溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
服務心跳機制主要用于確認服務的存活狀態,UAVStack的心跳數據還負責上報節點的容器及進程監控數據,支持在前端實時查看應用容器和進程的運行狀態,并根據這些數據對容器和進程做出預警。
在微服務架構中,服務心跳是一個簡單但非常重要的機制,用于確認微服務的存活狀態。UAVStack中的心跳是一個Http請求,MonitorAgent(以下簡稱MA)通過定時向HealthManager(以下簡稱HM)發送一個帶有特定報文格式的Http請求完成一次心跳的發送過程。心跳報文含有發送時的時間戳,用于更新HM端的數據狀態。
與普通的心跳不同,UAVStack中的心跳還負責上送MA端的應用容器和進程監控數據。每次發送心跳的時候,在MA端會有定時任務去收集MA所在的應用容器心跳的基本信息,及應用容器上的進程數據,隨著心跳數據包一起上送。
本文將首先介紹UAVStack的基礎心跳機制,之后對應用容器、進程的數據采集做詳細說明。
心跳的實現有很多種方式,心跳的發起可以由客戶端發起也可以由服務端發起,只需完成確認存活這一基本功能即可。但是在一般的實現中,我們更傾向于客戶端主動向服務端進行報告,因為當客戶端逐漸增加,單純通過服務端的輪詢會導致服務端的壓力,影響性能。
在UAVStack的實現中,我們也采用了這樣的方式,通過客戶端(MA)主動向服務端(HM)發送心跳信息,告知HM自身的存活情況。
一次心跳由UAV的MA和HM共同完成:
MA定時生成心跳數據,攜帶MA節點的應用容器信息、進程信息以及服務信息,通過Http請求上報給HM;
HM負責將接收到的心跳數據存入Redis緩存,并定時掃描心跳數據,確認節點的存活狀態。對于隨同的應用容器等監控信息,會在Redis進行暫存,后續隨著HM的定時任務最終存入OpenTSDB進行落盤。整體的架構如下所示:
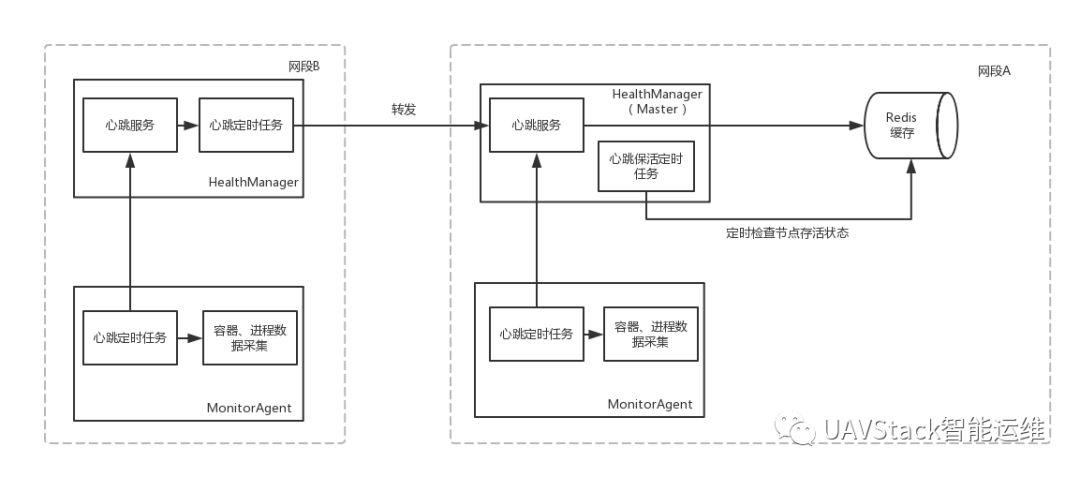
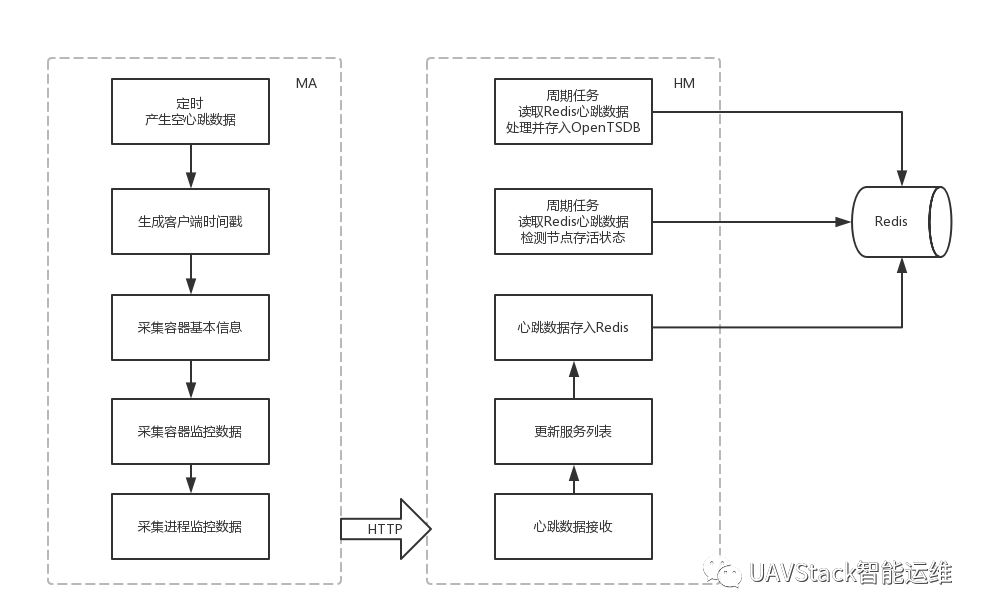
心跳服務主要流程如上圖所示,其邏輯有以下幾步:
1)MA的定時心跳任務生成一個空心跳數據,將心跳數據交給MA端的容器、進程數據采集任務。
2)MA端的容器、進程數據采集任務負責產生心跳數據的時間戳、采集節點的應用容器、進程監控數據、節點的基本信息、節點的可用服務信息等。經過以上過程之后,心跳數據將包含以下內容:
最后將心跳數據發送給HM。
3)HM端在接收到心跳數據之后,將其存入自身的Redis緩存。使用上報數據中的服務信息更新Redis中的服務狀態,用于服務發現請求。
4)HM端在啟動心跳接收服務時,會同時啟動心跳檢查任務。這個任務會定時掃描Redis中的心跳數據,根據當前系統時間與心跳時間戳的差,判斷心跳節點的存活狀態,更新節點的狀態,并對于過期的節點做刪除處理。
UAV的心跳數據除了完成心跳功能之外,還要上報節點的應用容器及進程的監控數據。
將應用容器與進程數據通過Http方式上報是為了保證應用容器監控數據與應用監控數據的隔離,通過不同方式的上送可以保證在MQ服務不能使用時不影響容器與進程數據的采集。
本節將集中說明這些數據的采集細節。
應用容器的數據分為兩部分:
其一是容器的基本信息,即節點的ID,主機名,系統信息和JVM信息等;
另一部分是一些簡單的實時監控采集數據,包括CPU的負載、內存占用情況和磁盤占用情況等。這些數據在每次上報心跳數據的時候會分別從以下數據源實時采集:
不同于應用容器數據采集,進程的數據并不是在心跳進程中進行采集的,而是由專門的Feature負責。在Feature中將進程數據采集進一步分解成進程端口流量數據采集以及其他數據采集。這兩者均由定時任務完成,互相協作,最終由進程探測的定時任務更新心跳客戶端的進程數據。
這種使用多個采集任務分別采集的方式可以針對不同的數據進行不同頻度的采集。如對于網絡端口流量的采集,就可以以更長的周期進行,以減低數據采集帶來的性能損耗。同時,不同的任務也可以使用不同的線程執行,提升執行的效率。
進程數據采集流程大致如下圖所示:
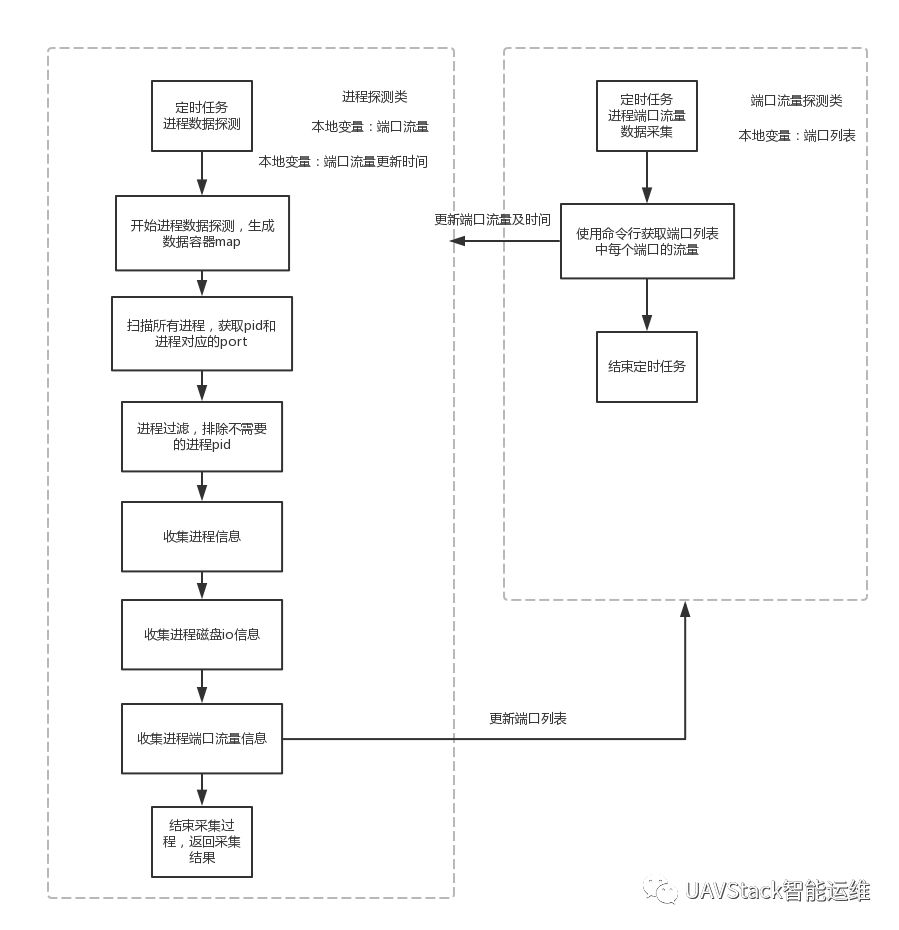
進程端口流量探測定時任務每隔一定時間讀取本地變量端口列表,獲取要采集的端口號。
之后對于Windows環境,采用JPcap獲取網卡對象,并在網卡上設置tcp過濾器來統計一段時間內的端口流量。對于Linux環境則是直接通過調用Python腳本打開socket,分析流過的數據包獲得。
獲得全部端口上的流量數據后,任務會將采集數據交給進程數據采集任務,更新其本地變量,同時設置本次采集的時間戳。
進程探測定時任務由一系列子任務構成,在任務開始的時候,會先準備好一個Map結構的數據容器,用于存放采集到的進程信息,每個進程由pid區分,作為Map的key。
任務會先掃描所有的進程,獲取pid和進程的端口。掃描到的進程會經過一個過濾器排除不需要采集數據的進程,之后正式采集每個進程上的數據。
對于每一個進程,會通過運行系統命令采集連接數、CPU、內存占用,磁盤讀寫數據以及網絡端口流量數據。其中網絡端口流量數據是由端口流量探測任務采集并更新的本地變量,而進程探測任務也會將掃描到的最新的端口列表更新到端口流量探測任務的本地變量。
如果應用是部署在容器上的,則還會有對應的容器信息采集。最后進程探測任務會將采集到的進程數據更新到心跳客戶端的本地變量,隨著每次心跳數據的生成被一起采集并上報。
進程數據的采集分別來自以下數據源:
心跳數據和容器數據在通過Http上送到HM端之后,會由HM端對應的服務進行處理。
HM在啟動時會啟動自己的心跳客戶端,負責發送本機的心跳數據和采集HM所在容器的監控數據。同時還會啟動一個心跳服務,負責接收處理所有上送的心跳和容器數據信息。
心跳服務在收到心跳數據請求后,會根據HM的配置,判定當前的HM是不是Master節點。如果HM是Master節點,心跳服務會從Http攜帶的報文中拿出上報的數據,取得上報節點中的可用服務用于更新服務發現信息,之后將數據存入后端的Redis緩存中;如果不是Master節點,則會將數據移交至本機的心跳客戶端,由其下次發送心跳時一起上送。
這樣的設計是考慮到大規模監控時會有跨機房的情況存在,此時各監控節點往往不在同一個網段內,通過將同一個網段內的機器上交到邊界的“網關”統一上交可解決這一問題。此時的HM即充當著“網關”這一角色。
HM在啟動的時候同時還會啟動一個定時任務,這個任務負責處理各節點的存活狀況。任務定時從Redis中讀取全部心跳數據,依次檢查上送心跳數據中的客戶端時間戳與當前系統時間戳的差值。
當時間超過一定的上送時間間隔之后,更改對應的節點存活狀態。當超過一倍上送時間間隔,意味節點可能死亡,處于dying狀態。當超過兩倍時間間隔時,意味著節點已經死亡。當超過三倍時間間隔時,心跳服務會刪除該節點的緩存記錄。
隨心跳一起上報的容器和進程數據會隨著心跳數據一同被存入Redis中,后續由HM的其他定時任務讀取并發送給預警中心進行處理,最終監控指標被格式化成特定的結構存入OpenTSDB。
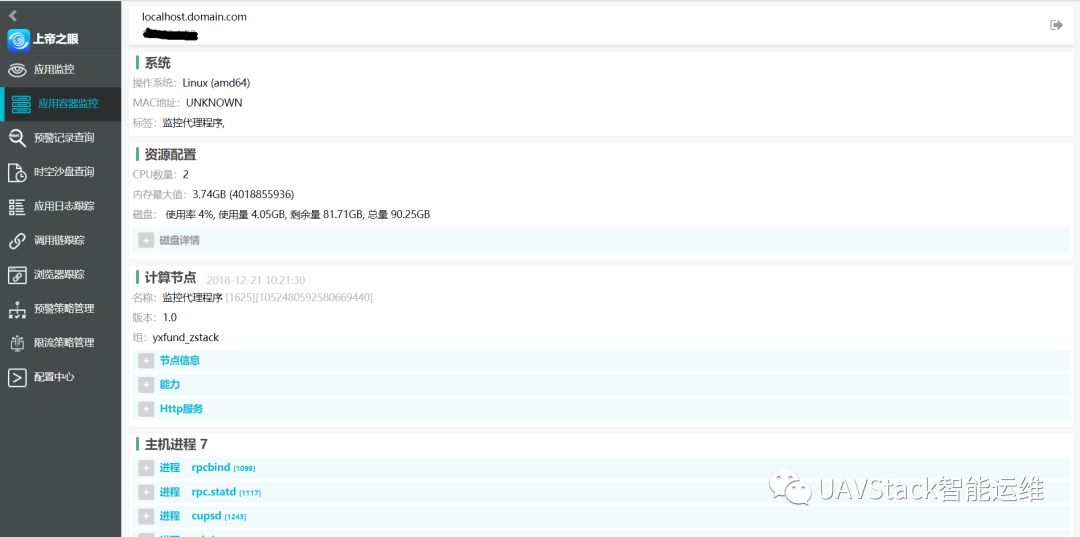
同時采集的容器數據和進程數據會提供前端AppHub查看界面,如圖所示:
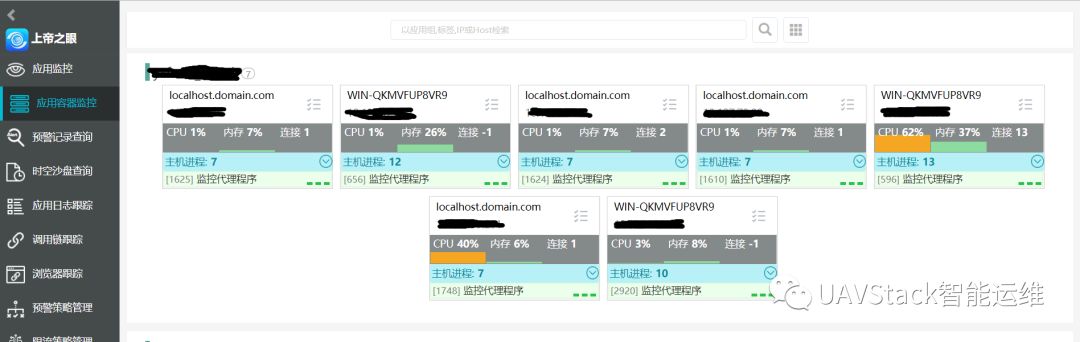
點擊頁面上的每一個節點,可以查看詳細的節點信息,包括節點的操作系統信息、JVM信息、提供的服務和安裝的Feture等等。這些也就是前文所說的隨心跳數據上報的那部分信息。如圖所示:
心跳是微服務架構基礎但重要的機制,通過定時發送心跳數據,MA節點報告了自身的存活狀態,使得HM能夠知曉當前系統的運行狀態。
同時,UAVStack的心跳數據還同時負責上報節點的容器及進程監控數據,隨著這些數據的上報,HM可以對監控的容器和進程做出預警,也能夠在前端實時看到應用容器和進程的運行狀態。
官方網站:https://uavorg.github.io/main/
開源地址:https://github.com/uavorg
作者:張明明
來源:宜信技術學院
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





