溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
小編給大家分享一下爬蟲如何做反爬措施,希望大家閱讀完這篇文章后大所收獲,下面讓我們一起去探討方法吧!
爬蟲常見的反爬措施有三種:
1、header頭部信息
解決方法:
加User-Agent值:
如果不加header頭,部分網站服務器判斷不到用戶的訪問來源,所以會返回一個404錯誤來告知你是一個爬蟲,拒絕訪問,解決辦法如下:
headers = {
'User-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.56 Safari/537.36'
}這樣服務器就會把用戶當做瀏覽器了。
加Referer值
這類反爬網站也很常見,例如美團,僅僅加User-Agnet還是返回錯誤信息,這時就要把Referer值也加到頭部信息中:
 這樣就會返回正常網頁了。
這樣就會返回正常網頁了。
加Host值
根據同源地址判斷用戶是否為爬蟲,解決辦法為:

加Accept值
之前遇到過這種網站,我加了一圈header頭部信息才成功,最后發現是需要加Accept值,這類反爬措施的解決辦法為:

2、限制IP的請求數量
這種就更常見了,大部分網站都有此類反爬措施,也就是說網站服務器會根據某個ip在特定時間內的訪問頻率來判斷是否為爬蟲,然后把你把你拉進“黑名單”,素質好的給你返回403或者出來個驗證碼,素質不好的會給你返回兩句臟話。此種情況有兩種解決辦法:
①降低爬蟲請求速率,但是會降低效率;
②添加代理ip,代理ip又分為付費的和不要錢的,前者比較穩定,后者經常斷線。
添加格式為:

3、Ajax動態請求加載
這類一般是動態網頁,無法直接找到數據接口,以某易新聞網站為例:
我想爬取該網頁內的新聞圖片,發現它的網頁url一直不變,但是下拉網頁的時候會一直加載圖片,那么我們該怎么辦呢?
首先按照開頭方式打開流量分析工具
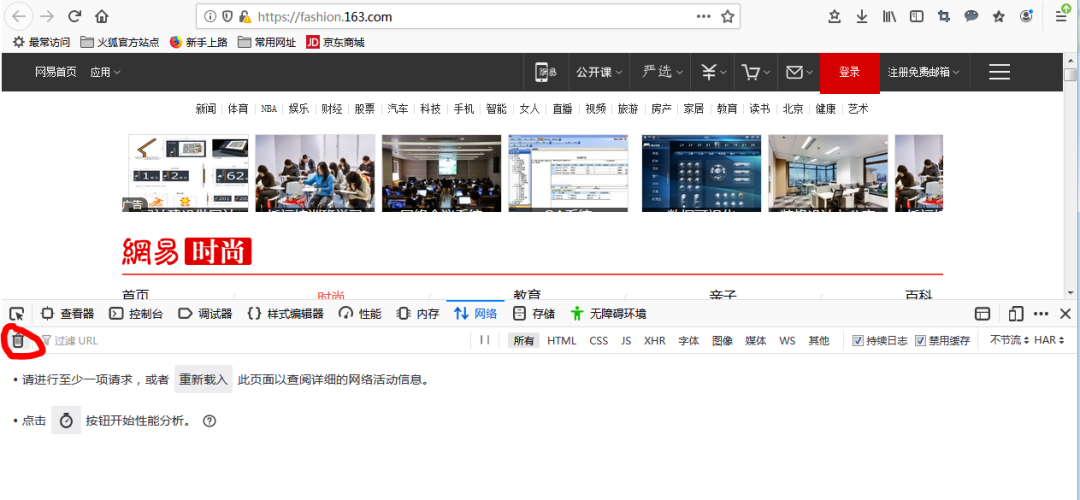
點擊左上角“垃圾桶”圖標清空緩存,然后下拉新聞網頁:
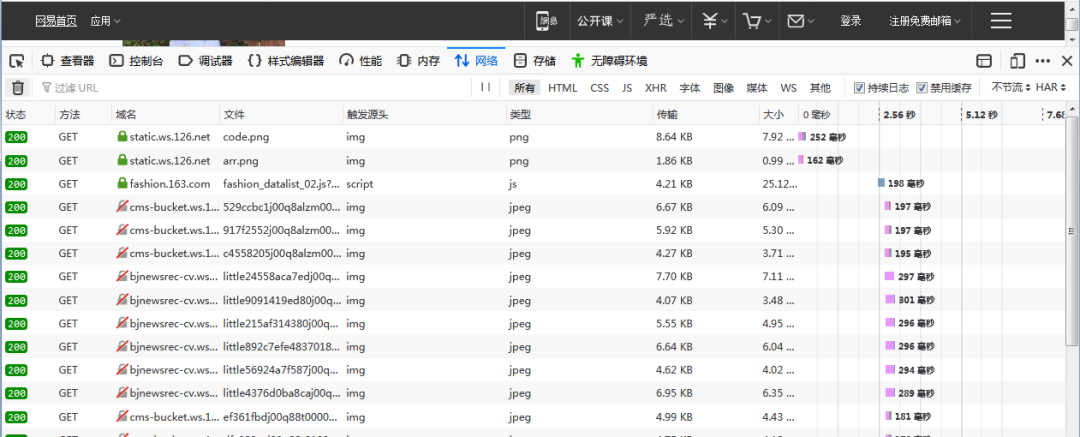
會出現一大堆東西,但是不用慌,我們可以根據類型去尋找,一般圖片信息肯定實在html、js或json格式的文件中,一個一個點進去看看,很快就找到了結果:
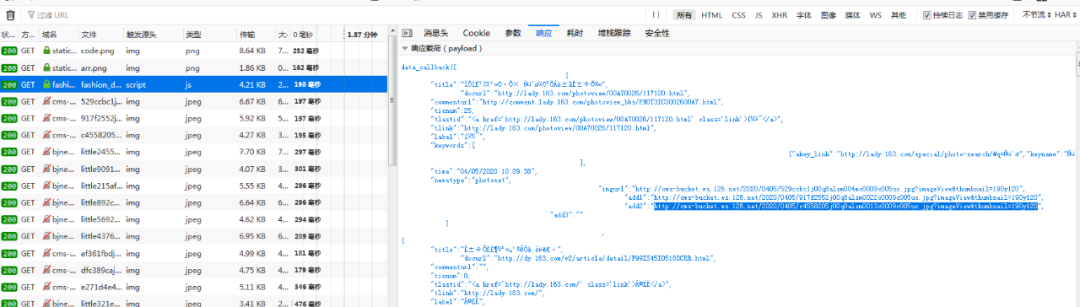
結果中把callback去掉之后就是個json文件,它的url為:

看完了這篇文章,相信你對爬蟲如何做反爬措施有了一定的了解,想了解更多相關知識,歡迎關注億速云行業資訊頻道,感謝各位的閱讀!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





