溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
今天就跟大家聊聊有關python爬蟲怎么利用spider抓取程序,可能很多人都不太了解,為了讓大家更加了解,小編給大家總結了以下內容,希望大家根據這篇文章可以有所收獲。
spider抓取程序:
在貼上代碼之前,先對抓取的頁面和鏈接做一個分析:
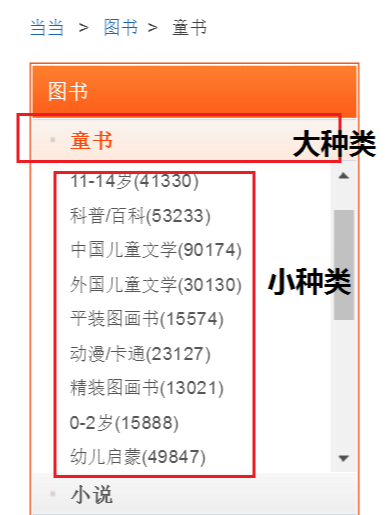
網址:http://category.dangdang.com/pg4-cp01.25.17.00.00.00.html
這個是當當網圖書的鏈接,經過分析發現:大種類的id號對應 cp01.25 中的25,小種類對應id號中的第三個 17,pg4代表大種類 —>小種類下圖書的第17頁信息。
為了在抓取圖書信息的同時找到這本圖書屬于哪一大種類下的小種類的歸類信息,我們需要分三步走,第一步:大種類劃分,在首頁找到圖書各大種類名稱和對應的id號;第二步,根據大種類id號生成的鏈接,找到每個大種類下的二級子種類名稱,及對應的id號;第三步,在大種類 —>小種類的歸類下抓取每本圖書信息。
分步驟介紹下:
1、我們繼承RedisSpider作為父類,start_urls作為初始鏈接,用于請求首頁圖書數據
# -*- coding: utf-8 -*-
import scrapy
import requests
from scrapy import Selector
from lxml import etree
from ..items import DangdangItem
from scrapy_redis.spiders import RedisSpider
class DangdangSpider(RedisSpider):
name = 'dangdangspider'
redis_key = 'dangdangspider:urls'
allowed_domains = ["dangdang.com"]
start_urls = 'http://category.dangdang.com/cp01.00.00.00.00.00.html'
def start_requests(self):
user_agent = 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.22 \
Safari/537.36 SE 2.X MetaSr 1.0'
headers = {'User-Agent': user_agent}
yield scrapy.Request(url=self.start_urls, headers=headers, method='GET', callback=self.parse)2、在首頁中抓取大種類的名稱和id號,其中yield回調函數中傳入的meta值為本次匹配出的大種類的名稱和id號
def parse(self, response):
user_agent = 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.22 \
Safari/537.36 SE 2.X MetaSr 1.0'
headers = {'User-Agent': user_agent}
lists = response.body.decode('gbk')
selector = etree.HTML(lists)
goodslist = selector.xpath('//*[@id="leftCate"]/ul/li')
for goods in goodslist:
try:
category_big = goods.xpath('a/text()').pop().replace(' ','') # 大種類
category_big_id = goods.xpath('a/@href').pop().split('.')[1] # id
category_big_url = "http://category.dangdang.com/pg1-cp01.{}.00.00.00.00.html".\
format(str(category_big_id))
# print("{}:{}".format(category_big_url,category_big))
yield scrapy.Request(url=category_big_url, headers=headers,callback=self.detail_parse,
meta={"ID1":category_big_id,"ID2":category_big})
except Exception:
Pass3、根據傳入的大種類的id號抓取每個大種類下的小種類圖書標簽,yield回調函數中傳入的meta值為大種類id號和小種類id號
def detail_parse(self, response):
ID1:大種類ID ID2:大種類名稱 ID3:小種類ID ID4:小種類名稱
url = 'http://category.dangdang.com/pg1-cp01.{}.00.00.00.00.html'.format(response.meta["ID1"])
category_small = requests.get(url)
contents = etree.HTML(category_small.content.decode('gbk'))
goodslist = contents.xpath('//*[@class="sort_box"]/ul/li[1]/div/span')
for goods in goodslist:
try:
category_small_name = goods.xpath('a/text()').pop().replace(" ","").split('(')[0]
category_small_id = goods.xpath('a/@href').pop().split('.')[2]
category_small_url = "http://category.dangdang.com/pg1-cp01.{}.{}.00.00.00.html".\
format(str(response.meta["ID1"]),str(category_small_id))
yield scrapy.Request(url=category_small_url, callback=self.third_parse, meta={"ID1":response.meta["ID1"],\
"ID2":response.meta["ID2"],"ID3":category_small_id,"ID4":category_small_name})
# print("============================ {}".format(response.meta["ID2"])) # 大種類名稱
# print(goods.xpath('a/text()').pop().replace(" ","").split('(')[0]) # 小種類名稱
# print(goods.xpath('a/@href').pop().split('.')[2]) # 小種類ID
except Exception:
Pass4、抓取各大種類——>小種類下的圖書信息
def third_parse(self,response):
for i in range(1,101):
url = 'http://category.dangdang.com/pg{}-cp01.{}.{}.00.00.00.html'.format(str(i),response.meta["ID1"],\
response.meta["ID3"])
try:
contents = requests.get(url)
contents = etree.HTML(contents.content.decode('gbk'))
goodslist = contents.xpath('//*[@class="list_aa listimg"]/li')
for goods in goodslist:
item = DangdangItem()
try:
item['comments'] = goods.xpath('div/p[2]/a/text()').pop()
item['title'] = goods.xpath('div/p[1]/a/text()').pop()
item['time'] = goods.xpath('div/div/p[2]/text()').pop().replace("/", "")
item['price'] = goods.xpath('div/p[6]/span[1]/text()').pop()
item['discount'] = goods.xpath('div/p[6]/span[3]/text()').pop()
item['category1'] = response.meta["ID4"] # 種類(小)
item['category2'] = response.meta["ID2"] # 種類(大)
except Exception:
pass
yield item
except Exception:
pass看完上述內容,你們對python爬蟲怎么利用spider抓取程序有進一步的了解嗎?如果還想了解更多知識或者相關內容,請關注億速云行業資訊頻道,感謝大家的支持。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





