溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
以下是整個PaaS平臺的架構
其中主要包括這些子系統:
微服務治理框架:為應用提供自動注冊、發現、治理、隔離、調用分析等一系列分布式/微服務治理能力,屏蔽分布式系統的復雜度。
應用調度與資源管理框架:打通從應用建模、編排部署到資源調度、彈性伸縮、監控自愈的生命周期管理自動化。
應用開發流水線框架:打通從編寫代碼提交到自動編譯打包、持續集成、自動部署上線的一系列CI/CD全流程自動化。
云中間件服務:應用云化所需的數據庫、大數據、通信和應用中間件服務;通過服務集成管控可集成傳統非云化的中間件能力。
面對一個如此復雜的系統,性能優化工作是一個非常艱巨的挑戰,這里有這么一些痛點:
源代碼及開發組件多,100+ git repo,整體構建超過1天
運行架構復雜,全套安裝完需要30+VM,200+進程
軟件棧深,網絡平面復雜
集群規模大,5k — 10k節點環境搭建非常困難
系統操作會經過分布式的多個組件,無法通過單一組件診斷發現系統瓶頸
無法追蹤上千個處于不同層次的API的時延和吞吐
大部分開發人員專注于功能開發,無法意識到自己的代碼可能造成性能問題
那么,對于這么一個大的、復雜的系統,從方法論的角度來講,應該怎么去優化呢?基本思路就是做拆分,把一個大的問題分解為多個互相不耦合的維度,進行各個擊破。從大的維度來講,一個PaaS容器集群,可以分為3個大的子系統。
控制子系統:控制指令的下發和運行(k8s),例如創建pod
業務流量子系統:容器網絡(flannel)、負載均衡(ELB/kube-proxy)
監控子系統:監控告警數據的采集(kafka, Hadoop)
這個看起來僅僅是一個架構上的劃分,那么如何和具體的業務場景對應起來呢?我們可以考慮如下一個場景,在PaaS平臺上大批量的部署應用。看看在部署應用的過程中,會對各個子系統產生什么壓力。
應用軟件包大小:400M
應用模板大小:10M
1000個節點,每個節點一個POD,一個實例
10種類型的軟件包,依賴長度為3,10GB 網絡
調度及資源管理 3VM
這是一個典型的部署應用的一些規格,那么對于這樣的一個輸入,我們可以按照架構把壓力分解到每個子系統上,這樣得出的子系統需要支撐的指標是:
控制子系統: kubernetes調度速度 > 50 pods/s,倉庫支持300并發下載,>40M/s
數據子系統:overlay容器網絡TCP收發性能損耗 <5%
監控子系統:在上面這個場景中不涉及,但可以從別的場景大致告警處理能力100條/秒
這里的業務場景:架構分析:子系統指標,這三者是m:1:n的,也就是說在不同場景下對不同的組件的性能要求不同,最后每個組件需要取自己指標的最大值。
指標決定了后續怎么進行實驗測試,而測試是要花較大時間成本的,所以在指標的選取上要求少求精,盡量力圖用2-3個指標衡量子系統。
上面講的還是偏紙上的推演和分析,接下來進入實戰階段
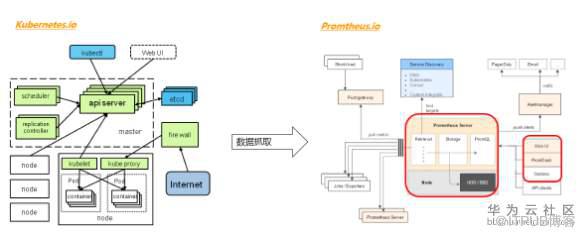
對于服務器后端的程序來講,推薦使用Promtheus這個工具來做指標的定義和采集。Promtheus的基本工作原理是:后端程序引入Promtheus的SDK,自定義所有需要的測量的指標,然后開啟一個http的頁面,定期刷新數據。Promtheus服務器會定期抓取這個頁面上的數據,并存在內部的時間序列數據庫內。這種抓而非推的方式減少了對被測試程序的壓力,避免了被測程序要頻繁往外發送大量數據,導致自身性能反而變差而導致測量不準確。Promtheus支持這幾種數據類型:
計數(對應收集器初始化方法NewCounter、NewCounterFunc、NewCounterVec,單一數值,數值一直遞增,適合請求數量統計等)
測量(對應收集器初始化方法NewGauge、NewGaugeFunc、NewGaugeVec,單一數值,數值增減變動,適合CPU、Mem等的統計)
直方圖測量(對應收集器初始化方法NewHistogram、NewHistogramVec,比較適合時長等的統計)
概要測量(對應收集器初始化方法NewSummary、NewSummaryVec,比較適合請求時延等的統計)
我們可以看看在kubernetes項目里面是怎么用的:
var ( // TODO(a-robinson): Add unit tests for the handling of these metrics once // the upstream library supports it. requestCounter = prometheus.NewCounterVec( prometheus.CounterOpts{ Name: "apiserver_request_count", Help: "Counter of apiserver requests broken out for each verb, API resource, client, and HTTP response contentType and code.", }, []string{"verb", "resource", "client", "contentType", "code"}, ) requestLatencies = prometheus.NewHistogramVec( prometheus.HistogramOpts{ Name: "apiserver_request_latencies", Help: "Response latency distribution in microseconds for each verb, resource and client.", // Use buckets ranging from 125 ms to 8 seconds. Buckets: prometheus.ExponentialBuckets(125000, 2.0, 7), }, []string{"verb", "resource"}, ) requestLatenciesSummary = prometheus.NewSummaryVec( prometheus.SummaryOpts{ Name: "apiserver_request_latencies_summary", Help: "Response latency summary in microseconds for each verb and resource.",// Make the sliding window of 1h. MaxAge: time.Hour, }, []string{"verb", "resource"}, ) )
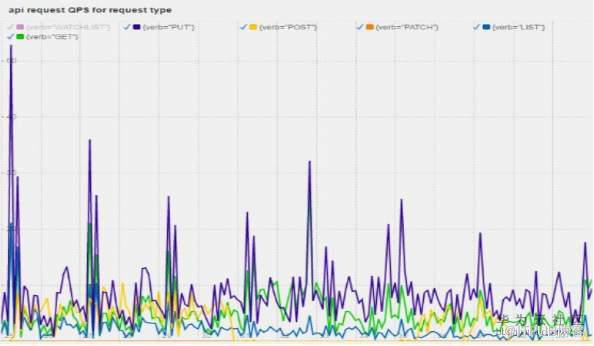
在這里,一個http請求被分為verb, resource, client, contentType, code這五個維度,那么后面在PromDash上就能圖形化的畫出這些請求的數量。 從而分析哪種類型的請求是最多,對系統造成最大壓力的,如圖
除了Promtheus,還可以引入其他的測量手段,對系統進行分析。
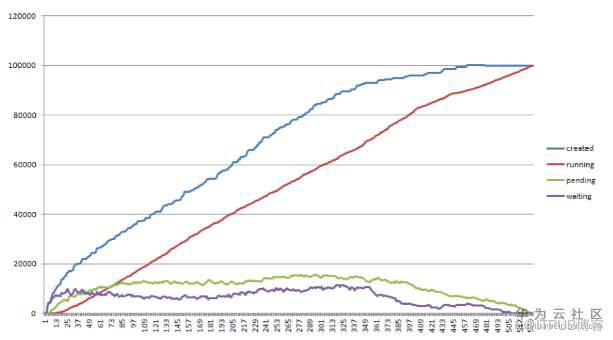
在kubernetes調度過程中,各個狀態Pod的數量,看哪一步是最卡的
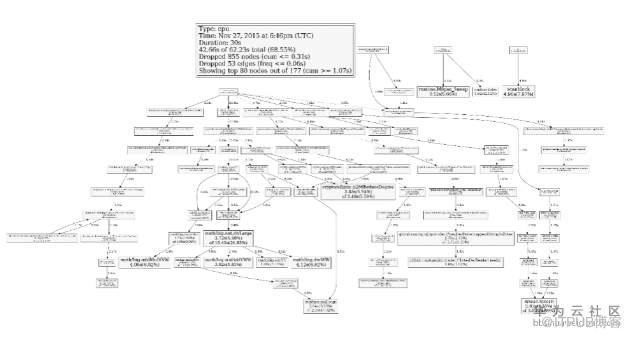
go pprof分析,哪些函數是最耗CPU的
發現了瓶頸之后,下一步就是解決瓶頸,和具體業務邏輯有關,本文在這里就不做過多的闡釋。需要對相關代碼非常熟悉,在不改變功能的情況下增強性能,基本思路為并發/緩存/去除無用步驟等。
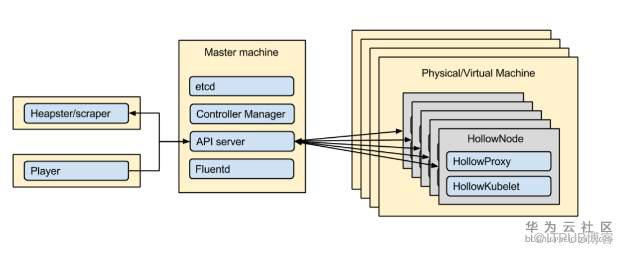
在上面的優化過程當中,基本上工程師要做幾百次優化的測試和開發。這里會產生一個循環:
測試尋找瓶頸點
修改代碼突破這個瓶頸點
重新測試驗證這段代碼是否有效,是否需要改優化思路
這就是一個完整的優化的迭代過程,在這個過程當中,大部分時間被浪費在構建代碼、搭建環境、輸出報告上。開發人員真正思考和寫代碼的時間比較短。為了解決這個問題,就需要做很多自動化的工作。在kubernetes優化的過程中,有這么幾項方法可以節省時間:
5.PNG
kubemark模擬器 :社區項目,使用容器模擬虛擬機,在測試中模擬比達到1:20,也就是一臺虛擬機可以模擬20臺虛擬機對apiserver產生的壓力。在測試過程當中,我們使用了500臺虛擬機,模擬了10000節點的控制面行為。
CI集成:提交PR后自動拉性能優化分支并開始快速構建
CD集成:使用I層的快照機制,快速搭建集群并執行測試案例輸出測試報告
以上都是在實踐過程中總結的一些點,對于不同的項目工程應該有很多點可以做進一步的優化,提升迭代效率。
在搭建完這套系統后,我們發現這個系統可以從源頭上預防降低系統性能的代碼合入主線。如果一項特性代碼造成了性能下降,在CI的過程當中,功能開發者就能收到性能報告,這樣開發者就能自助式的去查找自己代碼的性能問題所在,減少性能工程師的介入。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





