溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
Python垃圾回收機制的案例分析?這個問題可能是我們日常學習或工作經常見到的。希望通過這個問題能讓你收獲頗深。下面是小編給大家帶來的參考內容,讓我們一起來看看吧!
引用計數器為主、分代碼回收和標記清除為輔
在Python的C源碼中有一個名為refchain的環狀雙向鏈表,這個鏈表比較牛逼了,因為Python程序中一旦創建對象都會把這個對象添加到refchain這個鏈表中。也就是說他保存著所有的對象。
age = 18number = age # 對象18的引用計數器 + 1del age # 對象18的引用計數器 - 1def run(arg):
print(arg)
run(number) # 剛開始執行函數時,對象18引用計數器 + 1,當函數執行完畢之后,對象18引用計數器 - 1 。num_list = [11,22,number] # 對象18的引用計數器 + 1復制代碼基于引用計數器進行垃圾回收非常方便和簡單,但他還是存在循環引用的問題,導致無法正常的回收一些數據,例如:
v1 = [11,22,33] # refchain中創建一個列表對象,由于v1=對象,所以列表引對象用計數器為1.v2 = [44,55,66] # refchain中再創建一個列表對象,因v2=對象,所以列表對象引用計數器為1.v1.append(v2) # 把v2追加到v1中,則v2對應的[44,55,66]對象的引用計數器加1,最終為2.v2.append(v1) # 把v1追加到v1中,則v1對應的[11,22,33]對象的引用計數器加1,最終為2.del v1 # 引用計數器-1del v2 # 引用計數器-1復制代碼
標記清除:創建特殊鏈表專門用于保存 列表、元組、字典、集合、自定義類等對象,之后再去檢查這個鏈表中的對象是否存在循環引用,如果存在則讓雙方的引用計數器均 - 1 。
分代回收:對標記清除中的鏈表進行優化,將那些可能存在循引用的對象拆分到3個鏈表,鏈表稱為:0/1/2三代,每代都可以存儲對象和閾值,當達到閾值時,就會對相應的鏈表中的每個對象做一次掃描,除循環引用各自減1并且銷毀引用計數器為0的對象。
// 分代的C源碼#define NUM_GENERATIONS 3struct gc_generation generations[NUM_GENERATIONS] = { /* PyGC_Head, threshold, count */
{{(uintptr_t)_GEN_HEAD(0), (uintptr_t)_GEN_HEAD(0)}, 700, 0}, // 0代
{{(uintptr_t)_GEN_HEAD(1), (uintptr_t)_GEN_HEAD(1)}, 10, 0}, // 1代
{{(uintptr_t)_GEN_HEAD(2), (uintptr_t)_GEN_HEAD(2)}, 10, 0}, // 2代};復制代碼特別注意:0代和1、2代的threshold和count表示的意義不同。
0代,count表示0代鏈表中對象的數量,threshold表示0代鏈表對象個數閾值,超過則執行一次0代掃描檢查。 1代,count表示0代鏈表掃描的次數,threshold表示0代鏈表掃描的次數閾值,超過則執行一次1代掃描檢查。 2代,count表示1代鏈表掃描的次數,threshold表示1代鏈表掃描的次數閾值,超過則執行一2代掃描檢查。
根據C語言底層并結合圖來講解內存管理和垃圾回收的詳細過程。
第一步:當創建對象age=19時,會將對象添加到refchain鏈表中。
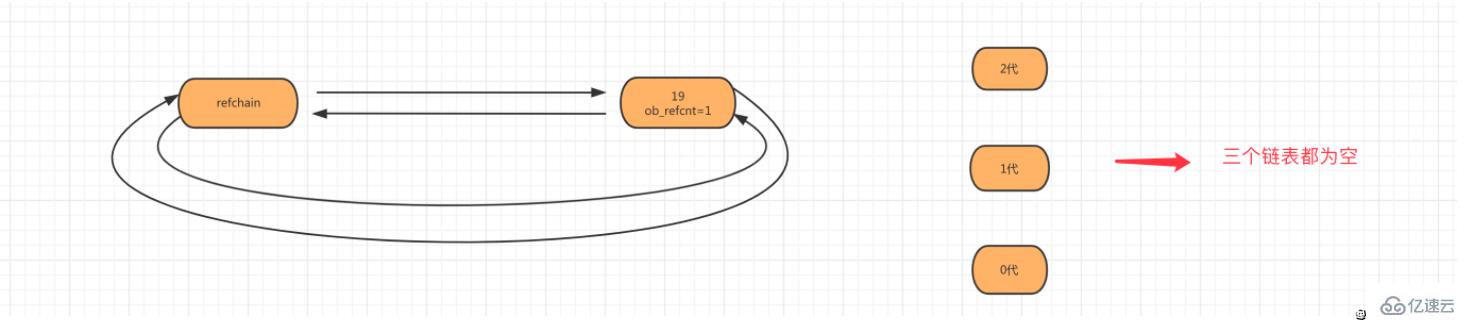
第二步:當創建對象num_list = [11,22]時,會將列表對象添加到 refchain 和 generations 0代中。
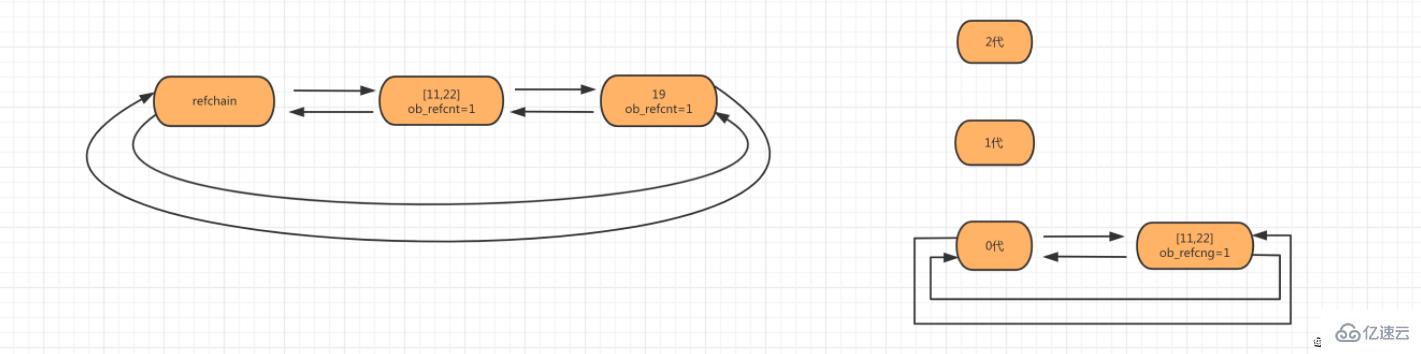
第三步:新創建對象使generations的0代鏈表上的對象數量大于閾值700時,要對鏈表上的對象進行掃描檢查。
當0代大于閾值后,底層不是直接掃描0代,而是先判斷2、1是否也超過了閾值。
對拼接起來的鏈表在進行掃描時,主要就是剔除循環引用和銷毀垃圾,詳細過程為:
至此,垃圾回收的過程結束。
從上文大家可以了解到當對象的引用計數器為0時,就會被銷毀并釋放內存。而實際上他不是這么的簡單粗暴,因為反復的創建和銷毀會使程序的執行效率變低。Python中引入了“緩存機制”機制。
例如:引用計數器為0時,不會真正銷毀對象,而是將他放到一個名為 free_list 的鏈表中,之后會再創建對象時不會在重新開辟內存,而是在free_list中將之前的對象來并重置內部的值來使用。
v1 = 3.14 # 開辟內存來存儲float對象,并將對象添加到refchain鏈表。 print( id(v1) ) # 內存地址:4436033488 del v1 # 引用計數器-1,如果為0則在rechain鏈表中移除,不銷毀對象,而是將對象添加到float的free_list. v2 = 9.999 # 優先去free_list中獲取對象,并重置為9.999,如果free_list為空才重新開辟內存。 print( id(v2) ) # 內存地址:4436033488 # 注意:引用計數器為0時,會先判斷free_list中緩存個數是否滿了,未滿則將對象緩存,已滿則直接將對象銷毀。復制代碼
v1 = 38 # 去小數據池small_ints中獲取38整數對象,將對象添加到refchain并讓引用計數器+1。 print( id(v1)) #內存地址:4514343712 v2 = 38 # 去小數據池small_ints中獲取38整數對象,將refchain中的對象的引用計數器+1。 print( id(v2) ) #內存地址:4514343712 # 注意:在解釋器啟動時候-5~256就已經被加入到small_ints鏈表中且引用計數器初始化為1, # 代碼中使用的值時直接去small_ints中拿來用并將引用計數器+1即可。另外,small_ints中的數據引用計數器永遠不會為0 # (初始化時就設置為1了),所以也不會被銷毀。復制代碼
v1 = "A" print( id(v1) ) # 輸出:4517720496 del v1 v2 = "A" print( id(v1) ) # 輸出:4517720496 # 除此之外,Python內部還對字符串做了駐留機制,針對只含有字母、數字、下劃線的字符串(見源碼Objects/codeobject.c),如果 # 內存中已存在則不會重新在創建而是使用原來的地址里(不會像free_list那樣一直在內存存活,只有內存中有才能被重復利用)。 v1 = "asdfg" v2 = "asdfg" print(id(v1) == id(v2)) # 輸出:True復制代碼
list類型,維護的free_list數組最多可緩存80個list對象。
v1 = [11,22,33] print( id(v1) ) # 輸出:4517628816del v1 v2 = ["你","好"] print( id(v2) ) # 輸出:4517628816復制代碼
v1 = (1,2)
print( id(v1) )del v1 # 因元組的數量為2,所以會把這個對象緩存到free_list[2]的鏈表中。v2 = ("哈哈哈","Alex") # 不會重新開辟內存,而是去free_list[2]對應的鏈表中拿到一個對象來使用。print( id(v2) )復制代碼 v1 = {"k1":123}
print( id(v1) ) # 輸出:4515998128
del v1
v2 = {"name":"哈哈哈","age":18,"gender":"男"}
print( id(v1) ) # 輸出:4515998128復制代碼C語言源碼底層分析
感謝各位的閱讀!看完上述內容,你們對Python垃圾回收機制的案例分析大概了解了嗎?希望文章內容對大家有所幫助。如果想了解更多相關文章內容,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





