溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹了爬蟲及繞過網站反爬取機制的案例分析,具有一定借鑒價值,需要的朋友可以參考下。希望大家閱讀完這篇文章后大有收獲。下面讓小編帶著大家一起了解一下。

爬蟲是什么呢,簡單而片面的說,爬蟲就是由計算機自動與服務器交互獲取數據的工具。爬蟲的最基本就是get一個網頁的源代碼數據,如果更深入一些,就會出現和網頁進行POST交互,獲取服務器接收POST請求后返回的數據。一句話,爬蟲用來自動獲取源數據,至于更多的數據處理等等是后續的工作,這篇文章主要想談談爬蟲獲取數據的這一部分。爬蟲請注意網站的Robot.txt文件,不要讓爬蟲違法,也不要讓爬蟲對網站造成傷害。
反爬及反反爬概念的不恰當舉例
基于很多原因(如服務器資源,保護數據等),很多網站是限制了爬蟲效果的。
考慮一下,由人來充當爬蟲的角色,我們怎么獲取網頁源代碼?最常用的當然是右鍵源代碼。
網站屏蔽了右鍵,怎么辦?

拿出我們做爬蟲中最有用的東西 F12(歡迎討論)
同時按下F12就可以打開了(滑稽)
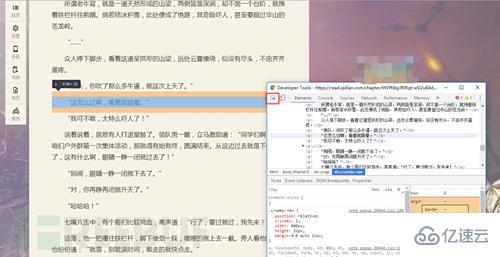
源代碼出來了!!
在把人當作爬蟲的情況下,屏蔽右鍵就是反爬取策略,F12就是反反爬取的方式。
講講正式的反爬取策略
事實上,在寫爬蟲的過程中一定出現過沒有返回數據的情況,這種時候也許是服務器限制了UA頭(user-agent),這就是一種很基本的反爬取,只要發送請求的時候加上UA頭就可以了…是不是很簡單?
其實一股腦把需要不需要的Request Headers都加上也是一個簡單粗暴的辦法……
有沒有發現網站的驗證碼也是一個反爬取策略呢?為了讓網站的用戶能是真人,驗證碼真是做了很大的貢獻。隨驗證碼而來的,驗證碼識別出現了。
說到這,不知道是先出現了驗證碼識別還是圖片識別呢?
簡單的驗證碼現在識別起來是非常簡單的,網上有太多教程,包括稍微進階一下的去噪,二值,分割,重組等概念。可是現在網站人機識別已經越發的恐怖了起來,比如這種:
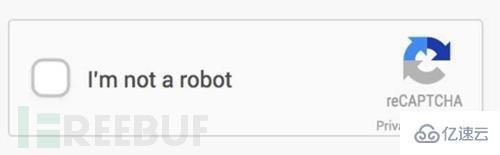
簡單講述一下去噪二值的概念
將一個驗證碼
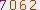
變成
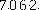
就是二值,也就是將圖片本身變成只有兩個色調,例子很簡單,通過python PIL庫里的
Image.convert("1")
就能實現,但如果圖片變得更為復雜,還是要多思考一下,比如
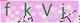
如果直接用簡單方式的話 就會變成
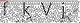
思考一些這種驗證碼應該怎么識別?這種時候 去噪 就派上了用處,根據驗證碼本身的特征,可以計算驗證碼的底色和字體之外的RGB值等,將這些值變成一個顏色,將字體留出。示例代碼如下,換色即可
for x in range(0,image.size[0]): for y in range(0,image.size[1]): # print arr2[x][y] if arr[x][y].tolist()==底色: arr[x][y]=0 elif arr[x][y].tolist()[0] in range(200,256) and arr[x][y].tolist()[1] in range(200,256) and arr[x][y].tolist()[2] in range(200,256): arr[x][y]=0 elif arr[x][y].tolist()==[0,0,0]: arr[x][y]=0 else: arr[x][y]=255
arr是由numpy得到的,根據圖片RGB值得出的矩陣,讀者可以自己嘗試完善代碼,親自實驗一下。
細致的處理之后圖片可以變成

識別率還是很高的。
在驗證碼的發展中,還算清晰的數字字母,簡單的加減乘除,網上有輪子可以用,有些難的數字字母漢字,也可以自己造輪子(比如上面),但更多的東西,已經足夠寫一個人工智能了……(有一種工作就是識別驗證碼…)
再加一個小提示:有的網站PC端有驗證碼,而手機端沒有…
下一個話題!
反爬取策略中比較常見的還有一種封IP的策略,通常是短時間內過多的訪問就會被封禁,這個很簡單,限制訪問頻率或添加IP代理池就OK了,當然,分布式也可以…
IP代理池->左轉Google右轉baidu,有很多代理網站,雖然免費中能用的不多 但畢竟可以。
還有一種也可以算作反爬蟲策略的就是異步數據,隨著對爬蟲的逐漸深入(明明是網站的更新換代!),異步加載是一定會遇見的問題,解決方式依然是F12。以不愿透露姓名的網易云音樂網站為例,右鍵打開源代碼后,嘗試搜索一下評論

數據呢?!這就是JS和Ajax興起之后異步加載的特點。但是打開F12,切換到NetWork選項卡,刷新一下頁面,仔細尋找,沒有秘密。
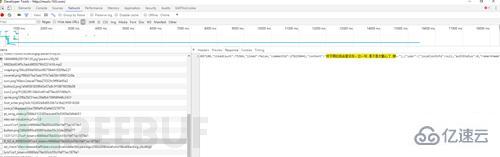
哦,對了 如果你在聽歌的話,點進去還能下載呢…
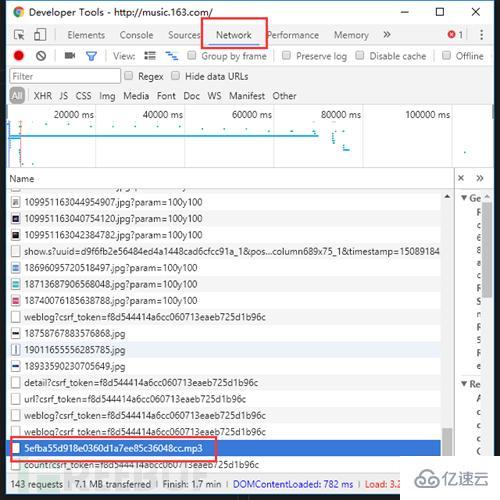
僅為對網站結構的科普,請自覺抵制盜版,保護版權,保護原創者利益。
如果說這個網站限制的你死死的,怎么辦?我們還有最后一計,一個強無敵的組合:selenium + PhantomJs
這一對組合非常強力,可以完美模擬瀏覽器行為,具體的用法自行百度,并不推薦這種辦法,很笨重,此處僅作為科普。
感謝你能夠認真閱讀完這篇文章,希望小編分享爬蟲及繞過網站反爬取機制的案例分析內容對大家有幫助,同時也希望大家多多支持億速云,關注億速云行業資訊頻道,遇到問題就找億速云,詳細的解決方法等著你來學習!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





