溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章給大家分享的是有關如何使用RabbitMQ實現RPC的內容。小編覺得挺實用的,因此分享給大家做個參考,一起跟隨小編過來看看吧。
背景知識
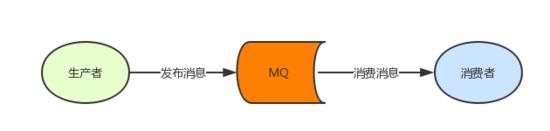
RabbitMQ
RabbitMQ 是基于 AMQP 協議實現的一個消息隊列(Message Queue),Message Queue 是一個典型的生產者/消費者模式。生產者發布消息,消費者消費消息,生產者和消費者之間是解耦的,互相不知道對方的存在。
RPC
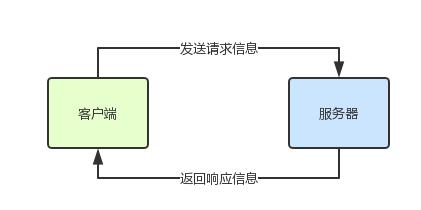
Remote Procedure Call:遠程過程調用,一次遠程過程調用的流程即客戶端發送一個請求到服務端,服務端根據請求信息進行處理后返回響應信息,客戶端收到響應信息后結束。
如何使用 RabbitMQ 實現 RPC?
使用 RabbitMQ 實現 RPC,相應的角色是由生產者來作為客戶端,消費者作為服務端。
但 RPC 調用一般是同步的,客戶端和服務器也是緊密耦合的。即客戶端通過 IP/域名和端口鏈接到服務器,向服務器發送請求后等待服務器返回響應信息。
但 MQ 的生產者和消費者是完全解耦的,那么如何用 MQ 實現 RPC 呢?很明顯就是把 MQ 當作中間件實現一次雙向的消息傳遞:
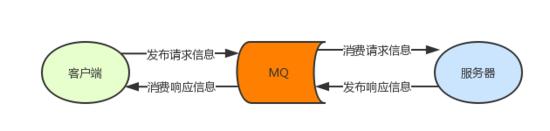
客戶端和服務端即是生產者也是消費者。客戶端發布請求,消費響應;服務端消費請求,發布響應。
具體實現
MQ部分的定義
請求信息的隊列
我們需要一個隊列來存放請求信息,客戶端向這個隊列發布請求信息,服務端消費該隊列處理請求。該隊列不需要復雜的路由規則,直接使用 RabbitMQ 默認的 direct exchange 來路由消息即可。
響應信息的隊列
存放響應信息的隊列不應只有一個。如果存在多個客戶端,不能保證響應信息被發布請求的那個客戶端消費到。所以應為每一個客戶端創建一個響應隊列,這個隊列應該由客戶端來創建且只能由這個客戶端使用并在使用完畢后刪除,這里可以使用 RabbitMQ 提供的排他隊列(Exclusive Queue):
channel.queueDeclare(queue:"", durable:false, exclusive:true, autoDelete:false, new HashMap<>())
并且要保證隊列名唯一,聲明隊列時名稱設為空 RabbitMQ 會生成一個唯一的隊列名。
exclusive 設為 true 表示聲明一個排他隊列,排他隊列的特點是只能被當前的連接使用,并且在連接關閉后被刪除。
一個簡單的 demo(使用 pull 機制)
我們使用一個簡單的 demo 來了解客戶端和服務端的處理流程。
發布請求
編寫代碼前的一個小問題
我們在聲明隊列時為每一個客戶端聲明了獨有的響應隊列,那服務器在發布響應時如何知道發布到哪個隊列呢?其實就是客戶端需要告訴服務端將響應發布到哪個隊列,RabbitMQ 提供了這個支持,消息體的 Properties 中有一個屬性 reply_to 就是用來標記回調隊列的名稱,服務器需要將響應發布到 reply_to 指定的回調隊列中。
解決了這個問題之后我們就可以編寫客戶端發布請求的代碼了:
// 定義響應回調隊列
String replyQueueName = channel.queueDeclare("", false, true, false, new HashMap<>()).getQueue();
// 設置回調隊列到 Properties
AMQP.BasicProperties properties = new AMQP.BasicProperties.Builder()
.replyTo(replyQueueName)
.build();
String request = "request";
// 發布請求
channel.basicPublish("", "rpc_queue", properties, request.getBytes());Direct reply-to:
RabbitMQ 提供了一種更便捷的機制來實現 RPC,不需要客戶端每次都定義回調隊列,客戶端發布請求時將 replyTo 設為 amq.rabbitmq.reply-to ,消費響應時也指定消費 amq.rabbitmq.reply-to ,RabbitMQ 會為客戶端創建一個內部隊列
消費請求
接下來是服務端處理請求的部分,接收到請求后經過處理將響應信息發布到 reply_to 指定的回調隊列:
// 服務端 Consumer 的定義
public class RpcServer extends DefaultConsumer {
public RpcServer(Channel channel) {
super(channel);
}
@Override
public void handleDelivery(String consumerTag, Envelope envelope, AMQP.BasicProperties properties, byte[] body) throws IOException {
String msg = new String(body);
String response = (msg + " Received");
// 獲取回調隊列名
String replyTo = properties.getReplyTo();
// 發布響應消息到回調隊列
this.getChannel().basicPublish("", replyTo, new AMQP.BasicProperties(), response.getBytes());
}
}
...
// 啟動服務端 Consumer
channel.basicConsume("rpc_queue", true, new RpcServer(channel));接收響應
客戶端如何接收服務器的響應呢?有兩種方式:1.輪詢的去 pull 回調隊列中的消息,2.異步的消費回調隊列中的消息。我們在這里簡單實現第一種方案。
GetResponse getResponse = null;
while (getResponse == null) {
getResponse = channel.basicGet(replyQueueName, true);
}
String response = new String(getResponse.getBody());一個簡單的基于 RabbitMQ 的 RPC 模型已經實現了,但這個 demo 并不實用,因為客戶端每次發送完請求都要同步的輪詢等待響應消息,只能每次處理一個請求。RabbitMQ 的 pull 模式效率也比較低。
實現一個完備可用的 RPC 模式需要做的工作還有很多,要處理的關鍵點也比較復雜,有句話叫不要重復造輪子,spring 已經實現了一個完備可用的 RPC 模式的庫,接下來我們來了解一下。順便在此給大家推薦一個Java架構方面的交流學習群:698581634,進群即可獲取Java架構師資料:有Spring,MyBatis,Netty源碼分析,高并發、高性能、分布式、微服務架構的原理,JVM性能優化這些成為架構師必備的知識體系,群里一定有你需要的資料,大家趕緊加群吧。
Spring Rabbit 中的實現
和上面 demo 的 pull 模式一次只能處理一個請求相對應的:如何異步的接收響應并處理多個請求呢?關鍵點就在于我們需要記錄請求和響應并將它們關聯起來,RabbitMQ 也提供了支持,Properties 中的另一個屬性 correlation_id 用來標識一個消息的唯一 id。
參考 spring-rabbit 中的 convertSendAndReceive 方法的實現,為每一次請求生成一個唯一的 correlation_id :
private final AtomicInteger messageTagProvider = new AtomicInteger(); ... String messageTag = String.valueOf(this.messageTagProvider.incrementAndGet()); ... message.getMessageProperties().setCorrelationId(messageTag);
并使用一個 ConcurrentHashMap 來維護 correlation_id 和響應信息的映射:
private final Map<String, PendingReply> replyHolder = new ConcurrentHashMap<String, PendingReply>(); ... final PendingReply pendingReply = new PendingReply(); this.replyHolder.put(correlationId, pendingReply);
PendingReply 中有一個 BlockingQueue 存放響應信息,在發送完請求信息后調用 BlockingQueue 的 pull 方法并設置超時時間來獲取響應:
private final BlockingQueue<Object> queue = new ArrayBlockingQueue<Object>(1);
public Message get ( long timeout , TimeUnit unit ) throws InterruptedException { Object reply = this . queue . poll ( timeout , unit ); return reply == null ? null : processReply ( reply
);
}
在獲取響應后不論結果如何,都會將 PendingReply 從 replyHolder 中移除,防止 replyHolder 中積壓超時的響應消息:
try {
reply = exchangeMessages(exchange, routingKey, message, correlationData, channel, pendingReply,messageTag);
} finally {
this.replyHolder.remove(messageTag);
...
}響應信息是何時如何被放到這個 BlockingQueue 中的呢?看一下 RabbitTemplate 接收消息的地方:
public void onMessage(Message message) {
String messageTag;
if (this.correlationKey == null) { // using standard correlationId property
messageTag = message.getMessageProperties().getCorrelationId();
} else {
messageTag = (String) message.getMessageProperties()
.getHeaders().get(this.correlationKey);
}
// 存在 correlation_id 才認為是RPC的響應信息,不存在時不處理
if (messageTag == null) {
logger.error("No correlation header in reply");
return;
}
// 從 replyHolder 中取出 correlation_id 對應的 PendingReply
PendingReply pendingReply = this.replyHolder.get(messageTag);
if (pendingReply == null) {
if (logger.isWarnEnabled()) {
logger.warn("Reply received after timeout for " + messageTag);
}
throw new AmqpRejectAndDontRequeueException("Reply received after timeout");
}
else {
restoreProperties(message, pendingReply);
// 將響應信息 add 到 BlockingQueue 中
pendingReply.reply(message);
}
}以上的 spring 代碼隱去了很多額外部分的處理和細節,只關注關鍵的部分。
至此一個完整可用的由 RabbitMQ 作為中間件實現的 RPC 模式就完成了。
總結
服務端
服務端的實現比較簡單,和一般的 Consumer 的區別只在于需要將請求回復到 replyTo 指定的 queue 中并帶上消息標識 correlation_id 即可
服務端的一點小優化:
超時的處理是由客戶端來實現的,那服務端有沒有可以優化的地方呢?
答案是有的:如果我們的服務端處理比較耗時,如何判斷客戶端是否還在等待響應呢?
我們可以使用 passive 參數去檢查 replyTo 的 queue 是否存在,因為客戶端聲明的是內部隊列,客戶端如果斷掉鏈接了這個 queue 就不存在了,這時服務端就無需處理這個消息了。
客戶端
客戶端承擔了更多的工作量,包括:
聲明 replyTo 隊列(使用 amq.rabbitmq.reply-to 會簡單很多)
維護請求和響應消息(使用唯一的 correlation_id 來關聯)
消費服務端的返回
處理超時等異常情況(使用BlockingQueue來阻塞獲取)
好在 spring 已經實現了一套完備可靠的代碼,我們在清楚了流程和關鍵點之后,可以直接使用 spring 提供的 RabbitTemplate ,無需自己實現。
使用 MQ 實現 RPC 的意義
通過 MQ 實現 RPC 看起來比客戶端和服務器直接通訊要復雜一些,那我們為什么要這樣做呢?或者說這樣做有什么好處:
將客戶端和服務器解耦:客戶端只是發布一個請求到 MQ 并消費這個請求的響應。并不關心具體由誰來處理這個請求,MQ 另一端的請求的消費者可以隨意替換成任何可以處理請求的服務器,并不影響到客戶端。
減輕服務器的壓力:傳統的 RPC 模式中如果客戶端和請求過多,服務器的壓力會過大。由 MQ 作為中間件的話,過多的請求而是被 MQ 消化掉,服務器可以控制消費請求的頻次,并不會影響到服務器。
服務器的橫向擴展更加容易:如果服務器的處理能力不能滿足請求的頻次,只需要增加服務器來消費 MQ 的消息即可,MQ會幫我們實現消息消費的負載均衡。
可以看出 RabbitMQ 對于 RPC 模式的支持也是比較友好地,
amq.rabbitmq.reply-to , reply_to , correlation_id 這些特性都說明了這一點,再加上 spring-rabbit 的實現,可以讓我們很簡單的使用消息隊列模式的 RPC 調用。
感謝各位的閱讀!關于“如何使用RabbitMQ實現RPC”這篇文章就分享到這里了,希望以上內容可以對大家有一定的幫助,讓大家可以學到更多知識,如果覺得文章不錯,可以把它分享出去讓更多的人看到吧!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





