溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
Puppet監控速查問題的原因及解決方案是什么,相信很多沒有經驗的人對此束手無策,為此本文總結了問題出現的原因和解決方法,通過這篇文章希望你能解決這個問題。
Puppet是基于C/S架構的集中配置管理系統,基于自有描述性語言,可以實現對配置文件、用戶、定時任務、軟件包、系統服務等管理,保證大規模集群基礎配置一致性。
我們用Puppet管理了上千臺服務器,經過多次優化監控,自動化灰度發布保證了所有集群基礎配置一致性。本文探討了如何對Puppet系統進行監控,也將典型問題和解決方案一并分享給大家。
監控選型
Foreman提供了較全面的交互設施,包括Web前端、CLI和RESTful API。在此基礎之上,可以構建監控管理系統,以及實現報警等功能。
核心業務流程
可以簡單將Puppet的工作流程抽象為四部分:
請求階段:Agent基于SSL將自身信息發送給Server;
響應階段:Server基于客戶端信息解析相應的配置,并最終將偽代碼(catalog)發送回Agent;
執行階段:Agent接收catalog并執行命令或者更新文件;
匯報階段:Agent把結果匯報給Server。
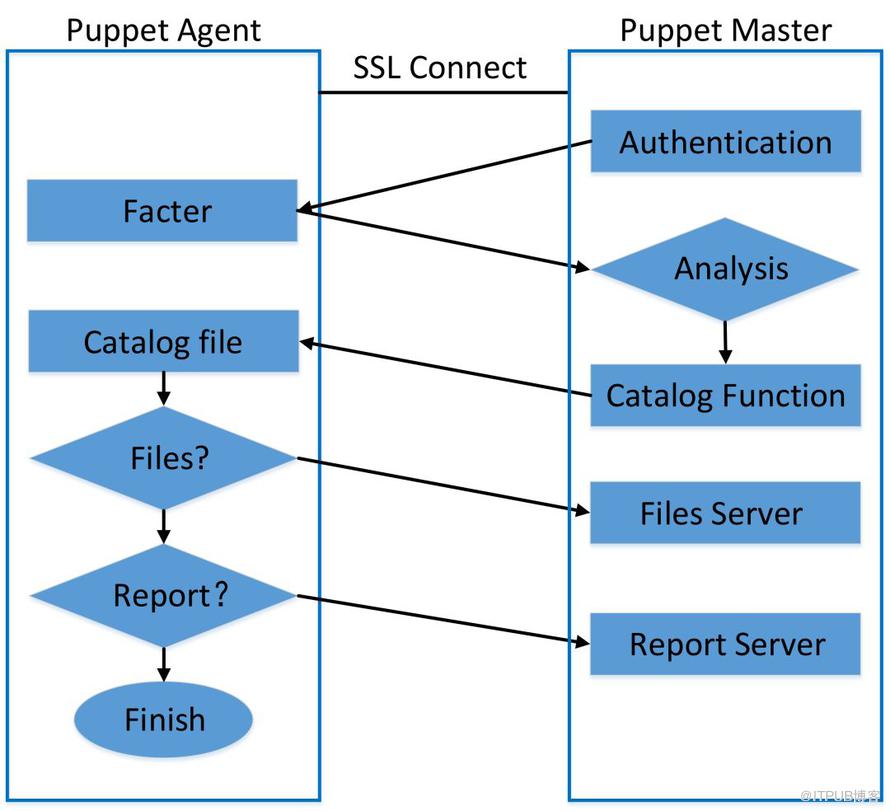
圖1 Puppet工作流程
監控概覽
對Puppet的核心監控主要覆蓋如下環節:
Agent與Master通信是否正常;
Agent策略執行是否生效;
Puppet發布的策略生效時間及范圍;
Master及其所管理集群的運行狀態。
黑盒監控
Puppet黑盒監控指標不符合預期,說明集群不能正常工作或出現異常,黑盒監控指標有:所有策略是否都生效,策略生效范圍是否符合預期,策略生效結果是否符合預期。
所有策略是否都生效
說明:將一批測試節點,加入到線上Puppet集群,通過定期運行檢查腳本驗證所有策略是否都生效。
策略生效范圍
說明:策略上線后,需要確認其生效范圍是否符合預期,即策略是否僅在指定的節點生效。
實現:通過Puppet模塊MCollective定時執行檢查任務(檢查實際生效的機器列表和服務樹機器列表是否一致),如下圖,集群hn-xdata 有98%的機器符合預期,2%不符合。
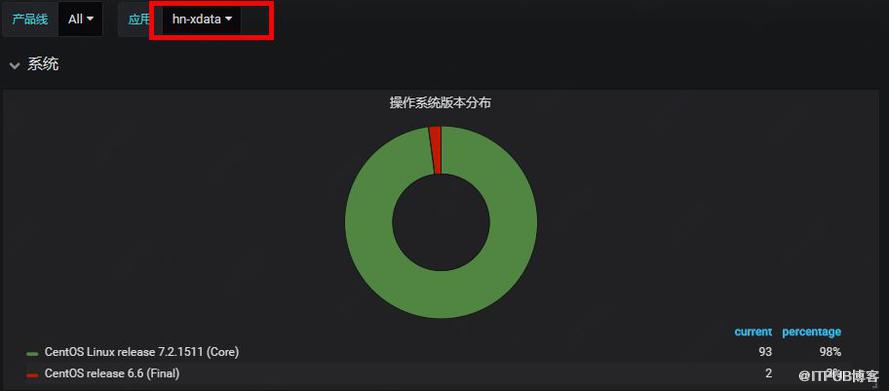
圖2 Puppet策略生效范圍監控
策略生效結果是否符合預期
說明:策略上線后,需要確保所有策略在所有機器都生效。
實現:通過Puppet模塊MCollective定時執行檢查任務,(檢查實際生效的機器列表和服務樹機器列表是否一致),如下圖,每一個策略有一張餅圖。
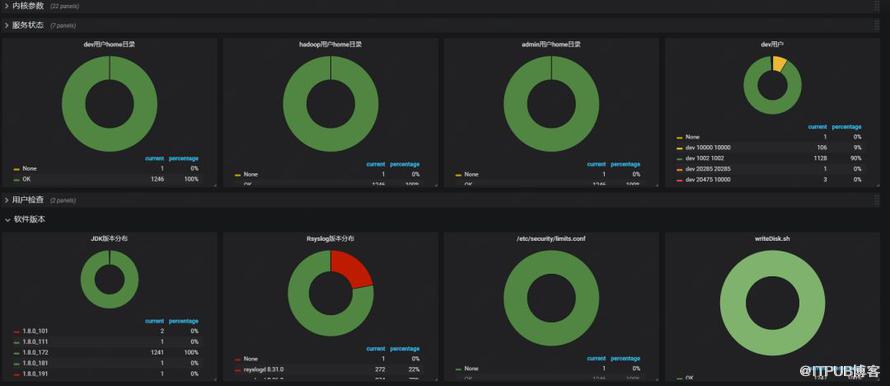
圖3 Puppet策略結果監控
白盒監控
白盒監控是黑盒監控的補充,服務于故障定位,從集群容量、流量、延遲、錯誤四個方面梳理。
數據采集方式:
通過Foreman API
Master日志分析
表1 通過Foreman API獲取采集的白盒指標概覽
指標 | 說明 |
No reports | 沒有匯報的主機 |
Error | 連上了但是執行策略出錯 |
Out of sync | 執行策略超時;主機名重復;主機連不上 |
Active | Agent拉取策略正常 |
Pending | 容量指標,Master處理不過來 |
No changes | Agent正常拉取策略但是沒有變更 |
puppet_report_time_total | Agent執行策略總時間 |
Pv | 每分鐘訪問量 |
容量
Master所在實例的CPU,網絡連接數指標,網卡
流量
Agent PV,基于Puppet Master的訪問日志puppetserver-access.log來計算流量
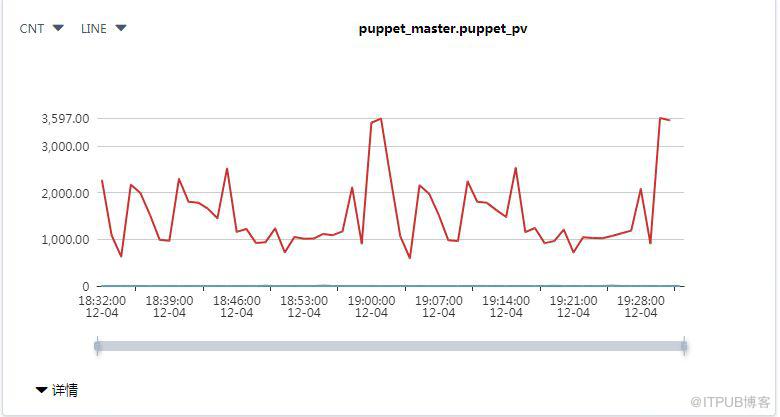
圖4 Agent PV流量圖
延遲
單個Agent更新策略需要的時間:puppet_report_time_total
說明:puppet_report_time_total 是Agent從連接Master到發送報告給Master總時間,0-3s的占50%,0-11s的占90%,0-15s占99%。
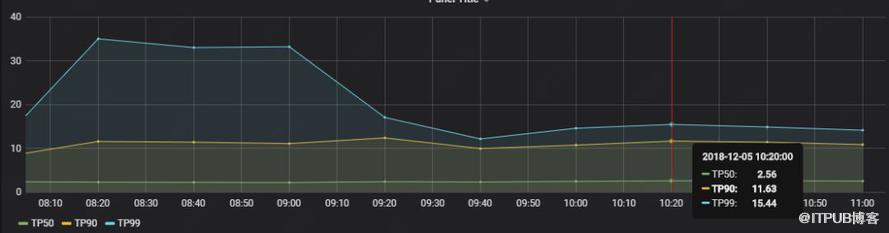
圖5 Agent 延遲
錯誤
No reports:沒有報告的實例數量;
Error agent:執行策略出錯的實例數量;
Out of sync:執行策略超時、主機名重復、主機連不上Master的實例數量。
圖6 Foreman錯誤監控指標
Puppet監控發現的問題
Agent覆蓋所有機器
問題:不能保證所有機器Agent都正常運行。
解決方案:基于服務樹或者CMDB相關系統將所有機器填加Agent進程監控。
Agent執行策略超時
問題:大文件并發下載時,出現超時告警。
排查方法:在Agent上執行命令“puppet agent -t --debug”, 發現在拉取文件時超時,由于文件較大,在Master上同時很多Agent拉取,導致超時。
解決方案:將大文件存放在云存儲上,提高下載速度。
分組不止僅限于現有Facter屬性
問題:策略分組和灰度發布分組現有Facter屬性不滿足。
原因:隨著接入業務越來越多,業務分組也越多。
解決方案:自定義Facter。
Agent不同步(Out of Sync)
問題:Agent報不同步。
原因及解決方案:
表二
原因 | 解決方案 |
主機名重復 | 修改Agent Hostname后重新認證 |
主機認證后重命名 | 直接在Foreman控制臺中刪除原名稱認證的機器 |
Agent服務異常 | 在Agent上重啟Puppet服務 |
Agent磁盤打滿 | 清理磁盤后,Agent會自行啟動并恢復 |
Agent端證書error | 在Agent上刪除/etc/puppetlabs/puppet/ssl文件夾后,執行puppet agent –t重新認證 |
Agent端puppet.conf文件為空 | 將相應的[Agent]配置寫入puppet.conf文件中即可恢復 |
Master端puppe.conf文件為空 | 將相應[Master]配置寫入puppet.conf文件中即可恢復 |
Foreman服務down掉 | 在Foreman機器上執行service httpd restart、service foreman restart |
Could not request certificate | 1)Agent與Master時間不同步,ntpdate master –IP同步時間;2)Agent與Master端網絡不通;3)Master端8140端口不通 |
策略發布到非預期集群
問題:策略生效范圍出錯。
原因:Puppet Master入口文件統一為site.pp,由于策略分組多,在灰度發布階段,相應分支也會很多,運維工程師很容易操作出錯。
解決方案:將site.pp作為一個策略模塊進行管理,策略模塊中包含默認default分組,以及需要灰度發布的分組。manifest文件夾下的site.pp只需include該模塊即可。
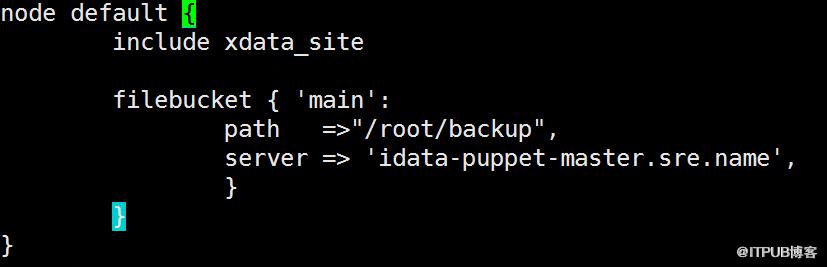
圖7 site.pp優化后default分組策略
圖8 策略發布灰度階段分組
功能監控發現所同步的文件非預期
問題:Master采用集群方式部署,在策略變更期間多臺Master上數據可能不同步,此時,同一Agent拉取到的文件可能不一致 。
原因:由于有多臺Master,其中一臺Master沒有更新文件,LB通過輪詢策略進行轉發,當Agent請求Master時是Master A,再拉取文件時請求的可能是Master B,兩臺Master數據不一致。
解決方案:LB策略更新為源IP哈希。
看完上述內容,你們掌握Puppet監控速查問題的原因及解決方案是什么的方法了嗎?如果還想學到更多技能或想了解更多相關內容,歡迎關注億速云行業資訊頻道,感謝各位的閱讀!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





