溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容主要講解“如何用Numpy分析各類用戶占比”,感興趣的朋友不妨來看看。本文介紹的方法操作簡單快捷,實用性強。下面就讓小編來帶大家學習“如何用Numpy分析各類用戶占比”吧!
觀察上次的數據,數據中有的數據有會員與非會員兩種用戶類別。
這次我們主要分析一下兩種類別用戶在數據中占比。
根據流程示意圖我們主要遵循下面幾個步驟:

此處代碼為:
# 數據讀取,數據清洗
def read_clean_data():
clndata_arr_list = []
for data_filename in data_filenames:
file = os.path.join(data_path, data_filename)
data_arr = np.loadtxt(file, skiprows=1, delimiter=',', dtype=bytes).astype(str)
cln_arr = np.core.defchararray.replace(data_arr[:, -1], '"', '')
cln_arr = cln_arr.reshape(-1,1)
clndata_arr_list.append(cln_arr)
year_cln_arr = np.concatenate(clndata_arr_list)
return year_cln_arr
這里需要注意兩點:
因為數據較大,我們沒有數據文件具體數據量,所以在使用numpy.reshape時我們可以使用numpy.reshape(-1,1)這樣numpy可以使用統計后的具體數值替換-1。
我們對數據的需求不再是獲取時間的平均值,只需獲取數據最后一列并使用concatenate方法堆疊到一起以便下一步處理。
根據這次的分析目標,我們取出最后一列Member type。
在上一步我們已經獲取了全部的數值,在本部只需篩選統計出會員與非會員的數值就可以了。
我們可以先看下完成后的這部分代碼:
# 數據分析
def mean_data(year_cln_arr):
member = year_cln_arr[year_cln_arr == 'Member'].shape[0]
casual = year_cln_arr[year_cln_arr == 'Casual'].shape[0]
users = [member,casual]
print(users)
return users
同樣,這里使用numpy.shape獲取用戶分類的具體數據。
生成的餅圖:
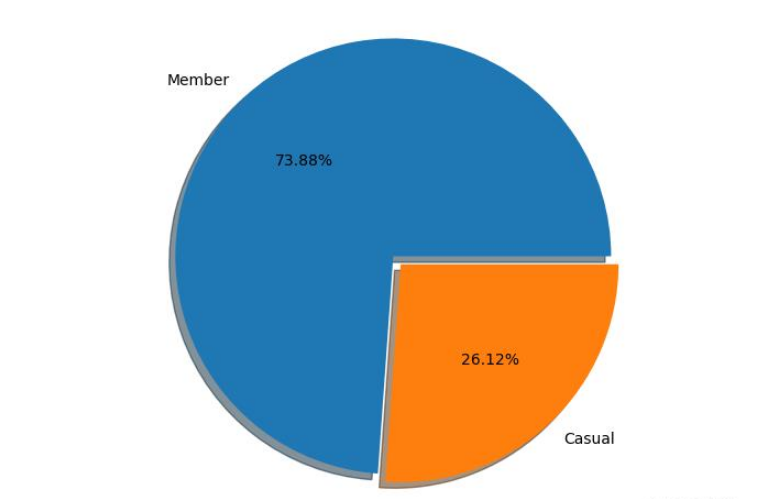
下面是生成餅圖的代碼:
# 結果展示
plt.figure()
plt.pie(users, labels=['Member', 'Casual'], autopct='%.2f%%', shadow=True, explode=(0.05, 0))
plt.axis('equal')
plt.tight_layout()
plt.savefig(os.path.join(output_path, './piechart.png'))
plt.show()
到此,相信大家對“如何用Numpy分析各類用戶占比”有了更深的了解,不妨來實際操作一番吧!這里是億速云網站,更多相關內容可以進入相關頻道進行查詢,關注我們,繼續學習!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





