溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這期內容當中小編將會給大家帶來有關利用Python怎么創建一個神經網絡,文章內容豐富且以專業的角度為大家分析和敘述,閱讀完這篇文章希望大家可以有所收獲。
步驟1: 導入 NumPy、 Scikit-learn 和 Matplotlib
import numpy as np from sklearn.preprocessing import MinMaxScaler import matplotlib.pyplot as plt
我們將在這個項目中使用上述三個庫。NumPy 將用于創建向量和矩陣以及數學操作。Scikit-learn 將用于縮放數據,Matplotlib 將用于在神經網絡訓練期間繪圖。
神經網絡在大型和小型數據集的學習趨勢方面都很擅長。然而,數據科學家必須意識到過擬合的危險,這在使用小數據集的項目中更為明顯。過擬合是當一個算法訓練和建模過于接近一組數據點,以至于它不能很好地推廣到新的數據點。
通常情況下,過擬合的機器學習模型在訓練的數據集上有很高的準確性,但是作為一個數據科學家,目標通常是盡可能精確地預測新的數據點。為了確保根據預測新數據點的好壞來評估模型,而不是根據對當前數據點的建模好壞來評估模型,通常將數據集拆分為一個訓練集和一個測試集(有時是一個驗證集)。
input_train = np.array([[0, 1, 0], [0, 1, 1], [0, 0, 0], [10, 0, 0], [10, 1, 1], [10, 0, 1]]) output_train = np.array([[0], [0], [0], [1], [1], [1]]) input_pred = np.array([1, 1, 0]) input_test = np.array([[1, 1, 1], [10, 0, 1], [0, 1, 10], [10, 1, 10], [0, 0, 0], [0, 1, 1]]) output_test = np.array([[0], [1], [0], [1], [0], [0]])
在這個簡單的神經網絡中,我們將1x3向量分類,10作為第一個元素。使用 NumPy 的 array 函數創建輸入和輸出訓練集和測試集,并創建 input_pred 以測試稍后將定義的 prediction 函數。訓練和測試數據由6個樣本組成,每個樣本具有3個特征,由于輸出已經給出,我們理解這是監督式學習的一個例子。
許多機器學習模型不能理解例如單位之間的區別,自然而然地對高度的特征應用更多的權重。這會破壞算法預測新數據點的能力。此外,訓練具有高強度特征的機器學習模型將會比需要的慢,至少如果使用梯度下降法。這是因為當輸入值在大致相同的范圍內時,梯度下降法收斂得更快。
scaler = MinMaxScaler() input_train_scaled = scaler.fit_transform(input_train) output_train_scaled = scaler.fit_transform(output_train) input_test_scaled = scaler.fit_transform(input_test) output_test_scaled = scaler.fit_transform(output_test)
在我們的訓練和測試數據集中,這些值的范圍相對較小,因此可能沒有必要進行特征擴展。然而,這樣可以使得小伙伴們使用自己喜歡的數字,而不需要更改太多的代碼。由于 Scikit-learn 包及其 MinMaxScaler 類,在 Python 中實現特征伸縮非常容易。只需創建一個 MinMaxScaler 對象,并使用 fit_transform 函數將非縮放數據作為輸入,該函數將返回相同的縮放數據。Scikit-learn 包中還有其他縮放功能,我鼓勵您嘗試這些功能。
要熟悉神經網絡的所有元素,最簡單的方法之一就是創建一個神經網絡類。這樣一個類應該包括所有的變量和函數,將是必要的神經網絡工作正常。
class NeuralNetwork():
def __init__(self, ):
self.inputSize = 3
self.outputSize = 1
self.hiddenSize = 3
self.W1 = np.random.rand(self.inputSize, self.hiddenSize)
self.W2 = np.random.rand(self.hiddenSize, self.outputSize)
self.error_list = []
self.limit = 0.5
self.true_positives = 0
self.false_positives = 0
self.true_negatives = 0
self.false_negatives = 0
def forward(self, X):
self.z = np.matmul(X, self.W1)
self.z2 = self.sigmoid(self.z)
self.z3 = np.matmul(self.z2, self.W2)
o = self.sigmoid(self.z3)
return o
def sigmoid(self, s):
return 1 / (1 + np.exp(-s))
def sigmoidPrime(self, s):
return s * (1 - s)
def backward(self, X, y, o):
self.o_error = y - o
self.o_delta = self.o_error * self.sigmoidPrime(o)
self.z2_error = np.matmul(self.o_delta,
np.matrix.transpose(self.W2))
self.z2_delta = self.z2_error * self.sigmoidPrime(self.z2)
self.W1 += np.matmul(np.matrix.transpose(X), self.z2_delta)
self.W2 += np.matmul(np.matrix.transpose(self.z2),
self.o_delta)
def train(self, X, y, epochs):
for epoch in range(epochs):
o = self.forward(X)
self.backward(X, y, o)
self.error_list.append(np.abs(self.o_error).mean())
def predict(self, x_predicted):
return self.forward(x_predicted).item()
def view_error_development(self):
plt.plot(range(len(self.error_list)), self.error_list)
plt.title('Mean Sum Squared Loss')
plt.xlabel('Epoch')
plt.ylabel('Loss')
def test_evaluation(self, input_test, output_test):
for i, test_element in enumerate(input_test):
if self.predict(test_element) > self.limit and \
output_test[i] == 1:
self.true_positives += 1
if self.predict(test_element) < self.limit and \
output_test[i] == 1:
self.false_negatives += 1
if self.predict(test_element) > self.limit and \
output_test[i] == 0:
self.false_positives += 1
if self.predict(test_element) < self.limit and \
output_test[i] == 0:
self.true_negatives += 1
print('True positives: ', self.true_positives,
'\nTrue negatives: ', self.true_negatives,
'\nFalse positives: ', self.false_positives,
'\nFalse negatives: ', self.false_negatives,
'\nAccuracy: ',
(self.true_positives + self.true_negatives) /
(self.true_positives + self.true_negatives +
self.false_positives + self.false_negatives))步驟4.1: 創建一個 Initialize 函數
當我們在 Python 中創建一個類以便正確地初始化變量時,會調用 __init__ 函數。
def __init__(self, ): self.inputSize = 3 self.outputSize = 1 self.hiddenSize = 3 self.W1 = torch.randn(self.inputSize, self.hiddenSize) self.W2 = torch.randn(self.hiddenSize, self.outputSize) self.error_list = [] self.limit = 0.5 self.true_positives = 0 self.false_positives = 0 self.true_negatives = 0 self.false_negatives = 0
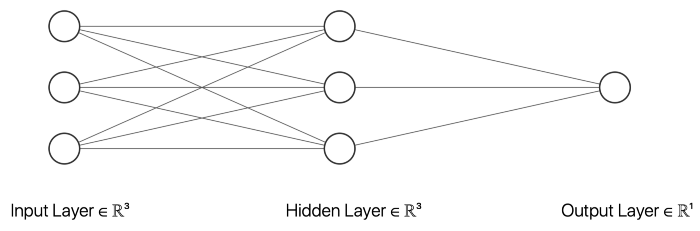
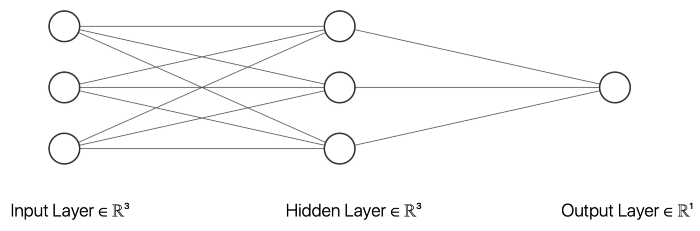
在這個例子中,我選擇了一個有三個輸入節點、三個隱藏層節點和一個輸出節點的神經網絡。以上的 __init__ 函數初始化描述神經網絡大小的變量。inputSize 是輸入節點的數目,它應該等于輸入數據中特征的數目。outputSize 等于輸出節點數,hiddenSize 描述隱藏層中的節點數。此外,我們的網絡中不同節點之間的權重將在訓練過程中進行調整。
除了描述神經網絡的大小和權重的變量之外,我還創建了幾個在創建神經網絡對象時初始化的變量,這些對象將用于評估目的。誤差列表將包含每個時期的平均絕對誤差(MAE) ,這個極限將描述一個向量應該被分類為一個向量,元素10作為第一個元素而不是。然后,還有一些變量可以用來存儲真實陽性、假陽性、真實陰性和假陰性的數量。
步驟4.2: 創建一個前向傳播函數
前向傳播函數的作用是通過神經網絡的不同層次進行迭代,以預測特定 epoch 的輸出。然后,根據預測輸出和實際輸出之間的差異,在反向傳播的過程中更新權重。
def forward(self, X): self.z = np.matmul(X, self.W1) self.z2 = self.sigmoid(self.z) self.z3 = np.matmul(self.z2, self.W2) o = self.sigmoid(self.z3) return o
為了計算每一層中每個節點的值,前一層中節點的值將被乘以適當的權重,然后應用非線性激活函數來擴大最終輸出函數的可能性。在這個例子中,我們選擇了 Sigmoid 作為激活函數,但也有許多其他的選擇。
步驟4.3: 創建一個反向傳播函數
反向傳播是對神經網絡中不同節點的權值進行更新,從而決定其重要性的過程。
def backward(self, X, y, o): self.o_error = y - o self.o_delta = self.o_error * self.sigmoidPrime(o) self.z2_error = np.matmul(self.o_delta, np.matrix.transpose(self.W2)) self.z2_delta = self.z2_error * self.sigmoidPrime(self.z2) self.W1 += np.matmul(np.matrix.transpose(X), self.z2_delta) self.W2 += np.matmul(np.matrix.transpose(self.z2), self.o_delta)
在上面的代碼片段中,輸出層的輸出錯誤被計算為預測輸出與實際輸出之間的差值。然后,在重復整個過程直到到達輸入層之前,將這個錯誤與 Sigmoid 相乘以運行梯度下降法。最后,更新不同層之間的權重。
步驟4.4: 創建一個訓練函數
在訓練過程中,該算法將運行向前和向后傳遞,從而更新每個 epoch 的權重。為了得到最精確的權重值,這是必要的。
def train(self, X, y, epochs): for epoch in range(epochs): o = self.forward(X) self.backward(X, y, o) self.error_list.append(np.abs(self.o_error).mean())
除了向前和向后傳播之外,我們還將平均絕對誤差(MAE)保存到一個錯誤列表中,以便日后觀察平均絕對誤差在訓練過程中是如何演變的。
步驟4.5: 創建一個預測函數
在訓練過程中對權重進行了微調之后,該算法就可以預測新數據點的輸出。預測的輸出數字有望與實際輸出數字非常接近。
def predict(self, x_predicted): return self.forward(x_predicted).item()
步驟4.6: 繪制平均絕對誤差發展圖
評價機器學習算法質量的方法有很多。經常使用的測量方法之一是平均絕對誤差,這個誤差應該隨著時間的推移而減小。
def view_error_development(self):
plt.plot(range(len(self.error_list)), self.error_list)
plt.title('Mean Sum Squared Loss')
plt.xlabel('Epoch')
plt.ylabel('Loss')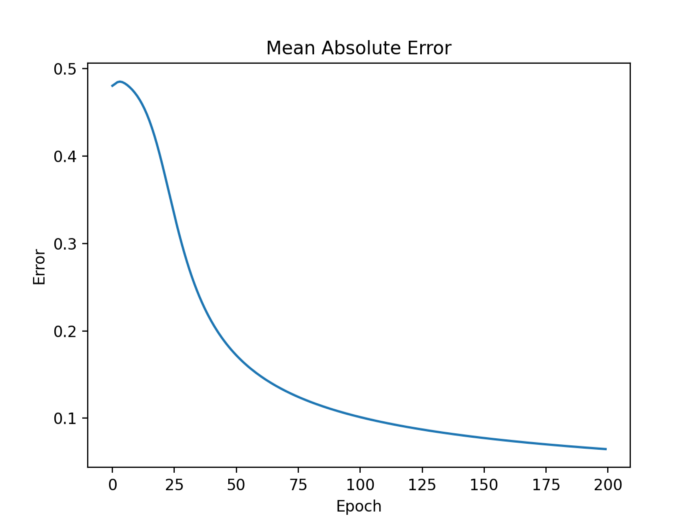
步驟4.7: 計算精度及其組成部分
真正、假正、真負和假負的數量描述了機器學習分類算法的質量。訓練后的神經網絡權值更新,使算法能夠準確地預測新的數據點。在二進制分類任務中,這些新數據點只能是1或0。根據預測值是否高于或低于定義的限制,算法將新條目分為1或0。
def test_evaluation(self, input_test, output_test):
for i, test_element in enumerate(input_test):
if self.predict(test_element) > self.limit and \
output_test[i] == 1:
self.true_positives += 1
if self.predict(test_element) < self.limit and \
output_test[i] == 1:
self.false_negatives += 1
if self.predict(test_element) > self.limit and \
output_test[i] == 0:
self.false_positives += 1
if self.predict(test_element) < self.limit and \
output_test[i] == 0:
self.true_negatives += 1
print('True positives: ', self.true_positives,
'\nTrue negatives: ', self.true_negatives,
'\nFalse positives: ', self.false_positives,
'\nFalse negatives: ', self.false_negatives,
'\nAccuracy: ',
(self.true_positives + self.true_negatives) /
(self.true_positives + self.true_negatives +
self.false_positives + self.false_negatives))當運行 test _ evaluation 函數時,我們得到以下結果:
真正: 2
真負: 4
假正: 0
假負: 0
準確性由以下公式給出:
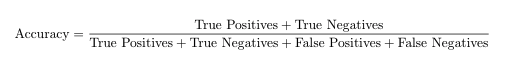
由此我們可以推斷,在我們的案例中,精確度是1。
NN = NeuralNetwork() NN.train(input_train_scaled, output_train_scaled, 200) NN.predict(input_pred) NN.view_error_development() NN.test_evaluation(input_test_scaled, output_test_scaled)
為了嘗試我們剛剛構建的神經網絡類,我們將首先初始化一個神經網絡類型的對象。然后對訓練數據進行神經網絡訓練,在新訓練的模型在測試向量上進行測試之前,對算法的權值進行200個 epoch 以上的“修正”。然后,在利用測試數據集對模型進行評估之前,繪制誤差圖。
提供的代碼可以很容易地修改,以處理其他類似的情況。我們鼓勵讀者嘗試改變變量并使用自己的數據等等。改進或變更的潛在想法包括但不限于:
泛化代碼以適用于任何輸入和輸出大小的數據
使用平均絕對誤差以外的另一個度量來衡量誤差
使用其他的縮放函數
上述就是小編為大家分享的利用Python怎么創建一個神經網絡了,如果剛好有類似的疑惑,不妨參照上述分析進行理解。如果想知道更多相關知識,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





