溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本文轉載自《金融電子化》
原文鏈接:https://mp.weixin.qq.com/s/WGG91Rv9QTBHPsNVPG8Z5g
隨著移動互聯網的迅猛發展,分布式架構在互聯網IT技術領域廣泛應用并積累了大量實踐經驗。在互聯網金融快速發展和利率市場化的大環境下,建設能夠支持海量客戶、具有彈性擴展能力、高效靈活的分布式架構應用系統已成為國內金融行業迫切的需要。
分布式數據庫應用大勢所趨
我社普惠金融平臺建設,旨在“充分運用金融科技手段,優化信貸流程和客戶評價模型,降低企業融資成本,紓解民營企業、小微企業融資難融資貴問題,增強金融服務實體經濟能力”。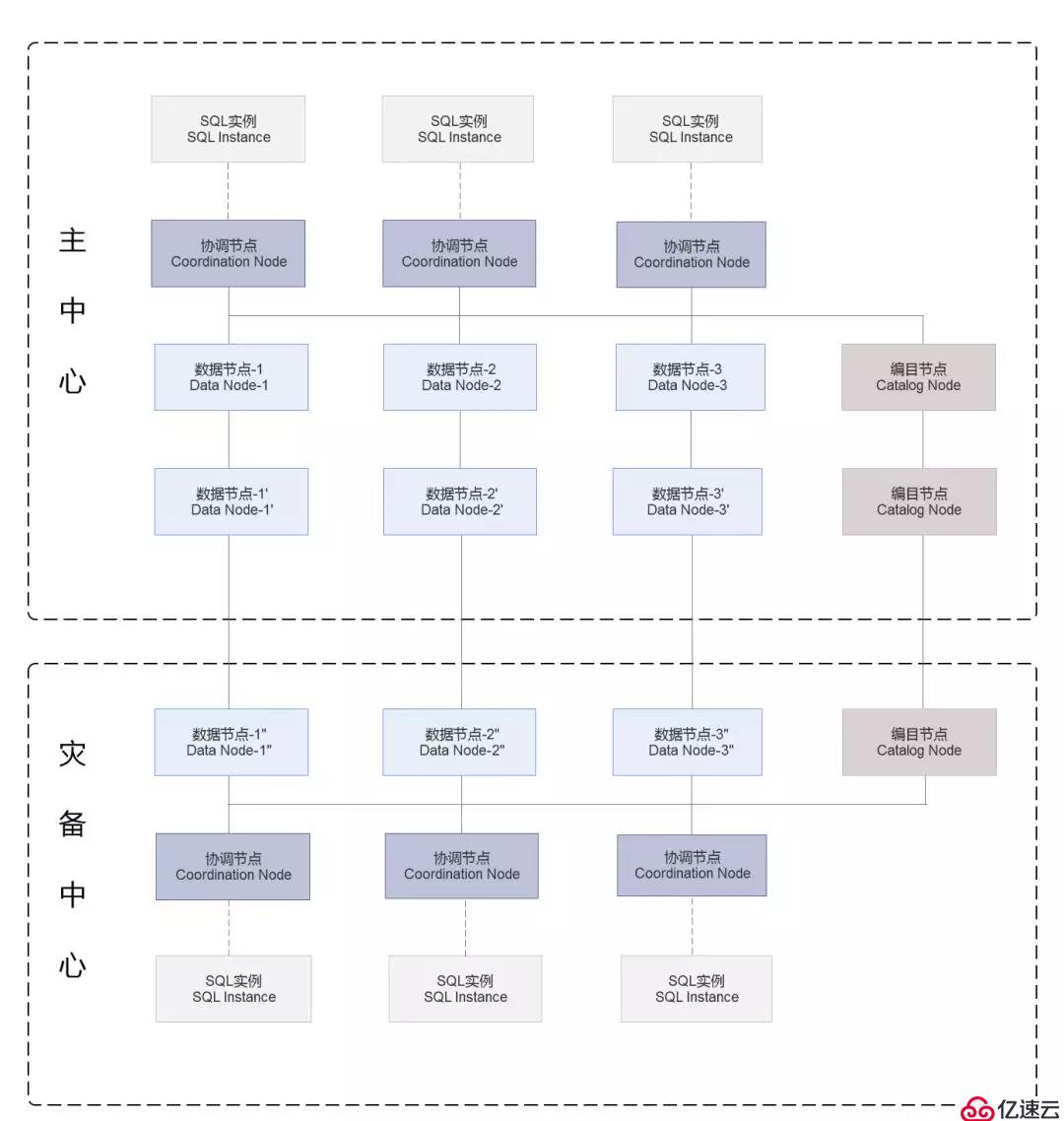
普惠金融服務是典型的互聯網應用,其與傳統信貸系統不同,具有互聯網場景接入能力,如果沿用集中式的技術架構,在應對海量客戶的互聯網應用場景和總擁有成本等方面存在以下的潛在問題:
集中式架構普遍缺乏彈性伸縮的能力。隨著交易量和數據量的增長,系統整體吞吐量會遇到硬件或技術的瓶頸。尤其在支持面向互聯網客戶相關業務時,不能有效處理瞬時爆發的高并發交易,制約了客戶獲取以及大規模業務營銷。
集中式架構采用單體應用設計。軟件開發和運行管理的最小單元是應用,管理力度較粗,容易“牽一發而動全身”,應用的開發過程不易踐行輕量化敏捷開發理念,系統在運行過程中容易出現單點故障,難以有效進行故障隔離。
集中式架構系統的基礎設施通常使用高端服務器和存儲設備,以及傳統關系型數據庫。硬件和軟件采購成本高,開發和運維主要依賴于服務廠商,服務成本高,也無法做到完全自主掌控。
技術體系封閉,技術的發展高度依賴于廠商,特別是依賴國外廠商,商業銀行的IT團隊缺乏自主可控能力,在一定程度上存在信息安全風險。
我社在規劃新一代普惠金融平臺建設時,從戰略高度對上述問題進行深入分析與思考,立足長遠發展規劃,從橫縱兩個角度看待該分布式系統的研發,即在數據方面著眼于分布式數據庫,在功能層面則引入微服務架構,進而真正實現全方位分布式框架的金融服務底層系統。同時,響應國家對技術自主可控的要求,選擇國產分布式數據庫,有效控制IT成本和實現技術自主可控。
國產分布式數據庫應用實踐
普惠金融平臺與傳統業務系統不同,具有互聯網場景接入能力,獲客方式發生了變化。為了滿足客戶申請貸款的爆發式增長,在審批方式和流程上有所改變,對企業征信和智能風控的要求更高。隨著細分領域競爭的加劇,平臺應用需要不斷調整、隨時迭代。
經過仔細而嚴格的評選,最終我社采用國產分布式數據庫—SequoiaDB巨杉數據庫作為底層分布式數據庫平臺。
平臺應用利用分布式數據庫計算-存儲層分離技術,將協議解析、計算等模塊與底層存儲解耦,存儲層通過多維分區實現彈性擴張,計算層采用無狀態設計,獨立部署,通過動態增加數據庫實例線性提升計算能力,有效應對瞬時爆發的高并發海量交易,分布式數據庫平臺同時完整兼容MySQL、PosgreSQL和SparkSQL針對應用提供較高兼容性。
平臺應用開發基于Spring Cloud微服務框架,業務邏輯從傳統的單一中間件被拆解成眾多微服務組件,分布式數據庫實例服務層提供了可選擇、可適配、可動態伸縮的標準數據庫計算引擎,可根據應用的場景靈活選擇。應用開發采用數據庫分布式計算引擎,面向聯機交易的業務場景,采用兼容MySQL的計算實例,批處理業務場景選用兼容SparkSQL的計算實例。實例通過訪問分布式數據庫不同的數據副本,實現對數據的并行處理和多元利用(一份數據,多種用途)。
以下是聯機業務應用分布式數據庫的幾個技術要點:
1.分布式架構下的應用設計
分布式數據庫的核心機制即是將海量數據通過某種算法切分到一個或多個分區中。每個數據分區可以使用不同的物理服務器,通過網絡設備將服務器連接到一起,以構成一個邏輯上對外統一的數據庫服務。因此,如何將數據進行均勻切分、如何在切分后對數據進行快速檢索,是分布式策略必須優先保障的內容。
分布式數據庫切分規則包括:
(1)散列分區:散列分區指的是在數據寫入的過程中,針對指定分區字段的值進行散列后,判斷其數據物理存放分區的規則。
?(2)范圍分區:范圍分區指的是在數據寫入的過程中,針對指定分區字段的值判斷其所在范圍,根據數據所在范圍對應的數據分區,判斷其物理位置的規則。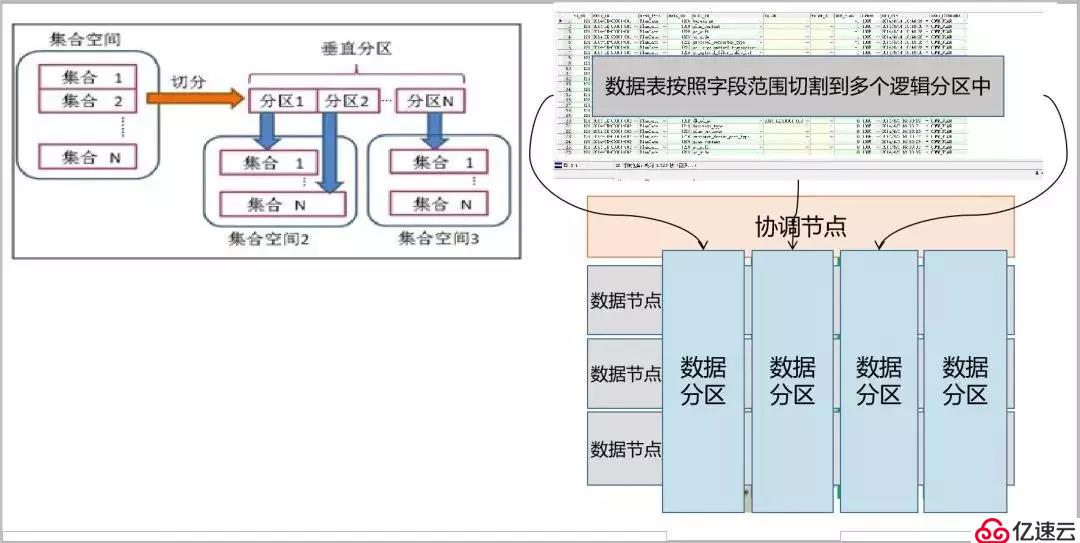
?(3)多維混合分區:多維混合分區是散列分區與范圍分區的結合。在多維混合分區中,用戶在建表時可以指定兩個不同的字段,首先根據第一個字段進行范圍的判定,之后再根據第二個字段在該范圍所對應的一系列物理服務器中進行散列判斷其位置。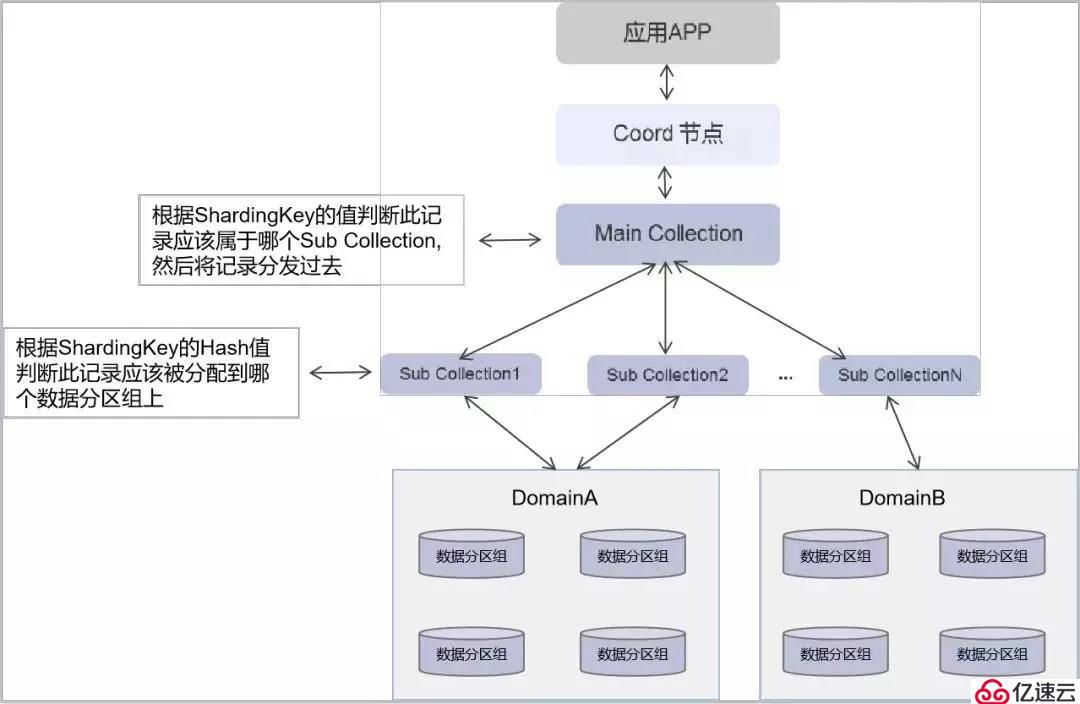
在我社新一代普惠金融服務平臺項目中,對于數據庫表結構的設計面向數據特征有針對性地定義分區字段與規則。在實踐的過程中,極大提升應用的效率與并發能力,避免了傳統架構中數據庫成為瓶頸與熱點的問題。
2.分布式微服務架構下的數據一致性保證
在利用分布式數據庫系統實現底層業務支撐時,會帶來很多傳統集中式數據庫無法比擬的特性,例如:分布式容錯能力、彈性可擴展能力等,這些都是對銀行等金融行業來說至關重要的優化因素。分布式數據庫系統之所以能夠具有這些能力,主要是因為它的分布式存儲特性,即每個節點保存完整數據庫的一部分,而在其它若干節點上部署它的副本。那么,為了實現這樣的分布式數據庫系統,使之發揮應有的能力,很重要的一環就是在于它的一致性策略。
在實踐的過程中,我社重點研究并解決了行業內公認的分布式環境下端到端數據一致性與數據安全的難題:
(1)利用柔性事務保證微服務之間的數據一致性;
通過平臺對分布式數據庫在銀行領域應用策略的研究,深入了解分布式底層技術,利用柔性事務TCC實現微服務之間數據一致性。普惠金融平臺應用開發基于Spring Cloud微服務框架,應用程序微服務開發規范明確了每組微服務必須提供try-confirm-cancel接口,遵循對微服務的分布式事務所提出的RESTful TCC解決方案,結合Spring Cloud Netflix和分布式柔性事務實現微服務之間的數據一致性。
(2)在微服務內部,通過分布式數據庫技術實現自動化事務一致性保障;
結合普惠金融系統業務數據的特點,合理運用數據多維分區策略,并利用分布式數據庫技術,在兩階段提交(2PC)基礎之上,針對異常故障場景,實現自動化的事務一致性保障。
為了保證數據的一致性,需要維護一個全局唯一性的ID來區別并發的事務,標識產生或變更的數據,實現這樣一個全局唯一的ID通常結合事務發起的時間,依賴時間戳加上其他的一些標識位。國產分布式數據系統,專門設計了一套全分布的邏輯時鐘機制,避免了強制所有參與節點從GTM中獲取唯一ID的步驟,同時又能滿足分布式存儲和處理的要求。
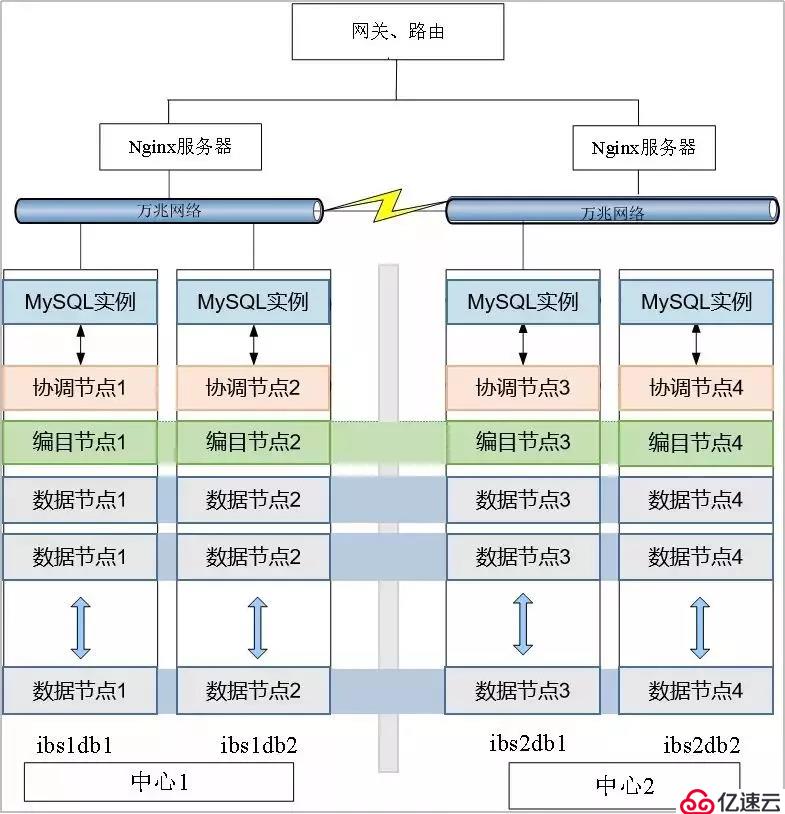
3.分布式數據庫跨同城數據中心部署
基于分布式數據庫完善的多副本數據同步機制,實現跨同城雙中心部署,支持數據的容災與高可用,實現新一代普惠金融平臺應用跨數據中心運行,當主中心出現災難時,數據零丟失,分布式數據庫自動容災切換,對應用系統完全透明。下圖是省聯社普惠金融平臺分布式數據庫應用的雙活部署示意圖:
?
項目創新成果
1.分布式架構轉型與金融國產化
分布式數據庫提供靈活、彈性、便捷、融合的數據服務能力,應對瞬時爆發型業務量增長,與微服務架構相結合,為應用的敏捷迭代開發打下了良好的基礎,快速推出創新、差異化、跨界的金融服務和產品。
利用國產分布式數據庫巨杉數據庫,對底層代碼完全自主可控,替換國外數據庫產品,避免核心技術的綁定,從軟件與硬件兩個方面、性能和效率兩個層面、短期應用的戰術最優化和長遠發展的戰略最優化兩個角度實現了整體的全面提升。另外,考慮到異地災備,通過分布式數據與應用相結合的多活部署與實踐,為各地農信社和其它金融機構未來多活數據中心建設探索出了一條切實可行的道路。
2.分布式環境下端到端數據一致性
在實踐的過程中,我社重點研究并解決了行業內公認的分布式環境下端到端數據一致性與數據安全的難題:(1)利用柔性事務保證微服務之間的數據一致性;(2)在微服務內部,通過分布式數據庫技術實現自動化事務一致性保障;(3)利用分布式數據庫多活體系解決跨數據中心數據一致性與高可用問題。
在虛擬化云環境中微服務框架下,我社完成了分布式系統的多層次數據一致性,進而實現了高效彈性易擴展、事務處理的最終一致性、微服務級別的數據保障以及多活異地容災等優良的特性,為金融科技背景下銀行等金融系統的進一步升級與改革提供了強大動力和發展潛力。
3.實現社會與經濟效益最大化
我社對互聯網融資行業進行了深入調研,將互聯網融資業務的共性進行提煉,基于建彈性多層次混合平臺系統推出了一個強大穩定的集客戶賬戶、產品創新、全周期核算、業務自動化審批、智能風控等為一體的普惠金融平臺。該平臺為客戶提供差異化配置金融服務,完成互聯網跨界的產品整合、服務交互、產品核算等功能。不僅提供了全方位的一攬子普惠金融、互聯網融資服務,而且為企業互聯網金融業務的快速發展奠定了堅實的基礎。
?
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





