溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章給大家介紹grep與正則表達式怎么在linux中使用,內容非常詳細,感興趣的小伙伴們可以參考借鑒,希望對大家能有所幫助。
grep (縮寫來自Globally search a Regular Expression and Print)是一種強大的文本搜索工具,它能使用特定模式匹配(包括正則表達式)搜索文本,并默認輸出匹配行。Unix的grep家族包括grep、egrep和fgrep。Windows系統下類似命令FINDSTR。
grep egrep fgrep(不支持正則表達式)
grep需要標準輸入 因此常常位于管道右側
命令參數:
--color=auto: 對匹配到的文本著色顯示
-v: 顯示不被pattern匹配到的行
-i: 忽略字符大小寫
-n:顯示匹配的行號
-c: 統計匹配的行數
-o: 僅顯示匹配到的字符串
-q: 靜默模式,不輸出任何信息
-A #: after, 后#行
-B #: before, 前#行
-C #:context, 前后各#行
-e:實現多個選項間的邏輯or關系
grep –e ‘cat ' -e ‘dog' file
-w:匹配整個單詞 數字加字母下劃線全都算單詞的一部分,其他的都是單詞的分隔符
-E:相當于egrep
-F:相當于fgrep,不支持正則表達式
-f: 跟一個文件(寫有不同字符)進行內容檢索是邏輯or關系
練習題:
1、顯示三個用戶root、centos、arch的UID和默認shell (用戶需要自己創建)

2、找出/etc/rc.d/init.d/functions文件中行首為某單詞(包括下劃線)后面跟一 個小括號的行
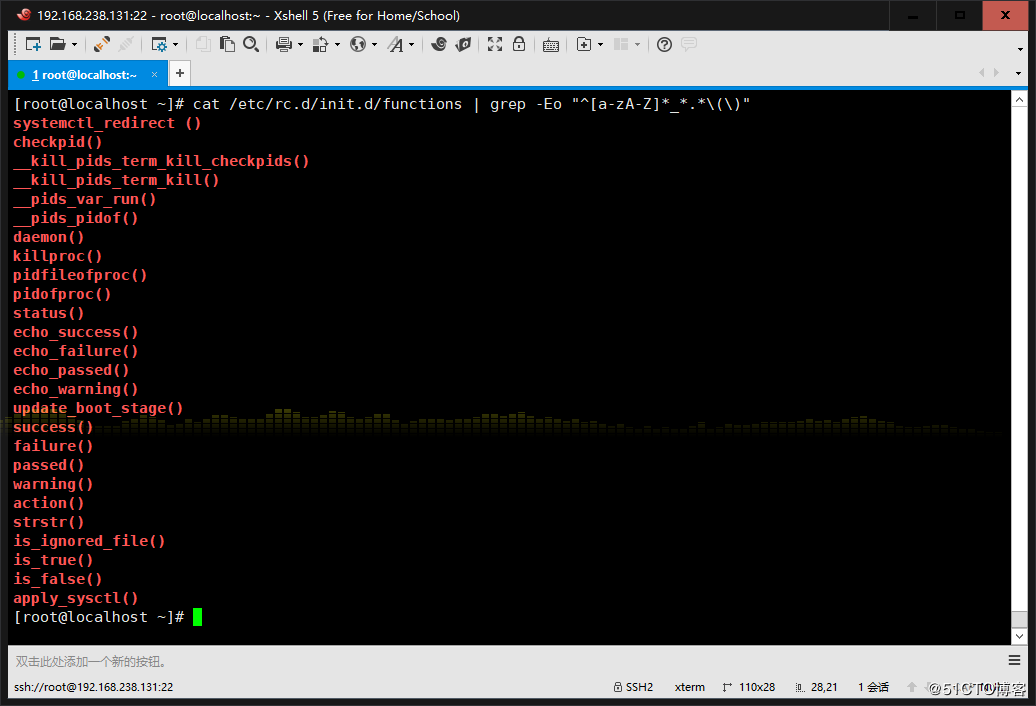
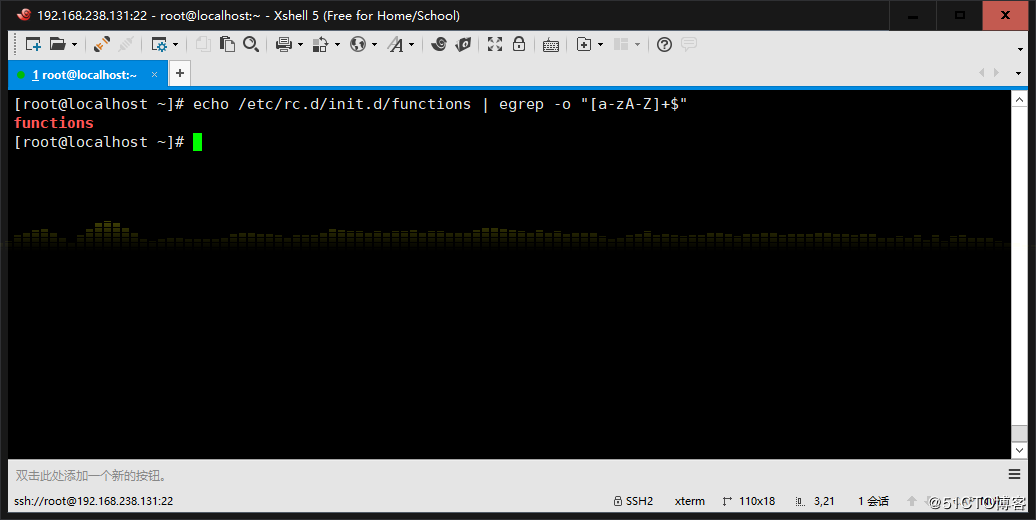
3、使用egrep取出/etc/rc.d/init.d/functions中其基名
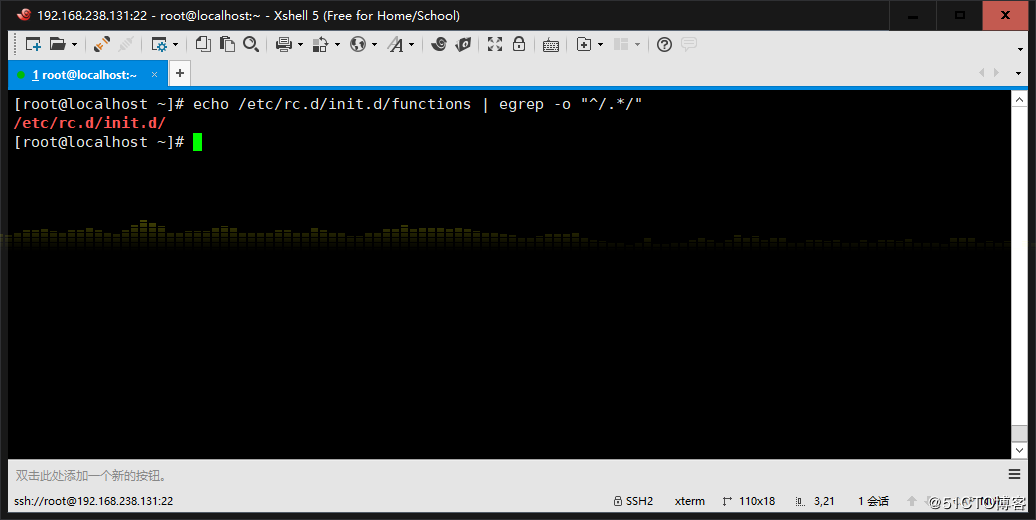
4、使用egrep取出上面路徑的目錄名
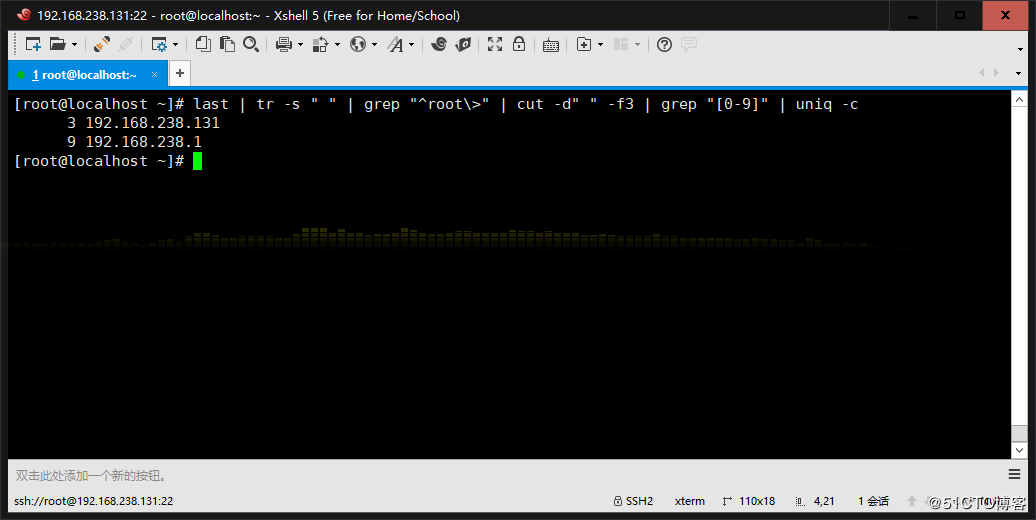
5、統計last命令中以root登錄的每個主機IP地址登錄次數
6、利用擴展正則表達式分別表示0-9、10-99、100-199、200-249、250-255
0-9: [0-9]
10-99: [1-9][0-9]
100-199: 1[0-9][0-9]
200-249: 2[0-5][0-9]
250-255: 25[0-5]
7、顯示ifconfig命令結果中所有IPv4地址
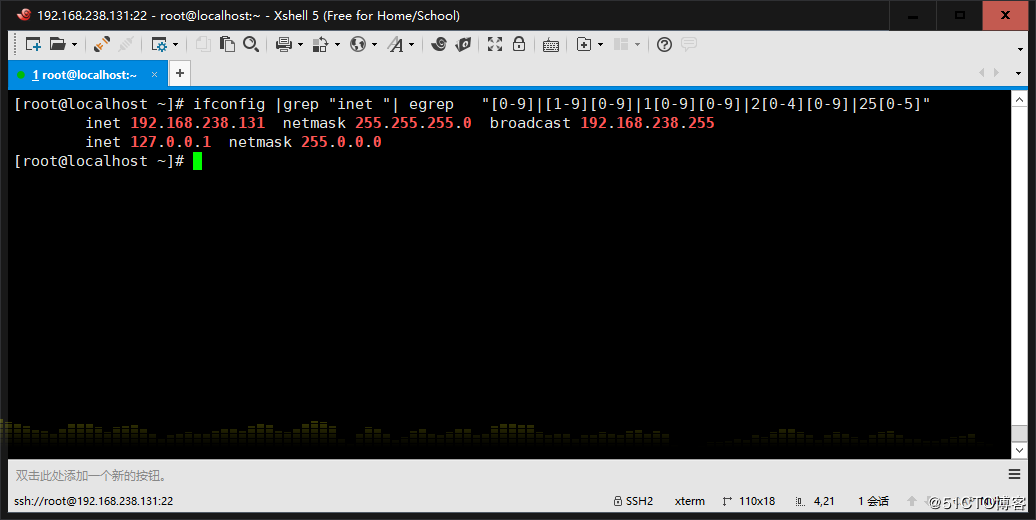
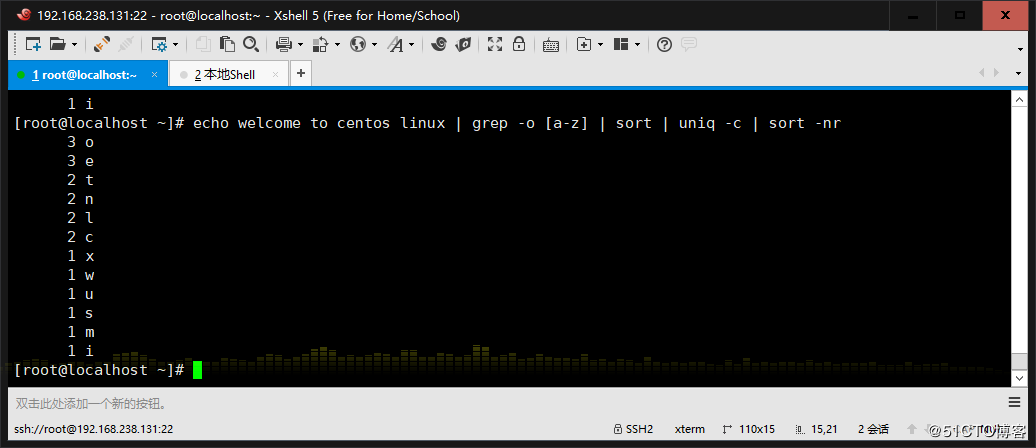
8、將此字符串:welcome to centos linux 中的每個字符排序,重復 次數多的排到前面
正則表達式:
REGEXP:由一類特殊字符及文本字符所編寫的模式,其中有些字符(元字符) 不表示字符字面意義,而表示控制或通配的功能
程序支持:grep,sed,awk,vim, less,nginx,varnish等
分兩類:
基本正則表達式:BRE
擴展正則表達式:ERE
grep -E, egrep
正則表達式引擎:
采用不同算法,檢查處理正則表達式的軟件模塊
PCRE(Perl Compatible Regular Expressions)
元字符分類:字符匹配、匹配次數、位置錨定、分組
man 7 regex
字符匹配:
. 匹配任意單個字符 默認是貪婪匹配
[] 匹配指定范圍內的任意單個字符 .在里面也是點不需要轉義
[^] 匹配指定范圍外的任意單個字符
[:alnum:] 字母和數字
[:alpha:] 代表任何英文大小寫字符,亦即 A-Z, a-z
[:lower:] 小寫字母
[:upper:] 大寫字母
[:blank:] 空白字符(空格和制表符)
[:space:] 水平和垂直的空白字符(比[:blank:]包含的范圍廣)
[:cntrl:] 不可打印的控制字符(退格、刪除、警鈴...)
[:digit:] 十進制數字
[:xdigit:]十六進制數字
[:graph:] 可打印的非空白字符
[:print:] 可打印字符
[:punct:] 標點符號
匹配次數:用在要指定次數的字符后面,用于指定前面的字符要出現的次數
* 匹配前面的字符任意次,包括0次
貪婪模式:盡可能的匹配符合條件的字符
.* 任意長度的任意字符
\? 匹配其前面的字符0或1次
\+ 匹配其前面的字符至少1次
\{n\} 匹配前面的字符n次
\{m,n\} 匹配前面的字符至少m次,至多n次
\{,n\} 匹配前面的字符至多n次
\{n,\} 匹配前面的字符至少n
位置錨定:定位出現的位置
^ 行首錨定,用于模式的最左側
$ 行尾錨定,用于模式的最右側
^PATTERN$ 用于模式匹配整行
^$ 空行
^[[:space:]]*$ 空白行
\< 或 \b 詞首錨定,用于單詞模式的左側
\> 或 \b 詞尾錨定;用于單詞模式的右側
\<PATTERN\> 匹配整個單詞
分組:\(\) 將一個或多個字符捆綁在一起,當作一個整體進行處理,如: \(root\)\+
分組括號中的模式匹配到的內容會被正則表達式引擎記錄于內部的變量中,
這些變量的命名方式為: \1, \2, \3, ...
\1 表示從左側起第一個左括號以及與之匹配右括號之間的模式所匹配到的字符
示例: \(string1\+\(string2\)*\)
\1 :string1\+\(string2\)*
\2 :string2
后向引用:引用前面的分組括號中的模式所匹配字符,而非模式本身
或者:\|
示例:a\|b: a或b C\|cat: C或cat \(C\|c\)at:Cat或cat
擴展的正則表達式:
egrep = grep -E
egrep [OPTIONS] PATTERN [FILE...]
擴展正則表達式的元字符:
字符匹配:
. 任意單個字符
[] 指定范圍的字符
[^] 不在指定范圍的字符
次數匹配:
*:匹配前面字符任意次
?: 0或1次
+:1次或多次
{m}:匹配m次
{m,n}:至少m,至多n次
位置錨定:
^ :行首
$ :行尾
\<, \b :語首
\>, \b :語尾
分組:
() 后向引用:\1, \2, ...
或者:
a|b: a或b C|cat: C或cat (C|c)at:Cat或cat
練習題:
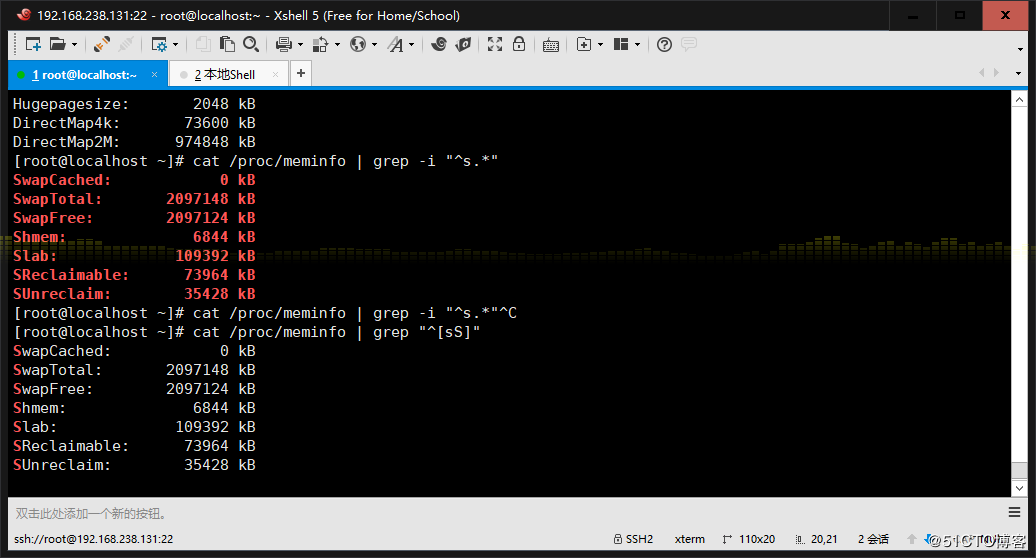
1、顯示/proc/meminfo文件中以大小s開頭的行(要求:使用兩種方法)
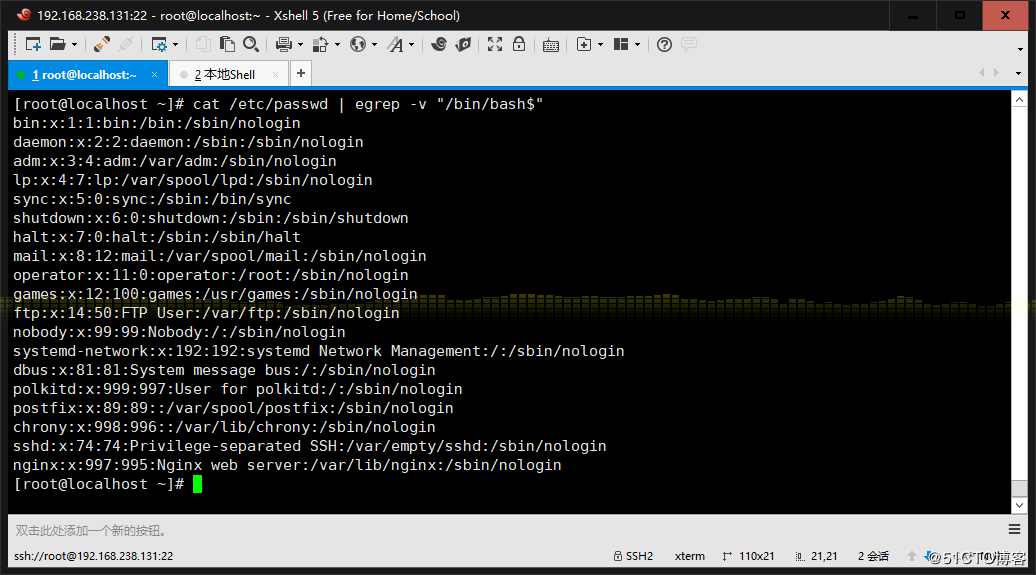
2、顯示/etc/passwd文件中不以/bin/bash結尾的行
3、顯示用戶rpc默認的shell程序

4、找出/etc/passwd中的兩位或三位數 (只要數字的話可以加-o選項僅僅顯示數字)
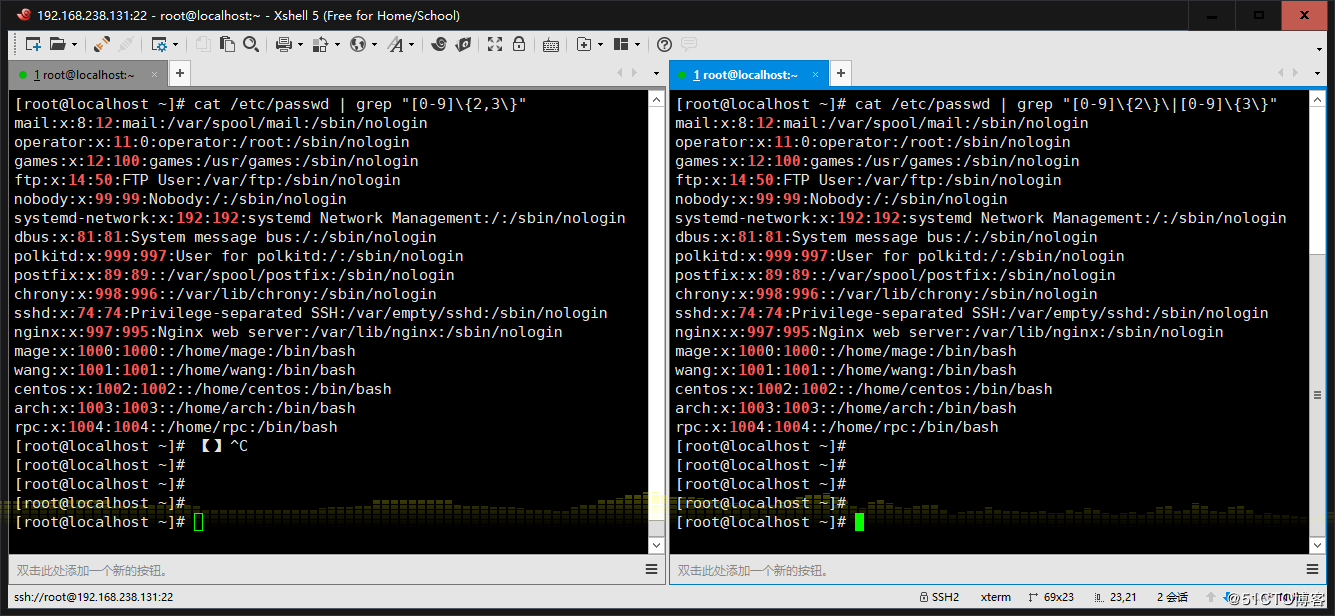
5、顯示CentOS7的/etc/grub2.cfg文件中,至少以一個空白字符開頭的且后面有非 空白字符的行
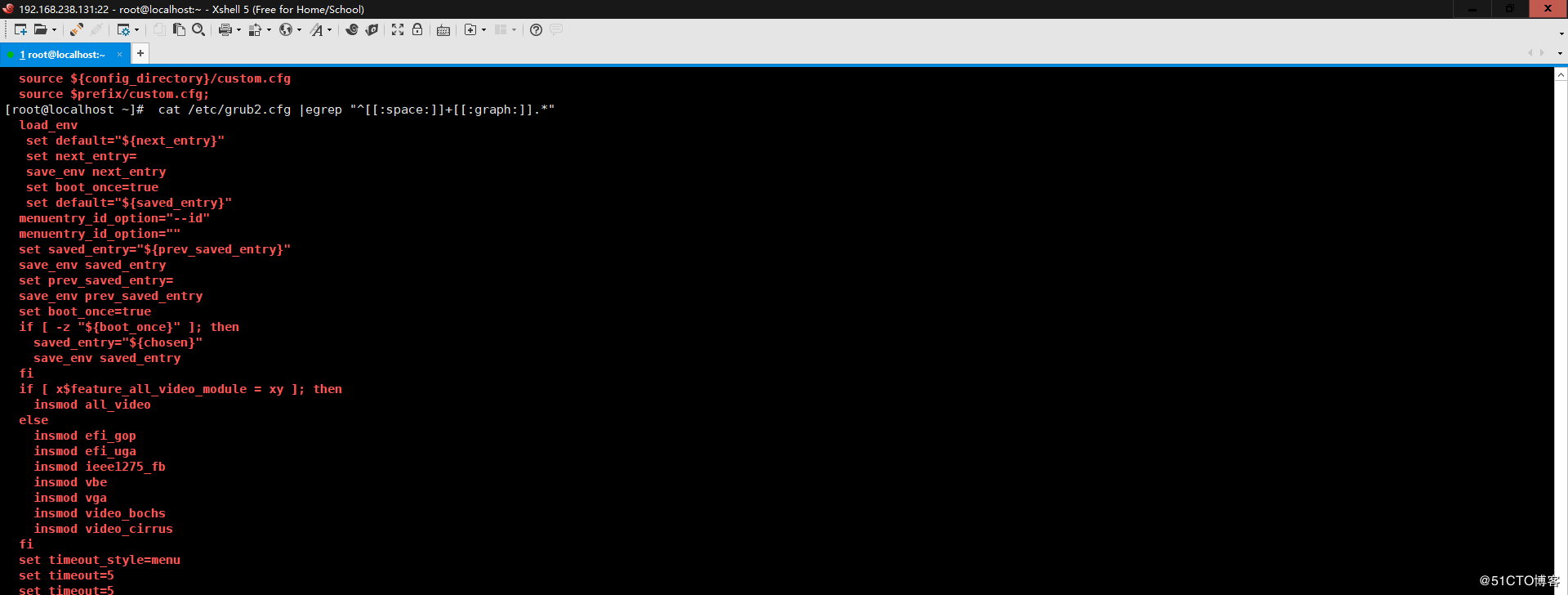
6、找出“netstat -tan”命令結果中以LISTEN后跟任意多個空白字符結尾的行
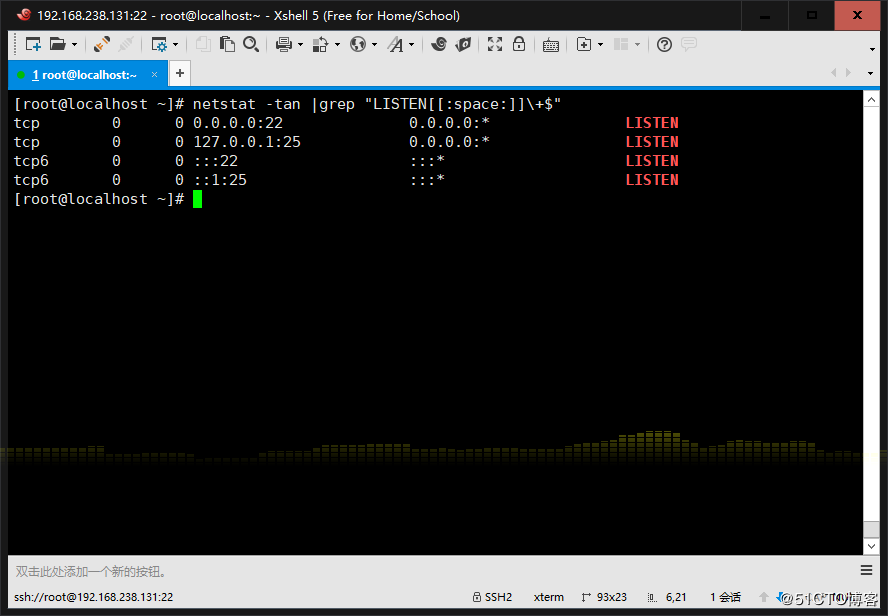
7、顯示CentOS7上所有系統用戶的用戶名和UID
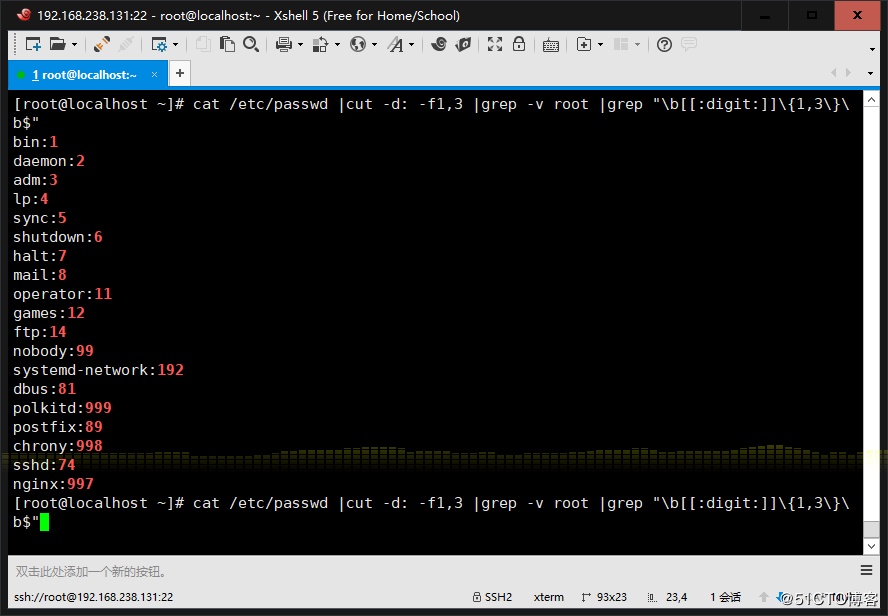
8、添加用戶bash、testbash、basher、sh、nologin(其shell為/sbin/nologin),找 出/etc/passwd用戶名和shell同名的行
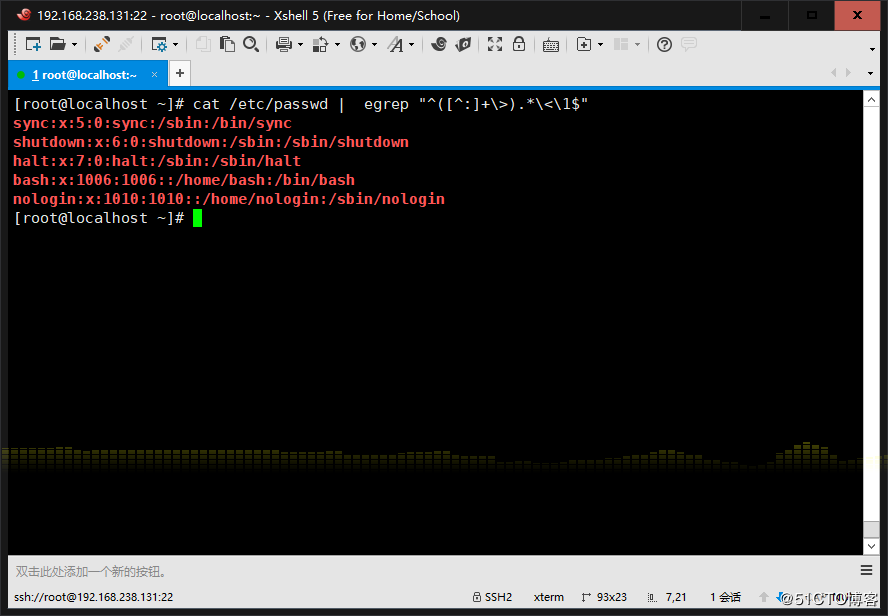
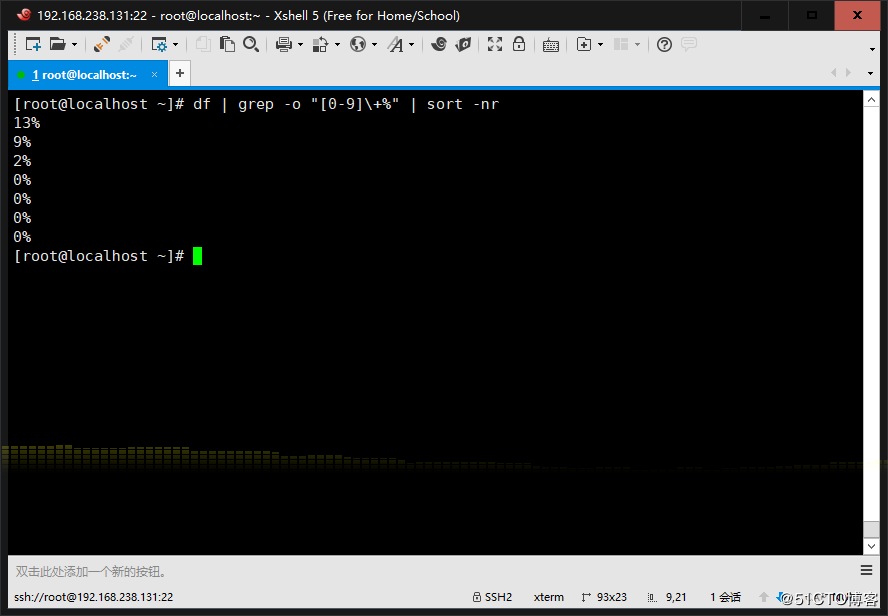
9、利用df和grep,取出磁盤各分區利用率,并從大到小排序
grep和正則表達式參數
一:grep參數
1,-n :顯示行號

2,-o :只顯示匹配的內容

3,-q :靜默模式,沒有任何輸出,得用$?來判斷執行成功沒有,即有沒有過濾到想要的內容
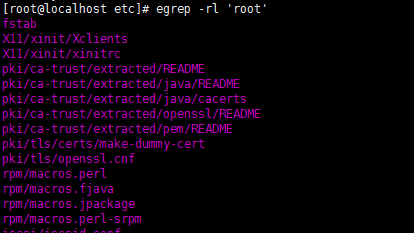
4,-l :如果匹配成功,則只將文件名打印出來,失敗則不打印,通常-rl一起用,grep -rl 'root' /etc
 ,
,
5,-A :如果匹配成功,則將匹配行及其后n行一起打印出來
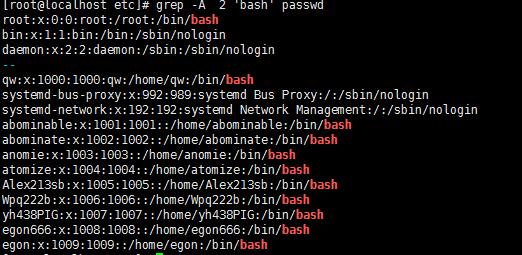
6,-B :如果匹配成功,則將匹配行及其前n行一起打印出來
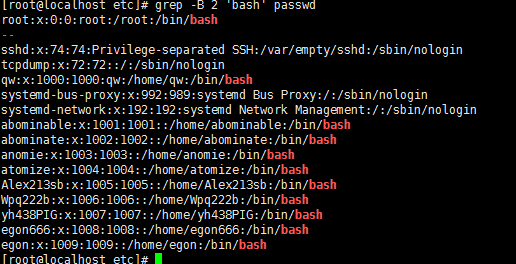
7,-C :如果匹配成功,則將匹配行及其前后n行一起打印出來
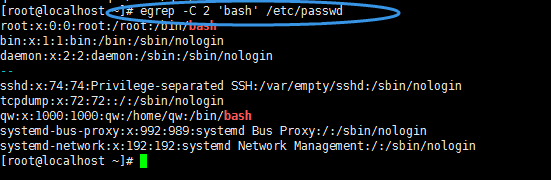
8,-c :如果匹配成功,則將匹配到的行數打印出來

9,-E :等于egrep,擴展
10,-i :忽略大小寫
11,-v :取反,不匹配
12,-w:匹配單詞
二:正則介紹
首先建a.txt。在進行驗證
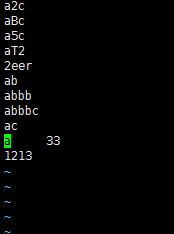
1,^ 行首
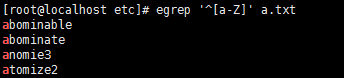
2,$行尾

3,.除了換行符以外的任意單個字符
4,*前導字符的零個或多個

5, .*所有字
6, []字符組內的任一字符

7,[^]對字符組內的每個字符取反(不匹配字符組內的每個字符)

8, ^[^]非字符組內的字符開頭的行

9,[a-z] 小寫字母
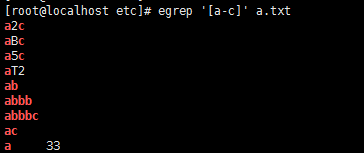
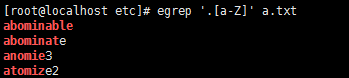
10,[A-Z] 大寫字母

11,[a-Z] 小寫和大寫字母
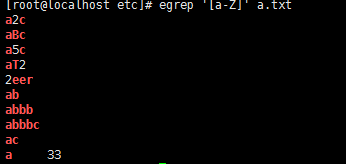
12,[0-9] 數字
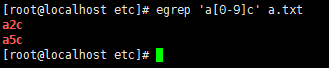
13,\<單詞頭 單詞一般以空格或特殊字符做分隔,連續的字符串被當做單詞
\>單詞尾


關于grep與正則表達式怎么在linux中使用就分享到這里了,希望以上內容可以對大家有一定的幫助,可以學到更多知識。如果覺得文章不錯,可以把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





