溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
博文大綱:
一、Docker的監控
二、prometheus簡介
三、Prometheus組成及架構
四、部署prometheus
1)環境準備
2)部署prometheus
3)配置Peometheus監控實現報警
[root@localhost ~]# docker top wordpress_wordprss_1 //查看容器的使用狀態
UID PID PPID C STIME TTY TIME CMD
root 5601 5569 0 20:53 ? 00:00:00 apache2 -DFOREGROUND
33 6073 5601 0 20:54 ? 00:00:00 apache2 -DFOREGROUND
33 6074 5601 0 20:54 ? 00:00:00 apache2 -DFOREGROUND
33 6075 5601 0 20:54 ? 00:00:00 apache2 -DFOREGROUND
33 6076 5601 0 20:54 ? 00:00:00 apache2 -DFOREGROUND
33 6077 5601 0 20:54 ? 00:00:00 apache2 -DFOREGROUND
33 6096 5601 0 20:54 ? 00:00:00 apache2 -DFOREGROUND
33 6098 5601 0 20:54 ? 00:00:00 apache2 -DFOREGROUND
33 6099 5601 0 20:54 ? 00:00:00 apache2 -DFOREGROUND
33 6100 5601 0 20:54 ? 00:00:00 apache2 -DFOREGROUND
33 6155 5601 0 20:57 ? 00:00:00 apache2 -DFOREGROUND
[root@localhost ~]# docker stats wordpress_wordprss_1
[root@localhost ~]# docker logs wordpress_wordprss_1
//這三條都是容器本身自帶的監控命令[root@localhost ~]# docker run -it --rm --name sysdig --privileged=true --volume=/var/run/docker.sock:/host/var/run/docker.sock --volume=/dev:/host/dev --volume=/proc:/host/proc:ro --volume=/boot:/host/boot:ro --volume=/lib/modules:/host/lib/modules:ro --volume=/usr:/host/usr:ro sysdig/sysdig
//創建一個容器并自動進入容器中
//--rm:隨著退出容器而被刪除;
//--privileged=true:賦予特殊權限;
root@711dbeb59fdd:/# csysdig //執行這條命令如圖: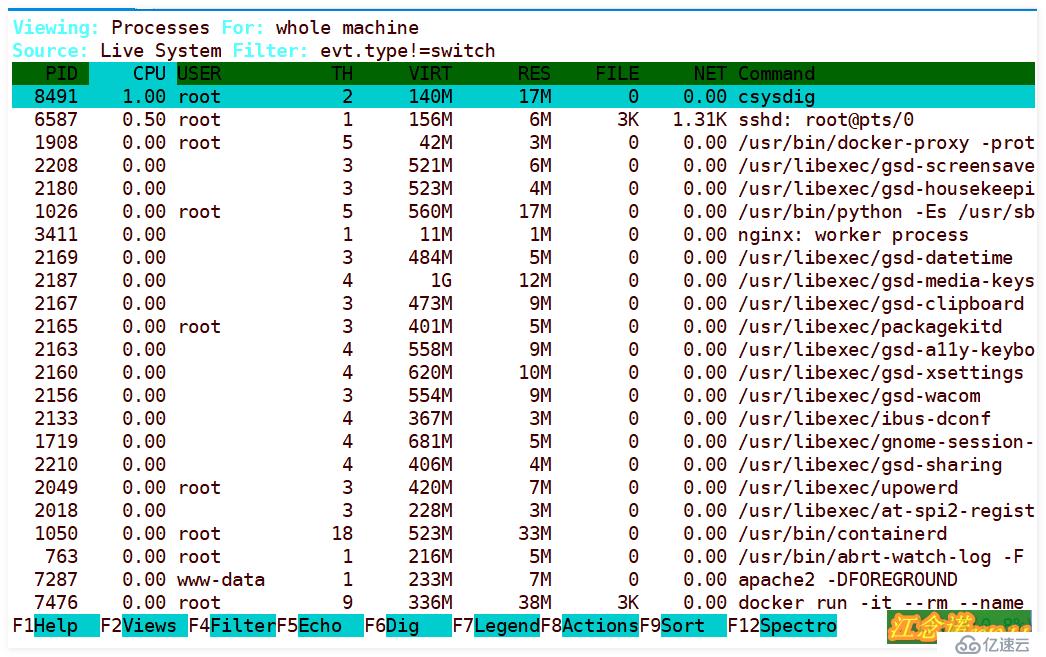
圖中可以使用鍵盤和鼠標進行操作!
[root@localhost ~]# curl -L git.io/scope -o /usr/local/bin/scope
[root@localhost ~]# chmod +x /usr/local/bin/scope //下載安裝腳本
[root@localhost ~]# scope launch //以容器方式啟動
……………………
Weave Scope is listening at the following URL(s):
* http://172.21.0.1:4040/
* http://192.168.122.1:4040/
* http://172.22.0.1:4040/
* http://172.20.0.1:4040/
* http://172.18.0.1:4040/
* http://172.19.0.1:4040/
* http://192.168.1.1:4040/
//根據末尾的提示信息進行訪問如圖: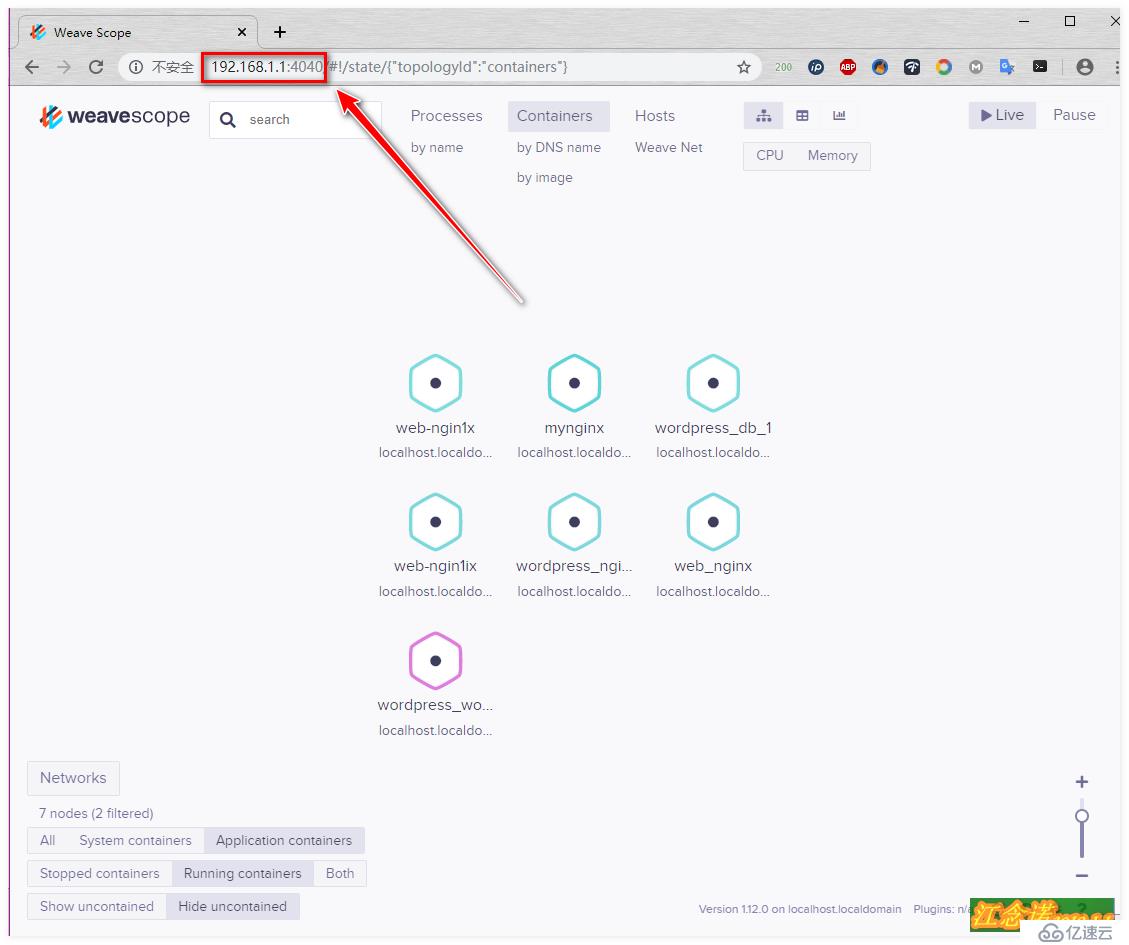
根據圖中的提示,自行可以點擊進行測試!
如果要監控兩臺的話:主機名必須進行區分方法如下:
[root@dockerA ~]# curl -L git.io/scope -o /usr/local/bin/scope
[root@dockerA ~]# chmod +x /usr/local/bin/scope
[root@dockerA ~]# scope launch 192.168.1.1 192.168.1.2 //首選指定本地的IP,再指定對方的IP
[root@dockerA ~]# docker run -itd --name http httpd //運行一個容器進行測試
[root@dockerB ~]# curl -L git.io/scope -o /usr/local/bin/scope
[root@dockerB ~]# chmod +x /usr/local/bin/scope
[root@dockerB ~]# scope launch 192.168.1.2 192.168.1.1
[root@dockerB ~]# docker run -itd --name nginx nginx訪問(dockerA、dockerB任意一臺即可)測試: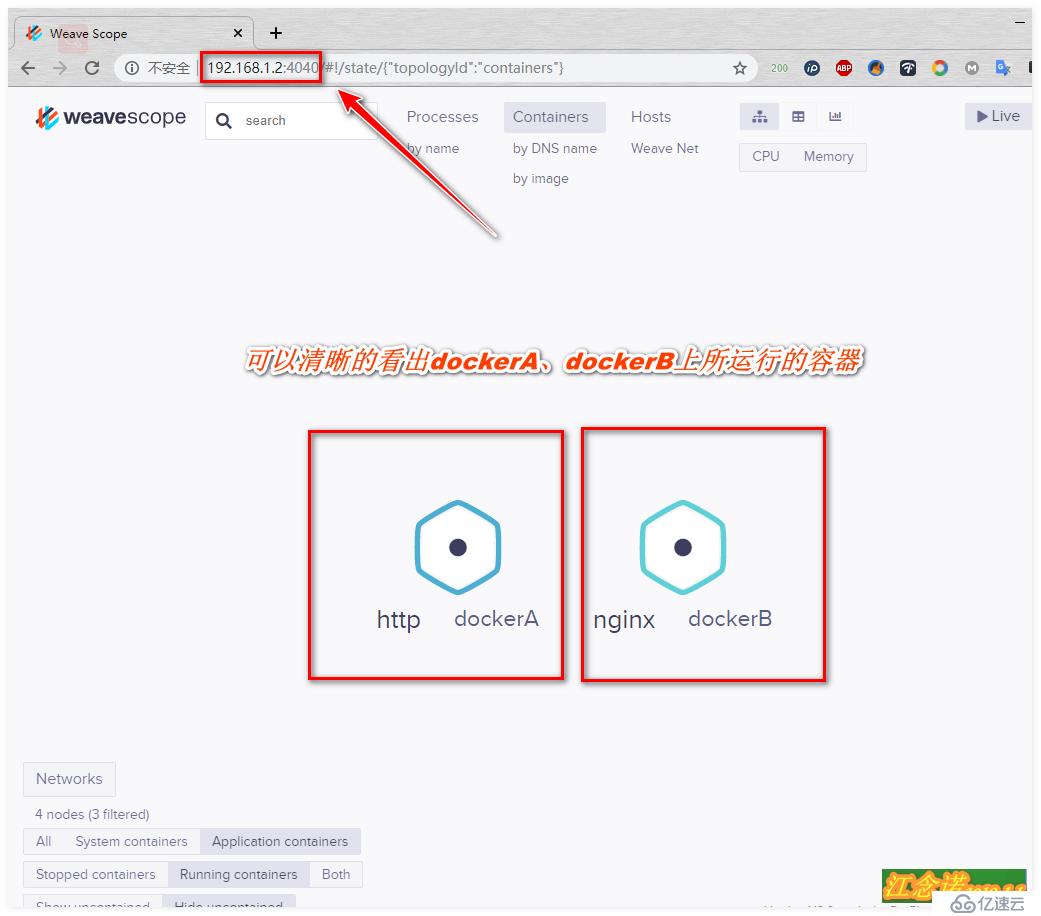
Prometheus是一套開源的系統監控報警框架。它以給定的時間間隔從已配置的目標收集指標,評估規則表達式,顯示結果,并在發現某些情況為真時觸發警報。
作為新一代的監控框架,Prometheus具有以下特點 :
- 強大的多維度數據模型:
(1)時間序列數據通過metric名和鍵值對來區分;
(2)所有的metrics都可以設置任意的多維標簽;
(3)數據模型更隨意,,不需要刻意設置為以點分隔的字符串;
(4)可以對數據模型進行聚合、切割和切片操作;
(5)支持雙精度浮點類型,標簽可以設為全unicode(統一碼);- 靈活、強大的查詢語句:在同一個查詢語句,可以對多個 metrics 進行乘法、加法、連接、取分數位等操作;
- 易于管理:不依賴于分布式存儲;
- 使用 pull 模式采集時間序列數據;
- 可以采用 push gateway 的方式把時間序列數據推送至 Prometheus server 端;
- 可以通過服務發現或者靜態配置去獲取監控的 targets;
- 有多種可視化圖形界面;
- 易于伸縮。;
Prometheus包含了許多組件,其中許多組件都是可選的,常用的組件有:
- Prometheus Server:用于收集和存儲時間序列數據;
- Client Library:客戶端庫,為需要監控的服務生成相應的 metrics 并暴露給 Prometheus server;
- Push Gateway:主要用于短期的 jobs。由于這類 jobs 存在時間較短,可能在 Prometheus 來 pull 之前就消失了。為此,這次 jobs 可以直接向 Prometheus server 端推送它們的 metrics;
- Exporters:用于暴露已有的第三方服務的 metrics 給 Prometheus;
- Alertmanager:從 Prometheus server 端接收到 alerts 后,會進行去除重復數據,分組,并路由到對端的接受方式,發出報警;
…………等等,還有好多,這里就列出幾個常用的組件!
Prometheus官方文檔中的架構圖:
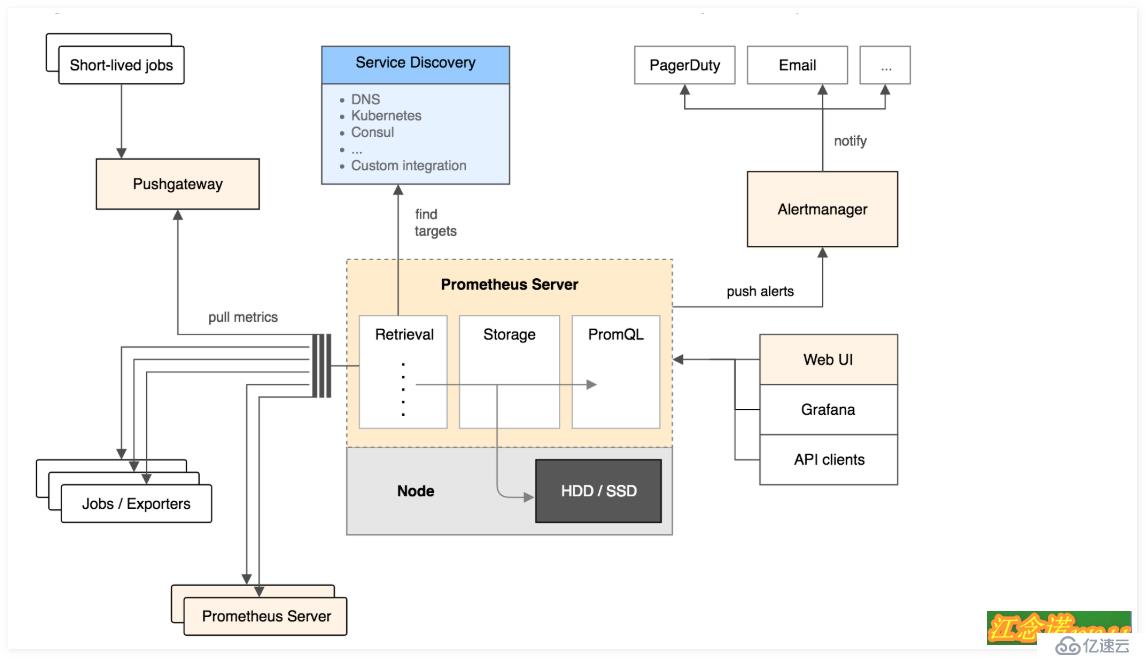
官方的架構圖中,主要模塊塊包括:Prometheus server, exporters, Pushgateway, PromQL, Alertmanager 以及圖形界面;
大致的工作流程是:
(1)Prometheus server 定期從配置好的 jobs 或者 exporters 中拉 metrics,或者接收來自 Pushgateway 發過來的 metrics,或者從其他的 Prometheus server 中拉 metrics;
(2)Prometheus server 在本地存儲收集到的 metrics,并運行已定義好的 alert.rules,記錄新的時間序列或者向 Alertmanager 推送警報;
(3)Alertmanager 根據配置文件,對接收到的警報進行處理,發出告警;
(4)在圖形界面中,可視化采集數據;
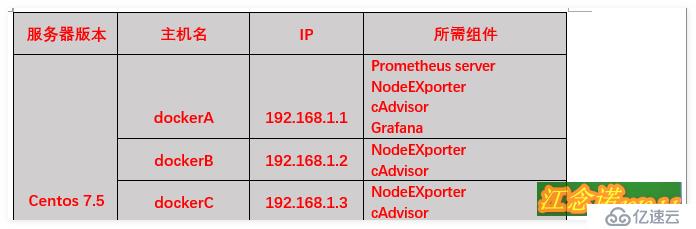
注意:上述三臺服務器上必須具備最基本的docker環境,上述環境的docker版本為18.09.0!
上述環境所需組件的作用如下:
- Prometheus server:普羅米修斯的主服務器(端口:9090);
- NodeEXporter:負責收集Host硬件信息和操作系統信息,(端口:9100);
- cAdvisor:負責收集Host上運行的容器信息(端口:8080);
- Grafana:負責展示普羅米修斯監控界面(3000);
- Alertmanager:用來接收Prometheus發送的報警信息,并且執行設置好的報警方式,報警內容(同樣也是在dockerA主機上部署,端口:9093);
各組件的關系:NodeEXporter、cAdvisor負責收集信息發送給 Prometheus server,在由 Prometheus server交給Grafana進行圖形化的顯示。如需報警,則由prometheus向Alertmanager組件發送信息!
實驗環境,為了簡單起見,關閉防火墻、SELinux,實際環境中需開啟相應的端口!
NodeEXporter主要負責收集Host硬件信息和操作系統信息!
[root@dockerA ~]# docker run -d --name node -p 9100:9100 -v /proc:/host/proc -v /sys:/host/sys -v /:/rootfs --net=host prom/node-exporter --path.procfs /host/proc --path.sysfs /host/sys --collector.filesystem.ignored-mount-points "^/(sys|proc|dev|host|etc)($|/)"
//使用prom/node-exporter 鏡像創建一個名為node的容器,用于收集硬件和系統信息;
//--net=host表示Prometheus server可以直接與node-exporter通信;
//并映射9100端口執行完成后,客戶端使用瀏覽器進行訪問,如圖: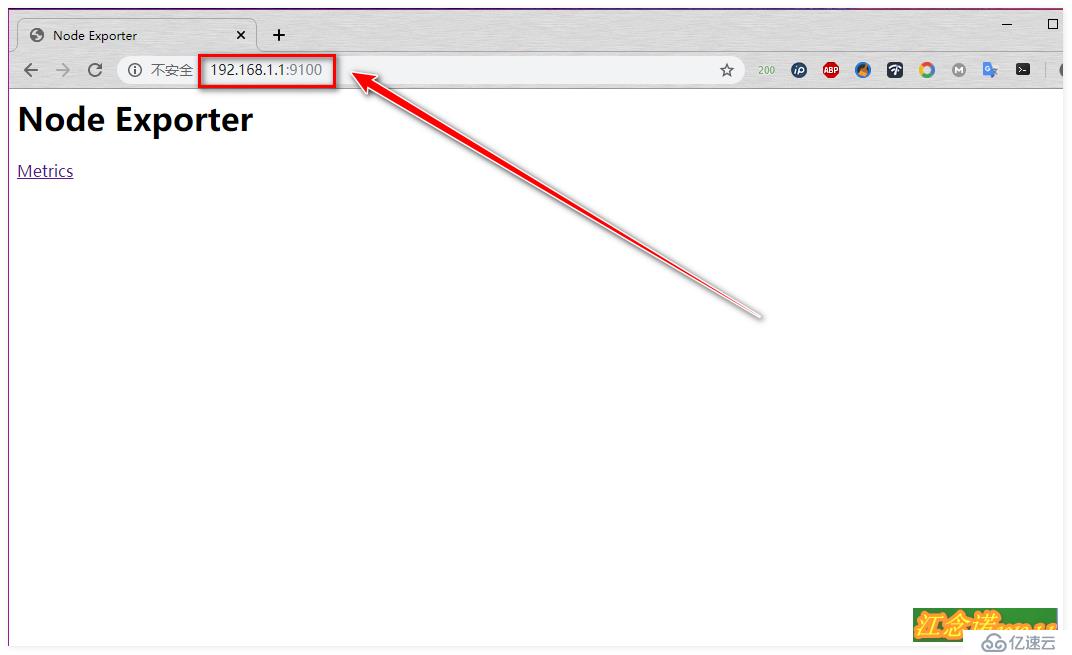
訪問到以上頁面表示node-exporter這個組件安裝成功!
由于這個NodeEXporter組件需要在三臺docker host主機上,所以以上命令就需要在另外兩臺主機上都執行。執行完成后,自行使用瀏覽器訪問測試!
cAdvisor主要負責收集Host上運行的容器信息!
[root@dockerA ~]# docker run -v /:/rootfs:ro -v /var/run:/var/run/:rw -v /sys:/sys:ro -v /var/lib/docker:/var/lib/docker:ro -p 8080:8080 --detach=true --name=cadvisor --net=host google/cadvisor客戶端訪問測試: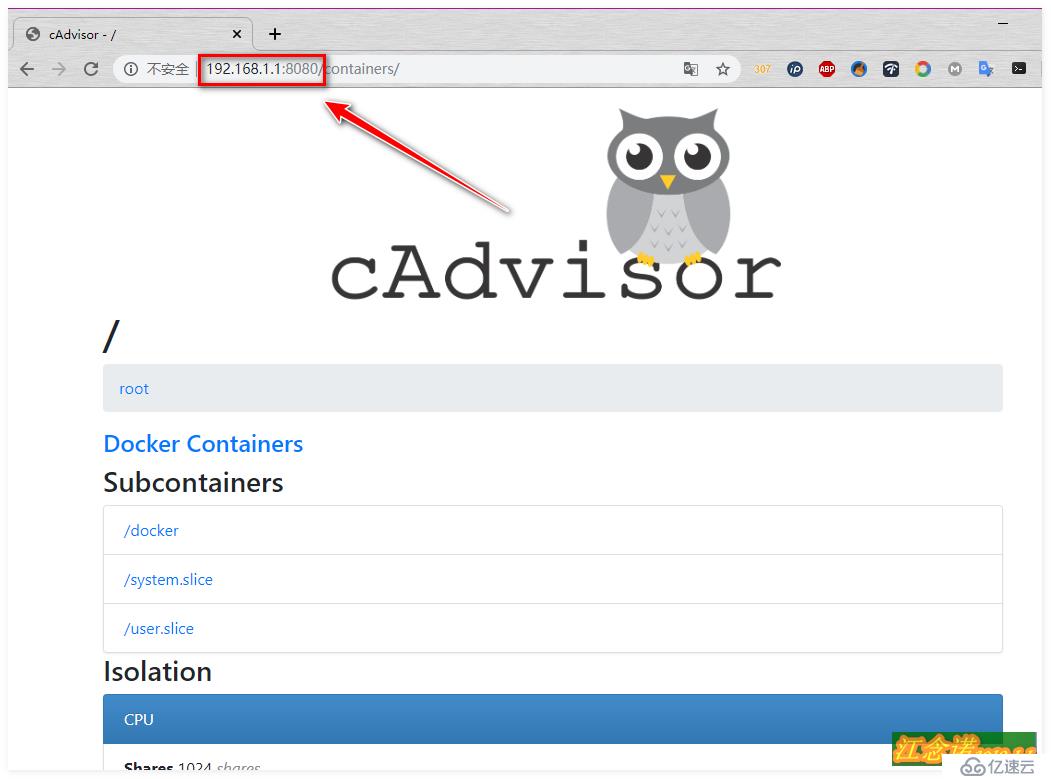
訪問到上述頁面則表示cAdvisor這個組件安裝成功!
同樣這個cAdvisor組件也是需要在三臺docker host上全部安裝的!所以以上命令也需在另外兩臺主機上執行,執行完成后,自行測試!
Prometheus是普羅米修斯的主服務器!
在部署Prometheus之前,需要對它的配置文件進行修改,所以首先運行一個Prometheus容器將其配置文件復制到本地,便于進行修改。
[root@dockerA ~]# docker run -d -p 9090:9090 --name prometheus --net=host prom/prometheus
//運行一個Prometheus容器是為了將它的配置文件拿到本地
[root@dockerA ~]# docker cp prometheus:/etc/prometheus/prometheus.yml .
//將Prometheus容器中的主配置文件復制到本地
[root@dockerA ~]# vim prometheus.yml //編輯主配置文件
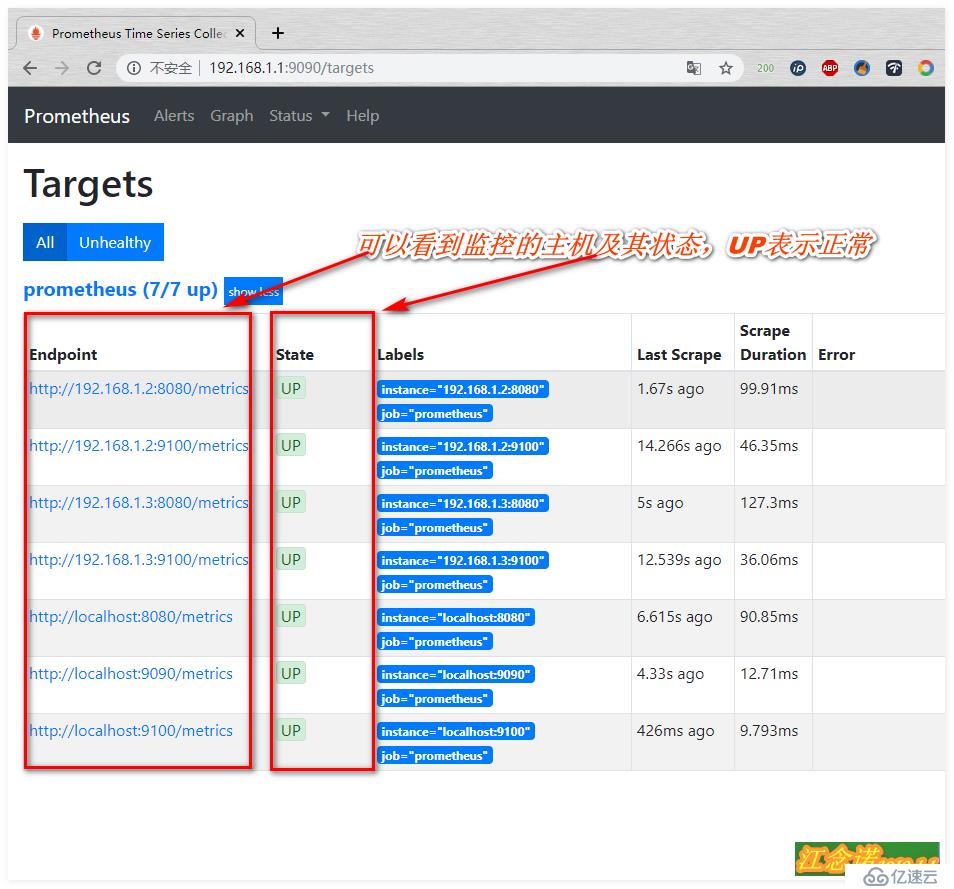
- targets: ['localhost:9090','localhost:8080','localhost:9100','192.168.1.2:8080','192.168.1.2:9100','192.168.1.3:8080','192.168.1.3:9100']
//這項原本是存在的,只需修改即可!
//用于指定監控本機的9090、8080、9100這三個端口,另外添加另外兩臺docker主機的8080、9100這兩個端口。
//8080端口運行的是cAdvisor服務
//9100端口運行的是node-exporter服務
//9090端口運行的就是Prometheus服務
[root@dockerA ~]# docker rm prometheus -f //將剛才運行的容器刪除
prometheus
[root@dockerA ~]# docker run -d -p 9090:9090 --name prometheus --net=host -v /root/prometheus.yml:/etc/prometheus/prometheus.yml prom/prometheus
//重新運行一個prometheus容器,將剛才修改完成的配置文件掛載到容器中客戶端訪問測試: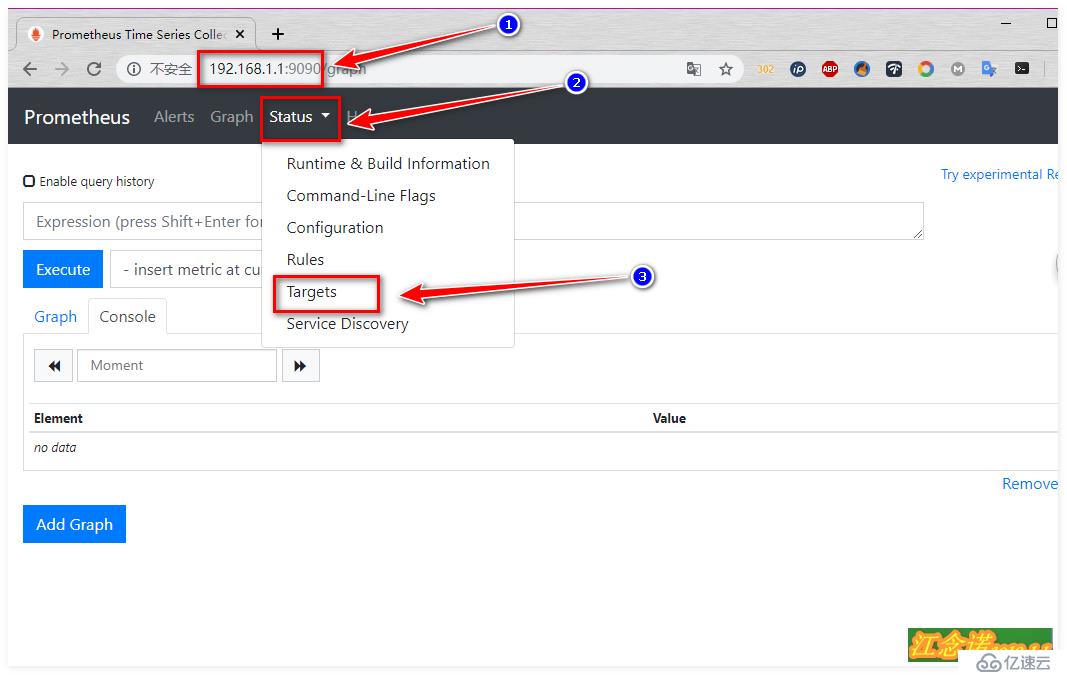
grafana主要負責展示普羅米修斯監控界面,給我們提供良好的圖形化界面!
[root@dockerA ~]# mkdir grafana-storage
[root@dockerA ~]# chmod 777 -R grafana-storage
//創建一個目錄,賦予777的權限
[root@dockerA ~]# docker run -d -p 3000:3000 --name grafana -v /root/grafana-storage:/var/lib/grafana -e "GF_SECURITY_ADMIN_PASSWORD=123.com" grafana/grafana
//“-e”選項表示修改容器內部的環境變量,將admin用戶的密碼更改為123.com;客戶端訪問測試:


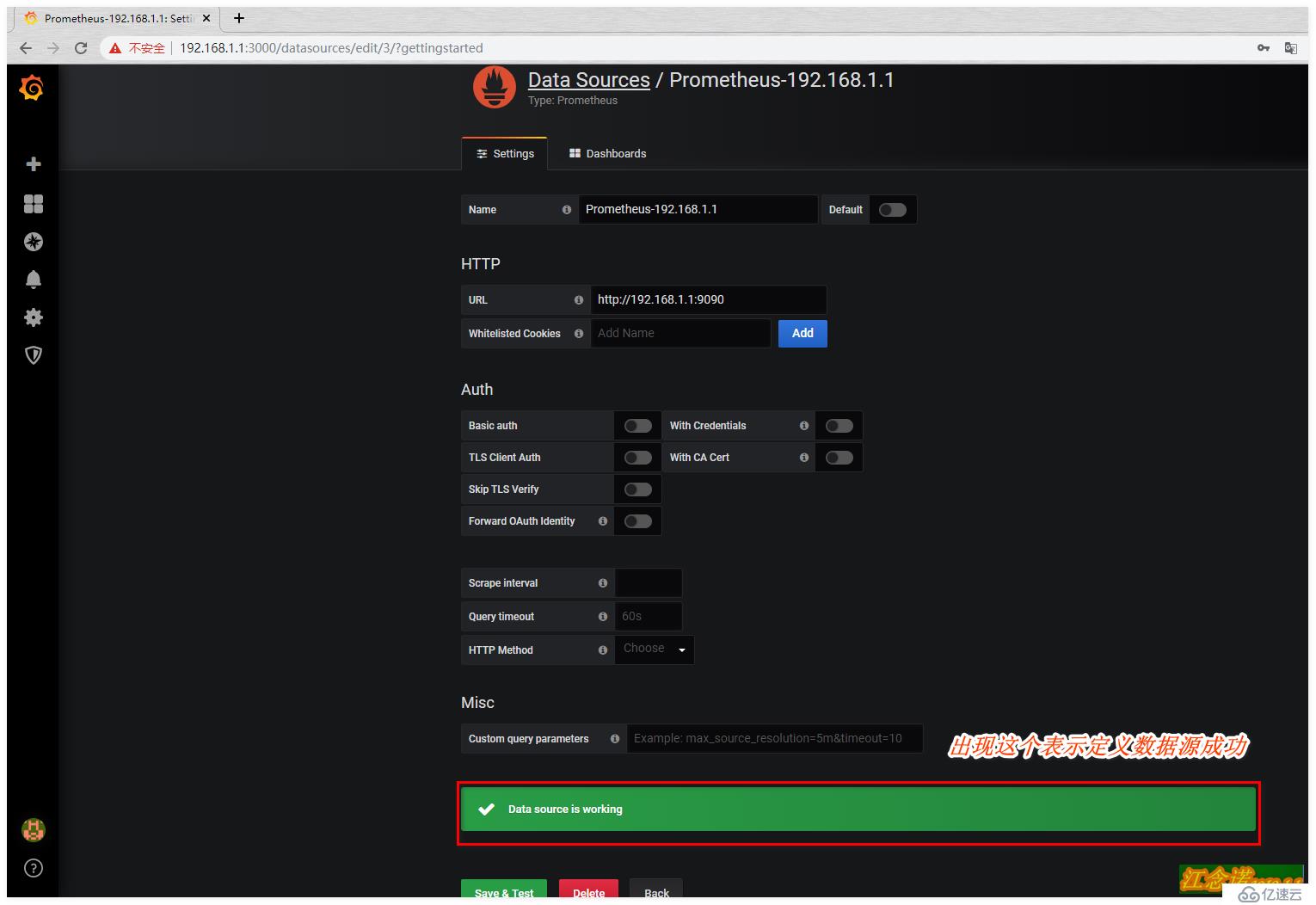
上述配置完成后,我們就需要配置它以什么樣的形式來給我們展示了,可以自定義,但是很麻煩,我選擇直接去grafana官網尋找現成的模板。如圖: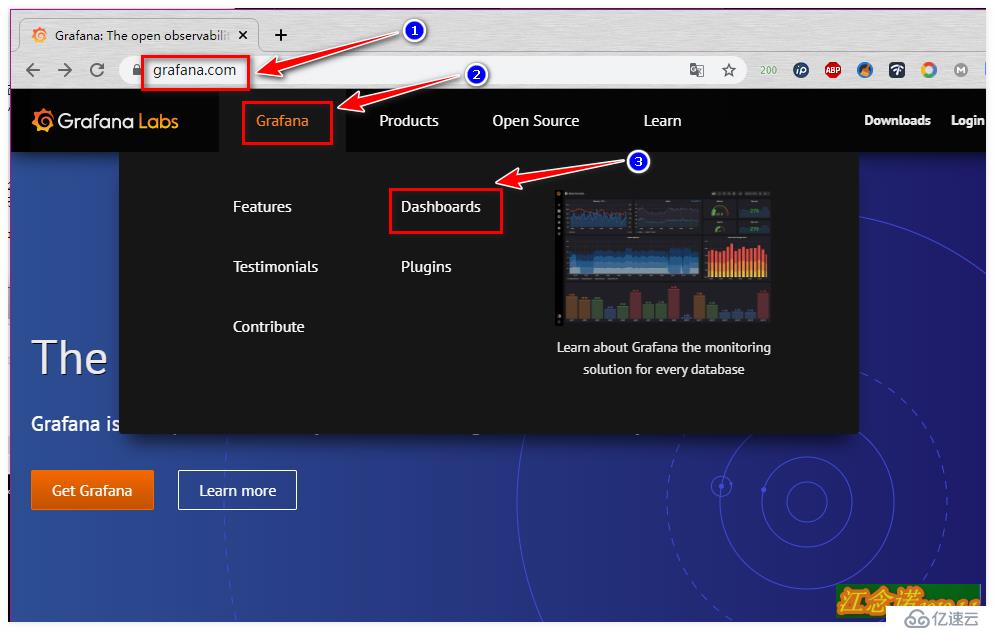
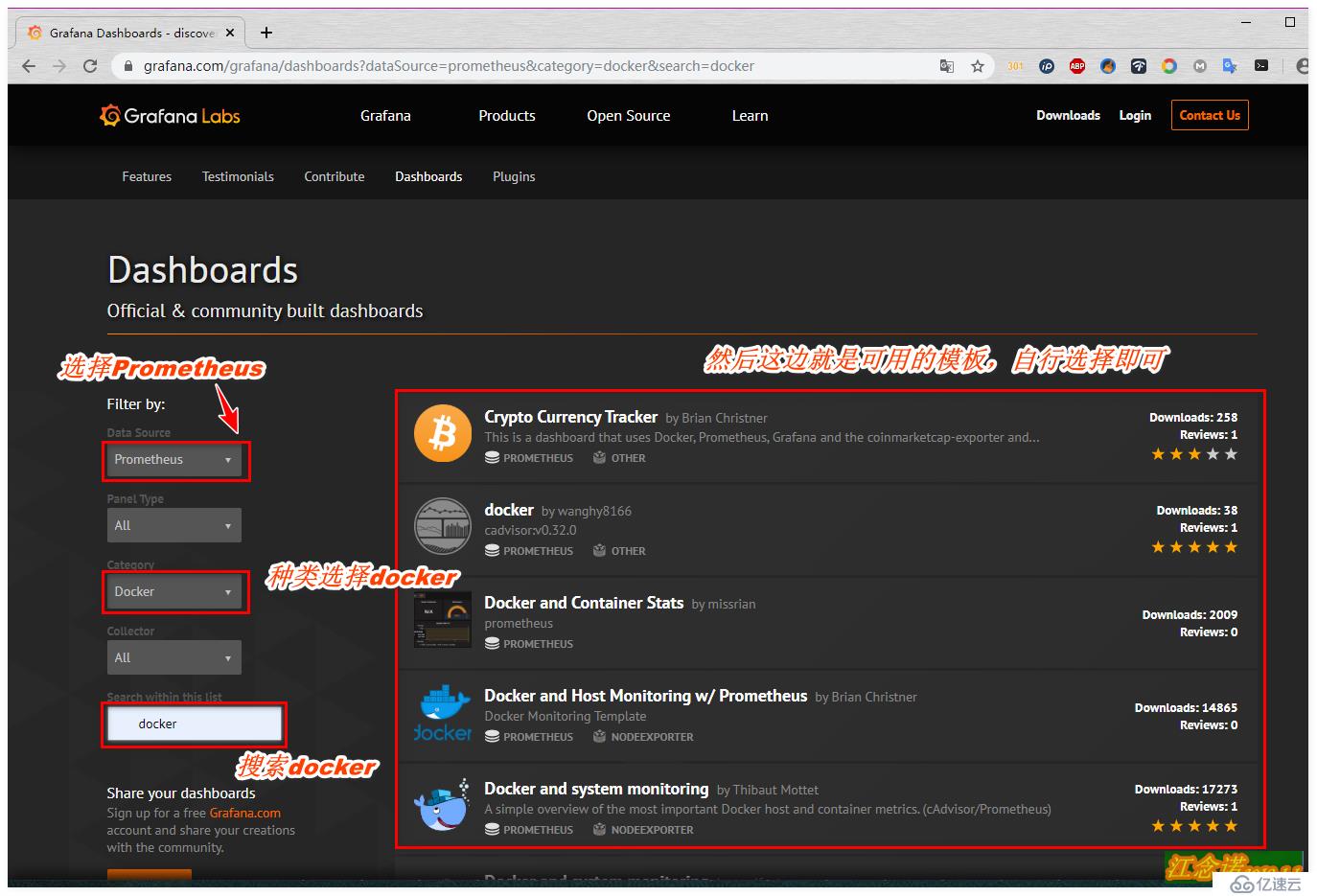
將grafana官方的模板導入到我們的grafana容器提供的web頁面中,方法有兩種方式:
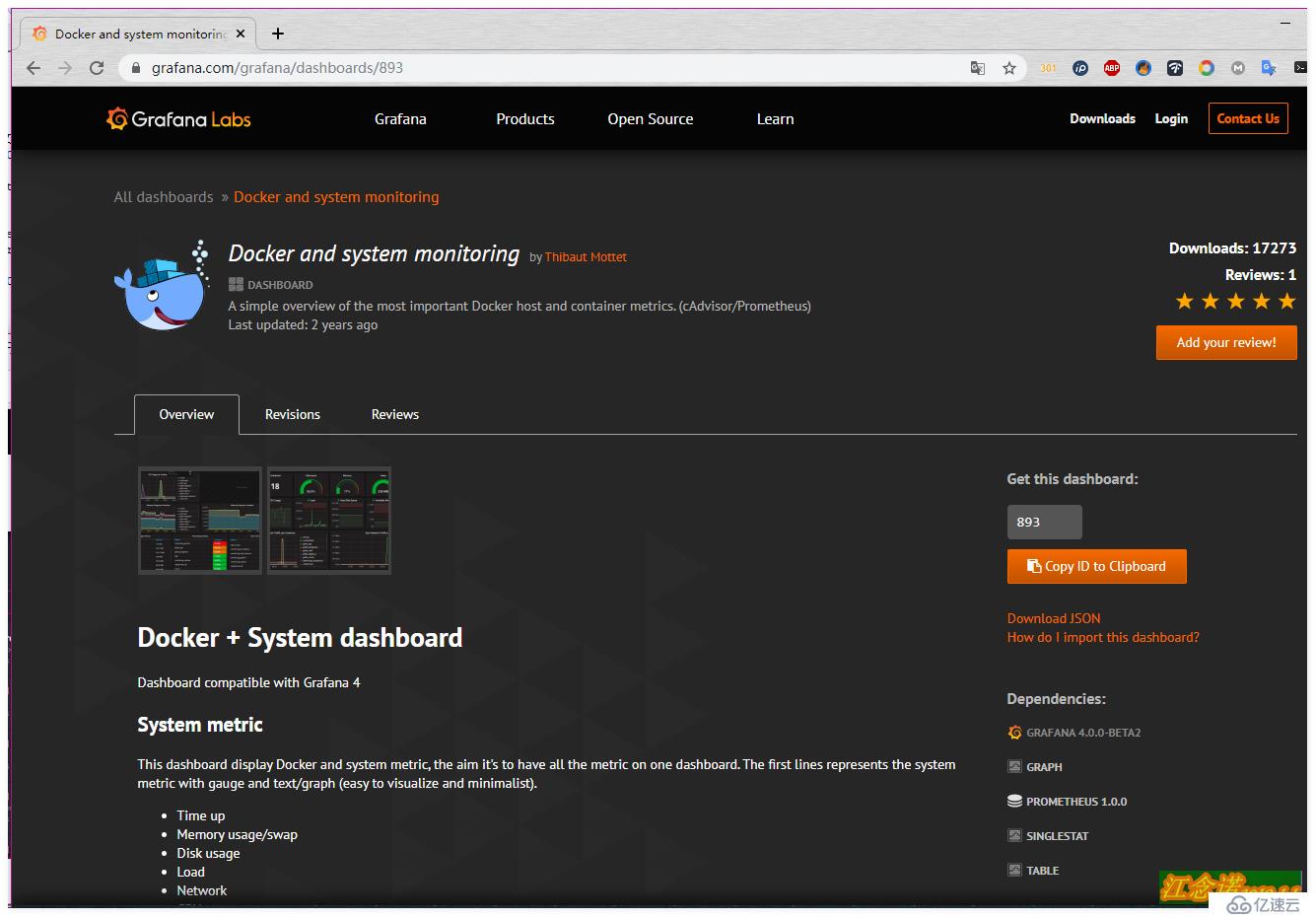
在grafana官網選擇自己喜歡的模板,點擊進入,如圖: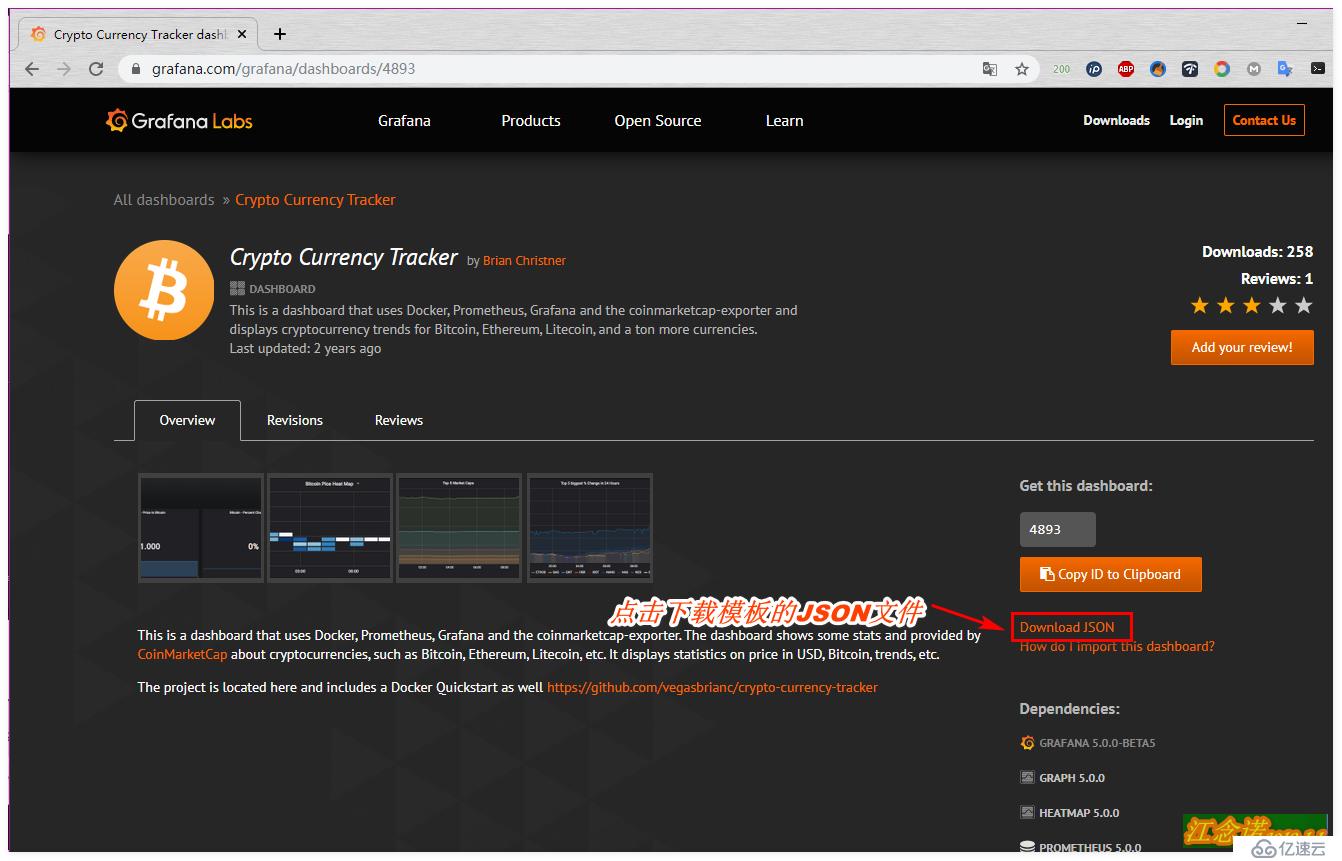
下載后,回到自己搭建的grafana容器提供的web頁面中,如圖: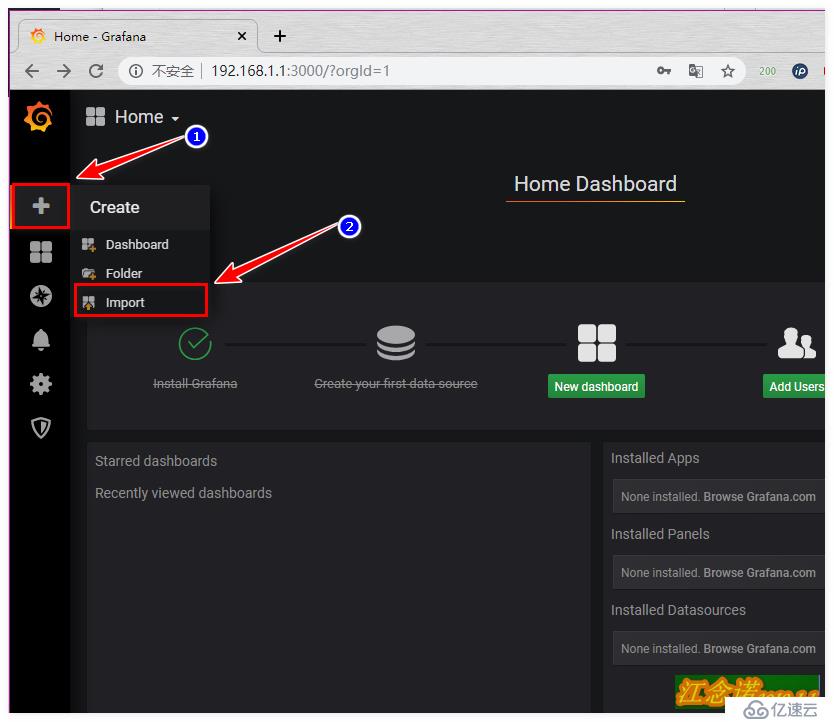
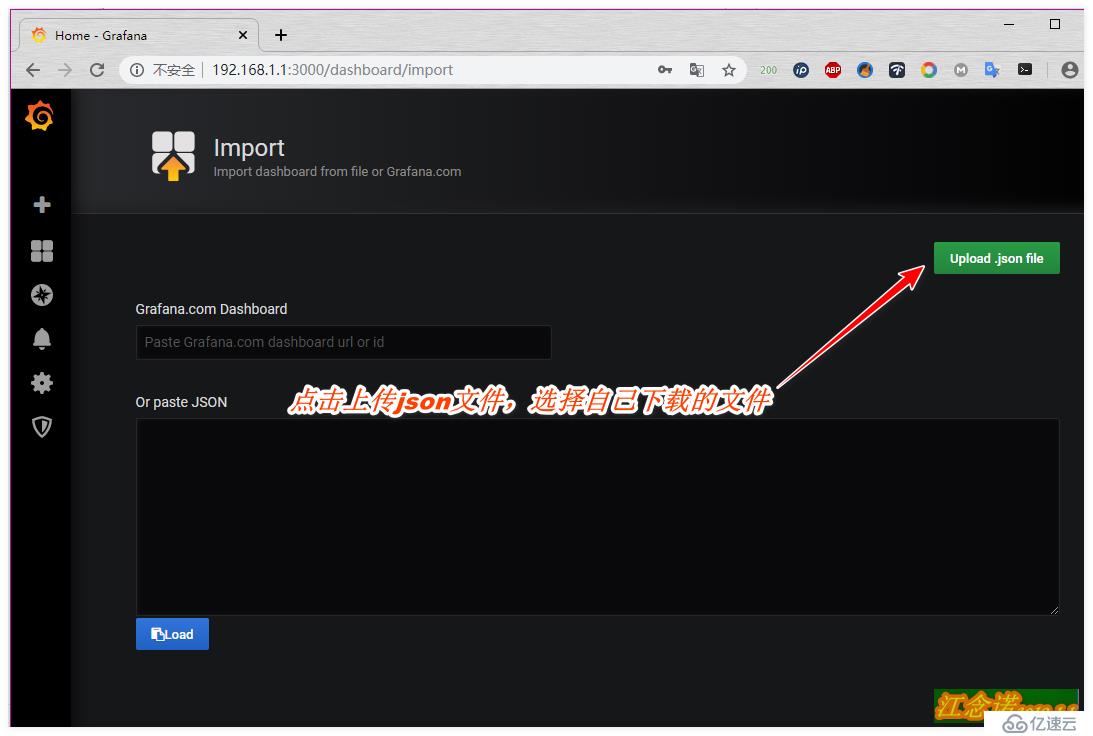
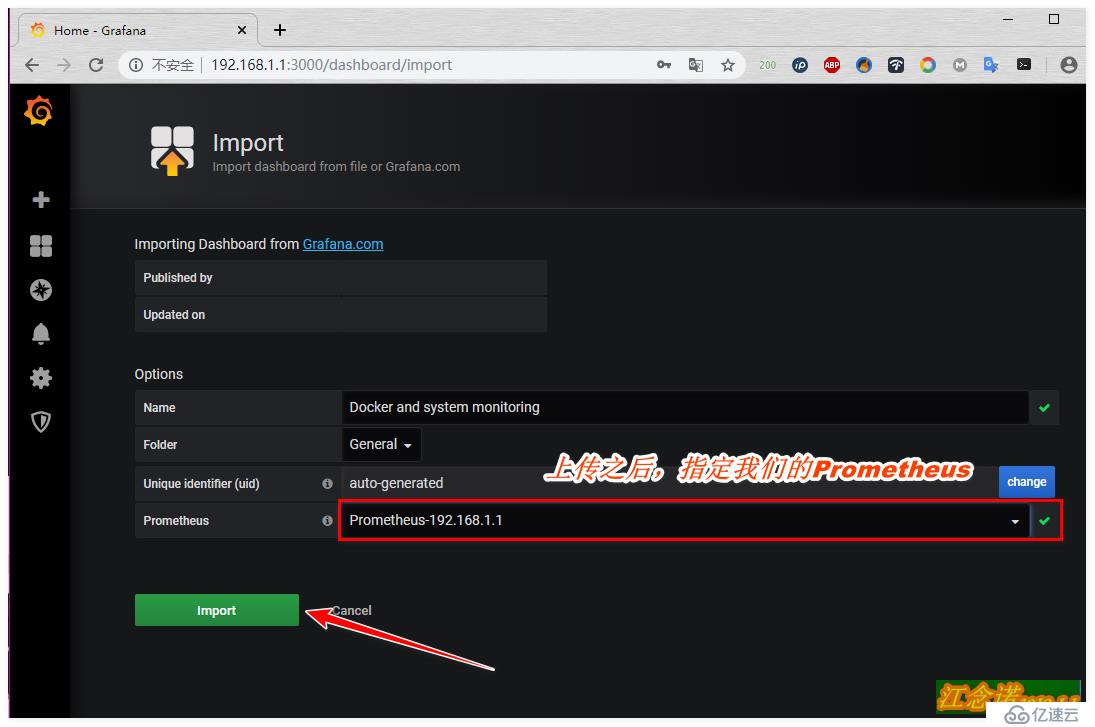
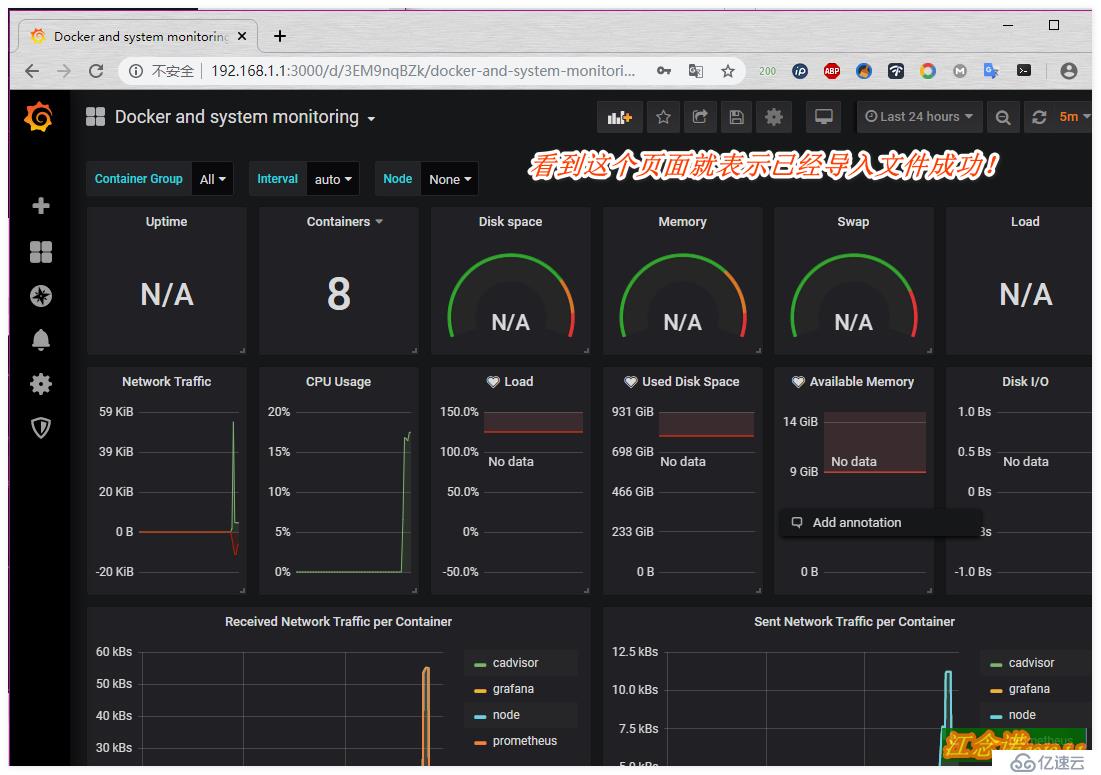
但是仔細看的話,會發現這個模板有些信息都檢測不到,所以這里就是為了展示一種方式導入模板的方式。個人建議推薦使用第二種方式!
選擇合適的模板后,記錄其ID號,如圖: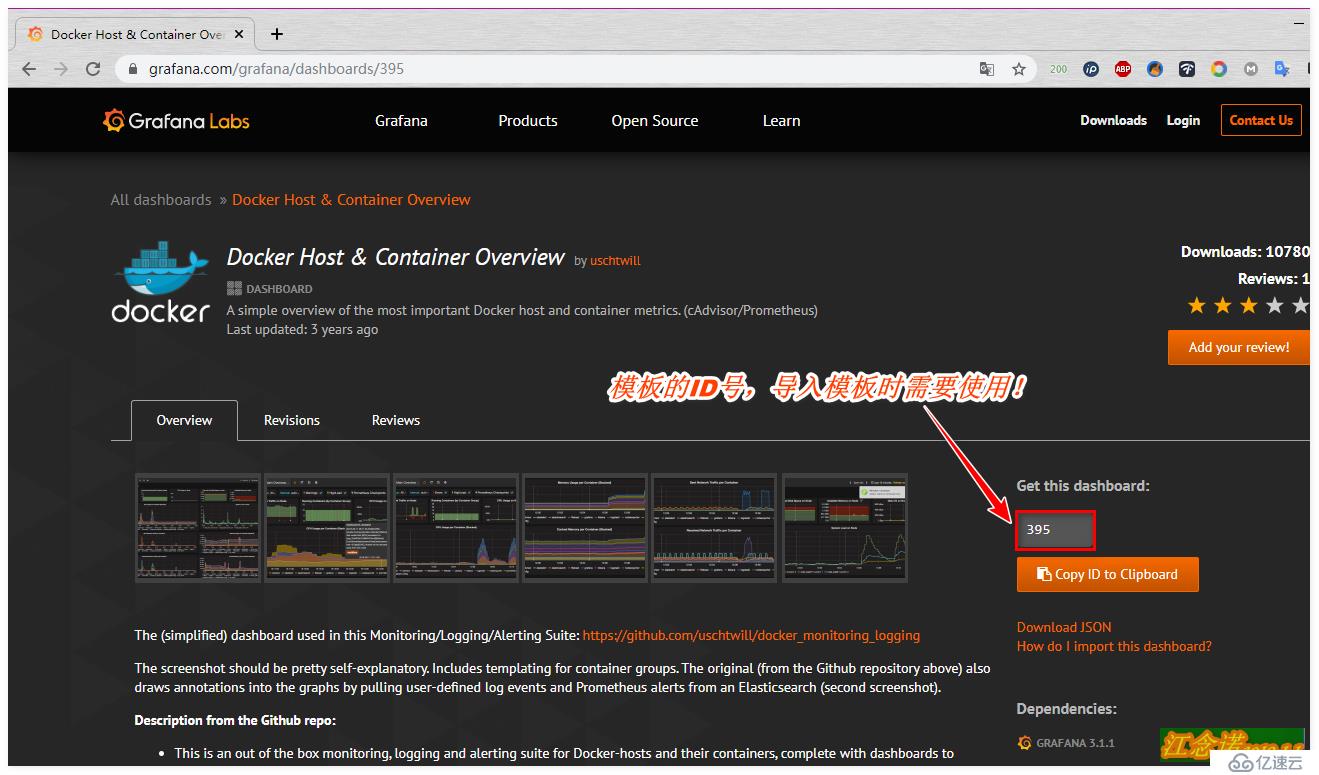
記錄下模板的ID號之后,同樣回到自己搭建的grafana容器提供的web頁面中,如圖: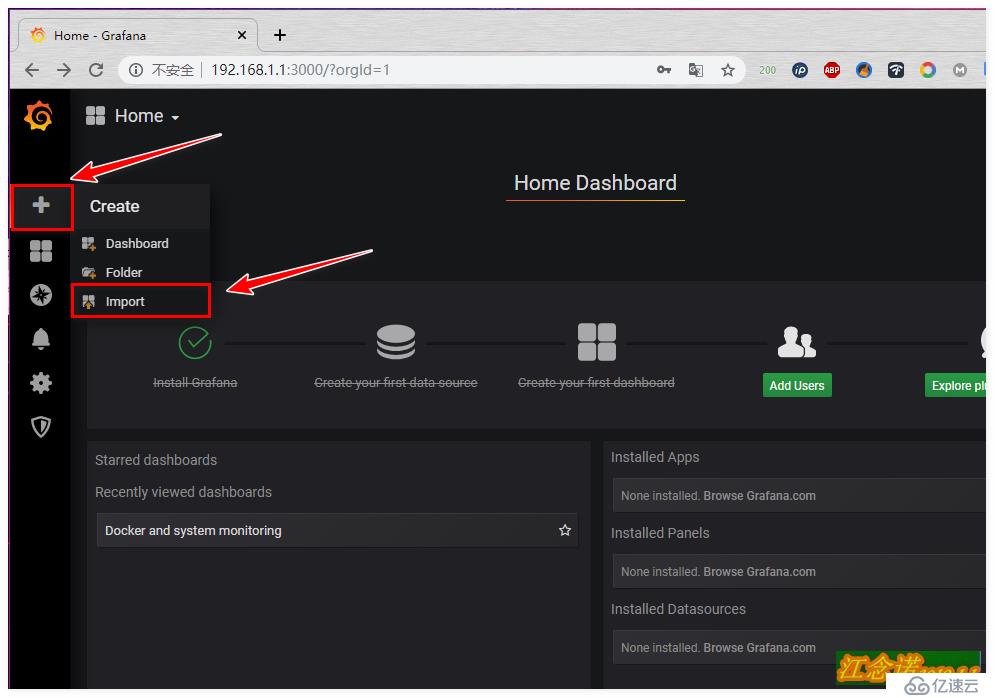
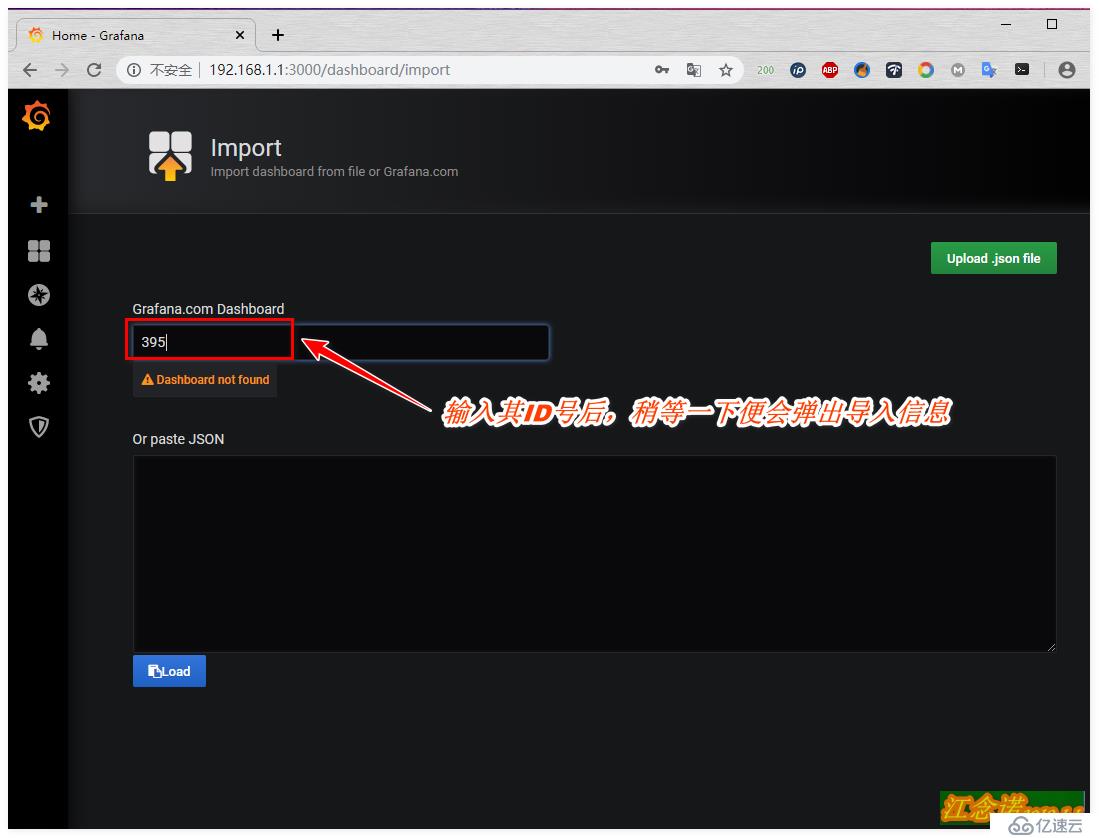
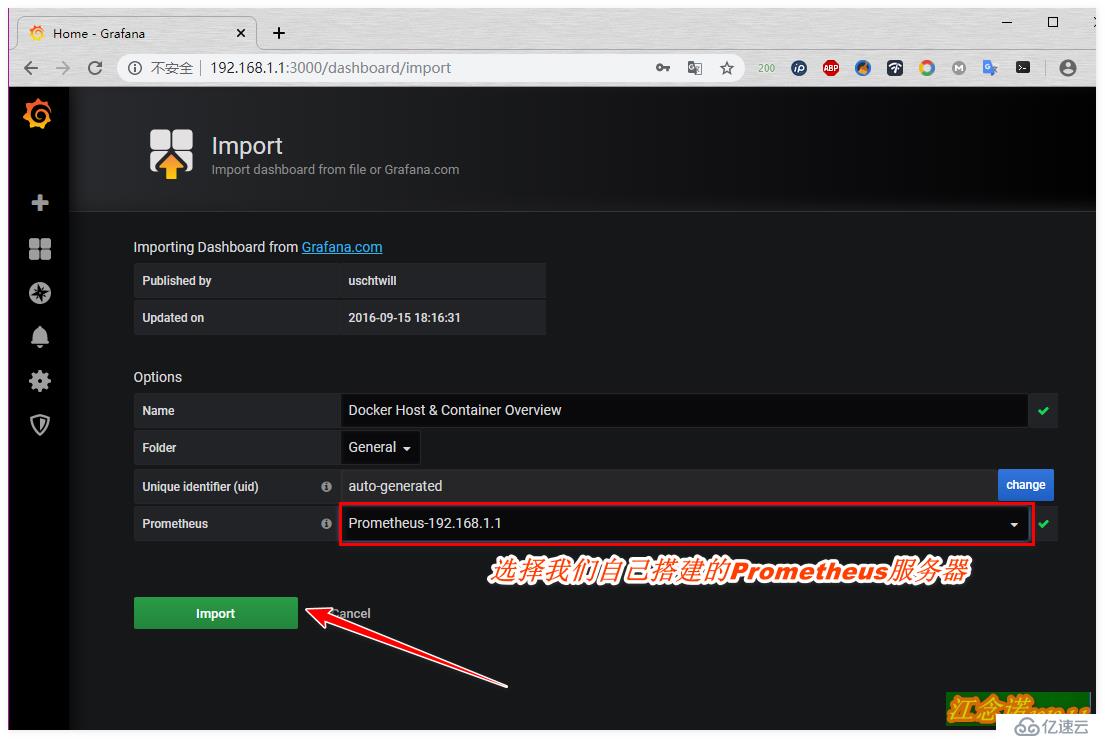
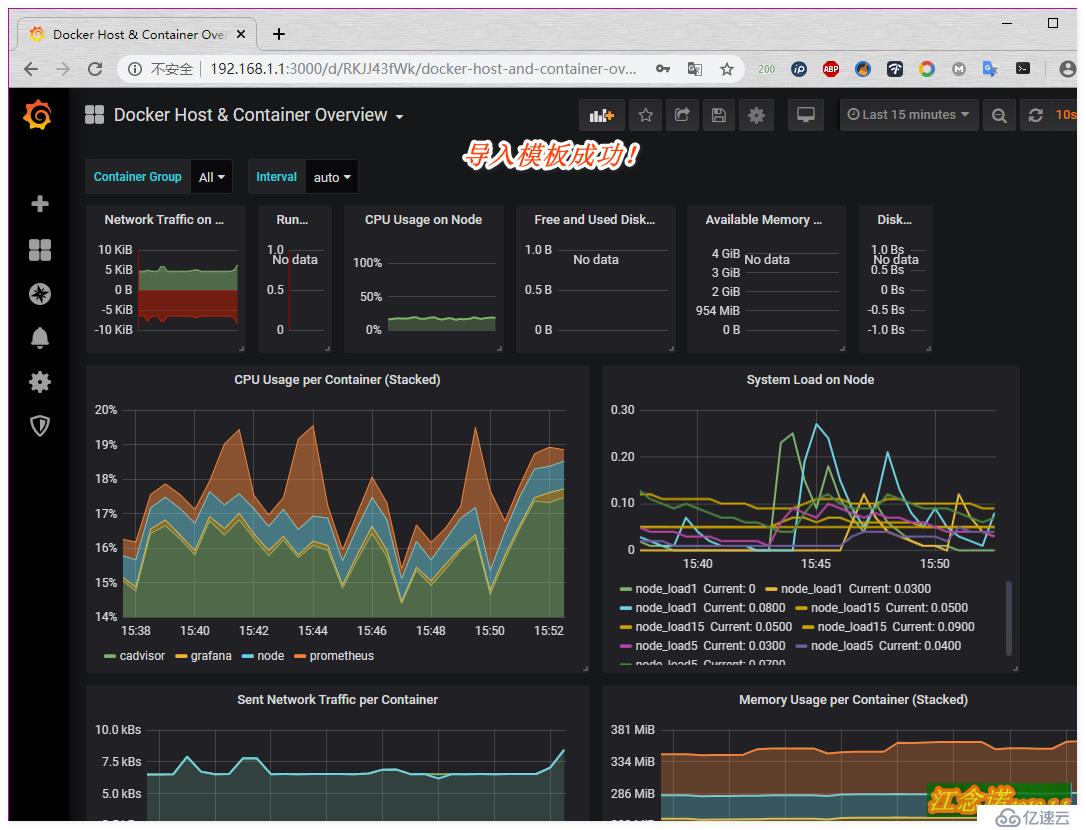
至此web界面的監控就部署完成了!
Prometheus的報警方式有好幾種,比如:郵箱、微信、釘釘等,本次案例采用郵箱告警的方式。
Alertmanager組件主要是用來接收Prometheus發送的報警信息,并且執行設置好的報警方式,報警內容;
只需在dockerA主機上部署即可!方法如下:
[root@dockerA ~]# docker run -d --name alertmanager -p 9093:9093 prom/alertmanager
//隨便運行一個容器,其目的就是將容器中服務的配置文件拿到本地
[root@dockerA ~]# docker cp alertmanager:/etc/alertmanager/alertmanager.yml .
//將altermanager服務的yml配置文件拿到本地
[root@dockerA ~]# vim alertmanager.yml //編輯配置文件
global:
resolve_timeout: 5m
smtp_from: '1454295320@qq.com' #發送者信息
smtp_smarthost: 'smtp.qq.com:465'
smtp_auth_username: '1454295320@qq.com' #接收者信息
smtp_auth_password: 'gfuxsudyqyulbaad' #使用qq郵箱生成的授權碼
smtp_require_tls: false
smtp_hello: 'qq.com'
route:
group_by: ['alertname'] #采用默認組
group_wait: 5s
group_interval: 5s
repeat_interval: 5m
receiver: 'email'
receivers:
- name: 'email'
email_configs:
- to: '1454295320@qq.com' //發送者信息
send_resolved: true //當容器恢復正常時,也會發送一份郵件
inhibit_rules:
- source_match:
severity: 'critical'
target_match:
severity: 'warning'
equal: ['alertname', 'dev', 'instance']
//配置文件中常用需要修改的地方已經做了備注alertmanager.yml配置文件中一級字段:
- global:全局配置(包括報警解決的超時時間、SMTP相關配置、各種渠道通知的API地址等新消息);
- route:用來設置報警的分發策略;
- receivers:配置告警消息接收者信息;
- inhibit_rules:抑制規則配置,當存在與另一組匹配的警報時,抑制規則將僅用于一組匹配的;
[root@dockerA ~]# docker rm -f alertmanager //將原本的alertmanager 容器刪除
[root@dockerA ~]# docker run -d --name alertmanager -p 9093:9093 -v /root/alertmanager.yml:/etc/alertmanager/alertmanager.yml prom/alertmanager
//重新運行alertmanager 容器,并將配置文件掛載到容器中
//建議運行容器之后,使用docker ps | grep alertmanager 確保容器正常運行
//如果配置文件編寫錯誤,那么這個容器是無法啟動的[root@dockerA ~]# mkdir -p prometheus/rules && cd prometheus/rules
//創建目錄用于存放規則的目錄
[root@dockerA rules]# vim node-up.rules //編寫規則
groups:
- name: node-up //自定義名稱
rules:
- alert: node-up
expr: up{job="prometheus"} == 0
// job的名稱必須和prometheus配置文件中的 - job_name: 'prometheus'對應
for: 15s
labels:
severity: 1
team: node
annotations:
summary: "{{ $labels.instance }} 已停止運行超過 15s!"可以根據以上配置文件進行修改,若想自己編寫報警規則,可以參考它的官方文檔,如圖:
[root@dockerA ~]# vim prometheus.yml
8 alerting:
9 alertmanagers:
10 - static_configs:
11 - targets:
12 - 192.168.1.1:9093 //此行將原本的內容更改為alertmanager容器的IP+端口
13
14 # Load rules once and periodically evaluate them according to the global 'evaluat ion_interval'.
15 rule_files:
16 - "/usr/local/prometheus/rules/*.rules" //這一行需要手動添加,指定容器內的路徑
[root@dockerA ~]# docker rm -f prometheus //修改完配置為文件后,需要將容器刪除,重新運行一臺新的容器
[root@dockerA ~]# docker run -d -p 9090:9090 --name prometheus --net=host -v /root/prometheus.yml:/etc/prometheus/prometheus.yml -v /root/prometheus/rules/node-up.rules:/usr/local/prometheus/rules/node-up.rules prom/prometheus
//指定步驟(2)編寫的rule文件的路徑,為防止格式可能會出現錯誤,附上截圖一張,如下: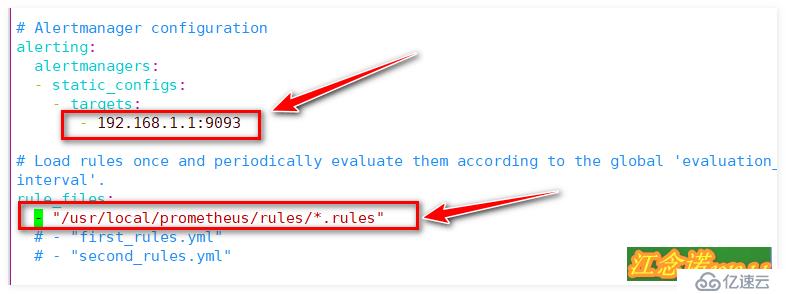
至此,如果prometheus頁面中的target有異常(比如宕機),那么就會給你的郵箱發送報警信息。
我手動停掉容器,收到的郵件如下: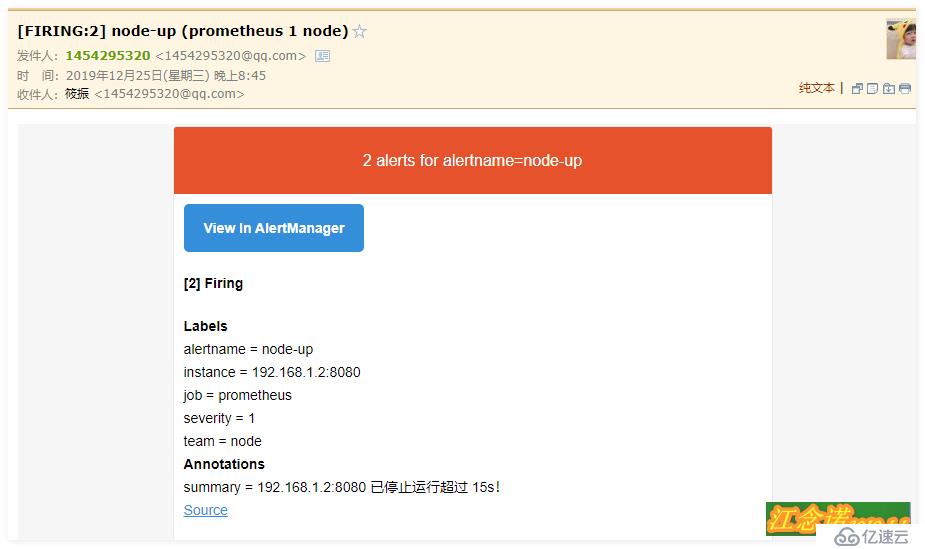
為了追求美觀,我們采取設置一下報警信息的模板!
[root@dockerA ~]# cd prometheus
[root@dockerA prometheus]# mkdir alertmanager-tmpl
[root@dockerA prometheus]# cd alertmanager-tmpl/
[root@dockerA prometheus]# vim email.tmpl
{{ define "email.from" }}1454295320@qq.com{{ end }}
{{ define "email.to" }}1454295320@qq.com{{ end }}
{{ define "email.to.html" }}
{{ range .Alerts }}
=========start==========<br>
告警程序: prometheus_alert<br>
告警級別: {{ .Labels.severity }} 級<br>
告警類型: {{ .Labels.alertname }}<br>
故障主機: {{ .Labels.instance }}<br>
告警主題: {{ .Annotations.summary }}<br>
觸發時間: {{ .StartsAt.Format "2019-08-04 16:58:15" }} <br>
=========end==========<br>
{{ end }}
{{ end }}
[root@dockerA ~]# vim alertmanager.yml
global:
resolve_timeout: 5m
smtp_from: '1454295320@qq.com'
smtp_smarthost: 'smtp.qq.com:465'
smtp_auth_username: '1454295320@qq.com'
smtp_auth_password: 'flnuwdktcbzwffag'
smtp_require_tls: false
smtp_hello: 'qq.com'
templates: //添加此行
- '/etc/alertmanager-tmpl/*.tmpl' //指定容器中模板的路徑
route:
group_by: ['alertname']
group_wait: 5s
group_interval: 5s
repeat_interval: 5m
receiver: 'email'
receivers:
- name: 'email'
email_configs:
- to: '{{ template "email.to" }}' //必須和模板中對應
html: '{{ template "email.to.html" . }}' //必須和模板中對應
send_resolved: true
inhibit_rules:
- source_match:
severity: 'critical'
target_match:
severity: 'warning'
equal: ['alertname', 'dev', 'instance']
[root@dockerA ~]# docker rm alertmanager -f
//刪除容器
[root@dockerA ~]# docker run -d --name alertmanager -p 9093:9093 -v /root/alertmanager.yml:/etc/alertmanager/alertmanager.yml -v /root/prometheus/alertmanager-tmpl:/etc/alertmanager-tmpl prom/alertmanager
//創建容器本地創建的模板文件
//創建完成后,確定容器是正常運行至此,新的報警模板也生成了,如果以下容器有Down的,就會給你發送新的郵件,恢復正常后,也會發送郵件,同樣,郵件中的內容格式是有誤的,但是你可以正常接收到報警信息,若想要更改其報警模板,可以參考官方文檔
郵箱收到的報警信息如下: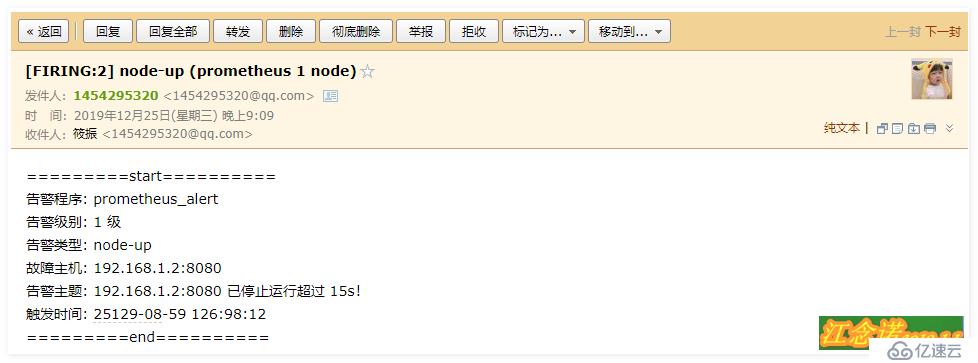
比原本的效果要好很多!就簡單介紹一下這一個吧,有興趣可以參考官網的文檔,自行進行編寫!
————————————本文到此結束,感謝閱讀————————————
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





