溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
如何進行Prometheus的數據庫監控,相信很多沒有經驗的人對此束手無策,為此本文總結了問題出現的原因和解決方法,通過這篇文章希望你能解決這個問題。
傳統監控系統,會面臨哪些問題?
以zabbix為例 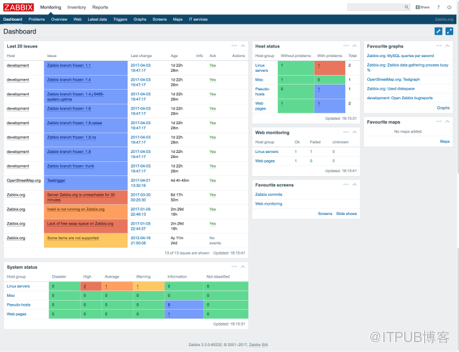
初次使用需要配置大量管理功能,隨著服務器和業務的增長會發現zabbix,這種傳統監控面臨很多問題
DB性能瓶頸,由于zabbix會將采集到的性能指標都存儲到數據庫中,當服務器數量和業務增長很快時數據庫性能首先成為瓶頸。
多套部署,管理成本高,當數據庫性能成為瓶頸時首先想到的辦法可能時分多套zabbix部署,但是又會帶來管理很維護成本很高的問題。
易用性差,zabbix的配置和管理非常復雜,很難精通。
郵件風暴,郵件配置各種規則相當復雜,一不小心可能就容易造成郵件風暴的問題。
隨著容器技術的發展,傳統監控系統面臨更多問題
容器如何監控?
微服務如何監控?
集群性能如何進行分析計算?
如何管理agent端大量配置腳本?
我們可以看到傳統監控系統無法滿足,當前IT環境下的監控需求
2015年Google發表了一篇論文《Google使用Borg進行大規模集群的管理》

這篇論文也描述了Google集群的規模和面臨的挑戰
單集群上萬服務器
幾千個不同的應用
幾十萬個以上的jobs,而且動態增加或者減少
每個數據中心數百個集群
基于這樣一個規模,Google的監控系統也面臨巨大挑戰,而Borg中的Borgmon監控系統就是為了應對這些挑戰而生。
那么我們來看一下Google如何做大規模集群的監控系統
首先,Borg集群中運行的所有應用都需要暴露出特定的URL,http://<app>:80/varz 通過這個URL我們就可以獲取到應用所暴露的全部監控指標。

然而這樣的應用有數千萬個,而且可能會動態增加或者減少,Borgmon中如何發現這些應用呢?Borg中的應用啟動時會自動注冊到Borg內部的域名服務器BNS中,Borgmon通過讀取BNS中應用列表信息,收集到應用列表,從而發現有哪些應用服務需要監控。當獲取到應用列表后,就會將應用的全部監控變量值拉取到Borgmon系統中。 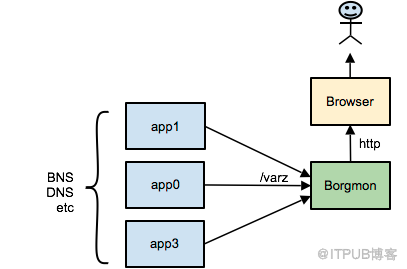
當監控指標收集到Borgmon中,就可以進行展現或者提供給告警使用,另外由于一個集群實在是太過龐大了,一個Borgmon可能無法滿足整個集群的監控采集和展現需求,所以一般會在一些復雜的環境下,一個數據中心可能部署多個Borgmon,分為數據收集層和匯總層,數據收集層會有多個Borgmon專門用來到應用中收集數據,匯總層Borgmon則從數據收集層Borgmon中獲取數據。 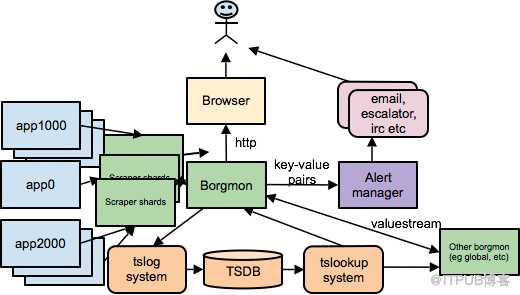
Borgmon收集到了性能指標數據后,會把所有的數據存儲在內存數據庫里,定時checkpoint到磁盤上,并且會周期性的打包到外部的系統TSDB。通常情況下,數據中心和全局Borgmon中一般至少會存放12小時左右的數據量,以便渲染圖表使用。每個數據點大概占用24字節的內存,所以存放100萬個time-series,每個time-series每分鐘一個數據點,同時保存12小時數據,僅需17GB內存。 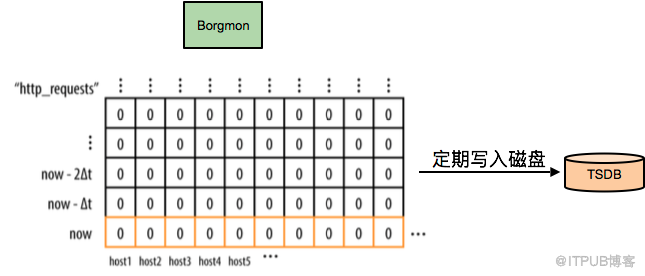
Borgmon中通過標簽的方式查詢指標,基于標簽過濾我們可以查詢到某個應用的具體指標,也可以查詢更高維度的信息
基于標簽過濾信息,比如我們基于一組過濾信息查詢到host0:80這個app的http_requests 
我們也可以查詢到整個美國西部,job為webserver的http_requests 
那么這個時候拿到的就是所有符合條件的實例的列表 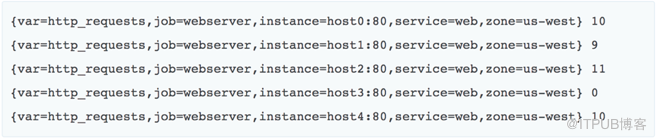
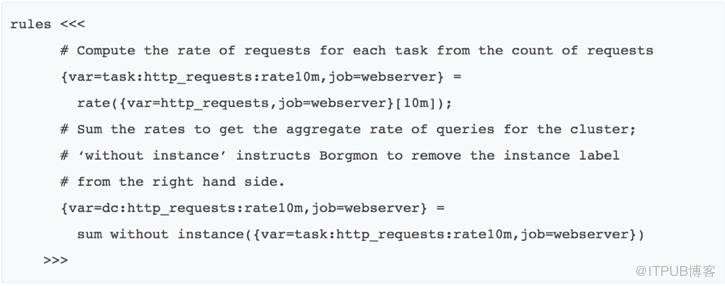
在數據收集和存儲的基礎之上,我們可以通過規則計算得到進一步的數據。
比如,我們想在web server報錯超過一定比例的時候報警,或者說在非200返回碼,占總請求的比例超過某個值的時候報警。 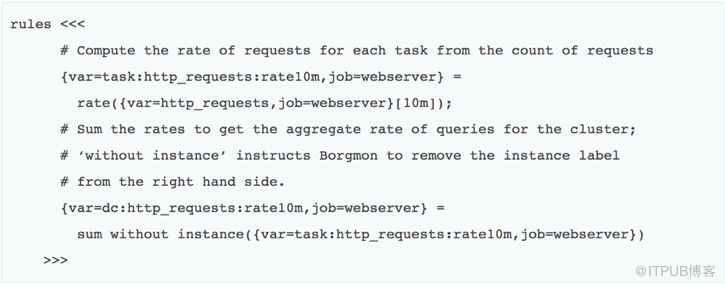
Borgmon是Google內部的系統,那么在Google之外如何使用它呢?這里就提到我們所描述的Prometheus這套監控系統。Google內部SRE工程師的著作《Google SRE》這本書中,直接就提到了Prometheus相當于就是開源版本的Borgmon。目前Prometheus在開源社區也是相當火爆,由Google發起Linux基金會旗下的原生云基金會(CNCF)就將Prometheus納入其下第二大開源項目(第一項目為Kubernetes,為Borg的開源版本)。
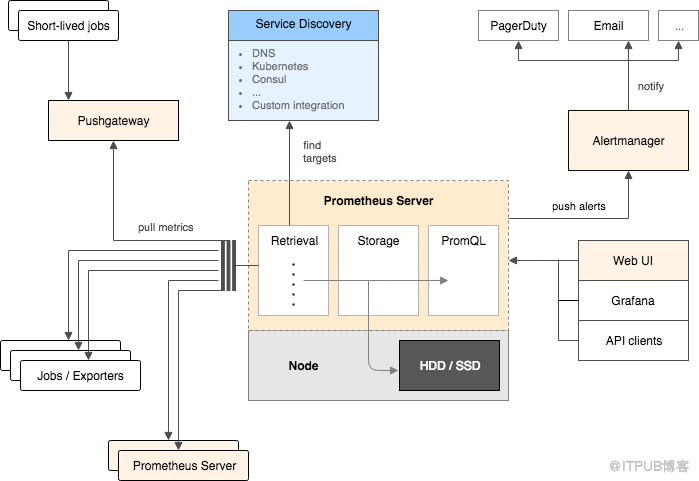
Prometheus整體架構和Borgmon類似,組件如下,有些組件是可選的:
Prometheus主服務器,用來收集和存儲時間序列數據
應用程序client代碼庫
短時jobs的push gateway
特殊用途的exporter(包括HAProxy、StatsD、Ganglia等)
用于報警的alertmanager
命令行工具查詢
另外Grafana是作為Prometheus Dashboard展現的絕佳工具
基于Prometheus的數據庫指標采集,我們以MySQL為例,由于MySQL沒有暴露采集性能指標的接口,我們可以單獨啟動一個mysql_exporter,通過mysql_exporter到MySQL數據庫上抓去性能指標,并暴露出性能采集接口提供給Prometheus,另外我們可以啟動node_exporter用于抓取主機的性能指標。 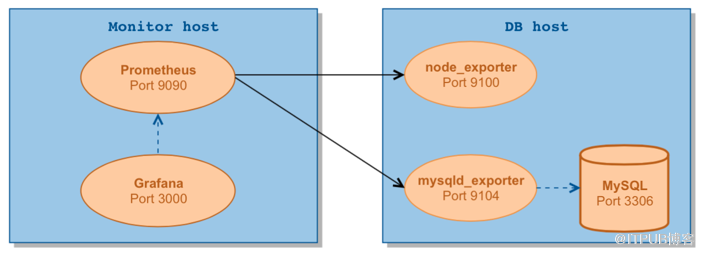
對于服務端配置非常簡單,由于Prometheus全部基于Go語言開發,而Go語言程序在安裝方面非常方便,安裝服務端程序只需要下載,解壓并運行即可。可以看到服務端常用程序也比較少,只需要包含prometheus這個主服務程序和alertmanager這個告警系統程序。 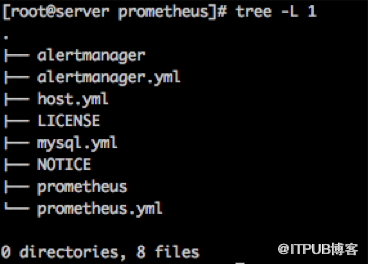
服務端配置也非常簡單,常用配置包含拉取時間和具體采集方式,就我們監控mysql數據庫來講,只需要填入mysql_exporter地址即可。 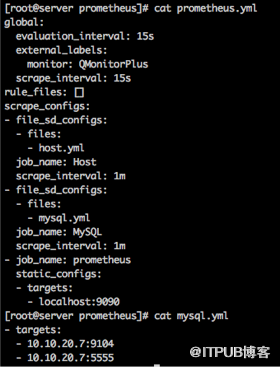
對于mysql采集只需要配置連接信息,并啟動mysql_exporter即可 
完成配置之后即可通過mysql_exporter采集mysql性能指標 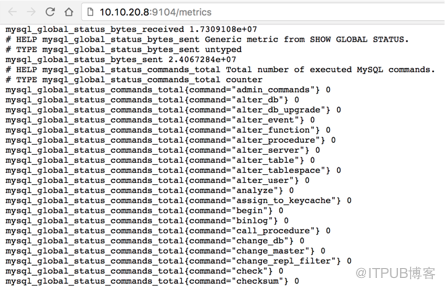
然后我們在prometheus服務端也可以查詢到采集的mysql性能指標 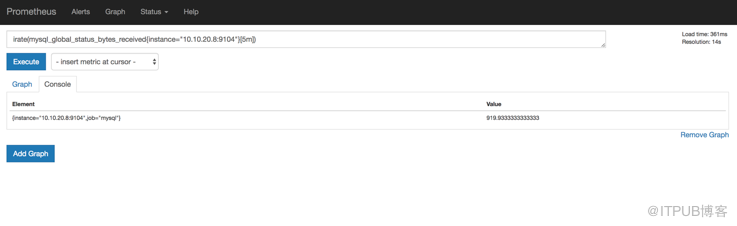
基于這些采集指標和Prometheus提供的規則計算語句,我們可以實現一些高緯度的查詢需求,比如,increase(mysql_global_status_bytes_received{instance="$host"}[1h])
我們可以查詢MySQL每小時接受到的字節數,然后我們將這個查詢放到Grafana中,就可以展現非常酷炫的性能圖表。
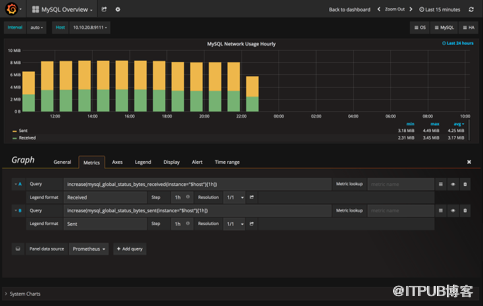
而目前結合Prometheus和Grafana的MySQL監控方案已經有開源實現,我們很輕松可以搭建一套基于Prometheus的監控系統 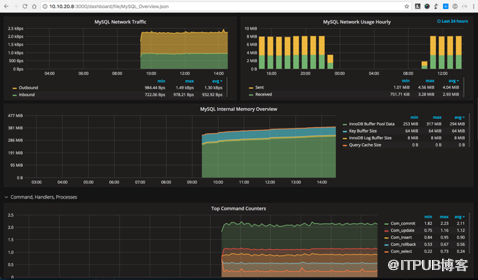
對于告警方面我們也可以基于Prometheus豐富的查詢語句實現復雜告警邏輯
比如我們要對MySQL備庫進行監控,如果復制IO線程未運行或者復制SQL線程未運行并且持續2分鐘就發送告警我們可以使用如下這條告警規則。
# Alert: The replication IO or SQL threads are stopped. ALERT MySQLReplicationNotRunning IF mysql_slave_status_slave_io_running == 0 OR mysql_slave_status_slave_sql_running == 0 FOR 2m LABELS { severity = "critical" } ANNOTATIONS { summary = "Slave replication is not running", description = "Slave replication (IO or SQL) has been down for more than 2 minutes.", }在比如,我們要監控MySQL備庫延遲大于30秒并且預測在未來2分鐘之后大于0秒持續1分鐘,則告警
# Alert: The replicaiton lag is non-zero and it predicted to not recover within
# 2 minutes. This allows for a small amount of replication lag. ALERT MySQLReplicationLag
IF (mysql_slave_lag_seconds > 30) AND on (instance) (predict_linear(mysql_slave_lag_seconds[5m], 60*2) > 0) FOR 1m LABELS { severity = "critical" } ANNOTATIONS { summary = "MySQL slave replication is lagging", description = "The mysql slave replication has fallen behind and is not recovering", }當然在數據庫方面不只是有MySQL的監控實現,目前業界也有很多其他開源實現,所以在數據庫監控方面也能實現開箱即用的效果
看完上述內容,你們掌握如何進行Prometheus的數據庫監控的方法了嗎?如果還想學到更多技能或想了解更多相關內容,歡迎關注億速云行業資訊頻道,感謝各位的閱讀!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





