溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
大數據中怎么來加載數據呢?數據加載應該注意哪些問題呢?關系型數據庫和Impala、Hive加載數據有哪些區別呢?
在了解加載數據之前必須明確一個概念“數據驗證”, Impala和Hive與其他關系型數據庫不一樣,關系型數據庫是在寫的時候進行校驗,比如我們創建一個表,當去給它加載數據的時候,它會去驗證數據以及數據類型是不是符合要求,如果不符合,數據就加載不了。
在Hive和Impala中,它在讀的時候進行校驗。為什么會這樣設計呢?主要是為了提升寫的速度和加載的效率。那么,這樣檢驗數據會不會出錯呢?當然不會,如果你查詢不到這個數據,它會以“null”來表達。如果要對查詢可靠性進行保證,保證每個數據都能查到和匹配,可以通過其它的工程語言在前端進行一個保證。
一、從HDFS加載數據
(1)為了加載數據,可以簡單地添加文件到HDFS的表目錄,這個直接使用hdfs dfs命令完成
示例:從HDFS加載數據到sales表

(2)使用LOAD DATA INPATH命令,在Hive或者Impala里完成。這個操作將在HDFS內移動數據,就像前面的命令一樣,數據源可以是文件或目錄。

二、覆蓋數據
(1)添加OVERWRITE關鍵字在導入之前刪除所有記錄。就是在表目錄內移除所有文件,然后把新文件移動到那個目錄。

三、追加選擇的記錄到表中
(1)通過查詢插入數據
1、使用INSERT INTO來添加結果到已存在的Hive表中

2、指定WHERE條件來控制哪些記錄將被追加

四、使用元數據庫管理器加載數據
(1)元數據管理器提供了兩種方法來加載數據
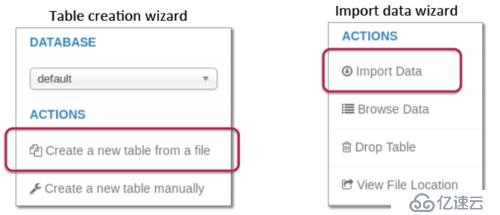
五、從關系型數據庫加載數據
Sqoop內嵌支持導入數據到Hive和Impala,可以添加--hive-import選項到Sqoop命令,在Hive元數據庫中創建表,從RDBMS導入數據到HDFS表目錄。

注意--hive-import創建的表在Hive和Impala中都可以訪問
有問題,隨時來,還有同行共歡聚,大家一起聊!
歡迎關注微信公眾號“大數據cn”。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





