溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
Hive方便地實現存儲過程是怎樣的,針對這個問題,這篇文章詳細介紹了相對應的分析和解答,希望可以幫助更多想解決這個問題的小伙伴找到更簡單易行的方法。
第一種是 HPL/SQL。這種方式目前還不完善,比如游標使用限制多,很多功能無法實現,對變量要求嚴格,經常發生不兼容的錯誤。只要可調試,代碼報錯并非障礙,但 HPL/SQL 的問題在于不可調試,對于開發者就很不方便。
更不方便的是,HPL/SQL 缺乏 JDBC 接口,無法方便地嵌入 JAVA 程序,只能在 JAVA 中調用命令行執行 HPL/SQL,再由 HPL/SQL 實施計算并將結果回寫 Hive 臨時表,最后 JAVA 通過 Hive 的 JDBC 讀取臨時表。
第二種是用 JAVA 開發的 UDF 間接實現。JAVA 缺乏結構化計算類庫,所有的算法都要硬編碼,比如最基本的二維表要用 ArrayList+HashMap 組合實現,最簡單的分組匯總要寫幾十行,關聯計算更是冗長繁瑣。由于硬編碼很難統一規則,所以即使相似的業務邏輯,具體算法也是千差萬別,這就導致代碼可讀性差、維護困難。
JAVA 存儲過程還存在高耦合性的問題。JAVA 類無法進行熱部署,每次修改都要重新編譯并重啟 Hive 服務,這會對生產環境產生嚴重影響。如果設計一個巧妙的結構,也許能降低耦合性,但項目成本必然大幅上升。
如果使用集算器,實現 Hive 存儲過程就會方便很多。
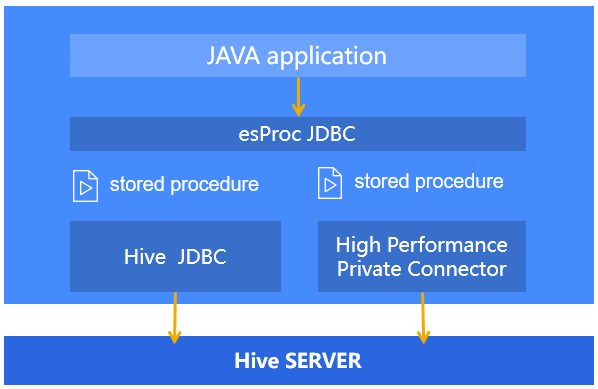
集算器具有豐富的結構化類庫,無論查詢、排序、聚合還是分組匯總、關聯查詢,都可以用內置函數直接實現。集算器也提供了針對結構化數據的分支判斷、循環語句、動態語法,復雜業務邏輯也可輕松實現。集算器允許設置斷點、跟蹤調試,以便程序員快速排錯。向上接口方面,集算器提供了標準的 JDBC 驅動,供 JAVA 代碼調用,實際的存儲過程則以腳本文件的形式存在,修改存儲過程不影響 JAVA 代碼或 Hive 服務。向下接口方面,集算器除了支持標準的 Hive JDBC,還提供了更高性能的私有接口,兩者都可執行 HSQL 語句。
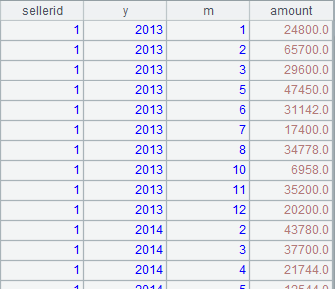
例子:Hive 中 sales 表按銷售、年、月分組匯總后如下:
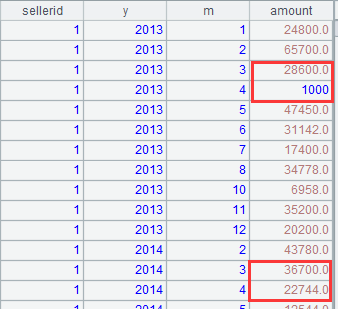
存儲過程算法:調整每個銷售 Q1Q2 的賬務,具體是將 4 月份的 1000 元轉移到 3 月份。要求對同一個銷售同一年的數據做調整,如果 3 月份缺失,則調整時需在 3 月份追加 -1000 的空記錄,以便平衡賬務,如果 4 月份缺失,則調整時在 4 月份追加 1000 的空記錄,都缺失則不做調整。
計算結果應當如下:
集算器存儲過程如下:
| A | B | C | D | |
| 1 | =connect@l("hiveDB") | /connect to hive via jdbc | ||
| 2 | =A1.cursor@x("select sellerid,year(orderdate) y,month(orderdate) m,sum(amount)amount from sales group by sellerid,year(orderdate),month(orderdate) order by sellerid, year(orderdate),month(orderdate)") | /run HSQL | ||
| 3 | =A2.create() | /prepare a blank result | ||
| 4 | for A2;[sellerid,y] | /batch for every year of every seller | ||
| 5 | =A4.select(m==3) | =A4.select(m==4) | /reocrd of Mar. and Apr. | |
| 6 | if B5!=[] && C5!=[] | >B5.amount=B5.amount-1000 | /if both exist then modify batch | |
| 7 | >C5.amount=C5.amount+1000 | |||
| 8 | else if B5==[] &&C5!=[] | >A3.record([A4.sellerid,A4.y,3,-1000]) | /if Mar. not exists then add new reocord to result | |
| 9 | >C5.amount=C5.amount+1000 | /modify batch | ||
| 10 | else if B5!=[] &&C5==[] | >B5.amount=B5.amount-1000 | /if Apr. not exists then add new record to result | |
| 11 | >A3.record([A4.sellerid,A4.y,4,1000]) | /modify batch | ||
| 12 | >A3.paste@i(A4.(sellerid),A4.(y),A4.(m),A4.(amount)) | /union up this batch to result | ||
| 13 | return A3.sort(sellerid,y,m) | /sort and return result | ||
關于Hive方便地實現存儲過程是怎樣的問題的解答就分享到這里了,希望以上內容可以對大家有一定的幫助,如果你還有很多疑惑沒有解開,可以關注億速云行業資訊頻道了解更多相關知識。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





