溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
小編給大家分享一下Java中HashSet原理及常用方法的示例分析,相信大部分人都還不怎么了解,因此分享這篇文章給大家參考一下,希望大家閱讀完這篇文章后大有收獲,下面讓我們一起去了解一下吧!
一. HashSet概述
HashSet是Java集合Set的一個實現類,Set是一個接口,其實現類除HashSet之外,還有TreeSet,并繼承了Collection,HashSet集合很常用,同時也是程序員面試時經常會被問到的知識點,下面是結構圖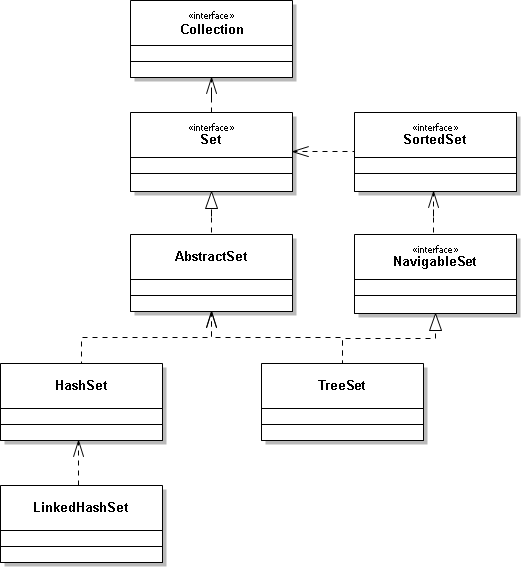
public class HashSetextends AbstractSetimplements Set, Cloneable, java.io.Serializable
{}二. HashSet構造
HashSet有幾個重載的構造方法,我們來看一下
private transient HashMapmap;
//默認構造器
public HashSet() {
map = new HashMap<>();
}
//將傳入的集合添加到HashSet的構造器
public HashSet(Collection< ? extends E> c) {
map = new HashMap<>(Math.max((int) (c.size()/.75f) + 1, 16));
addAll(c);
}
//明確初始容量和裝載因子的構造器
public HashSet(int initialCapacity, float loadFactor) {
map = new HashMap<>(initialCapacity, loadFactor);
}
//僅明確初始容量的構造器(裝載因子默認0.75)
public HashSet(int initialCapacity) {
map = new HashMap<>(initialCapacity);
}通過上面的源碼,我們發現了HashSet就TM是一個皮包公司,它就對外接活兒,活兒接到了就直接扔給HashMap處理了。因為底層是通過HashMap實現的,這里簡單提一下:
HashMap的數據存儲是通過數組+鏈表/紅黑樹實現的,存儲大概流程是通過hash函數計算在數組中存儲的位置,如果該位置已經有值了,判斷key是否相同,相同則覆蓋,不相同則放到元素對應的鏈表中,如果鏈表長度大于8,就轉化為紅黑樹,如果容量不夠,則需擴容(注:這只是大致流程)。
如果對HashMap原理不太清楚的話,可以先去了解一下
HashMap原理(一) 概念和底層架構
HashMap原理(二) 擴容機制及存取原理
三. add方法
HashSet的add方法時通過HashMap的put方法實現的,不過HashMap是key-value鍵值對,而HashSet是集合,那么是怎么存儲的呢,我們看一下源碼
private static final Object PRESENT = new Object();
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}看源碼我們知道,HashSet添加的元素是存放在HashMap的key位置上,而value取了默認常量PRESENT,是一個空對象,至于map的put方法,大家可以看HashMap原理(二) 擴容機制及存取原理。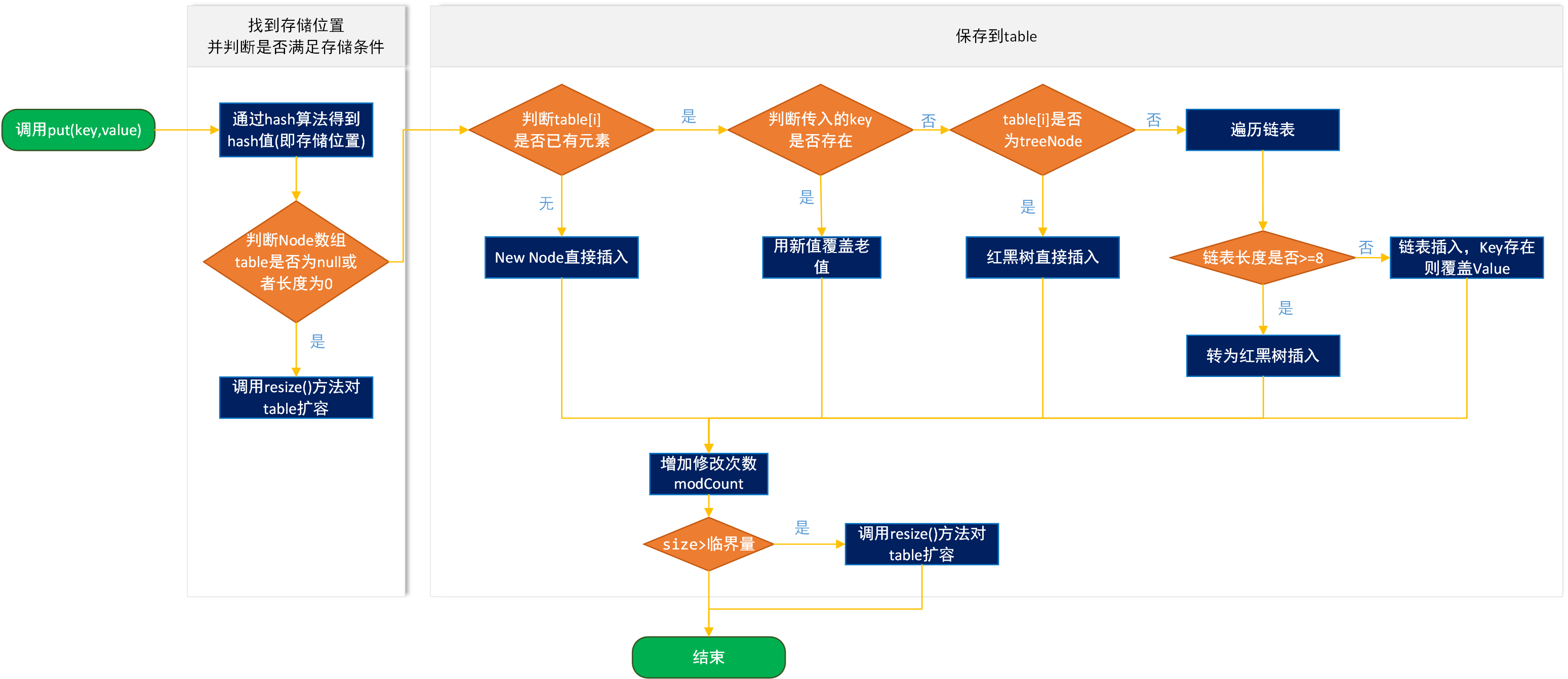
四. remove方法
HashSet的remove方法通過HashMap的remove方法來實現
//HashSet的remove方法
public boolean remove(Object o) {
return map.remove(o)==PRESENT;
}
//map的remove方法
public V remove(Object key) {
Nodee;
//通過hash(key)找到元素在數組中的位置,再調用removeNode方法刪除
return (e = removeNode(hash(key), key, null, false, true)) == null ? null : e.value;
}
/**
*
*/
final NoderemoveNode(int hash, Object key, Object value,
boolean matchValue, boolean movable) {
Node[] tab; Nodep; int n, index;
//步驟1.需要先找到key所對應Node的準確位置,首先通過(n - 1) & hash找到數組對應位置上的第一個node
if ((tab = table) != null && (n = tab.length) > 0 &&
(p = tab[index = (n - 1) & hash]) != null) {
Nodenode = null, e; K k; V v;
//1.1 如果這個node剛好key值相同,運氣好,找到了
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
node = p;
/**
* 1.2 運氣不好,在數組中找到的Node雖然hash相同了,但key值不同,很明顯不對, 我們需要遍歷繼續
* 往下找;
*/
else if ((e = p.next) != null) {
//1.2.1 如果是TreeNode類型,說明HashMap當前是通過數組+紅黑樹來實現存儲的,遍歷紅黑樹找到對應node
if (p instanceof TreeNode)
node = ((TreeNode)p).getTreeNode(hash, key);
else {
//1.2.2 如果是鏈表,遍歷鏈表找到對應node
do {
if (e.hash == hash &&
((k = e.key) == key ||
(key != null && key.equals(k)))) {
node = e;
break;
}
p = e;
} while ((e = e.next) != null);
}
}
//通過前面的步驟1找到了對應的Node,現在我們就需要刪除它了
if (node != null && (!matchValue || (v = node.value) == value ||
(value != null && value.equals(v)))) {
/**
* 如果是TreeNode類型,刪除方法是通過紅黑樹節點刪除實現的,具體可以參考【TreeMap原理實現
* 及常用方法】
*/
if (node instanceof TreeNode)
((TreeNode)node).removeTreeNode(this, tab, movable);
/**
* 如果是鏈表的情況,當找到的節點就是數組hash位置的第一個元素,那么該元素刪除后,直接將數組
* 第一個位置的引用指向鏈表的下一個即可
*/
else if (node == p)
tab[index] = node.next;
/**
* 如果找到的本來就是鏈表上的節點,也簡單,將待刪除節點的上一個節點的next指向待刪除節點的
* next,隔離開待刪除節點即可
*/
else
p.next = node.next;
++modCount;
--size;
//刪除后可能存在存儲結構的調整,可參考【LinkedHashMap如何保證順序性】中remove方法
afterNodeRemoval(node);
return node;
}
}
return null;
}removeTreeNode方法具體實現可參考 TreeMap原理實現及常用方法
afterNodeRemoval方法具體實現可參考LinkedHashMap如何保證順序性
五. 遍歷
HashSet作為集合,有多種遍歷方法,如普通for循環,增強for循環,迭代器,我們通過迭代器遍歷來看一下
public static void main(String[] args) {
HashSetsetString = new HashSet<> ();
setString.add("星期一");
setString.add("星期二");
setString.add("星期三");
setString.add("星期四");
setString.add("星期五");
Iterator it = setString.iterator();
while (it.hasNext()) {
System.out.println(it.next());
}
}打印出來的結果如何呢?
星期二
星期三
星期四
星期五
星期一
意料之中吧,HashSet是通過HashMap來實現的,HashMap通過hash(key)來確定存儲的位置,是不具備存儲順序性的,因此HashSet遍歷出的元素也并非按照插入的順序。
六. 合計合計
按照我前面的規劃,應該每一塊主要的內容都單獨寫一下,如集合ArrayList,LinkedList,HashMap,TreeMap等。不過我在寫這篇關于HashSet的文章時,發現有前面對HashMap的講解后,確實簡單,HashSet就是一個皮包公司,在HashMap外面加了一個殼,那么LinkedHashSet是否就是在LinkedHashMap外面加了一個殼呢,而TreeSet是否是在TreeMap外面加了一個殼?我們來驗證一下
先看一下LinkedHashSet
最開始的結構圖已經提到了LinkedHashSet是HashSet的子類,我們來看源碼
public class LinkedHashSetextends HashSetimplements Set, Cloneable, java.io.Serializable
{
public LinkedHashSet(int initialCapacity, float loadFactor) {
super(initialCapacity, loadFactor, true);
}
public LinkedHashSet(int initialCapacity) {
super(initialCapacity, .75f, true);
}
public LinkedHashSet() {
super(16, .75f, true);
}
public LinkedHashSet(Collection< ? extends E> c) {
super(Math.max(2*c.size(), 11), .75f, true);
addAll(c);
}
public Spliteratorspliterator() {
return Spliterators.spliterator(this, Spliterator.DISTINCT | Spliterator.ORDERED);
}
}上面就是LinkedHashSet的所有代碼了,是不是感覺智商被否定了,這基本上沒啥東西嘛,構造器還全部調用父類的,下面就是其父類HashSet的對此的構造方法
HashSet(int initialCapacity, float loadFactor, boolean dummy) {
map = new LinkedHashMap<>(initialCapacity, loadFactor);
}大家也看出來,和我們的猜測一樣,沒有深究下去的必要了。如果有興趣可以看看LinkedHashMap如何保證順序性
在看一下TreeSet
public class TreeSetextends AbstractSetimplements NavigableSet, Cloneable, java.io.Serializable
{
public TreeSet() {
this(new TreeMap());
}
public TreeSet(Comparator< ? super E> comparator) {
this(new TreeMap<>(comparator));
}
public TreeSet(Collection< ? extends E> c) {
this();
addAll(c);
}
public TreeSet(SortedSets) {
this(s.comparator());
addAll(s);
}
}確實如我們所猜測,TreeSet也完全依賴于TreeMap來實現
以上是“Java中HashSet原理及常用方法的示例分析”這篇文章的所有內容,感謝各位的閱讀!相信大家都有了一定的了解,希望分享的內容對大家有所幫助,如果還想學習更多知識,歡迎關注億速云行業資訊頻道!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





