溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
Python教程之Pandas知識點匯總——查詢,索引,基本統計
一. 查詢與索引
1.Series和一維數組的不同:
在一維數組中就無法通過索引標簽(index)獲取數據,index默認是從0開始,步長為1的索引,也可以自己設置索引標簽。
2.若有兩個序列,對其進行算術運算,這時索引就體現了價值——自動化對齊

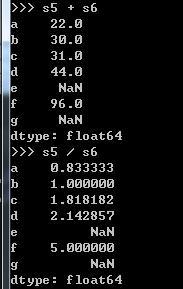
由于s5、s6中存在非對應索引,故結果存在NaN。這里的運算過程就應用了序列索引的自動對齊。對于DataFrame不僅自動對齊行,也會自動對齊列(columns_name)。
3.DataFrame索引
DataFrame數據:

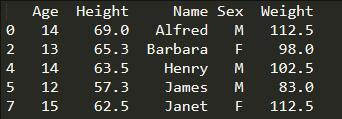
查詢指定行:
print(student.loc[[0,2,4,5,7]]) #這里的loc索引標簽函數必須是中括號[ ]
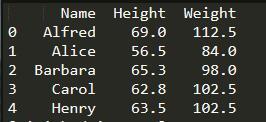
查詢指定列:
print(student[‘Height’].head()) #只查詢一列

print(student[[‘Name’,‘Height’,‘Weight’]].head()) #如果多個列的話,必須使用雙重中括號[]
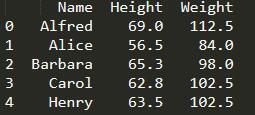
print(student.loc[:,[‘Name’,‘Height’,‘Weight’]].head())
按條件查詢:student[(條件1) & (條件2)]
eg1: 查詢12歲以上的女生信息
print(student[(student['Sex'] == 'F') & (student['Age'] > 12)])
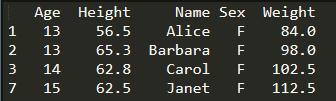
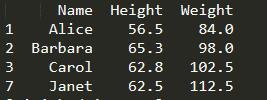
eg2:查詢出12歲以上的女生的姓名、身高和體重
print(student[(student['Sex']=='F') & (student['Age']>12)][['Name','Height','Weight']])
如果是多個條件的查詢,必須使用&(and)或者丨(or)的兩端條件用括號括起來。
二. 簡單的統計分析

在實際工作中,可能處理一些數據型DataFrame,將函數應用到DataFrame中的每一列,可以使用apply函數。
import pandas as pd import numpy as np np.random.seed(1234) d1 = pd.Series(2*np.random.normal(size = 100)+3) d2 = np.random.f(2,4,size = 100) d3 = np.random.randint(1,100,size = 100) def stats(x): return pd.Series( [x.count(),x.min(),x.idxmin(),x.quantile(.25),x.median(),x.quantile(.75), x.mean(),x.max(),x.idxmax(),x.mad(),x.var(),x.std(),x.skew(),x.kurt()], index = ['Count','Min','Whicn_Min','Q1','Median','Q3','Mean','Max','Which_Max','Mad','Var','Std','Skew','Kurt'] ) df = pd.DataFrame(np.array([d1,d2,d3]).T,columns = ['x1','x2','x3']) print(df.head()) print(stats(df['x1'])) print(stats(d1))
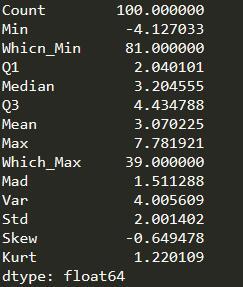
講的還是比較詳細的,有什么疑問的地方,大家可以留言,更多的 Python教程也會繼續為大家更新!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





