溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容介紹了“js中的正則表達式入門教程”的有關知識,在實際案例的操作過程中,不少人都會遇到這樣的困境,接下來就讓小編帶領大家學習一下如何處理這些情況吧!希望大家仔細閱讀,能夠學有所成!
什么是正則表達式呢?
正則表達式(regular expression)描述了一種字符串匹配的模式,可以用來檢查一個字符串是否含有某種子串、將匹配的子串做替換或者從某個字符串中取出符合某個條件的子串等。
先科普一下基本的知識
js中使用正則表達式,除了了解正則表達式基本的匹配規則外。還需要了解下面的基本的知識:
python,js,groovy這些腳本語言都有在線調試的網站,可以在線測試是否有語法錯誤,用起來也很方便。
var reg = new RegExp('\\d{8-20}')
reg.test(“11111111a”)
這里的\\,第一個\是轉義符,用于轉義。
上面的例子還可以寫成:
var reg = new RegExp(/\d{8-20}/)
reg.test(“11111111a”)
test可以測試字符串是否匹配正則表達是的規則,exec、match用于捕獲匹配的子串。
說白了正則表達式就是處理字符串的,我們可以用它來處理一些復雜的字符串。
我們直接用一個例子來說明
//找出這個字符串中的所有數字
var str = 'abc123de45fgh7789qqq111';
//方法1
function findNum(str) {
var tmp = '',
arr = [];
for (var i = 0; i < str.length; i++) {
var cur = str[i];
if (!isNaN(cur)) {
tmp += cur;
} else {
if (tmp) {
arr.push(tmp);
tmp = '';
}
}
}
if (tmp) {
arr.push(tmp)
}
return arr;
}
console.log(findNum(str))
//["123", "45", "6789", "111"]
//方法2 使用正則表達式
var reg = /\d+/g;
console.log(str.match(reg))
// ["123", "45", "6789", "111"]通過比較2種方法我們明顯看出在對字符串進行處理時,使用正則表達式會簡單許多,所以雖然正則表達式看起來像是火星文一樣的一堆亂碼的東西,但我們還是有必要去學習它的。
正則表達式的創建方式
1、字面量創建方式
2、實例創建方式
var reg = /pattern/flags // 字面量創建方式 var reg = new RegExp(pattern,flags); //實例創建方式 pattern:正則表達式 flags:標識(修飾符) 標識主要包括: 1. i 忽略大小寫匹配 2. m 多行匹配,即在到達一行文本末尾時還會繼續尋常下一行中是否與正則匹配的項 3. g 全局匹配 模式應用于所有字符串,而非在找到第一個匹配項時停止
字面量創建方式和構造函數創建方式的區別
字面量創建方式不能進行字符串拼接,實例創建方式可以
var regParam = 'cm'; var reg1 = new RegExp(regParam+'1'); var reg2 = /regParam/; console.log(reg1); // /cm1/ console.log(reg2); // /regParam/
字面量創建方式特殊含義的字符不需要轉義,實例創建方式需要轉義
var reg1 = new RegExp('\d'); // /d/
var reg2 = new RegExp('\\d') // /\d/
var reg3 = /\d/; // /\d/元字符
代表特殊含義的元字符
\d : 0-9之間的任意一個數字 \d只占一個位置
\w : 數字,字母 ,下劃線 0-9 a-z A-Z _
\s : 空格或者空白等
\D : 除了\d
\W : 除了\w
\S : 除了\s
. : 除了\n之外的任意一個字符
\ : 轉義字符
| : 或者
() : 分組
\n : 匹配換行符
\b : 匹配邊界 字符串的開頭和結尾 空格的兩邊都是邊界 => 不占用字符串位數
^ : 限定開始位置 => 本身不占位置
$ : 限定結束位置 => 本身不占位置
[a-z] : 任意字母 []中的表示任意一個都可以
[^a-z] : 非字母 []中^代表除了
[abc] : abc三個字母中的任何一個 [^abc]除了這三個字母中的任何一個字符
代表次數的量詞元字符
* : 0到多個
+ : 1到多個
? : 0次或1次 可有可無
{n} : 正好n次;
{n,} : n到多次
{n,m} : n次到m次
量詞出現在元字符后面 如\d+,限定出現在前面的元字符的次數
var str = '1223334444';
var reg = /\d{2}/g;
var res = str.match(reg);
console.log(res) //["12", "23", "33", "44", "44"]
var str =' 我是空格君 ';
var reg = /^\s+|\s+$/g; //匹配開頭結尾空格
var res = str.replace(reg,'');
console.log('('+res+')') //(我是空格君)正則中的()和[]和重復子項 //拿出來單獨說一下
一般[]中的字符沒有特殊含義 如+就表示+
但是像\w這樣的還是有特殊含義的
var str1 = 'abc'; var str2 = 'dbc'; var str3 = '.bc'; var reg = /[ab.]bc/; //此時的.就表示. reg.test(str1) //true reg.test(str2) //false reg.test(str3) //true
[]中,不會出現兩位數
[12]表示1或者2 不過[0-9]這樣的表示0到9 [a-z]表示a到z
例如:匹配從18到65年齡段所有的人
var reg = /[18-65]/; // 這樣寫對么
reg.test('50')
reg = /(18|19)|([2-5]\d)|(6[0-5])/;Uncaught SyntaxError: Invalid regular expression: /[18-65]/: Range out of order in character class 聰明的你想可能是8-6這里不對,于是改成[16-85]似乎可以匹配16到85的年齡段的,但實際上發現這也是不靠譜的實際上我們匹配這個18-65年齡段的正則我們要拆開來匹配我們拆成3部分來匹配 18-19 20-59 60-65
()的提高優先級功能:凡是有|出現的時候,我們一定要注意是否有必要加上()來提高優先級;
()的分組 重復子項 (兩個放到一起說)
分組:
只要正則中出現了小括號那么就會形成一份分組
只要有分組,exec(match)和replace中的結果就會發生改變(后邊的正則方法中再說)
分組的引用(重復子項) :
只要在正則中出現了括號就會形成一個分組,我們可以通過\n (n是數字代表的是第幾個分組)來引用這個分組,第一個小分組我們可以用\1來表示
例如:求出這個字符串'abAAbcBCCccdaACBDDabcccddddaab'中出現最多的字母,并求出出現多少次(忽略大小寫)。
var str = 'abbbbAAbcBCCccdaACBDDabcccddddaab';
str = str.toLowerCase().split('').sort(function(a,b){return a.localeCompare(b)}).join('');
var reg = /(\w)\1+/ig;
var maxStr = '';
var maxLen = 0;
str.replace(reg,function($0,$1){
var regLen = $0.length;
if(regLen>maxLen){
maxLen = regLen;
maxStr = $1;
}else if(maxLen == regLen){
maxStr += $1;
}
})
console.log(`出現最多的字母是${maxStr},共出現了${maxLen}次`)當我們加()只是為了提高優先級而不想捕獲小分組時,可以在()中加?:來取消分組的捕獲
var str = 'aaabbb'; var reg = /(a+)(?:b+)/; var res =reg.exec(str); console.log(res) //["aaabbb", "aaa", index: 0, input: "aaabbb"] //只捕獲第一個小分組的內容
正則運算符的優先級
正則表達式從左到右進行計算,并遵循優先級順序,這與算術表達式非常類似。
相同優先級的會從左到右進行運算,不同優先級的運算先高后低。
依次從最高到最低說明各種正則表達式運算符的優先級順序:
\ : 轉義符
(), (?:), (?=), [] => 圓括號和方括號
*, +, ?, {n}, {n,}, {n,m} => 量詞限定符
^, $, \任何元字符、任何字符
| => 替換,"或"操作
字符具有高于替換運算符的優先級,一般用 | 的時候,為了提高 | 的優先級,我們常用()來提高優先級
如: 匹配 food或者foot的時候 reg = /foo(t|d)/ 這樣來匹配
正則的特性
1、貪婪性
所謂的貪婪性就是正則在捕獲時,每一次會盡可能多的去捕獲符合條件的內容。
如果我們想盡可能的少的去捕獲符合條件的字符串的話,可以在量詞元字符后加?
2、懶惰性
懶惰性則是正則在成功捕獲一次后不管后邊的字符串有沒有符合條件的都不再捕獲。
如果想捕獲目標中所有符合條件的字符串的話,我們可以用標識符g來標明是全局捕獲
var str = '123aaa456'; var reg = /\d+/; //只捕獲一次,一次盡可能多的捕獲 var res = str.match(reg) console.log(res) // ["123", index: 0, input: "123aaa456"] reg = /\d+?/g; //解決貪婪性、懶惰性 res = str.match(reg) console.log(res) // ["1", "2", "3", "4", "5", "6"]
和正則相關的一些方法
這里我們只介紹test、exec、match和replace這四個方法
reg.test(str) 用來驗證字符串是否符合正則 符合返回true 否則返回false
var str = 'abc'; var reg = /\w+/; console.log(reg.test(str)); //true
reg.exec() 用來捕獲符合規則的字符串
var str = 'abc123cba456aaa789'; var reg = /\d+/; console.log(reg.exec(str)) // ["123", index: 3, input: "abc123cba456aaa789"]; console.log(reg.lastIndex) // lastIndex : 0 reg.exec捕獲的數組中 // [0:"123",index:3,input:"abc123cba456aaa789"] 0:"123" 表示我們捕獲到的字符串 index:3 表示捕獲開始位置的索引 input 表示原有的字符串
當我們用exec進行捕獲時,如果正則沒有加'g'標識符,則exec捕獲的每次都是同一個,當正則中有'g'標識符時 捕獲的結果就不一樣了,我們還是來看剛剛的例子
var str = 'abc123cba456aaa789'; var reg = /\d+/g; //此時加了標識符g console.log(reg.lastIndex) // lastIndex : 0 console.log(reg.exec(str)) // ["123", index: 3, input: "abc123cba456aaa789"] console.log(reg.lastIndex) // lastIndex : 6 console.log(reg.exec(str)) // ["456", index: 9, input: "abc123cba456aaa789"] console.log(reg.lastIndex) // lastIndex : 12 console.log(reg.exec(str)) // ["789", index: 15, input: "abc123cba456aaa789"] console.log(reg.lastIndex) // lastIndex : 18 console.log(reg.exec(str)) // null console.log(reg.lastIndex) // lastIndex : 0
每次調用exec方法時,捕獲到的字符串都不相同
lastIndex :這個屬性記錄的就是下一次捕獲從哪個索引開始。
當未開始捕獲時,這個值為0。
如果當前次捕獲結果為null。那么lastIndex的值會被修改為0.下次從頭開始捕獲。
而且這個lastIndex屬性還支持人為賦值。
exec的捕獲還受分組()的影響
var str = '2017-01-05'; var reg = /-(\d+)/g // ["-01", "01", index: 4, input: "2017-01-05"] "-01" : 正則捕獲到的內容 "01" : 捕獲到的字符串中的小分組中的內容
str.match(reg) 如果匹配成功,就返回匹配成功的數組,如果匹配不成功,就返回null
//match和exec的用法差不多 var str = 'abc123cba456aaa789'; var reg = /\d+/; console.log(reg.exec(str)); //["123", index: 3, input: "abc123cba456aaa789"] console.log(str.match(reg)); //["123", index: 3, input: "abc123cba456aaa789"]
上邊兩個方法console的結果有什么不同呢?二個字符串是一樣滴。
當我們進行全局匹配時,二者的不同就會顯現出來了.
var str = 'abc123cba456aaa789'; var reg = /\d+/g; console.log(reg.exec(str)); // ["123", index: 3, input: "abc123cba456aaa789"] console.log(str.match(reg)); // ["123", "456", "789"]
當全局匹配時,match方法會一次性把符合匹配條件的字符串全部捕獲到數組中,
如果想用exec來達到同樣的效果需要執行多次exec方法。
我們可以嘗試著用exec來簡單模擬下match方法的實現。
String.prototype.myMatch = function (reg) {
var arr = [];
var res = reg.exec(this);
if (reg.global) {
while (res) {
arr.push(res[0]);
res = reg.exec(this)
}
}else{
arr.push(res[0]);
}
return arr;
}
var str = 'abc123cba456aaa789';
var reg = /\d+/;
console.log(str.myMatch(reg))
// ["123"]
var str = 'abc123cba456aaa789';
var reg = /\d+/g;
console.log(str.myMatch(reg))
// ["123", "456", "789"]此外,match和exec都可以受到分組()的影響,不過match只在沒有標識符g的情況下才顯示小分組的內容,如果有全局g,則match會一次性全部捕獲放到數組中
var str = 'abc'; var reg = /(a)(b)(c)/; console.log( str.match(reg) ); // ["abc", "a", "b", "c", index: 0, input: "abc"] console.log( reg.exec(str) ); // ["abc", "a", "b", "c", index: 0, input: "abc"] 當有全局g的情況下 var str = 'abc'; var reg = /(a)(b)(c)/g; console.log( str.match(reg) ); // ["abc"] console.log( reg.exec(str) ); // ["abc", "a", "b", "c", index: 0, input: "abc"]
str.replace() 這個方法大家肯定不陌生,現在我們要說的就是和這個方法和正則相關的東西了。
正則去匹配字符串,匹配成功的字符去替換成新的字符串
寫法:str.replace(reg,newStr);
var str = 'a111bc222de';
var res = str.replace(/\d/g,'Q')
console.log(res)
// "aQQQbcQQQde"
//replace的第二個參數也可以是一個函數
str.replace(reg,fn);
var str = '2017-01-06';
str = str.replace(/-\d+/g,function(){
console.log(arguments)
})
//控制臺打印結果:
["-01", 4, "2017-01-06"]
["-06", 7, "2017-01-06"]
"2017undefinedundefined"
//從打印結果我們發現每一次輸出的值似乎跟exec捕獲時很相似,既然與exec似乎很相似,那么似乎也可以打印出小分組中的內容嘍
var str = '2017-01-06';
str = str.replace(/-(\d+)/g,function(){
console.log(arguments)
})
["-01", "01", 4, "2017-01-06"]
["-06", "06", 7, "2017-01-06"]
"2017undefinedundefined"
//從結果看來我們的猜測沒問題。此外,我們需要注意的是,如果我們需要替換replace中正則找到的字符串,函數中需要一個返回值去替換正則捕獲的內容。
通過replace方法獲取url中的參數的方法
(function(pro){
function queryString(){
var obj = {},
reg = /([^?&#+]+)=([^?&#+]+)/g;
this.replace(reg,function($0,$1,$2){
obj[$1] = $2;
})
return obj;
}
pro.queryString = queryString;
}(String.prototype));
// 例如 url為 https://www.baidu.com?a=1&b=2
// window.location.href.queryString();
// {a:1,b:2}用于查找在某些內容(但并不包括這些內容)之前或之后的東西,如\b,^,$那樣用于指定一個位置,這個位置應該滿足一定的條件(即斷言),因此它們也被稱為零寬斷言。
在使用正則表達式時,捕獲的內容前后必須是特定的內容,而我們又不想捕獲這些特定內容的時候,零寬斷言就可以派上用場了。
零寬度正預測先行斷言 (?=exp)
零寬度負預測先行斷言 (?!exp)
零寬度正回顧后發斷言 (?<=exp)
零寬度負回顧后發斷言 (?<!exp)
這四胞胎看著名字好長,給人一種好復雜好難的感覺,我們還是挨個來看看它們究竟是干什么的吧。
(?=exp) 這個簡單理解就是說字符出現的位置的右邊必須匹配到exp這個表達式。
var str = "i'm singing and dancing"; var reg = /\b(\w+(?=ing\b))/g var res = str.match(reg); console.log(res) // ["sing", "danc"]
注意一點,這里說到的是位置,不是字符。
var str = 'abc'; var reg = /a(?=b)c/; console.log(res.test(str)); // false // 這個看起來似乎是正確的,實際上結果是false
reg中a(?=b)匹配字符串'abc' 字符串a的右邊是b這個匹配沒問題,接下來reg中a(?=b)后邊的c匹配字符串時是從字符串'abc'中a的后邊b的前邊的這個位置開始匹配的,
這個相當于/ac/匹配'abc',顯然結果是false了
(?!exp) 這個就是說字符出現的位置的右邊不能是exp這個表達式。
var str = 'nodejs'; var reg = /node(?!js)/; console.log(reg.test(str)) // false
(?<=exp) 這個就是說字符出現的位置的前邊是exp這個表達式。
var str = '¥998$888'; var reg = /(?<=\$)\d+/; console.log(reg.exec(str)) //888
(?<!exp) 這個就是說字符出現的位置的前邊不能是exp這個表達式。
var str = '¥998$888'; var reg = /(?<!\$)\d+/; console.log(reg.exec(str)) //998
最后,來一張思維導圖
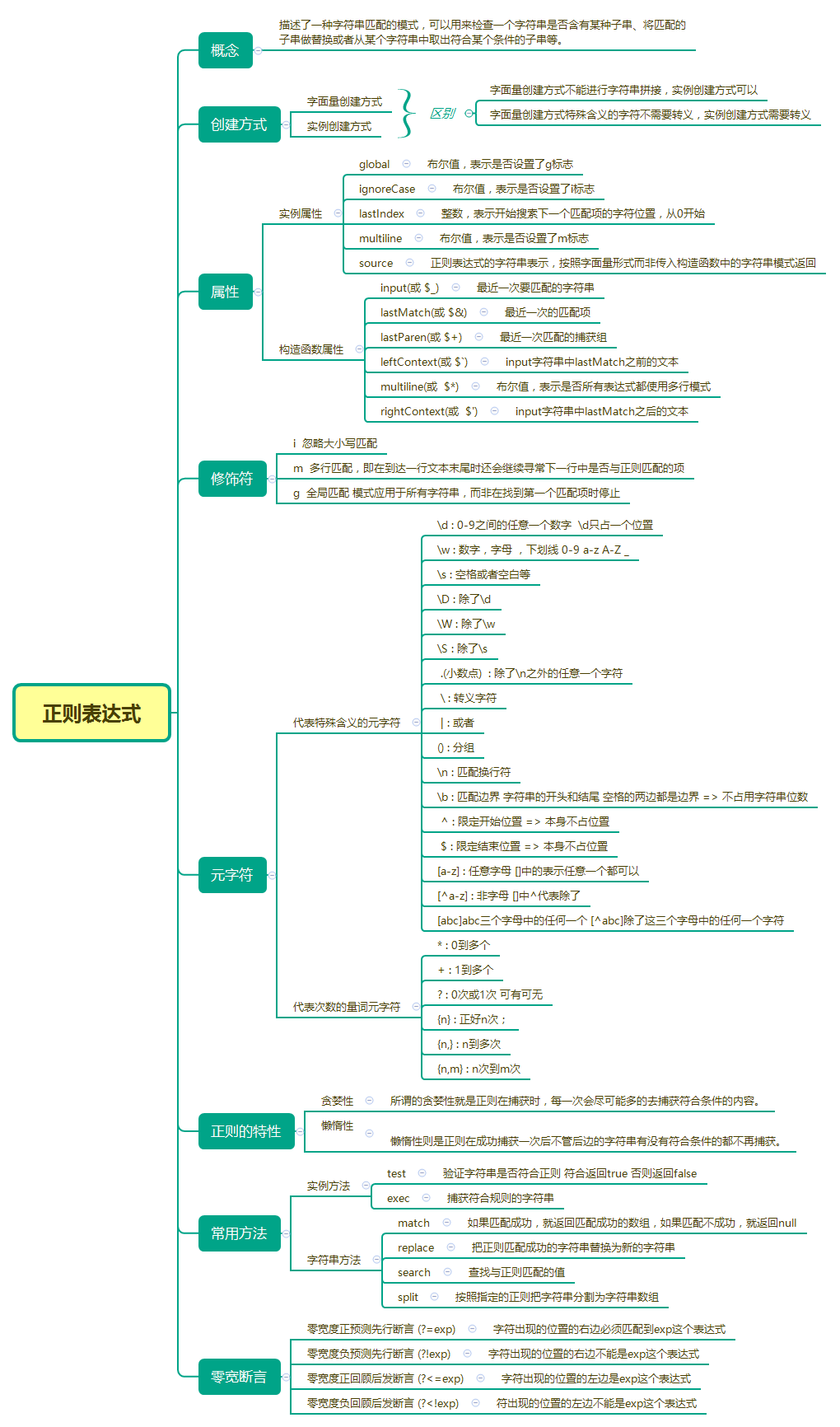
“js中的正則表達式入門教程”的內容就介紹到這里了,感謝大家的閱讀。如果想了解更多行業相關的知識可以關注億速云網站,小編將為大家輸出更多高質量的實用文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





