溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹“web分布式系統時間、時鐘和事件順序是什么”,在日常操作中,相信很多人在web分布式系統時間、時鐘和事件順序是什么問題上存在疑惑,小編查閱了各式資料,整理出簡單好用的操作方法,希望對大家解答”web分布式系統時間、時鐘和事件順序是什么”的疑惑有所幫助!接下來,請跟著小編一起來學習吧!
物理時鐘 vs 邏輯時鐘
可能有人會問,為什么分布式系統不使用物理時鐘(physical clock)記錄事件?每個事件對應打上一個時間戳,當需要比較順序的時候比較相應時間戳就好了。
這是因為現實生活中物理時間有統一的標準,而分布式系統中每個節點記錄的時間并不一樣,即使設置了 NTP 時間同步節點間也存在毫秒級別的偏差[1][2]。因而分布式系統需要有另外的方法記錄事件順序關系,這就是邏輯時鐘(logical clock)。

Lamport timestamps
Leslie Lamport 在1978年提出邏輯時鐘的概念,并描述了一種邏輯時鐘的表示方法,這個方法被稱為Lamport時間戳(Lamport timestamps)[3]。
分布式系統中按是否存在節點交互可分為三類事件,一類發生于節點內部,二是發送事件,三是接收事件。Lamport時間戳原理如下:
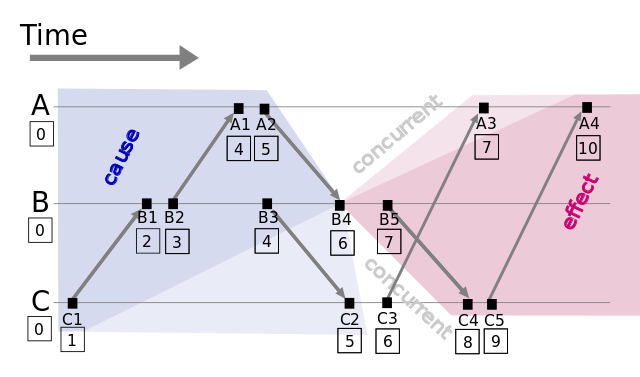
圖1: Lamport timestamps space time (圖片來源: wikipedia)
每個事件對應一個Lamport時間戳,初始值為0
如果事件在節點內發生,時間戳加1
如果事件屬于發送事件,時間戳加1并在消息中帶上該時間戳
如果事件屬于接收事件,時間戳 = Max(本地時間戳,消息中的時間戳) + 1
假設有事件a、b,C(a)、C(b)分別表示事件a、b對應的Lamport時間戳,如果C(a) < C(b),則有a發生在b之前(happened before),記作 a -> b,例如圖1中有 C1 -> B1。通過該定義,事件集中Lamport時間戳不等的事件可進行比較,我們獲得事件的 偏序關系(partial order)。
如果C(a) = C(b),那a、b事件的順序又是怎樣的?假設a、b分別在節點P、Q上發生,Pi、Qj分別表示我們給P、Q的編號,如果 C(a) = C(b) 并且 Pi j
,同樣定義為a發生在b之前,記作 a => b。假如我們對圖1的A、B、C分別編號Ai = 1、Bj = 2、Ck = 3,因 C(B4) = C(C3) 并且 Bj < Ck,則 B4 => C3。
通過以上定義,我們可以對所有事件排序、獲得事件的 全序關系(total order)。上圖例子,我們可以從C1到A4進行排序。
Vector clock
Lamport時間戳幫助我們得到事件順序關系,但還有一種順序關系不能用Lamport時間戳很好地表示出來,那就是同時發生關系(concurrent)[4]。例如圖1中事件B4和事件C3沒有因果關系,屬于同時發生事件,但Lamport時間戳定義兩者有先后順序。
Vector clock是在Lamport時間戳基礎上演進的另一種邏輯時鐘方法,它通過vector結構不但記錄本節點的Lamport時間戳,同時也記錄了其他節點的Lamport時間戳[5][6]。Vector clock的原理與Lamport時間戳類似,使用圖例如下:
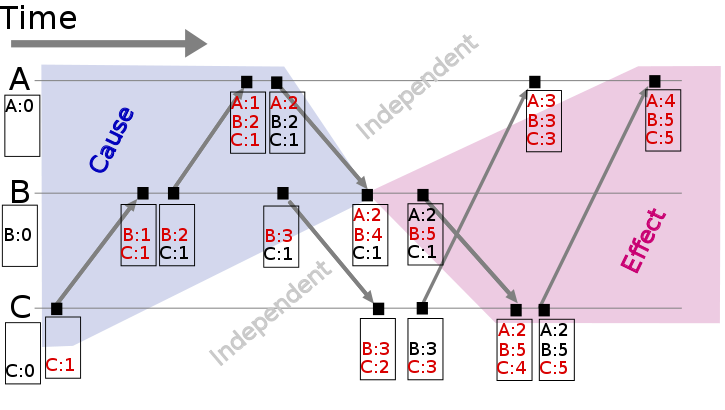
圖2: Vector clock space time (圖片來源: wikipedia)__
假設有事件a、b分別在節點P、Q上發生,Vector clock分別為Ta、Tb,如果 Tb[Q] > Ta[Q] 并且 Tb[P] >= Ta[P],則a發生于b之前,記作 a -> b。到目前為止還和Lamport時間戳差別不大,那Vector clock怎么判別同時發生關系呢?
如果 Tb[Q] > Ta[Q] 并且 Tb[P] < Ta[P],則認為a、b同時發生,記作 a <-> b。例如圖2中節點B上的第4個事件 (A:2,B:4,C:1) 與節點C上的第2個事件 (B:3,C:2) 沒有因果關系、屬于同時發生事件。
Version vector
基于Vector clock我們可以獲得任意兩個事件的順序關系,結果或為先后順序或為同時發生,識別事件順序在工程實踐中有很重要的引申應用,最常見的應用是發現數據沖突(detect conflict)。
分布式系統中數據一般存在多個副本(replication),多個副本可能被同時更新,這會引起副本間數據不一致[7],Version vector的實現與Vector clock非常類似[8],目的用于發現數據沖突[9]。下面通過一個例子說明Version vector的用法[10]:
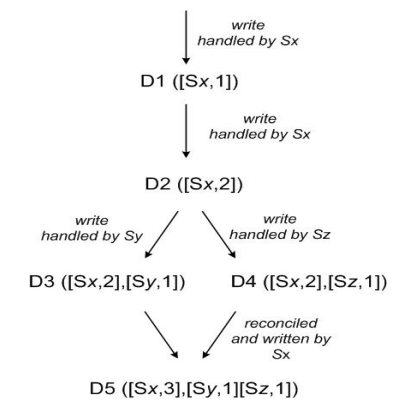
圖3: Version vector
client端寫入數據,該請求被Sx處理并創建相應的vector ([Sx, 1]),記為數據D1
第2次請求也被Sx處理,數據修改為D2,vector修改為([Sx, 2])
第3、第4次請求分別被Sy、Sz處理,client端先讀取到D2,然后D3、D4被寫入Sy、Sz
第5次更新時client端讀取到D2、D3和D4 3個數據版本,通過類似Vector clock判斷同時發生關系的方法可判斷D3、D4存在數據沖突,最終通過一定方法解決數據沖突并寫入D5
Vector clock只用于發現數據沖突,不能解決數據沖突。如何解決數據沖突因場景而異,具體方法有以最后更新為準(last write win),或將沖突的數據交給client由client端決定如何處理,或通過quorum決議事先避免數據沖突的情況發生[11]。
由于記錄了所有數據在所有節點上的邏輯時鐘信息,Vector clock和Version vector在實際應用中可能面臨的一個問題是vector過大,用于數據管理的元數據(meta data)甚至大于數據本身[12]。
解決該問題的方法是使用server id取代client id創建vector (因為server的數量相對client穩定),或設定最大的size、如果超過該size值則淘汰最舊的vector信息[10][13]。
到此,關于“web分布式系統時間、時鐘和事件順序是什么”的學習就結束了,希望能夠解決大家的疑惑。理論與實踐的搭配能更好的幫助大家學習,快去試試吧!若想繼續學習更多相關知識,請繼續關注億速云網站,小編會繼續努力為大家帶來更多實用的文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





