溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
隨著大數據技術在各行各業的廣泛應用,要求能對海量數據進行實時處理的需求越來越多,同時數據處理的業務邏輯也越來越復雜,傳統的批處理方式和早期的流式處理框架也越來越難以在延遲性、吞吐量、容錯能力以及使用便捷性等方面滿足業務日益苛刻的要求。
在這種形勢下,新型流式處理框架Flink通過創造性地把現代大規模并行處理技術應用到流式處理中來,極大地改善了以前的流式處理框架所存在的問題。飛馬網于3月13日晚,邀請到大數據技術高級架構師—曠東林,在線上直播中,曠老師向我們分享了Flink在諸多方面的創新以及它本身所具有的獨特能力。

我們主要從以下幾個部分來看:
一.流式處理的背景:
傳統的大數據處理方式一般是批處理式的,也就是說,今天所收集的數據,我們明天再把今天收集到的數據算出來,以供大家使用,但是在很多情況下,數據的時效性對于業務的成敗是非常關鍵的。
1.流式處理的背景—必要性

比如說,在***檢測的場景下,我們希望看到的結果是:一旦有***,我們能及時地作出響應。這種情況下,如果按照傳統的批處理方式,是不可能在***的時候實時檢測出結果的。另外,比如說在語音計算中,我們要實時監控各個虛擬器的運行狀態以及出現錯誤時的預警,這種情況下,也要求我們能夠實時監控數據,并對數據產生的各種報警,實時采取動作。由此,流式處理的必要性就顯得無疑了。
2.流式處理的背景—基礎架構
我們來看一下流式處理的基本框架。
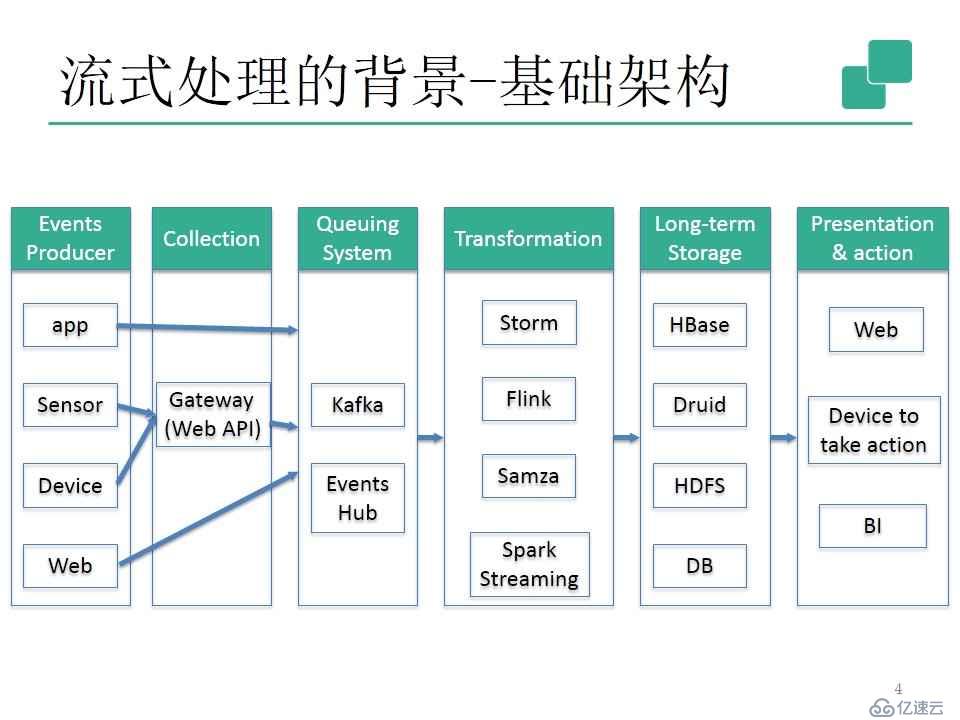
主要分為六個部分:事件生產者、收集、排隊系統(其中kafka的主要目的是,在數據高峰時,暫時把它緩存,防止數據丟失。)、數據變換(也就是流式處理過程)、長期存儲、陳述/行動。
3.流式處理的背景—評測指標
目前的業界有很多流式處理的框架,在這么多框架中,我們怎樣評價這個流式處理框架的性能呢?有哪些指標呢?一般我們會從以下這些方面來考核流式處理框架的能力。

其中“數據傳輸的保障度”,是指能不能保證數據被處理并到達目的地。它有三種可能性:保證至少一次、最多一次、精確一次。大多數情況下,“保證至少一次”就能滿足業務要求,除要求數據精確度高的特定場景。
“處理延遲”,在大多數情況下,流式處理的延遲越低越好,但很多情況下,我們的延遲越低,相應付出的代價也越高,“吞吐量”與“處理延遲”就是一對矛盾。吞吐量高,相應的延遲就會低,吞吐量低,相應的延遲就會高。
“狀態管理”,我們在實時變換的過程中,要有與外部的交互,如***檢測,以此來保護環境和數據的安全。
“容錯能力”和“容錯負荷”要求當流式處理在正常進行中,即使有某些機器掛掉,系統仍能正常運行,整個流式處理框架不受影響。
“流控”,也就是流量控制,我們在數據傳輸的過程中,可能會數據突然增多,為了保證系統不至于負荷過重而崩潰,這時候就需要控制數據密度。
“編程復雜性”,相對而言,API設計地越高級,編程負擔越低。
4.流式處理的背景—選型
了解流式處理框架的考核標準之后,那么我們為什么選擇Flink?Flink有哪些優勢呢?

“保證帶狀態計算下的精確一次語義”,對于某些特定的計算而言非常有必要。
一般在流式處理框架中,數據的處理一般有兩種方式,一種是按照處理時間來處理數據,另一種就是按照事件時間來處理數據,“事件時間語義支持”方式更為復雜。
Flink的API非常高級,在處理流式數據的邏輯業務中,效率更高。
二.Flink的原理:
了解Flink的背景之后,我們一起來看一看它的原理。
1.概述
Flink的整個組件類似于Spark,它的核心是一個分布式的流式處理框架,在核心之上,有兩套API,一套應用于批處理—DataSet API,一套應用于流式處理—DataStream API。

從圖中我們可以看到,在兩套API下又有更為高級的庫,而它的整個處理部署方式可以支持本地、集群、云端。
2.基礎架構
Flink的整個架構和Spark很相似,有三個主要部分。
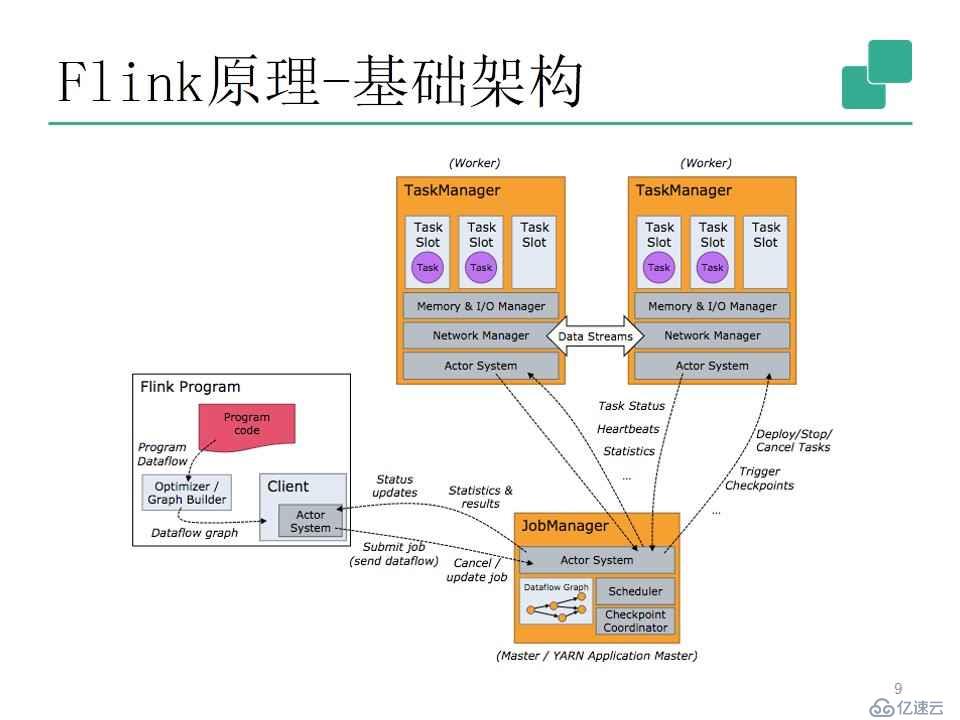
一個是提交任務的客戶端—Flink Program;還有作業的管理器—JobManager,主要負責任務的調度和狀態的檢測,以及在整個集群出現故障時進行初步管理;最后是任務管理器—TaskManager,實現業務邏輯的執行,負責把接受到的任務運行之后,將相應的結果輸出到外部或進行外部交互。
在整個過程中,JobManager是不負責任務執行的。
3.編程模型
下面我們來看一下Flink的具體編程模型結構。
第一條語句是建立整個Flink運行時的環境,類似于Spark里建立一個上下文。它的主要業務邏輯是由指定數據源、指定變換邏輯、指定輸出三部分決定的。
指定數據源的過程就是nv.addSource,這是指定我們的數據到底從哪里來,在這個設計中,它是從kafka里把數據讀出來。在這個事例里面,數據流的變換比較簡單,只是把每一行數據做一個解析,解析完后獲得另一個數據流,就構成了 DataStreamevents這個數據流。
在這個數據流上面,我們做了一個分組:keyBy(“id”)、timeWindow(Time.seconds(10))、apply(new MyWindowAggregationFunction())。我們把整個數據處理完之后,得到一個統計數據流,指定輸出。
這大致就是整個數據流的業務邏輯,箭頭下方是數據流圖。


示例里面展示的只是部分API,除了上面那些,還有很多操作,我們一起來看下面這張圖片。

“map”就是做一些映射,比如我們把兩個字符串合并成一個字符串,把一個字符串拆成兩個或者三個字符串。
“flatMap”類似于把一個記錄拆分成兩條、三條、甚至是四條記錄。
“Filter”就類似于過濾。
“keyBy”就等效于SQL里的group by。
“reduce”就類似于MapReduce里的reduce。
“join”操作就有點類似于我們數據庫里面的join。
“aggregate”是一個聚合操作,如計數、求和、求平均等。
“connect”實現把兩個流連成一個流。
“project”操作就類似于SQL里面的snacks。
“repartition”是一個重新分區操作。
4.執行機制
知道Flink的編程模型之后,那么Flink是怎樣去運行這些業務邏輯的呢?下面是它的執行機制。
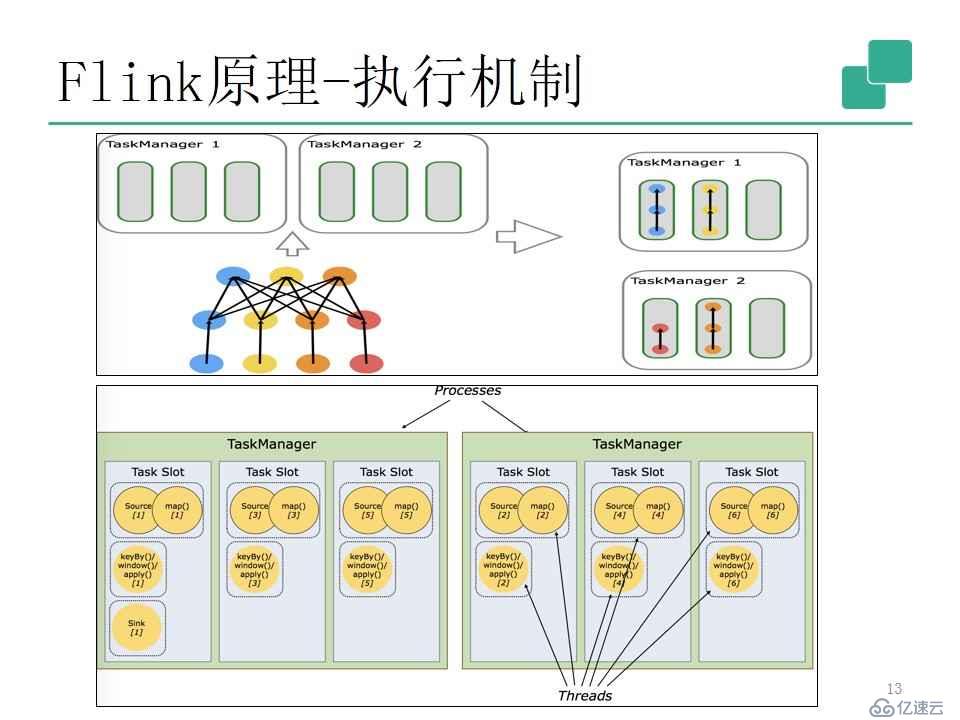
上圖是表現業務邏輯的業務執行圖,Flink的執行方式類似于管道,它借鑒了數據庫的一些執行原理,實現了自己獨特的執行方式。
5.狀態與容錯
Flink的容錯機制很特別,我們一起來看一看。

Flink在處理數據流時,它的整個數據流里面的數據分為兩種,一種是本身業務發給的數據,還有一種是Flink自己插到數據流里面的數據。插入的記錄我們叫它barrier,就是柵欄,我們可以把它看成一個表示進度的標記,標記整個數據處理的狀態,它從源頭發出。從圖中我們可以看到,不管是什么流,它都會產生一個checkpoint barrier。

當operator收到柵欄之后,它會把柵欄的狀態存儲,然后把特定記錄發出去,到達第二個operator里面,它又把它的狀態放到Master里,它就是這樣一步一步去完成的。在這個過程中,如果有一步出現故障,Flink會重復前面的步驟,重新去運行,所以不會出現數據的丟失和錯誤。
三.Flink的實踐:
1.示例
我們來看一下具體的示例。

第一步是初始化框架的運行時環境;第二步是指定數據流的數據源,示例里指定的是FlinkKafkaConsumer010<>(...)數據;第三步是實現數據流的業務變換邏輯,這里主要是通過flatmap把一個記錄分成多條記錄,通過filter進行過濾,之后按照域名進行分組,指定窗口長度,最后指定統計方式,這里的統計方式是計數;第四步就是對統計出來的數據流進行指定輸出;最后一步,提交數據變換邏輯到框架中經編譯后運行。
2.監控
把這個程序啟動之后,我們就可以看到Flink的監控頁面,下面是一些監控信息。

我們可以看到,在啟動的Flink集群里面,有80個Task Managers,80個巢,1個空閑的巢數,紅框點進去之后,就是下面的圖片。


監控指標有很多。


四.總結與展望:
最后,我們來做一下總結。以上只是關于Flink的一些簡單介紹,關于Flink的內存管理、部署、內部執行機制等相關詳細資料,我們可以通過以下網站進行資料查詢。

Apache Flink是有關Flink開源的官方網站。
Flink-Forward網站主要介紹各家大公司在使用Flink過程中的心得體會,以及Flink本身的發展提案的一些相關內容。
dataArtisans是Flink背后的一個商業公司,Flink由它發展起來。它上面的博客包含好多關于Flinkd的介紹,以及一些有深度的文章。
Athenax主要是關于Flink的前瞻×××的網站。
以上四部分就是本次線上直播曠東林老師講述的主要內容,在提問環節有哪些問題呢?我們一起來看看。
1.請老師講講Flink和最新版Spark的對比?
曠老師:spark streaming和flink是競爭關系,兩個框架都是流處理里面用的比較多,Flink最大的優勢在于保證高吞吐量情況下的低延遲,以及對復雜的帶有狀態的流的狀態管理能力,還有就是非常靈活窗口的支持。
2.新版spark采用的是timeline db技術嗎?
曠老師:不是的,timeline db在實現上與spark不是一樣的,spark streaming是典型的微批次的流處理框架,其他的大部分都是基于pipeline的執行架構。
這次線上直播,相信大家對Flink流式處理有了進一步的認識,在這里我們也很感謝曠東林老師的分享。想了解更多更詳細內容的小伙伴們,可以關注服務號:FMI飛馬網,點擊菜單欄飛馬直播,即可進行學習。

免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





