溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!

作者 | 蔣寶尚
編輯 | 叢末
5月29日,Science刊登了一篇標題為“人工智能某些領域的核心進展一直停滯不前”的文章,在文章里,作者Matthew Hutson提到:一些多年之前的“老算法”如果經過微調,其性能足以匹敵當前的SOTA。
另外,作者在文章中還列舉了一些論文,這些論文對當前關鍵的AI建模技術進行了分析,所有的分析結果主要有兩種:1、研究員聲稱的核心創新只是對原算法的微改進;2、新技術與多年前的舊算法在性能上相差不大。
具體到技術層面,論文對比分析的AI建模方法包括:神經網絡剪枝、神經網絡推薦算法、深度度量學習、對抗性訓練、語言模型。
科研有風險,入坑需謹慎。下面,AI科技評論簡要介紹這幾篇論文,為大家提供避坑指南。
1 神經網絡剪枝:評價指標模糊

論文地址:
https://proceedings.mlsys.org/static/paper_files/mlsys/2020/73-Paper.pdf
對神經網絡剪枝技術進行對比分析的論文是“What is the State of Neural Network Pruning?”,論文一作是來自麻省理工的研究員Davis Blalock。
他們通過對比81相關篇論文,并在對照條件下對數百個模型進行修剪后,明顯發現神經網絡剪枝這一領域并沒有標準化的基準和指標。換句話說,當前最新論文發表的技術很難進行量化,所以,很難確定該領域在過去的三十年中取得了多少進展。
主要表現在:1、許多論文雖然聲明提高了技術水平,但忽略了與其他方法進行比較(這些方法也聲稱達到了SOTA)。這種忽略體現兩個方面,一個是忽略2010年之前的剪枝技術,另一個是忽略了現在的剪枝技術。
2、數據集和架構都呈現“碎片化”。81篇論文一共使用了49個數據集、132個體系結構和195個(數據集、體系結構)組合。
3、評價指標“碎片化”。論文使用了各種各樣的評價指標,因此很難比較論文之間的結果。
4、混淆變量。有些混淆的變量使得定量分析變得十分困難。例如,初始模型的準確度和效率、訓練和微調中的隨機變化等等。
在論文的最后,Davis Blalock提出了具體的補救措施,并引入了開源的框架ShrinkBench,用于促進剪枝方法的標準化評估。另外,此篇論文發表在了3月份的MLSys會議上。
2 神經網絡推薦算法:18種算法無一幸免

https://dl.acm.org/doi/pdf/10.1145/3298689.3347058
對神經網絡推薦算法進行分析的論文是 “ Are We Really Making Much Progress? A Worrying Analysis of Recent Neural Recommendation Approaches ”,作者是來自意大利米蘭理工大學的研究員。
在論文中,作者對當前排名靠前的幾種推薦算法進行了系統分析,發現近幾年頂會中提出的18種算法,只有7種能夠合理的復現。還有另外6種,用相對簡單的啟發式方法就能夠勝過。剩下的幾種,雖然明顯優于baselines,但是卻打不過微調過的非神經網絡線性排名方法。
導致這種現象的原因,作者分析了三點:1、弱基準( weak baselines);2、建立弱方法作為新基準;3、在比較或復制不同論文的結果方面存在差異。
為了得到上述結果,作者在論文中介紹,其共進行了兩個步驟:第一步是用相關論文提供的源代碼、和數據嘗試復現論文結果;第二步,重新執行了原始論文中報告的實驗,但也在比較中加入了額外的基線方法,具體而言,其使用了基于用戶和基于項目的最近鄰啟發式方法,以及簡單的基于圖形的方法(graph-based approach)進行比較。
3 深度度量學習:該領域13年來并無進展

https://arxiv.org/pdf/2003.08505.pdf
對深度度量學習進行分析的文章來自Facebook AI 和 Cornell Tech 的研究人員,他們發表研究論文預覽文稿標題為“A Metric Learning Reality Check”。
在論文中,研究員聲稱近十三年深度度量學習(deep metric learning) 領域的目前研究進展和十三年前的基線方法(Contrastive, Triplet) 比較并無實質提高。
研究員一共指出了現有文獻中的三個缺陷:不公平的比較、通過測試集反饋進行訓練、不合理的評價指標。
不公平的比較:一般大家聲明一個算法性能優于另一個算法,通常需要確保盡可能多的參數不變,而在度量學習的論文中不是如此。另外,一些論文中所提到的精度提高其實只是所選神經網絡帶來的,并不是他們提出的“創新”方法。例如2017年的一篇論文聲稱使用ResNet50 獲得了巨大的性能提升,而實際上他的對比對象是精度較低的GoogleNet。
通過測試集反饋進行訓練:不僅是度量學習領域,大多數論文都有這一通病:將數據集一半拆分為測試集,一半拆分為訓練集,不設驗證集。在具體訓練的過程中,定期檢查模型的測試集精度,并報告最佳測試集精度,也就是說模型選擇和超參數調優是通過來自測試集的直接反饋來完成的,這顯然會有過擬合的風險。
不合理的評價指標:為了體現準確性,大多數度量學習論文都會報告Recall@K、歸一化相互信息(NMI)和F1分數。但這些一定是最好的衡量標準嗎?如下圖三個嵌入空間,每一個recall@1指標評價都接近滿分,而事實上,他們之間的特征并不相同。此外,F1和NMI分數也接近,這在一定程度上說明,其實,這幾個指標并沒帶來啥信息。

三個 toy示例:不同的精確指標如何評分。
在指出問題的同時,FB和康奈爾的研究員自然也指出了改進建議,針對上述三個缺點建議進行公平比較和重復性實驗、通過交叉驗證進行超參數搜索、采用更加準確的信息性、準確性度量。
4 對抗性訓練:所有改進都可通過“提前停止”實現
https://openreview.net/pdf?id=ByJHuTgA-
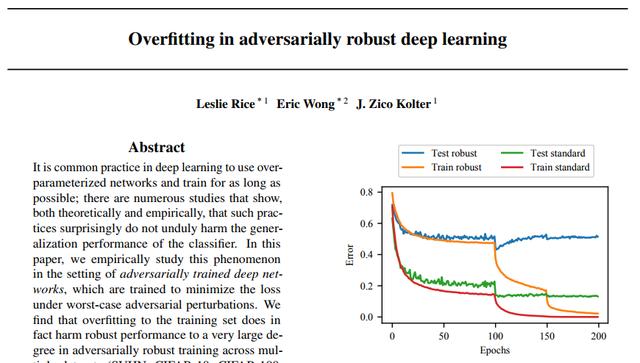
對“對抗性訓練”進行研究的論文標題是“Overfitting in adversarially robust deep learning”,第一作者是來自卡內基梅隴大學的研究員Leslie Rice。
在論文中,作者提到機器學習算法的進步可以來自架構、損失函數、優化策略等的改變,對這三個因素中的任何一個進行微調都能夠改變算法的性能。
他的研究領域是對抗訓練,他說:經過訓練的圖像識別模型可以免受黑客的 "對抗性攻擊",早期的對抗訓練方法被稱為投影梯度下降算法(projected gradient descent)。
近期的很多研究都聲稱他們的對抗訓練算法比投影梯度下降算法要好的多,但是經過研究發現,幾乎所有最近的算法改進在對抗性訓練上的性能改進都可以通過簡單地使用“提前停止”來達到。另外,在對抗訓練模型中,諸如雙下降曲線之類的效應仍然存在,觀察到的過擬合也不能很多的解釋。
最后,作者研究了幾種經典的和現代的深度學習過擬合補救方法,包括正則化和數據增強,發現沒有一種方法能超得過“提前停止”達到的收益。所以,他們得出結論:PGD之類的創新很難實現,當前的研究很少有實質性改進。
5 語言模型:LSTM仍然一枝獨秀

對語言翻譯進行研究的論文名為“On the State of the Art of Evaluation in Neural Language Models,此論文是DeepMind和牛津大學合力完成。
在論文中,作者提到神經網絡架構的不斷創新,為語言建模基準提供了穩定的最新成果。這些成果都是使用不同的代碼庫和有限的計算資源進行評估的,而這種評估是不可控的。
根據其論文內容,作者一共主要研究了三個遞歸模型架構(recurrent architectures),分別是:LSTM、 RHN(Recurrent Highway Network)、NAS。研究RHN是因為它在多個數據集上達到了SOTA,而研究NAS是因為它的架構是基于自動強化學習的優化過程的結果。
最后,作者通過大規模的自動黑箱超參數調優,重新評估了幾種流行的體系結構和正則化方法,得出的一個結論是:標準的LSTM體系結構在適當的正則化后,其性能表現優于“近期”的模型。
via
https://www.sciencemag.org/news/2020/05/eye-catching-advances-some-ai-fields-are-not-real
https://www.toutiao.com/i6832364243111641613/
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





