溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇文章為大家展示了Python中關于數據采集和解析是怎樣的,內容簡明扼要并且容易理解,絕對能使你眼前一亮,通過這篇文章的詳細介紹希望你能有所收獲。
我們已經了解到了開發一個爬蟲需要做的工作以及一些常見的問題,下面我們給出一個爬蟲開發相關技術的清單以及這些技術涉及到的標準庫和第三方庫,稍后我們會一一介紹這些內容。
下載數據 - urllib / requests / aiohttp。
解析數據 - re / lxml / beautifulsoup4 / pyquery。
生成數字簽名 - hashlib。
序列化和壓縮 - pickle / json / zlib。
調度器 - 多進程(multiprocessing) / 多線程(threading)。
HTML頁面
<!DOCTYPE html> <html> <head> <title>Home</title> <style type="text/css"> /* 此處省略層疊樣式表代碼 */ </style> </head> <body> <div> <header> <h2>Yoko's Kitchen</h2> <nav> <ul> <li><a href="">Home</a></li> <li><a href="">Classes</a></li> <li><a href="">Catering</a></li> <li><a href="">About</a></li> <li><a href="">Contact</a></li> </ul> </nav> </header> <section> <article> <figure> <img src="images/bok-choi.jpg" alt="Bok Choi" /> <figcaption>Bok Choi</figcaption> </figure> <hgroup> <h3>Japanese Vegetarian</h3> <h4>Five week course in London</h4> </hgroup> <p>A five week introduction to traditional Japanese vegetarian meals, teaching you a selection of rice and noodle dishes.</p> </article> <article> <figure> <img src="images/teriyaki.jpg" alt="Teriyaki sauce" /> <figcaption>Teriyaki Sauce</figcaption> </figure> <hgroup> <h3>Sauces Masterclass</h3> <h4>One day workshop</h4> </hgroup> <p>An intensive one-day course looking at how to create the most delicious sauces for use in a range of Japanese cookery.</p> </article> </section> <aside> <section> <h3>Popular Recipes</h3> <a href="">Yakitori (grilled chicken)</a> <a href="">Tsukune (minced chicken patties)</a> <a href="">Okonomiyaki (savory pancakes)</a> <a href="">Mizutaki (chicken stew)</a> </section> <section> <h3>Contact</h3> <p>Yoko's Kitchen<br> 27 Redchurch Street<br> Shoreditch<br> London E2 7DP</p> </section> </aside> <footer> ? 2011 Yoko's Kitchen </footer> </div> <script> // 此處省略JavaScript代碼 </script> </body> </html>
如果你對上面的代碼并不感到陌生,那么你一定知道HTML頁面通常由三部分構成,分別是用來承載內容的Tag(標簽)、負責渲染頁面的CSS(層疊樣式表)以及控制交互式行為的JavaScript。通常,我們可以在瀏覽器的右鍵菜單中通過“查看網頁源代碼”的方式獲取網頁的代碼并了解頁面的結構;當然,我們也可以通過瀏覽器提供的開發人員工具來了解更多的信息。
使用requests獲取頁面
GET請求和POST請求。
URL參數和請求頭。
復雜的POST請求(文件上傳)。
操作Cookie。
設置代理服務器。
【說明】:關于requests的詳細用法可以參考它的官方文檔。
頁面解析
幾種解析方式的比較
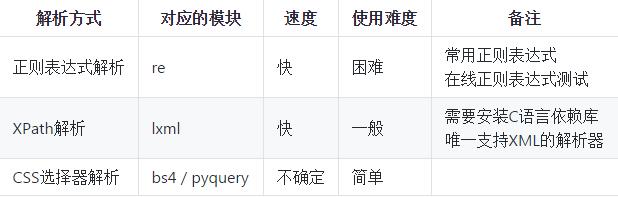
說明:BeautifulSoup可選的解析器包括:Python標準庫(html.parser)、lxml的HTML解析器、lxml的XML解析器和html5lib。
使用正則表達式解析頁面
如果你對正則表達式沒有任何的概念,那么推薦先閱讀《正則表達式30分鐘入門教程》,然后再閱讀我們之前講解在Python中如何使用正則表達式一文。
XPath解析和lxml
XPath是在XML文檔中查找信息的一種語法,它使用路徑表達式來選取XML文檔中的節點或者節點集。這里所說的XPath節點包括元素、屬性、文本、命名空間、處理指令、注釋、根節點等。
<?xml version="1.0" encoding="UTF-8"?> <bookstore> <book> <title>Harry Potter</title> <price>29.99</price> </book> <book> <title>Learning XML</title> <price>39.95</price> </book> </bookstore>
對于上面的XML文件,我們可以用如下所示的XPath語法獲取文檔中的節點。

在使用XPath語法時,還可以使用XPath中的謂詞。

XPath還支持通配符用法,如下所示。

如果要選取多個節點,可以使用如下所示的方法。
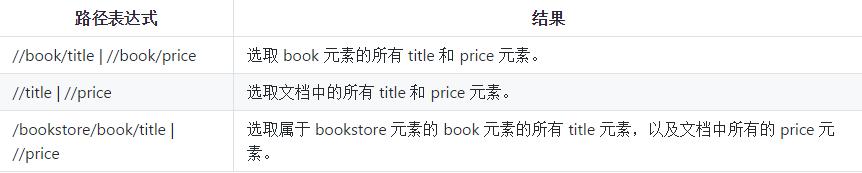
【說明】:上面的例子來自于菜鳥教程網站上XPath教程,有興趣的讀者可以自行閱讀原文。
當然,如果不理解或者不太熟悉XPath語法,可以在Chrome瀏覽器中按照如下所示的方法查看元素的XPath語法。
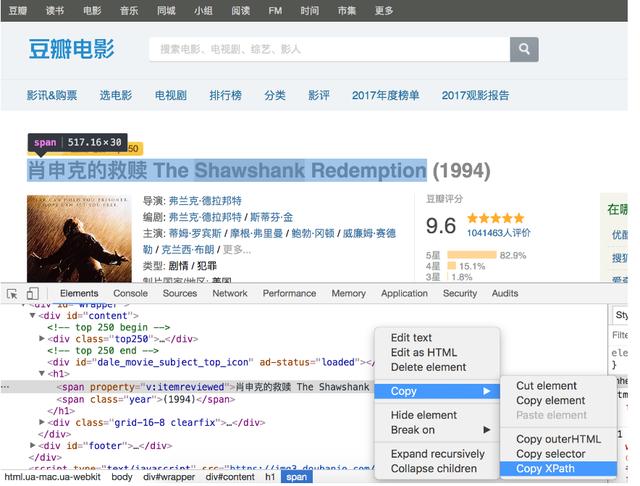
BeautifulSoup的使用
BeautifulSoup是一個可以從HTML或XML文件中提取數據的Python庫。它能夠通過你喜歡的轉換器實現慣用的文檔導航、查找、修改文檔的方式。
1.遍歷文檔樹
獲取標簽
獲取標簽屬性
獲取標簽內容
獲取子(孫)節點
獲取父節點/祖先節點
獲取兄弟節點
2.搜索樹節點
find / find_all
select_one / select
【說明】:更多內容可以參考BeautifulSoup的官方文檔。
PyQuery的使用
pyquery相當于jQuery的Python實現,可以用于解析HTML網頁。
實例 - 獲取知乎發現上的問題鏈接
from urllib.parse import urljoin
import re
import requests
from bs4 import BeautifulSoup
def main():
headers = {'user-agent': 'Baiduspider'}
proxies = {
'http': 'http://122.114.31.177:808'
}
base_url = 'https://www.zhihu.com/'
seed_url = urljoin(base_url, 'explore')
resp = requests.get(seed_url,
headers=headers,
proxies=proxies)
soup = BeautifulSoup(resp.text, 'lxml')
href_regex = re.compile(r'^/question')
link_set = set()
for a_tag in soup.find_all('a', {'href': href_regex}):
if 'href' in a_tag.attrs:
href = a_tag.attrs['href']
full_url = urljoin(base_url, href)
link_set.add(full_url)
print('Total %d question pages found.' % len(link_set))
if __name__ == '__main__':
main()上述內容就是Python中關于數據采集和解析是怎樣的,你們學到知識或技能了嗎?如果還想學到更多技能或者豐富自己的知識儲備,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





