溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
反deepfake陣營今日又有新成果,商湯入局,獻出迄今最大檢測數據集:
包含 60000個視頻,共計 1760萬幀,是現有同類數據集的10倍。
deepfake進化了一版又一版,效果越來越逼真,門檻卻越來越低。

不僅是明星們,連普通人都不禁瑟瑟發抖。
眼見亦不為實,難道就沒有什么能制住AI換臉了?
其實,魔高一尺時,道也未曾停止修煉。并且,還要以彼之道,還施彼身。
現在,商湯就攜手新加坡南洋理工的研究人員們,推出了迄今為止最大的deepfake檢測數據集, DeeperForensics-1.0。

并且,更接近現實場景,更具多樣性、挑戰性。
數據、代碼和預訓練模型,正在開源的路上。
在DeeperForensics-1.0的60000個視頻中,有50000個是研究團隊收集的原始視頻,剩下的10000則是他們造出來的“偽視頻”。
數據集的打造,一共分為三步。
第一步,是 數據采集。
將真實視頻中原本的人臉稱作目標人臉,被替換上去的人臉稱作源人臉,研究人員發現,在構建高質量數據集的過程中,源人臉比目標人臉起到了更為關鍵的作用。
源人臉的表情、姿勢和拍攝時的照明條件越豐富,人臉交換的可靠性就越高。
于是,研究人員雇傭了100位演員來參與人臉視頻的錄制。他們分別來自26個不同的國家,其中有53名男性和47名女性,年齡范圍在20-45歲之間,四種膚色(白,黑,黃,棕)比例為1:1:1:1。

這些視頻的錄制分辨率為1920×1080。拍攝過程中,演員們被要求展示各種不同的表情:中立,憤怒,快樂,悲傷,驚訝,鄙視,厭惡,恐懼等。
臉部面對鏡頭的角度在-90°到90°之間變化。還設置了九種不同的照明效果。

第二步, 以假治假。
知己知彼,百戰不殆。
為了生成更真的假視頻,研究人員提出了一種新的人臉交換框架:DeepFake變分自動編碼器(DeepFake Variational Auto-Encoder,DF-VAE)。

DF-VAE由三個模塊組成:結構提取模塊,解耦模塊和融合模塊。
在訓練中,通過提取標志物、構造未配對的樣本作為條件,重構源人臉和目標人臉。
重構后,最小化光流差異來改善時間連續性。
而MAdalN模塊,負責會將重現的面孔與原始背景融合到一起。

第三步,是進一步提升難度, 加入擾動模擬真實場景中的視頻。
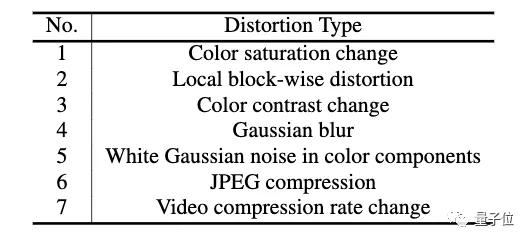
具體而言,就是在視頻中加入色彩飽和度變化、局部圖像塊失真、色彩對比變化、高斯模糊、色彩分量中的高斯白噪聲、JPEG壓縮和視頻壓縮率變化這七種失真。
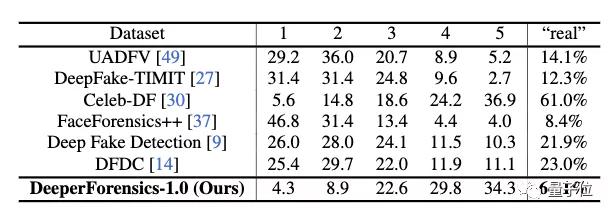
為了評估DeeperForensics-1.0的質量,研究人員邀請了100位計算機視覺專家對其進行評分。
根據反饋,專家們認為,與FaceForensics++、Celeb-DF等流行的Deepfake檢測數據集相比,DeeperForensics-1.0更加真實。
假視頻越演越真,引發了廣泛的擔憂。
以AI治AI的行動,也早已展開。
此前,Facebook就壕擲千萬,舉辦換臉視頻檢測挑戰賽。
UC伯克利EECS教授Hany Farid評價說:
為了從信息時代走向知識時代,我們必須更好的辨明真偽,獎真懲假,教育下一代成為更好的數字公民。這需要全面的投資,需要工業界、學界、非政府組織一同努力研究,發展和實施能快速精準辨別真偽的技術。
美國初創公司Truepic,則以打擊AI造假照片、視頻為核心業務,在2019年7月籌集了800萬美元(約合5680萬人民幣)資金。
國內,2019年11月底印發的《網絡音視頻信息服務管理規定》,則可視作針對AI造假視頻的一次針對性管控。

這項規定已于1月1日正式施行。
項目地址:
https://liming-jiang.com/projects/DrF1/DrF1.html
論文地址:
https://arxiv.org/abs/2001.03024
VB報道:
https://venturebeat.com/2020/01/15/sensetime-face-forgery-research-deepfakes/
— 完 —
https://www.toutiao.com/i6782403843717071368/
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





