溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
公司基礎架構這邊想提取慢作業和獲悉資源浪費的情況,所以裝個dr elephant看看。LinkIn開源的系統,可以對基于yarn的mr和spark作業進行性能分析和調優建議。
DRE大部分基于java開發,spark監控部分使用scala開發,使用play堆棧式框架。這是一個類似Python里面Django的框架,基于java?scala?沒太細了解,直接下來就能用,需要java1.8以上。
prerequest list:
Java 1.8
PlayFramework+activator
Nodejs+npm
scala+sbt
編譯服務器是設立在美國硅谷的某云主機,之前為了bigtop已經裝好了java,maven,ant,scala,sbt等編譯工具,所以下載activator解壓放到/usr/local并加入PATH即可。
然后從 github clone一份dr-elephant下來,打開compile.conf,修改hadoop和spark版本為當前使用版本,:wq保存退出,運行compile.sh進行編譯,經過短暫的等待之后,因為美國服務器,下依賴快。會有個dist文件夾,里面會打包一個dr-elephant-2.0.x.zip,拷出來解壓縮就可以用了。
DRE本身需要mysql 5.5以上支持,或者mariadb最新的10.1穩定版本亦可。這里會有一個問題,就是在DRE/conf/evolutions/default/1.sql里面的這三行:
create index yarn_app_result_i4 on yarn_app_result (flow_exec_id); create index yarn_app_result_i5 on yarn_app_result (job_def_id); create index yarn_app_result_i6 on yarn_app_result (flow_def_id);
由于在某些數據庫情況下,索引長度會超過數據庫本身的限制,所以,需要修改索引長度來避免無法啟動的情況發生。
create index yarn_app_result_i4 on yarn_app_result (flow_exec_id(150)); create index yarn_app_result_i5 on yarn_app_result (job_def_id(150)); create index yarn_app_result_i6 on yarn_app_result (flow_def_id(150));
然后就應該沒啥問題了。
到數據庫里創建一個叫drelephant的數據庫,并給出相關訪問權限用戶
接下來是需要配置DRE:
打開app-conf/elephant.conf
# Play application server port # 啟動dre后play框架監聽的web端口 port=8080 # Database configuration # 數據庫主機,用戶名密碼庫名 db_url=localhost db_name=drelephant db_user="root" db_password=
其他默認即可,不需更改
然后是GeneralConf.xml
<configuration> <property> <name>drelephant.analysis.thread.count</name> <value>3</value> <description>Number of threads to analyze the completed jobs</description> </property> <property> <name>drelephant.analysis.fetch.interval</name> <value>60000</value> <description>Interval between fetches in milliseconds</description> </property> <property> <name>drelephant.analysis.retry.interval</name> <value>60000</value> <description>Interval between retries in milliseconds</description> </property> <property> <name>drelephant.application.search.match.partial</name> <value>true</value> <description>If this property is "false", search will only make exact matches</description> </property> </configuration>
修改drelephant.analysis.thread.count,默認是3,建議修改到10,3的話從jobhistoryserver讀取的速度太慢,高于10的話又讀取的太快,會對jobhistoryserver造成很大壓力。下面兩個一個是讀取的時間周期,一個是重試讀取的間隔時間周期。
然后到bin下執行start.sh啟動。And then, show smile to the yellow elephant。
裝完看了一下這個東西,其實本身原理并不復雜,就是讀取各種jmx,metrics,日志信息,自己寫一個也不是沒有可能。功能主要是把作業信息里的內容匯總放到一屏里面顯示,省的在JHS的頁面里一個一個點了。
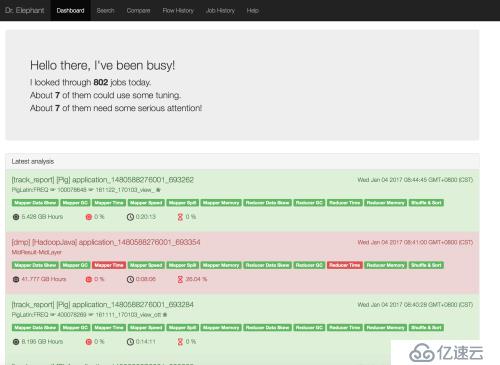
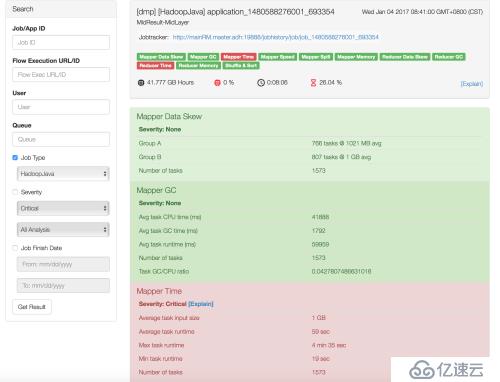
That's it, so easy
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





