溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容主要講解“如何利用Kubernetes實現容器的持久化存儲”,感興趣的朋友不妨來看看。本文介紹的方法操作簡單快捷,實用性強。下面就讓小編來帶大家學習“如何利用Kubernetes實現容器的持久化存儲”吧!
可以說,容器化徹底改變了我們對應用程序開發的思考方式,它帶來很多好處:開發和生產之間的一致環境、使用共享的資源但容器之間相互隔離、云環境之間的可移植性、快速部署……等等不勝枚舉。容器所固有的短暫性是它之所以偉大的核心原因:不可變的、相同的容器,可以在一瞬間快速啟動。但容器的短暫性也有不利的一面:缺乏持久化存儲。
引入Kubernetes
持久狀態(Persistent state)通常數量較大且難以移動,這一概念與容器這種快速、輕量級且易于隨時部署到任何地方的概念有很大的不同。正是由于這個原因,容器規范有意將持久狀態排除在外,轉而選擇存儲插件,將管理持久狀態的責任轉移給另一方。
開源容器編排工具Kubernetes已經開始著手解決這個問題。在這篇文章中,筆者將向您介紹Kubernetes中的幾個組件,它們有助于解決在容器環境中持久化狀態的問題。
有狀態性
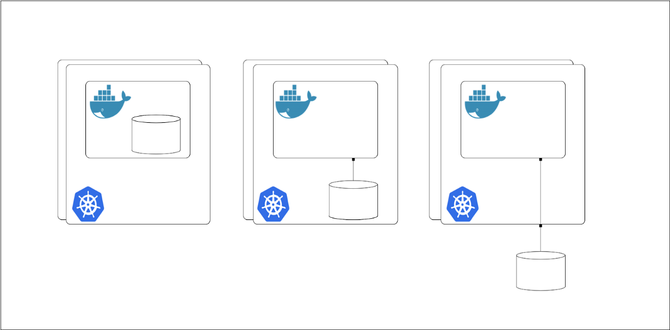
管理持久狀態的最大問題是決定它應該存留在何處。在決定持久化存儲應該放在何處時,有三種選擇,每種方法各有其優點:
·持久化存儲保存在容器中。如果數據是可復制的,而且不是關鍵數據,那么這中方法是非常有效的,但是當容器重新啟動時,您將丟失這些數據。
·持久化存儲保存在主機節點上。這種方法繞過了容器的短暫性問題,但是您可能會因為主機節點的易受攻擊性而遇到類似的問題。
·持久化存儲保存在遠程存儲中。這消除了容器和主機存儲的不可靠性,但是需要仔細考慮如何提供/管理遠程存儲。
什么時候需要考慮狀態?
應用程序有兩個需要持久狀態的關鍵特性:1、需要在應用程序中斷和重啟之前持久保存數據;2、需要跨相同的中斷和重啟,來管理應用程序狀態。此類應用程序的典型例子有數據庫及其副本、某種日志記錄應用程序,或者需要遠程存儲的分布式應用程序。
但是,此類應用程序對持久性的需求并不是相同程度的,因為對于不同的應用程序,其關鍵程度顯然是不同的。由于這個原因,筆者在設計有狀態的應用程序時,常常會問自己幾個問題:
·我們要管理多少數據?
·從最新的快照開始就可以嗎?還是需要絕對最新的可用數據?
·從快照重新啟動是否花費了太長時間,或者對這個應用程序而言已經足夠了?
·數據的復制有多容易?
·這些數據對任務有多重要?能否在容器或主機終止時“存活”,還是需要遠程存儲?
·這個應用程序中的不同Pods是可互換的嗎?
存儲解決方案
許多應用程序要求數據能夠跨容器和主機重啟實現持久化,這就需要遠程存儲。幸運的是,Kubernetes已經意識到這種需求,并提供了一種Pod與遠程存儲交互的方式:卷(Volumes)。

Kubernetes卷
Kubernetes卷提供了一種與遠程(或本地)存儲交互的方法。可以將這些卷視為掛載的存儲,這些存儲將持續存留到封閉Pod的生存期。卷比在該Pod中spin up/down的任何容器的壽命都長,這為容器的短暫性提供了一個很好的解決方案。下面是一個利用卷的Pod定義示例。
apiVersion: v1
kind: Pod
metadata:
name: test-pod
spec:
containers:
— name: test-container
image: nginx
volumeMounts:
— mountPath: /data
name: testvolume
volumes:
— name: testvolume
# This AWS EBS Volume must already exist.
awsElasticBlockStore:
volumeID: <volume-id>
fsType: ext4
正如我們從上面Pod定義中看到的,spec下的volumes部分指定了卷的名稱和已經創建的存儲的ID(在本例中是EBS卷)。要使用此卷,容器定義必須在spec下的containers volumeMounts字段中指定要掛載的卷。
在利用卷時要記住的一些關鍵點:
·Kubernetes提供許多類型的卷,一個Pod可以同時使用任意數量的卷。
·卷僅能持續與封閉的Pod一樣長的時間。當Pod停止存在時,卷也將停止。
·持久存儲的供應不是由卷或Pod本身處理的,卷后的持久存儲需要以其他方式提供。
雖然卷解決了容器化應用程序的一個巨大問題,但某些應用程序要求附加卷的生存期超過Pod的生存期。對于這個用例,持久卷和持久卷聲明將非常有用。
Kubernetes持久卷和持久卷聲明
Kubernetes持久卷和持久卷聲明提供了一種方法,以便從存儲的使用方式中提取關于如何提供存儲的細節。持久卷(PV,Persistent Volume)是一個集群中由管理員提供的可用持久存儲,它們作為集群資源存在,就像節點一樣,它們的生命周期獨立于任何單獨的Pod。持久卷聲明(PVC,Persistent Volume Claim)是用戶對存儲的請求,與Pod消耗內存和CPU等節點資源的方式類似,PVC也消耗存儲等PV資源。
PV的生命周期由四個階段組成:供應(provisioning)、綁定(binding)、使用(using)和回收(reclaiming)。
供應——PV的供應可以通過兩種方式完成:靜態或動態。
·靜態供應需要集群管理員手動創建大量要使用的PV。
·動態供應可以在PVC請求PV時發生,而不需要集群管理員進行任何手動干預。
·動態供應需要以存儲類(Storage Classes)的形式進行一些預先供應(我們稍后將對此進行討論)。
綁定——創建PVC時,它具有特定的存儲空間和特定的訪問模式。當有一個匹配的PV可用時,無論PVC需要多長時間,它都將只與請求的PVC綁定。如果匹配的PV不存在,則PVC將無限期地保持松散狀態。在動態供應PV的情況下,控制循環會始終把PV綁定到請求的PVC。否則,PVC至少會得到它們要求的存儲空間,但是卷可能會比要求更多。
使用——一旦PVC認領了PV,它就可以作為一個安裝體在封閉的Pod中使用。用戶可以為附加卷指定特定的模式(例如ReadWriteOnce、ReadOnlymany等)以及其他掛載的存儲選項。只要用戶需要,就可以使用安裝好的PV。
回收——當一個用戶完成了對存儲的使用后,他需要決定如何處理正在釋放的PV。在決定回收策略時,有三個選項:保留(retain)、刪除(delete)和循環利用(recycle)。
·保留PV只需要釋放PV,而不需要修改或刪除任何包含的數據,并允許相同的PVC在稍后手動回收此PV。
·刪除PV將完全刪除PV以及底層存儲資源。
·循環利用PV將從存儲資源中刪除數據,并使PV可用于任何其他PVC的請求。
下面是一個持久卷(使用靜態供應)的示例,以及持久卷聲明定義。
apiVersion: v1
kind: PersistentVolume
metadata:
name: mypv
spec:
storageClassName: mysc
capacity:
storage: 8Gi
accessModes:
— ReadWriteOnce
persistentVolumeReclaimPolicy: Recycle
awsElasticBlockStore:
volumeID: <volume-id> # This AWS EBS Volume must already exist.
持久卷
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: mypvc
spec:
storageClassName: mysc
accessModes:
— ReadWriteOnce
resources:
requests:
storage: 8Gi
持久卷聲明
持久卷定義指定存儲資源的容量,以及一些其他特定于卷的屬性,如回收策略和訪問模式。可以使用spec下的storageClassName將PV分類為特定的存儲類,PVC可以利用它來指定要聲明的特定存儲類。上面的持久卷聲明定義指定了它試圖聲明的持久卷的屬性,其中一些是存儲容量和訪問模式。PVC可以通過指定spec下的storageClassName字段請求特定的PV。特定類的PV只能綁定到請求該類的PVC,沒有指定類的PV只能綁定到沒有請求特定類的PVC。選擇器還可以用于指定要聲明的PV的特定類型,有關這方面的更多文檔可以在這里(https://kubernetes.io/docs/concepts/storage/persistent-volumes/#selector)找到。
下面是利用持久卷聲明來請求存儲的Pod定義示例:
apiVersion: v1
kind: Pod
metadata:
name: test-pod
spec:
containers:
— name: test-container
image: nginx
volumeMounts:
— mountPath: /data
name: myvolume
volumes:
— name: myvolume
persistentVolumeClaim:
claimName: mypvc
當將這個Pod定義與前面使用卷的定義進行比較時,我們可以看到它們幾乎是相同的。持久卷聲明不是直接與存儲資源交互,而是用于從Pod抽象存儲細節。
關于持久卷和持久卷聲明的一些關鍵結論:
*持久卷的生命周期獨立于Pod的生命周期。
*持久卷聲明將存儲供應的細節從Pod的存儲消耗中抽象出來。
*與卷類似,持久卷和持久卷聲明不直接處理存儲資源的供應。
Kubernetes存儲類和持久卷聲明
Kubernetes存儲類和持久卷聲明提供了一種在請求時動態提供存儲資源的方法,從而消除了集群管理員過度提供/手動提供存儲資源以滿足需求的必要性。存儲類允許集群管理員描述其提供的存儲“類”,并在動態創建存儲資源和持久卷時利用這些“類”作為模板。可以根據特定的應用程序需求(如所需的服務質量級別和備份策略)定義不同的存儲類。
存儲類定義圍繞三個特定區域:
·回收(Reclaim )策略
·供應程序(Provisioner)
·參數(Parameter)
Reclaim ——如果持久卷是由存儲類創建的,那么只有Retain或Delete作為回收策略可用,而手動創建的、由存儲類管理的持久卷在創建時將保留其分配的回收策略。
Provisioner——存儲類提供者負責決定在提供PV時需要使用哪個卷插件(例如AWS EBS的AWSElasticBlockStore或Portworx volume的PortworxVolume)。Provisioner字段不僅限于內部可用的Provisioner類型列表,任何遵循明確定義的規范的獨立外部供應程序都可以用來創建新的持久卷類型。
Parameter——定義存儲類的最后、也可以說最重要的一部分是參數部分。不同的提供程序可以使用不同的參數,這些參數用于描述特定“類”存儲的規范。
下面是持久卷聲明和存儲類定義:
apiVersion: v1
kind: StorageClass
metadata:
name: myscz
provisioner: kubernetes.io/aws-ebs
parameters:
type: io1
iopsPerGB: “10”
fsType: ext4
持久卷聲明
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: mypvc
spec:
storageClassName: mysc
accessModes:
— ReadWriteOnce
resources:
requests:
storage: 8Gi
存儲類
如果我們將PVC定義與上面靜態供應用例中使用的定義進行比較,可以看到它們是相同的。
這是因為存儲“供應”和存儲“消費”之間存在明顯的分離。與靜態創建的存儲類相比,使用存儲類創建的持久卷的消耗有一些巨大的優勢,最大的優點之一是能夠操作僅在資源創建時可用的存儲資源值。這意味著我們可以準確地提供用戶請求的存儲量,而無需集群管理員進行任何手動干預。由于存儲類需要由集群管理員提前定義,因此它們仍然會控制哪些類型的存儲對最終用戶可用,同時抽象出所有供應邏輯。
存儲類和持久卷聲明的要點:
*存儲類和持久卷聲明允許最終用戶使用存儲資源的動態供應,從而消除集群管理員所需的任何手動干預。
*存儲類抽象了存儲供應的細節,而依賴于指定的供應程序來處理供應邏輯。
應用程序狀態
當我們考慮狀態時,持久存儲是至關重要的。我的數據在哪里?當我的應用程序故障時,它是如何做到持久化的?而某些應用程序本身也需要狀態管理,不僅僅是持久化數據。這在利用多個不可互換Pod的應用程序中最容易看到(例如,主數據庫Pod及其某些分布式應用程序如Zookeeper或Elasticsearch的副本)。諸如此類的應用程序要求能夠在任何重新調度期間為每個Pod hat分配惟一標識符。Kubernetes通過使用StatefulSet提供了這種功能。
Kubernetes StatefulSets
Kubernetes StatefulSet提供類似于ReplicaSets 和Deployments的功能,但是具有穩定的重新調度。對于需要穩定標識符和有序部署、伸縮和刪除的應用程序來說,這種差異非常重要。StatefulSet有幾種不同的特性,可以幫助提供這些必要的功能。
惟一網絡標識符——StatefulSet中的每個Pod都從StatefulSet的名稱和Pod的序號派生其主機名。這個Pod的標識是粘滯的,不管這個Pod被調度到哪個節點,也不管它被重新調度了多少次。這種功能對于會形成不可互換的Pod邏輯“組”的應用程序特別有用,這類應用程序典型例子是分布式系統中的數據庫副本和代理。識別單個Pod的能力是StatefulSet的優勢的核心。
有序的部署、伸縮和刪除——StatefulSet中的Pod標識符不僅是惟一的,而且是有序的。StatefulSet中的Pod是按順序創建的,在轉移到下一個Pod之前,等待中的上一個Pod處于健康狀態。這種行為也擴展到了Pod的伸縮和刪除,在Pod的所有前身都處于健康狀態之前,任何Pod都不能進行更新或擴展。類似地,在Pod終止之前,必須關閉所有后續的Pod。這些功能允許對StatefulSet進行穩定的、可預測的更改。
下面是StatefulSet定義的一個示例:
apiVersion: v1
kind: StatefulSet
metadata:
name: web
spec:
selector:
matchLabels:
app: nginx # has to match .spec.template.metadata.labels
replicas: 3
template:
metadata:
labels:
app: nginx # has to match .spec.selector.matchLabels
spec:
terminationGracePeriodSeconds: 10
containers:
— name: nginx
image: nginx
ports:
— containerPort: 80
name: web
volumeMounts:
— name: www
mountPath: /usr/share/nginx/html
volumeClaimTemplates:
— metadata:
name: www
spec:
storageClassName: mysc
resources:
requests:
storage: 1Gi
如上所示,StatefulSet的名稱在metada下的name中指定,在創建封閉的Pod時將使用該名稱。這個StatefulSets定義將產生名為web-0、web-1和web-2的三個Pod。
這個特定的StatefulSet通過spec下的volumeClaimTemplates字段利用Pvc,以便將持久卷附加到每個Pod。
StatefulSet的關鍵要點:
* StatefulSet將其封閉的pod命名為唯一的,允許存在需要不可互換pod的應用程序
*以有序的方式處理StatefulSet的部署、擴展和刪除
雖然StatefulSet提供了部署和管理不可互換Pod的能力,但仍然存在一個問題:我如何找到和使用它們。這就是Headless Service發揮作用的地方。
Kubernetes Headless服務
有時我們的應用程序不希望或不需要負載平衡或單個服務IP,諸如此類的應用程序(主數據庫和副本數據庫、分布式應用程序中的代理等)需要一種將流量路由到支持服務的各個分離Pod的方法。具有唯一網絡標識符的Headless服務和Pod (例如使用statefulset創建的那些標識符)可以在此用例中一起使用。能夠直接路由到單個Pod將大量的性能重新交到開發人員手中,從處理服務發現到直接路由到主數據庫Pod。
下面是一個Headless服務的例子:
apiVersion: v1
kind: Service
metadata:
name: nginx-svc
spec:
clusterIP: None
selector:
app: nginx
ports:
— name: http
protocol: TCP
port: 80
targetPort: 30001
— name: https
protocol: TCP
port: 443
targetPort: 30002
使該規范真正“Headless”的屬性是設置.spec下的clusterIP為None。這個特殊的示例使用spec下的selector字段,以指定應該如何配置DNS。在這個例子中,所有匹配app: nginx選擇器的Pods將創建一條A記錄,直接指向支持服務的Pod。關于DNS如何為Headless服務自動配置的更多信息,可以在這里(https://kubernetes.io/docs/concepts/services-networking/service/#headless-services)找到。這個特殊的規范將創建端點nginx-svc-0、nginx-svc-1、nginx-svc-2,它們將分別直接路由到名為web-0、web-1和web-2的Pod。
Headless服務的要點:
*無頭服務允許直接路由到特定的豆莢
*使應用程序開發人員能夠以他們認為合適的方式處理服務發現
結論
Kubernetes使有狀態應用程序開發在容器世界中成為現實,特別是在管理應用程序狀態和持久數據時。持久卷和持久卷聲明建立在卷的基礎之上,以支持持久數據存儲,從而支持在一個主要是短暫性的環境中保持數據持久性。存儲類進一步擴展了這一思想,允許按需提供存儲資源。StatefulSet提供Pod惟一性和粘滯標識,為每個Pod提供有狀態標識,這些標識在Pod中斷和重啟期間持續存在。Headless服務可以與StatefulSet一起使用,為應用程序開發人員提供根據應用程序需求來利用Pod的獨特性的能力。
本文介紹了Kubernetes中有狀態應用程序所需的基本元素。隨著Kubernetes的不斷發展,圍繞有狀態應用程序的功能將繼續出現。對于有狀態應用程序開發人員和集群管理員來說,了解這些基本元素是非常重要的。
到此,相信大家對“如何利用Kubernetes實現容器的持久化存儲”有了更深的了解,不妨來實際操作一番吧!這里是億速云網站,更多相關內容可以進入相關頻道進行查詢,關注我們,繼續學習!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





