溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
Node服務中監控本地環境及生產環境內存變化的方法?這個問題可能是我們日常學習或工作經常見到的。希望通過這個問題能讓你收獲頗深。下面是小編給大家帶來的參考內容,讓我們一起來看看吧!
當使用 Node 在生產環境作為服務器語言時,并發量過大或者代碼問題造成 OOM (out of memory) 或者 CPU 滿載這些都是服務器中常見的問題,此時通過監控 CPU 及內存,再結合日志及 Release 就很容易發現問題。
本章將介紹如何監控本地環境及生產環境的內存變化
所以,如何動態監控一個 Node 進程的內存變化呢?
以下是一個 Node Server 的示例,并且是一個有內存泄漏問題的示例,并且是山月在生產環境定位了很久的問題的精簡版。
那次內存泄漏問題中,導致單個容器中的內存從原先的 400M 暴漲到 700M,在 800M 的容器資源限制下偶爾會發生 OOM,導致重啟。一時沒有定位到問題 (發現問題過遲,半個月前的時序數據已被吞沒,于是未定位到 Release),于是把資源限制上調到 1000M。后發現是由 ctx.request 掛載了數據庫某個大字段而致
const Koa = require('koa')
const app = new Koa()
function getData () {
return Array.from(Array(1000)).map(x => 10086)
}
app.use(async (ctx, next) => {
ctx.data = getData()
await next()
})
app.use(ctx => {
ctx.body = 'hello, world'
})
app.listen(3200, () => console.log('Port: 3200'))一些問題需要在本地及測試環境得到及時扼殺,來避免在生產環境造成更大的影響。那么了解在本地如何監控內存就至關重要。
pidstat 是 sysstat 系列 linux 性能調試工具的一個包,竟然用它來調試 linux 的性能問題,包括內存,網絡,IO,CPU 等。
這不僅試用與 node,而且適用于一切進程,包括 python,java 以及 go
# -r: 指輸出內存指標 # -p: 指定 pid # 1: 每一秒輸出一次 # 100: 輸出100次 $ pidstat -r -p pid 1 100
而在使用 pidstat 之前,需要先找到進程的 pid
在 node 中可以通過 process.pid 來找到進程的 pid
> process.pid 16425
雖然通過寫代碼可以找到 pid,但是具有侵入性,不太實用。那如何通過非侵入的手段找到 pid 呢?有兩種辦法
ps 定位進程lsof 定位進程$ node index.js shanyue # 第一種方法:通過多余的參數快速定位 pid $ ps -ef | grep shanyue root 31796 23839 1 16:38 pts/5 00:00:00 node index.js shanyue # 第二種方法:通過端口號定位 pid lsof -i:3200 COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME node 31796 root 20u IPv6 235987334 0t0 TCP *:tick-port (LISTEN)
從以上代碼中可以知道,node 服務的 pid 為 31796,為了可以觀察到內存的動態變化,再施加一個壓力測試
$ ab -c 10000 -n 1000000 http://localhost:3200/
# -r: 指輸出內存指標
# -p: 指定 pid
# 1: 每一秒輸出一次
# 100: 輸出100次
$ pidstat -r -p 31796 1 100
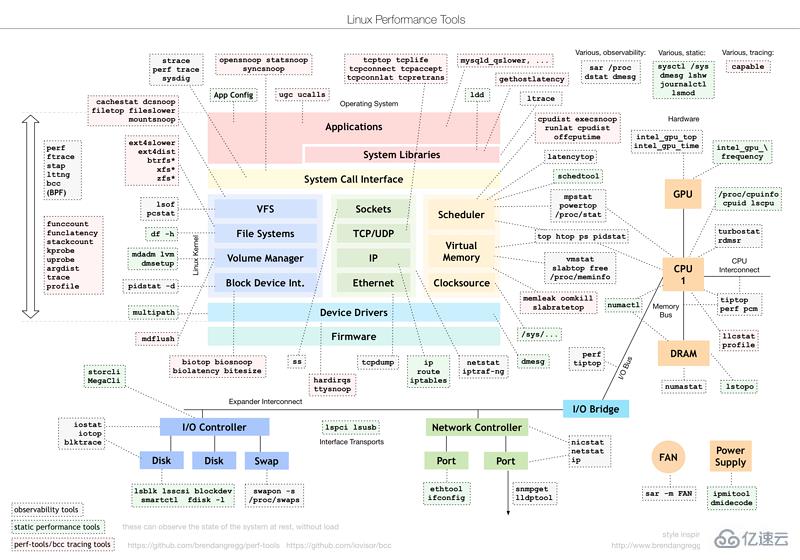
Linux 3.10.0-957.21.3.el7.x86_64 (shuifeng) 2020年07月02日 _x86_64_ (2 CPU)
UID PID minflt/s majflt/s VSZ RSS %MEM Command
19時20分39秒 0 11401 0.00 0.00 566768 19800 0.12 node
19時20分40秒 0 11401 0.00 0.00 566768 19800 0.12 node
19時20分41秒 0 11401 9667.00 0.00 579024 37792 0.23 node
19時20分42秒 0 11401 11311.00 0.00 600716 59988 0.37 node
19時20分43秒 0 11401 5417.82 0.00 611420 70900 0.44 node
19時20分44秒 0 11401 3901.00 0.00 627292 85928 0.53 node
19時20分45秒 0 11401 1560.00 0.00 621660 81208 0.50 node
19時20分46秒 0 11401 2390.00 0.00 623964 83696 0.51 node
19時20分47秒 0 11401 1764.00 0.00 625500 85204 0.52 node對于輸出指標的含義如下
RSS: Resident Set Size,常駐內存集,可理解為內存,這就是我們需要監控的內存指標VSZ: virtual size,虛擬內存從輸出可以看出,當施加了壓力測試后,內存由 19M 漲到了 85M。
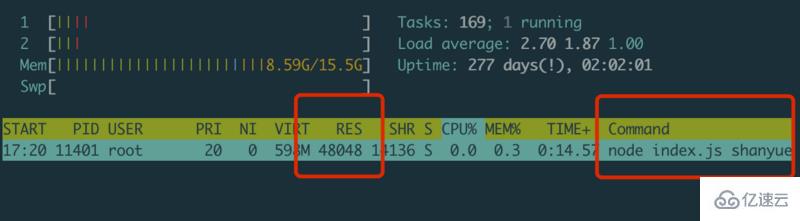
pidstat 是屬于 sysstat 下的 linux 性能工具,但在 mac 中,如何定位內存的變化?
此時可以使用 top/htop
$ htop -p 31796
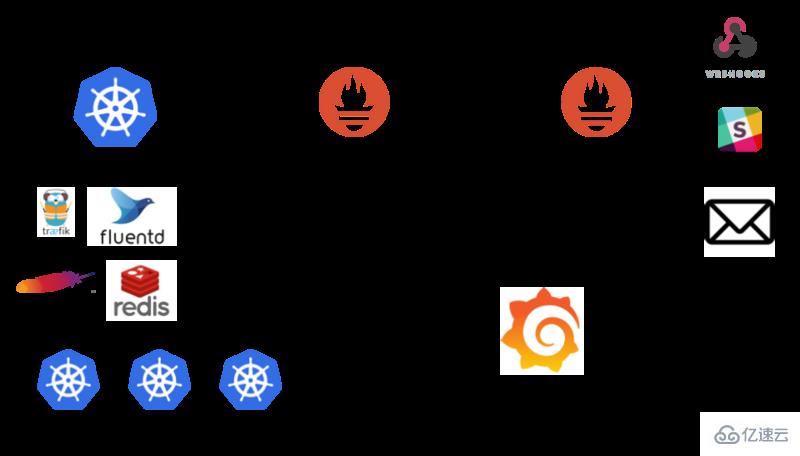
由于目前生產環境大都部署在 k8s,因此生產環境對于某個應用的內存監控本質上是 k8s 對于某個 workload/deployment 的內存監控,關于內存監控 metric 的數據流向大致如下:
k8s -> metric server -> prometheus -> grafana
架構圖如下:
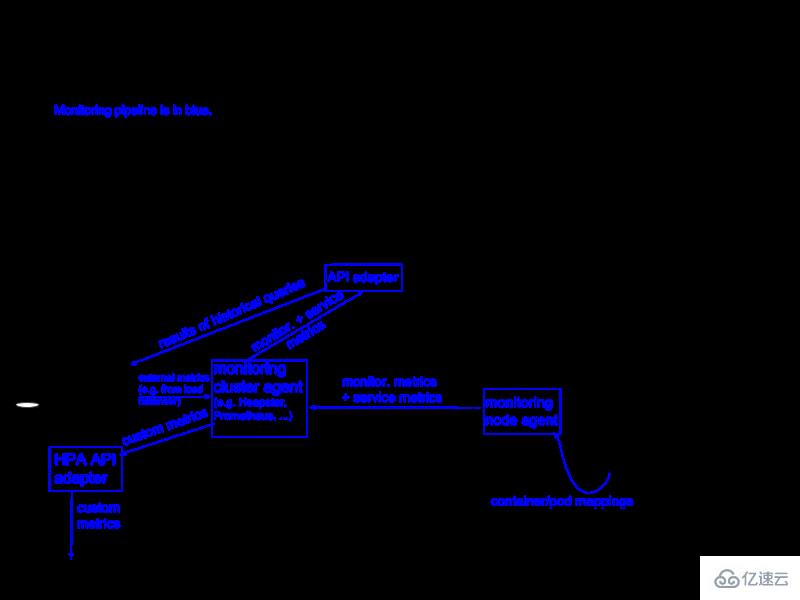
最終能夠在 grafana 中收集到某一應用的內存監控實時圖:
由于本部分設計內容過多,我將在以下的章節中進行介紹
這不僅僅適用于 node 服務,而且適用于一切 k8s 上的 workload
感謝各位的閱讀!看完上述內容,你們對Node服務中監控本地環境及生產環境內存變化的方法大概了解了嗎?希望文章內容對大家有所幫助。如果想了解更多相關文章內容,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





