溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容主要講解“多維數據庫Oracle Essbase和IBM Cogons的底層原理”,感興趣的朋友不妨來看看。本文介紹的方法操作簡單快捷,實用性強。下面就讓小編來帶大家學習“多維數據庫Oracle Essbase和IBM Cogons的底層原理”吧!
多維數據庫(Multi Dimensional Database,MDD)使用Dimension(維度)和Cube(數據立方體、數據集市)模型描述數據。
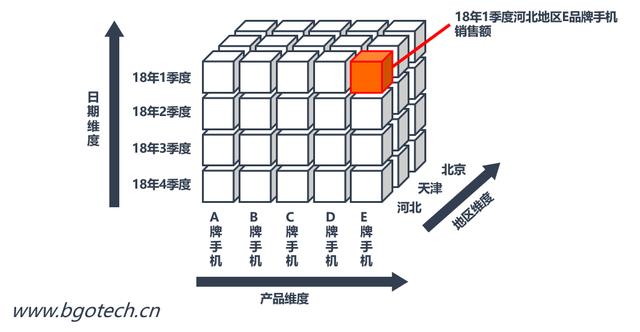
多維數據模型
關系型數據庫(Relational Database,RDB)中的星型結構或雪花型結構就是模擬上述多維模型結構的,但無法提供真正意義上的多維數據分析能力,這里不做過多解釋。
下文講解Oracle Essbase以及IBM Cogons這種真正的多維數據庫的原理。
多維數據庫中模型結構與事實數據分別以概要文件(profile)和數據塊(data block)的形式存在。
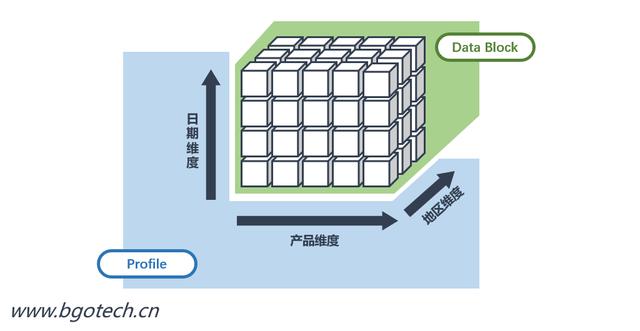
profile和data block
概要文件用來描述以下信息:
維度和維度成員信息
與維度相關的層級(Hierarchy)和級別(Level)信息
Cube的描述性信息,以及Cube與維度的關聯性
其他描述性的信息,如實體模型屬性
Cube中度量數據存放在data block中,data block可以被理解成為多維數組結構,其大小與相關維度的明細成員數量有直接關系。
計算公式:data block size = 維度1明細成員總數 * 維度2明細成員總數 * …… * 維度N明細成員總數
數據塊容量等于相關維度明細成員數量的笛卡爾積。
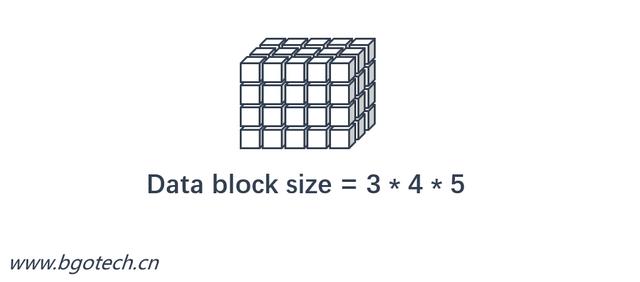
數據塊大小
明細度量值一般采用double類型,按8bytes算,上圖所描述的Cube的數據塊大小為480bytes。
除了數據塊中的明細度量值外,其他非明細度量值并沒有直接存儲,因為其可以通過對應的明細度量值計算出來。
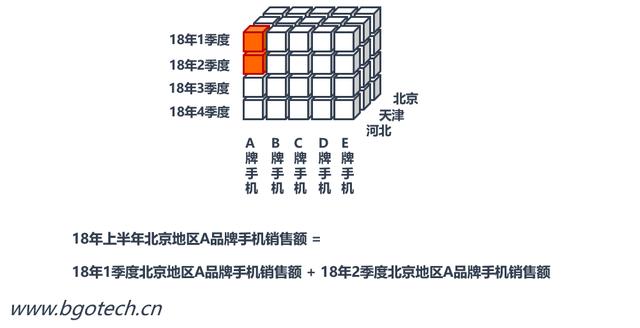
非明細度量值計算方式
一些不存在的度量值會造成數據空洞問題,假設2018年4季度河北省B品牌手機的銷售量是未知的,則會在數據塊中產生一個空洞。
注意:數據空洞表示不存在的值,與數值0的意義不同,數值0表示一個有意義的值。
如果數據空洞比較多,則數據塊的數據密度就會下降,將造成存儲空間的浪費。
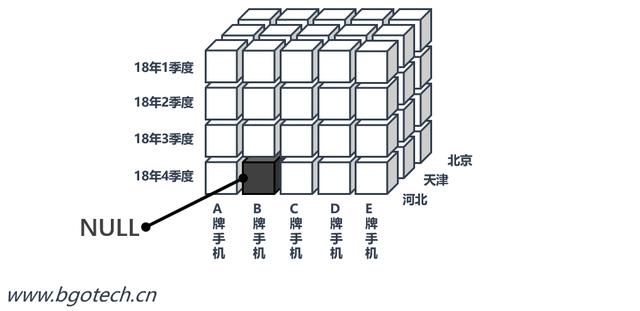
數據空洞
除了數據空洞問題,還存在數據爆炸問題。數據塊大小由全部維度明細成員數量的笛卡爾積決定,假如某個Cube關聯三個維度,每個維度明細成員數量均為100,則:data block size = 100 ^ 3 = 1000000,如果度量值按double類型存儲(8bytes),數據塊文件大約為7.62M。如果每個維度明細成員數量增加至150,則數據塊文件將膨脹到25.74M(data block size = 150 ^ 3 * 8bytes / 1024 / 1024)。
當數據塊極度膨脹并且存在很多數據空洞的時候,會極大地浪費存儲空間,并且可能導致數據存儲無法實現。
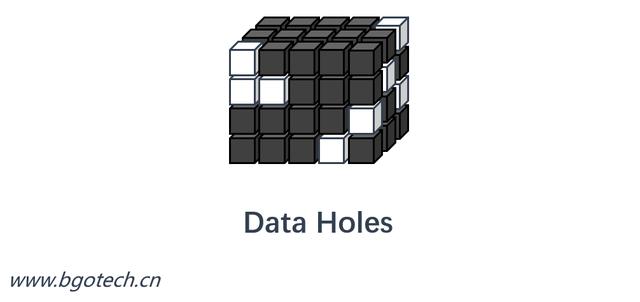
極度膨脹和存在大量空洞的多維數組
為了解決數據空洞和數據膨脹問題,引入了密集維度組合和稀疏維組合的概念。
判斷維度組合是密集還是稀疏的原則是看其所對應的明細度量值的存在情況,例如:
北京地區只有ABC三種手機的銷售額,天津地區只有BCD三種手機的銷售額,河北地區賣出的手機只有AE兩種,表明并不是每個地區對于每一種手機都有銷售額,所以地區與產品屬于稀疏的維度組合。
2018年的四個季度都有手機銷售額,所以日期維度自身可以構成密集的維度組合。
注意!在其他講解多維數據庫的文章中都把維度分為稀疏維與密集維,這是非常錯誤的,對于維度本身來講沒有稀疏與密集之分,稀疏與密集表示的是維度之間的組合!對于有N個維度的Cube而言,如果其只有一個維度退化成索引,或者有N - 1個維度退化成索引,則此時稀疏與密集的維組合只包含一個維度,但這只是一種特例,并不代表維度本身是稀疏或密集的。
在引入稀疏與密集的維度組合之后,原本由于數據空洞和數據爆炸而失控的數據塊結構將變成索引和密度相對較高的小數據塊結構。
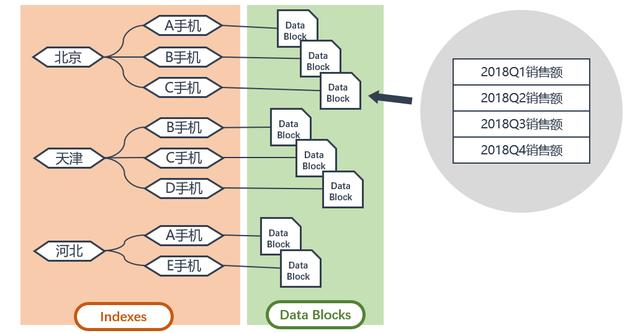
索引和小數據塊
之前數據文件大小為3 * 4 * 5 = 60,結構變換之后每個小數據塊大小為4(共8個),在不計算索引所占存儲大小的情況下,存儲容量變為原來的一半。
度量值的變化可能引起稀疏維度組合和密集維度組合的改變,如下圖所示。
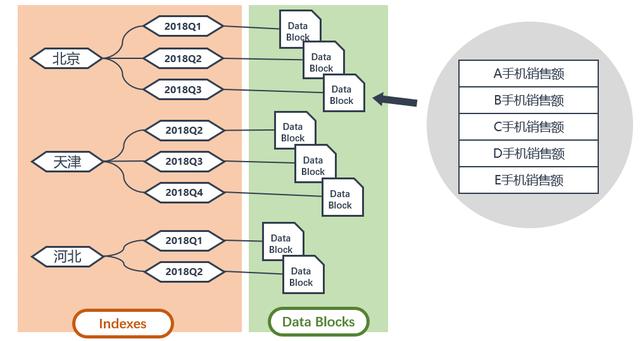
重構
雖然解決了數據空洞和數據爆炸的問題,但稀疏與密集的維組合所帶來的負作用是一旦度量值的變化導致了數據塊密度中心的改變,相關的索引和子數據塊必須重構,而這種重構的性能代價與時間成本是極為昂貴的。Cogons、Essbase等傳統多維數據庫以及其他MOLAP都存在此問題。
基于矢量計算引擎(Vector Calculation Engine)的新型分布式多維數據庫很好的解決了數據重構問題。
矢量計算引擎將海量數據的運算從多維數據庫核心分離出來,進而將多維分析時的邏輯運算與聚集計算解耦。多維數據庫核心只負責邏輯運算,完全不需要再考慮數據量的問題。矢量計算引擎采用極為簡單的數據結構存儲TB、PB級數據,并且只負責進行一種算法上極為簡單的聚集運算,針對此種特性,適宜采用更加接近底層的編程語言進行開發(如C語言),不僅得到了性能上的提升,也因為數據存儲結構的簡單而獲得了更加穩定的運行效果。
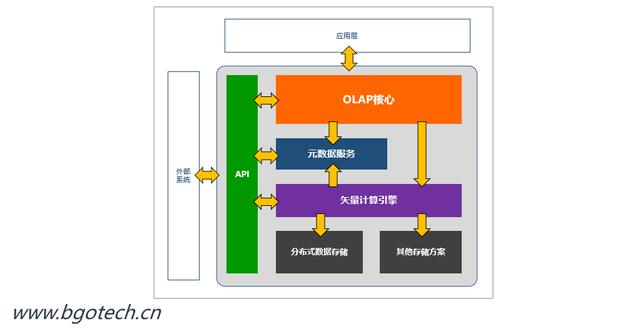
基于矢量計算引擎的多維數據庫
如上圖所示,在多維數據庫內核角度來看,矢量計算引擎是更加底層的一種基礎服務,所以可以根據各種應用場景切換不同的實現方式,而這一切對于多維數據庫內核來說都是透明的,多維數據庫本身對更上層的應用提供一致的數據查詢能力,從而更好的支持了100%面向業務的探索式數據分析能力。
到此,相信大家對“多維數據庫Oracle Essbase和IBM Cogons的底層原理”有了更深的了解,不妨來實際操作一番吧!這里是億速云網站,更多相關內容可以進入相關頻道進行查詢,關注我們,繼續學習!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





