溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這期內容當中小編將會給大家帶來有關使用Python怎么書寫一個線性回歸,文章內容豐富且以專業的角度為大家分析和敘述,閱讀完這篇文章希望大家可以有所收獲。
首先定義用于加載數據集的函數:
def load_data(filename): df = pd.read_csv(filename, sep=",", index_col=False) df.columns = ["housesize", "rooms", "price"] data = np.array(df, dtype=float) plot_data(data[:,:2], data[:, -1]) normalize(data) return data[:,:2], data[:, -1]
我們稍后將調用上述函數來加載數據集。此函數返回 x 和 y。
上述代碼不僅加載數據,還對數據執行歸一化處理并繪制數據點。在查看數據圖之前,我們首先了解上述代碼中的 normalize(data)。
查看原始數據集后,你會發現第二列數據的值(房間數量)比第一列(即房屋面積)小得多。該模型不會將此數據評估為房間數量或房屋面積,對于模型來說,它們只是一些數字。機器學習模型中某些列(或特征)的數值比其他列高可能會造成不想要的偏差,還可能導致方差和數學均值的不平衡。出于這些原因,也為了簡化工作,我們建議先對特征進行縮放或歸一化,使其位于同一范圍內(例如 [-1,1] 或 [0,1]),這會讓訓練容易許多。因此我們將使用特征歸一化,其數學表達如下:
Z = (x — μ) / σ
μ : mean
σ : standard deviation
其中 z 是歸一化特征,x 是非歸一化特征。有了歸一化公式,我們就可以為歸一化創建一個函數:
def normalize(data): for i in range(0,data.shape[1]-1): data[:,i] = ((data[:,i] - np.mean(data[:,i]))/np.std(data[:, i]))
上述代碼遍歷每一列,并使用每一列中所有數據元素的均值和標準差對其執行歸一化。
在對線性回歸模型進行編碼之前,我們需要先問「為什么」。
為什么要使用線性回歸解決這個問題?這是一個非常有用的問題,在寫任何具體代碼之前,你都應該非常清楚要使用哪種算法,以及在給定數據集和待解決問題的情況下,這是否真的是最佳選擇。
我們可以通過繪制圖像來證明對當前數據集使用線性回歸有效的原因。為此,我們在上面的 load_data 中調用了 plot_data 函數,現在我們來定義一下 plot_data 函數:
def plot_data(x, y):
plt.xlabel('house size')
plt.ylabel('price')
plt.plot(x[:,0], y, 'bo')
plt.show()調用該函數,將生成下圖:
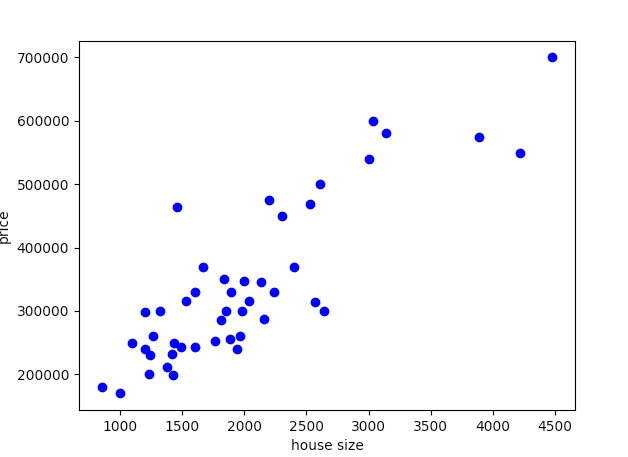
房屋面積與房屋價格關系圖。
如上圖所示,我們可以粗略地擬合一條線。這意味著使用線性近似能夠做出較為準確的預測,因此可以采用線性回歸。
準備好數據之后就要進行下一步,給算法編寫代碼。
首先我們需要定義假設函數,稍后我們將使用它來計算代價。對于線性回歸,假設是:
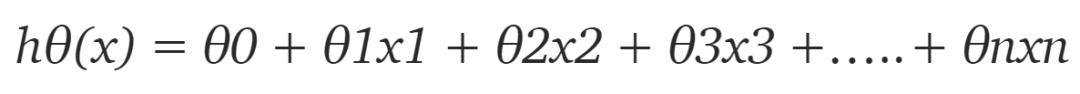
但數據集中只有 2 個特征,因此對于當前問題,假設是:
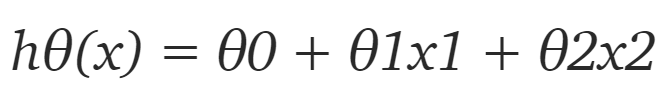
其中 x1 和 x2 是兩個特征(即房屋面積和房間數量)。然后編寫一個返回該假設的簡單 Python 函數:
def h(x,theta): return np.matmul(x, theta)
接下來我們來看代價函數。
使用代價函數的目的是評估模型質量。
代價函數的等式為:
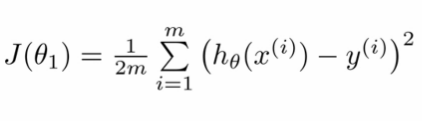
代價函數的代碼如下:
def cost_function(x, y, theta): return ((h(x, theta)-y).T@(h(x, theta)-y))/(2*y.shape[0])
到目前為止,我們定義的所有 Python 函數都與上述線性回歸的數學意義完全相同。接下來我們需要將代價最小化,這就要用到梯度下降。
梯度下降是一種優化算法,旨在調整參數以最小化代價函數。
梯度下降的主要更新步是:
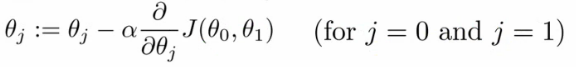
因此,我們將代價函數的導數乘以學習率(α),然后用參數(θ)的當前值減去它,獲得新的更新參數(θ)。
def gradient_descent(x, y, theta, learning_rate=0.1, num_epochs=10): m = x.shape[0] J_all = [] for _ in range(num_epochs): h_x = h(x, theta) cost_ = (1/m)*(x.T@(h_x - y)) theta = theta - (learning_rate)*cost_ J_all.append(cost_function(x, y, theta)) return theta, J_all
gradient_descent 函數返回 theta 和 J_all。theta 顯然是參數向量,其中包含假設的θs 值,J_all 是一個列表,包含每個 epoch 后的代價函數。J_all 變量并非必不可少,但它有助于更好地分析模型。
接下來要做的就是以正確的順序調用函數
x,y = load_data("house_price_data.txt")
y = np.reshape(y, (46,1))
x = np.hstack((np.ones((x.shape[0],1)), x))
theta = np.zeros((x.shape[1], 1))
learning_rate = 0.1
num_epochs = 50
theta, J_all = gradient_descent(x, y, theta, learning_rate, num_epochs)
J = cost_function(x, y, theta)
print("Cost: ", J)
print("Parameters: ", theta)
#for testing and plotting cost
n_epochs = []
jplot = []
count = 0
for i in J_all:
jplot.append(i[0][0])
n_epochs.append(count)
count += 1
jplot = np.array(jplot)
n_epochs = np.array(n_epochs)
plot_cost(jplot, n_epochs)
test(theta, [1600, 2])首先調用 load_data 函數載入 x 和 y 值。x 值包含訓練樣本,y 值包含標簽(在這里就是房屋的價格)。
你肯定注意到了,在整個代碼中,我們一直使用矩陣乘法的方式來表達所需。例如為了得到假設,我們必須將每個參數(θ)與每個特征向量(x)相乘。我們可以使用 for 循環,遍歷每個樣本,每次都執行一次乘法,但如果訓練的樣本過多,這可能不是最高效的方法。
在這里更有效的方式是使用矩陣乘法。本文所用的數據集具備兩個特征:房屋面積和房間數,即我們有(2+1)三個參數。將假設看作圖形意義上的一條線,用這種方式來思考額外參數θ0,最終額外的θ0 也要使這條線符合要求。
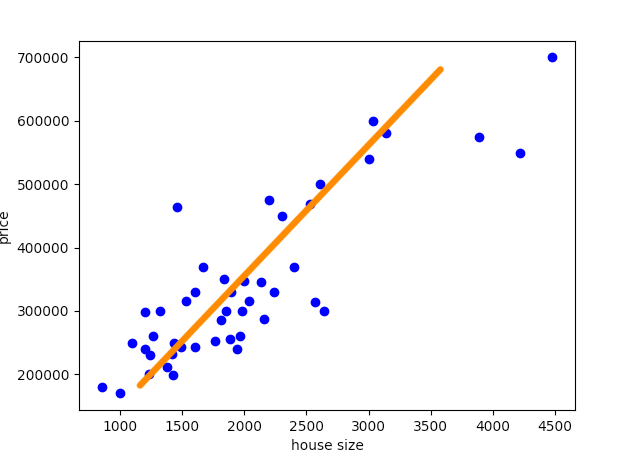
有利的假設函數圖示。
現在我們有了三個參數和兩個特征。這意味著θ或參數向量(1 維矩陣)的維數是 (3,1),但特征向量的維度是 (46,2)。你肯定會注意到將這樣兩個矩陣相乘在數學上是不可能的。再看一遍我們的假設:
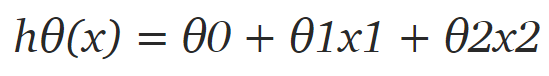
如果你仔細觀察的話,實際上這很直觀:如果在特征向量 (x) {維度為 (46, 3)} 的開頭添加額外的一列,并且對 x 和 theta 執行矩陣乘法,將得出 hθ(x) 的方程。
記住,在實際運行代碼來實現此功能時,不會像 hθ(x) 那樣返回表達式,而是返回該表達式求得的數學值。在上面的代碼中,x = np.hstack((np.ones((x.shape[0],1)), x)) 這一行在 x 開頭加入了額外一列,以備矩陣乘法需要。
在這之后,我們用零初始化 theta 向量,當然你也可以用一些小隨機值來進行初始化。我們還指定了訓練學習率和 epoch 數。
定義完所有超參數之后,我們就可以調用梯度下降函數,以返回所有代價函數的歷史記錄以及參數 theta 的最終向量。在這里 theta 向量定義了最終的假設。你可能注意到,由梯度下降函數返回的 theta 向量的維度為 (3,1)。
還記得函數的假設嗎?
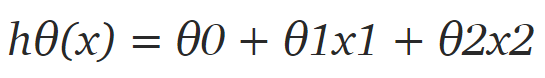
所以我們需要三個θ,theta 向量的維度為 (3,1),因此 theta [0]、theta [1] 和 theta [2] 實際上分別為θ0、θ1 和 θ2。J_all 變量是所有代價函數的歷史記錄。你可以打印出 J_all 數組,來查看代價函數在梯度下降的每個 epoch 中逐漸減小的過程。
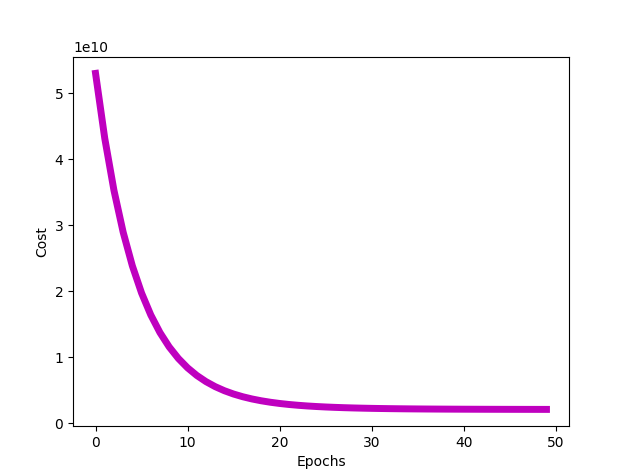
代價和 epoch 數量的關系圖。
我們可以通過定義和調用 plot_cost 函數來繪制此圖,如下所示:
def plot_cost(J_all, num_epochs):
plt.xlabel('Epochs')
plt.ylabel('Cost')
plt.plot(num_epochs, J_all, 'm', linewidth = "5")
plt.show()現在我們可以使用這些參數來找到標簽,例如給定房屋面積和房間數量時的房屋價格。
現在你可以測試調用測試函數的代碼,該函數會將房屋面積、房間數量和 logistic 回歸模型返回的最終 theta 向量作為輸入,并輸出房屋價格。
def test(theta, x):
x[0] = (x[0] - mu[0])/std[0]
x[1] = (x[1] - mu[1])/std[1]
y = theta[0] + theta[1]*x[0] + theta[2]*x[1]
print("Price of house: ", y)import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
#variables to store mean and standard deviation for each feature
mu = []
std = []
def load_data(filename):
df = pd.read_csv(filename, sep=",", index_col=False)
df.columns = ["housesize", "rooms", "price"]
data = np.array(df, dtype=float)
plot_data(data[:,:2], data[:, -1])
normalize(data)
return data[:,:2], data[:, -1]
def plot_data(x, y):
plt.xlabel('house size')
plt.ylabel('price')
plt.plot(x[:,0], y, 'bo')
plt.show()
def normalize(data):
for i in range(0,data.shape[1]-1):
data[:,i] = ((data[:,i] - np.mean(data[:,i]))/np.std(data[:, i]))
mu.append(np.mean(data[:,i]))
std.append(np.std(data[:, i]))
def h(x,theta):
return np.matmul(x, theta)
def cost_function(x, y, theta):
return ((h(x, theta)-y).T@(h(x, theta)-y))/(2*y.shape[0])
def gradient_descent(x, y, theta, learning_rate=0.1, num_epochs=10):
m = x.shape[0]
J_all = []
for _ in range(num_epochs):
h_x = h(x, theta)
cost_ = (1/m)*(x.T@(h_x - y))
theta = theta - (learning_rate)*cost_
J_all.append(cost_function(x, y, theta))
return theta, J_all
def plot_cost(J_all, num_epochs):
plt.xlabel('Epochs')
plt.ylabel('Cost')
plt.plot(num_epochs, J_all, 'm', linewidth = "5")
plt.show()
def test(theta, x):
x[0] = (x[0] - mu[0])/std[0]
x[1] = (x[1] - mu[1])/std[1]
y = theta[0] + theta[1]*x[0] + theta[2]*x[1]
print("Price of house: ", y)
x,y = load_data("house_price_data.txt")
y = np.reshape(y, (46,1))
x = np.hstack((np.ones((x.shape[0],1)), x))
theta = np.zeros((x.shape[1], 1))
learning_rate = 0.1
num_epochs = 50
theta, J_all = gradient_descent(x, y, theta, learning_rate, num_epochs)
J = cost_function(x, y, theta)
print("Cost: ", J)
print("Parameters: ", theta)
#for testing and plotting cost
n_epochs = []
jplot = []
count = 0
for i in J_all:
jplot.append(i[0][0])
n_epochs.append(count)
count += 1
jplot = np.array(jplot)
n_epochs = np.array(n_epochs)
plot_cost(jplot, n_epochs)
test(theta, [1600, 3])上述就是小編為大家分享的使用Python怎么書寫一個線性回歸了,如果剛好有類似的疑惑,不妨參照上述分析進行理解。如果想知道更多相關知識,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





