溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章給大家介紹如何用Keras框架構建一個簡單的卷積神經網絡,內容非常詳細,感興趣的小伙伴們可以參考借鑒,希望對大家能有所幫助。
問題介紹
在討論問題細節之前,我想先介紹一下業務流程,Avito.ma是一個行業領先的摩洛哥電子商務廣告平臺,用戶可以在其中發布廣告,銷售二手商品或新產品,如手機、筆記本電腦、汽車、摩托車等。
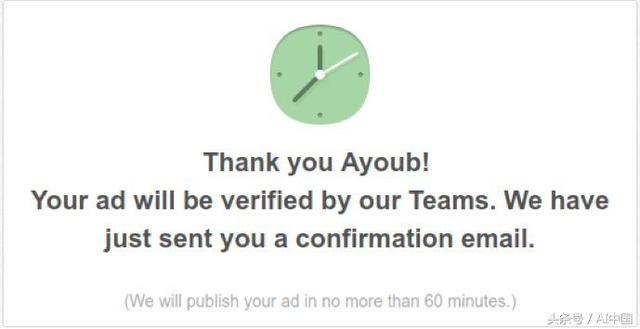
現在,讓我們討論這個問題:為了發布廣告、銷售產品,你首先必須填寫一個表單,描述你的產品概況,設定價格,并上傳其相應的照片。在成功填寫這些字段后,你必須等待大約60分鐘,以便在網站相關管理人員審核驗證這些圖片后,再發布你提交的廣告。
如今,在深度學習和計算機視覺的時代,通過人工檢查網頁內容這被認為是一種缺陷,并且非常耗時,而且它可能產生許多錯誤。例如下面這個錯誤,網站審核人員發布了列在電話類別中的筆記本電腦廣告,這是錯誤的,并將影響搜索引擎質量,而這項工作可以通過深度學習模型在一秒鐘內完成。
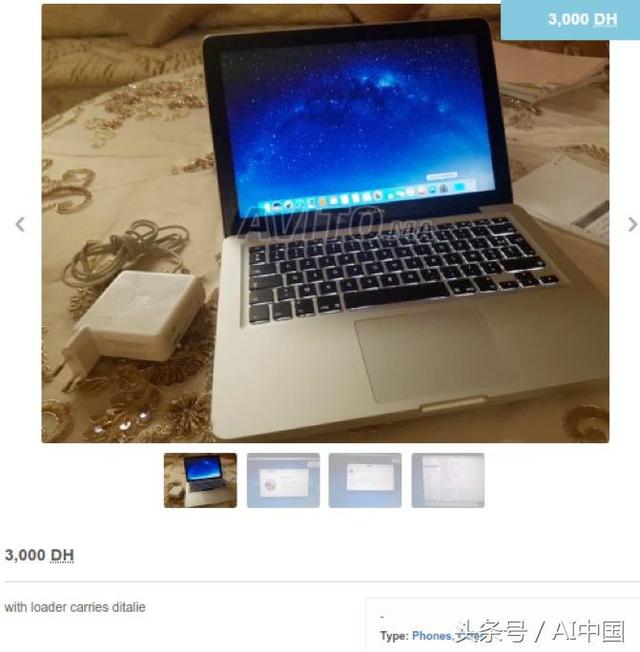
筆記本廣告發布在手機類鏈接中
在這篇博文中,我將介紹如何通過使用Keras框架構建一個簡單的卷積神經網絡來優化此過程,該框架可以分析上傳的圖像是用于手機廣告還是筆記本電腦廣告,并告訴我們圖像是否與廣告類別匹配。
博客文章將這個案例分為5個具體步驟。
數據收集
數據預處理
數據建模
使用TensorBoard分析模型
模型部署和評估
1.數據收集
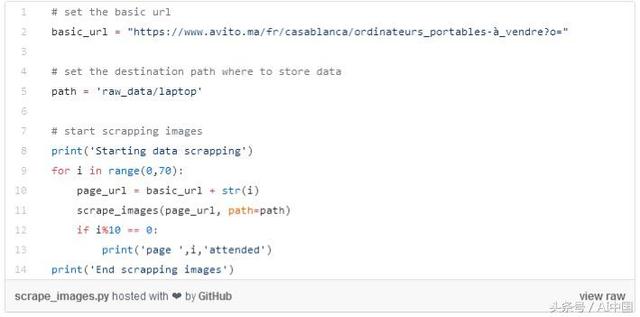
就像任何數據科學項目一樣,我們應該尋找的第一個組件是數據,在這種情況下,我們將處理的數據從同一網站Avito.ma中刪除的一組圖像,用于筆記本電腦和手機兩類產品,結果文件夾將包含兩個子目錄分別稱為“筆記本電腦”和“電話”,下載的圖像大小在120×90到67×90之間,每個子目錄有3個RGB通道。以下是執行此任務的代碼的快照,而筆記本中提供了完整代碼。(https://github.com/PaacMaan/avito_upload_classifier/blob/master/avito_image_classifier.ipynb)
一旦這個過程完成,我們得到了2097張筆記本電腦圖像和2180張手機圖像。為了使分類更準確并且沒有偏差,我們需要驗證幾乎相同的觀察數量的這兩個類,因為我們可以從下面的圖中實現可視化,兩個類的數量大致相當平衡。
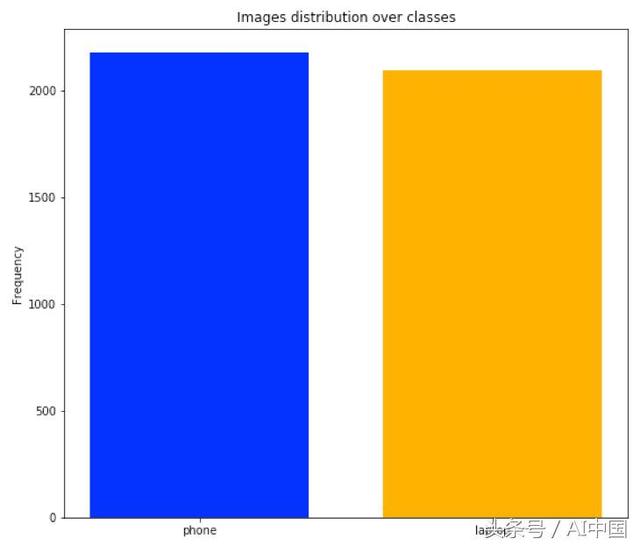
圖像分布在類上
2.數據預處理
對于預處理任務,我們將其分為三個子任務,如下所示:
2.1刪除噪聲數據
當人工檢查下載的圖像時,會注意到存在一些與相關類無關的噪聲圖像,例如下面的那些(手機充電器、手機包、虛擬現實眼鏡)能夠在手機文件夾中觀察到:

手機圖像中發現噪聲圖像
不幸的是,沒有自動的方法來解決這個問題,因此我們必須人工查看它們,并開始刪除它們以僅保留與相應類相關的圖像。
2.2圖像大小調整
此步驟完全取決于采用的深度學習架構,例如,當使用Alexnet模型對圖像進行分類時,輸入圖像大小應為22×227,而對于VGG-19,輸入圖像大小為224×224。
由于我們不打算采用任何預先構建的架構,將構建自己的卷積神經網絡模型,其輸入大小為64 ×64,如下面的代碼快照所示。
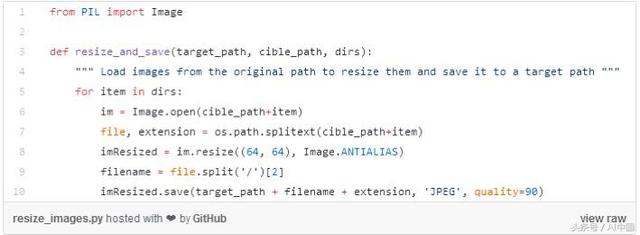
要執行此任務,我們在兩個子目錄phone和laptop中創建另一個名為preprocessed_data的目錄,然后我們循環raw_data原始文件夾中的每個圖像以調整其大小,并將其保存在新創建的目錄中。
因此,我們最終得到了兩個類的新生成數據集,其格式為64×64。
2.3數據拆分
在調整數據集大小后,我們將其拆分為80%用于訓練集,并保留其余部分進行驗證。為了執行此任務,我們創建了一個名為data的新目錄,其中我們設置了train和validation另外兩個新目錄,我們將為手機和筆記本電腦設置兩個類圖像。
更明確地,我們定義當前目標和目標目錄,然后我們將訓練集的比率固定為0.8,將驗證的比率固定為0.2,以測量我們將從原始路徑移動到目標路徑的圖像數量。

執行數據拆分的代碼快照
需要很好地可視化文件夾層次結構,這是項目樹視圖:
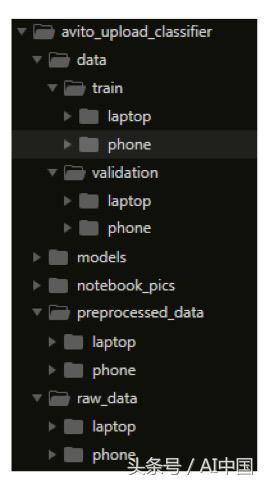
全局項目結構
3.數據建模
現在我們到了這一管道的主要步驟,即數據建模,為此我們將建立一個卷積神經網絡,將對我們之前處理過的幾千部手機和筆記本電腦圖像進行訓練。
在計算機視覺中,卷積運算是卷積神經網絡的基本構建塊之一,需要4個必需組件:

卷積神經網絡的主要組成部分
對于這個模型,我們將討論每個組件如何使用Keras實現它以及從卷積到完全連接層的自己的參數,但首先,讓我們發現內置模型的完整架構。

卷積神經網絡(CNN)模型架構
卷積層

在將順序對象實例化為模型之后,我們使用add方法添加一個名為Conv2D的卷積層,其中第一個參數是過濾器,它是輸出數量的維數,如模型摘要所示,第一層輸出的形狀為(None, 62, 62, 32)。
對于第二個參數,kernel_size指定了1D卷積窗口的長度,這里我們選擇3×3的窗口大小來卷積輸入卷。
第三個參數代表input_shape,它是分別與image_width x image_height x color channels (RGB)相關的64×64×3的大小,最后但并非最不重要的是activation_function,它負責添加非線性轉換。在這種情況下,我們選擇relu激活功能。
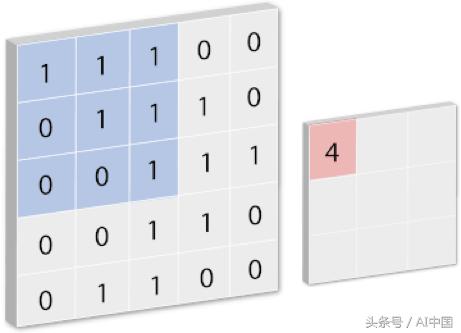
使用kernel_size =(3,3)進行卷積運算的插圖
最大池層
在卷積之后添加最大池化層的原因是減少我們之前應用的卷積層提取的特征量,換句話說,我們對這些特征的位置感興趣。
為了對其高度進行概括,如果有一個從x到y的垂直邊緣,將圖像的垂直邊緣降到圖像的2/3的高度。
所有這一過程都在Keras的一行代碼中恢復:
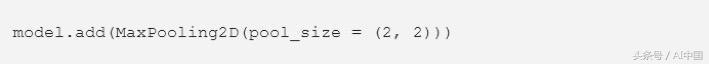
在這里,我們使用add方法注入另一層名為MaxPooling2D的Maximum Pooling,其中pool_size是(2,2)的窗口,默認情況下strides = None和padding ='valid'。
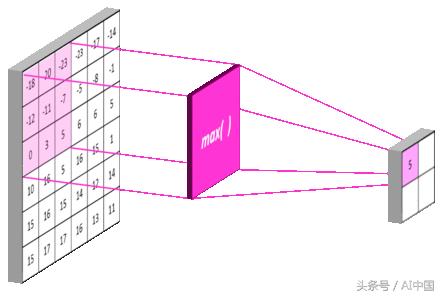
最大池與pool_size =(2,2)的圖示
展平輸出
在結束卷積神經網絡(CNN)模型時,將最大池展平輸出為連續的一維向量是必需的步驟。

Keras在這里所做的,只是在網絡中添加一個Flatten圖層,它簡單地相當于使用'C'排序重塑numpy中的函數。
全連接層
最后,我們將最后一層注入到全連接層的網絡中,您可以將其視為學習從先前卷積中提取的特征的非線性組合的廉價方法。

Keras通過將Dense功能添加到網絡中很容易實現,它只需要兩個參數units和activation,它們分別代表我們將擁有的輸出單元的數量,因為我們正在進行二進制分類,因此它取值為2并激活功能使用。
編譯網絡
最后,我們必須通過調用編譯函數來編譯我們剛剛構建的網絡,這是使用Keras構建的每個模型的必需步驟。

loss參數,因為我們有一個二元分類,其中類M的數量等于2,交叉熵可以計算為:
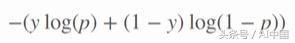
二元交叉熵的目標函數
其中p是預測概率,y是二進制指示符(0或1)。
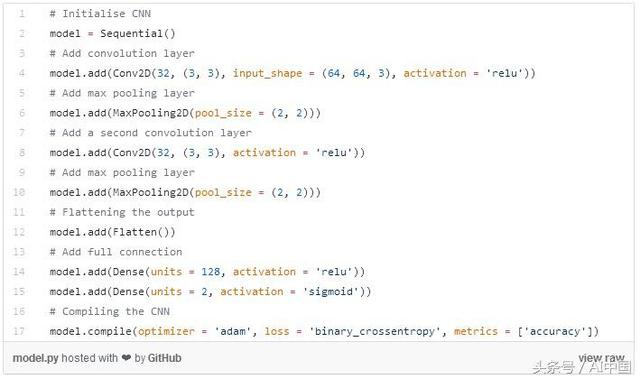
為了最小化這個目標函數,我們需要調用優化器,例如adam,這是Adaptive Moment Estimation的簡稱,默認情況下,其學習速率設置為0.001,但不會關閉超參數調整窗口。為了總結我們所做的事情,下面是內置模型的完整代碼。
加載圖像和數據轉換
為了將圖像提供給我們編譯的模型,我們調用ImageDataGenerator函數,它將幫助我們生成具有實時數據增強的批量張量圖像數據。數據將循環(批量)。
現在我們已經創建了兩個ImageDataGenerator實例,我們需要使用分類類模式為訓練和驗證數據集提供正確的路徑。
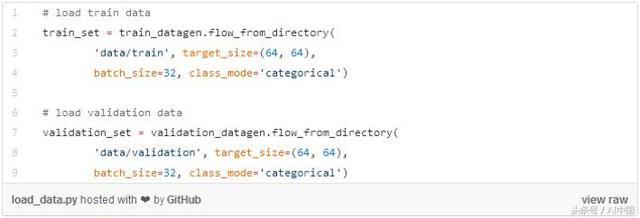
一旦訓練(train)和驗證(validation)集準備好為網絡提供信息,我們就會調用fit_generator方法將它們提供給模型。

通常我們準備另一個測試數據集,除了評估最終訓練模型的驗證,但為了保持簡單性,并且只在驗證集上進行評估。
模型評估
完成訓練后,我們的準確率達到87.7%左右,仍然有0.352的高損失率,但具有高精度并不一定意味著我們有良好的模型質量。我們需要在時間內跟蹤和可視化模型的行為,為此,我們使用Keras提供的TensorBoard作為與TensorFlow后端一起運行的回調函數。
4.使用TensorBoard分析模型
在這一步驟中,我們將看到如何使用TensorBoard分析我們的模型行為。TensorBoard是使用TensorFlow后端構建的模型的工具,幫助我們基本上可視化我們的模型隨時間的訓練,以及觀察準確性與驗證準確度或損失與驗證損失的關系。
使用Keras,可以通過調用TensorBoard函數僅在一行代碼中恢復此步驟,并在擬合數據時將其作為回調注入。

損失(Loss)
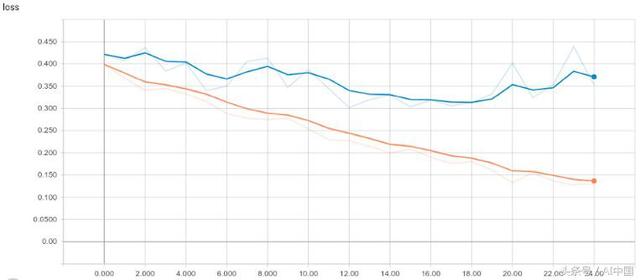
訓練和驗證集的損失直方圖
從上圖可以清楚地看出,對于從0.39到0.13的訓練線,損失顯著下降,而對于驗證線,從0.42開始并且花費25個周期達到0.35,它逐漸減少。
就個人而言,每當我想評估模型時,都會看到驗證損失,我們可以在這里看到的是,在19個周期之后,驗證損失開始稍微增加,這可能會導致模型記住許多輸入樣本,驗證這個假設,我們更好地檢查準確性直方圖。
準確性
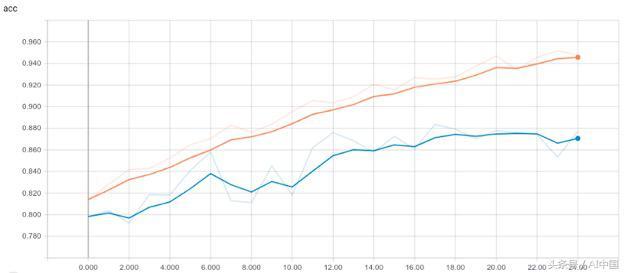
訓練和驗證集的準確度直方圖的演變
正如我們所看到的,驗證準確性一直在增加,直到第19個周期它變得有些穩定,并且具有預期的下降和上升,這可以通過從同一時期開始增加時的驗證損失行為來解釋。
為了保持良好的模型質量,建議在這種情況下使用早期停止回調,這將迫使模型在驗證損失開始增加或精度下降時以一定的容差停止訓練。
5.采用Flask進行模型部署
在轉移到部署細節之前,我們首先需要保存我們之前訓練過的模型,為此我們調用save方法,如下所示:

一旦我們的模型被保存,我們可以在以后使用它來預測新的圖像類。
為什么采用Flask?
Flask是一個Python的微框架,其靈感來自于引用“Do Thing and Do It Well”,這就是我選擇Flask作為REST API提供模型的原因。
Flask應用程序由2個主要組件組成:python應用程序(app.py)和HTML模板,對于app.py,它將包含執行預測的邏輯代碼,該代碼將作為HTTP響應發送。該文件包含三個主要組件,可以顯示如下:
加載保存的模型。
轉換上傳的圖像。
使用加載的模型預測其適當的類。
在下一節中,我們將討論這些方面最重要的組成部分。
回到主要問題
當用戶選擇作為廣告類別的筆記本電腦時,預計他必須上傳筆記本電腦的圖像,但正在發生的事情是不同的。正如我們之前看到的那樣,有許多廣告,其中圖片包含標注手機類別的筆記本電腦。
在運行應用程序并假設模型已成功加載后,用戶可以上傳不同大小的圖像,而我們的模型只能預測64×64×3的圖像,因此我們需要將它們轉換為正確的大小,以便我們的模型可以很好地預測它。
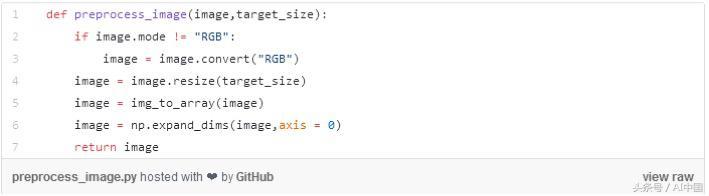
處理上傳圖像的代碼快照
轉換上傳的圖像后,我們將其作為參數發送到加載的模型,以便進行預測并將HTTP響應作為JSON對象返回,其中模式如下:

第一個屬性是圖像預測類,第二個屬性是布爾值,表示從用戶中選擇的類別是否與上傳的圖像匹配。下面我展示了執行此工作的代碼邏輯的快照。

應用演示
要運行應用程序,我們只需切換到創建app.py的文件夾,然后運行以下命令:

然后我們瀏覽控制臺上顯示的以下URL:http://127.0.0.1:5000 /,一旦顯示索引頁面,選擇廣告類別并上傳其相關照片,在幕后將請求發送到路徑/上傳將照片保存在目錄中以預測其適當的類。
這是現場演示我們在本項目結束時能夠建立的內容。
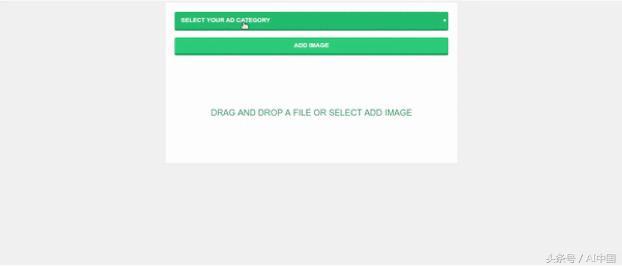
Web應用程序演示
如果選擇的和預測的類都匹配,那么你會得到一條成功消息,說明一切正常,否則會收到一條警告消息,選擇框將自動更改為相應的預測類。
結論
最后,本博客文章通過構建深度學習模型來展示完整的計算機視覺管道,該模型可以預測應用于電子商務場景的上傳圖像的類別,從數據收集到數據建模,并通過模型部署作為Web完成應用程序。
改善的方法:
1.通過為兩個類刪除更多圖像來增加數據大小并刪除噪聲。
2.針對學習率和beta值的超參數調整。
3.嘗試其他架構,如Lenet-5。(yann.lecun.com/exdb/publis/pdf/lecun-01a.pdf)
4.在完全連接(密集)層上使用Dropout。
關于如何用Keras框架構建一個簡單的卷積神經網絡就分享到這里了,希望以上內容可以對大家有一定的幫助,可以學到更多知識。如果覺得文章不錯,可以把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





