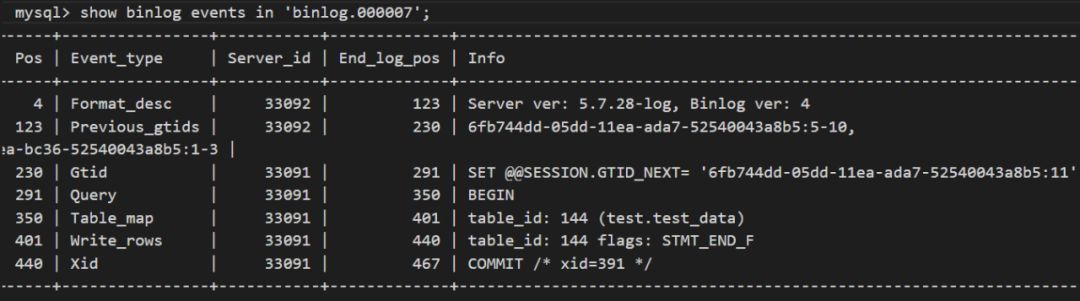
此時需要思考的是,在這個過程中偏移量是否發生了變化,從Master1產生的binlog到Master的relay log,如果通過mysqlbinlog去解析,得到的偏移量情況都是一模一樣,而在Master2消費后,產生了相關的binlog信息。
問題的關鍵就在這里,在Maser2里面是通過Server_id來標注了數據的源頭,所以在這里就稱為整個數據流轉的終點了,也就意味著數據復制的時候是按照server_id來進行U過濾的,每個Master端只會傳送自己相關的binlog信息。
如果從這個角度來說,MySQL對于復制中的server_id如此重要的一個原因就是基于此。
而如果換一個角度,看待基于偏移量的異步復制,其實也可以得到類似的信息。
這是Master1觸發insert語句后的binlog細節。

這是Master2接受實時數據后的binlog細節。

其實看到這里,還存在一個問題,那就是在偏移量模式下,如果需要一個數據變更操作在Master2丟失了,那么是沒有辦法進行回溯的。
而基于GTID模式可以唯一性標識全局事務,那么哪怕對這個操作進行了重復應用,哪怕是DDL語句,操作的影響行數也是0.
我們對一個已經執行的操作進行再次應用,看看MySQL是否會自動舍棄該類操作。
mysql> SET @@SESSION.GTID_NEXT= '6fb744dd-05dd-11ea-ada7-52540043a8b5:6'; Query OK, 0 rows affected (0.00 sec) mysql> use `test`; create table test_data (id int primary key auto_increment,name varchar(30)); Database changed Query OK, 0 rows affected (0.00 sec)
查看show binlog events發現這個過程不會產生額外的binlog。
所以基于此,我們也基本明確了數據回環解決方法的一個設計思想,那就是如何讓MySQL能夠識別出那些已經應用的事務數據,我想GTID是一個答案,而且分布式ID不用,這是MySQL內部的處理機制,而且是MySQL能夠識別的方式。
關于怎么在MySQL中通過配置雙主避免數據回環沖突問題的解答就分享到這里了,希望以上內容可以對大家有一定的幫助,如果你還有很多疑惑沒有解開,可以關注億速云行業資訊頻道了解更多相關知識。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





