溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇文章給大家分享的是有關如何給用Python每天定時給女神發一句情話,小編覺得挺實用的,因此分享給大家學習,希望大家閱讀完這篇文章后可以有所收獲,話不多說,跟著小編一起來看看吧。
我的日記 4月23日 晴
你三天沒回我的消息,在我孜孜不倦地騷擾下你終于舍得回我了,你說‘nmsl’我想這一定是有什么含義吧!噢!我恍然大悟,原來是尼美舒利顆粒。
她知道我關節炎,讓我吃尼美舒利顆粒,她還是關心我的但是又不想顯現的那么熱情的。
天啊!她好高冷,我好像更喜歡她了呢!你看,雖然女神經常不理我,但是還是會偷偷地關心我,雖然她不直說,但是我都懂。
唯一的問題就是,我最近很忙,忙到都沒有時間去給女神發“早安”了。不可以!“早安”絕對不能斷,這是我對女神誠摯的愛,女神雖然不會回復我,但是她肯定都記在心里,不回復我肯定是在考驗我!
作為一名無所不能的程序猿,我立刻就想到為什么不用Python爬取情話,然后每天定時發送給她呢?
爬取情話
選取情話資源
首先我們需要去網上找到合適的情話資源
分析網頁資源
1. 定位情話資源
鼠標放在我們要爬取的情話上快速按下右鍵+檢查(元素)。
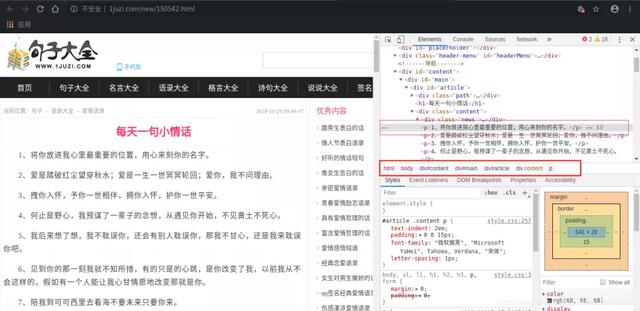
先在就可以看到我們的情話在頁面中是什么位置了。
2. 定位標簽
在開發者工具中,我們輕松的舊定位到了我們的情話的標簽,就是上圖紅框里的內容。
3. 分析請求方式
在剛才的界面(不要退出開發者模式)下刷新:
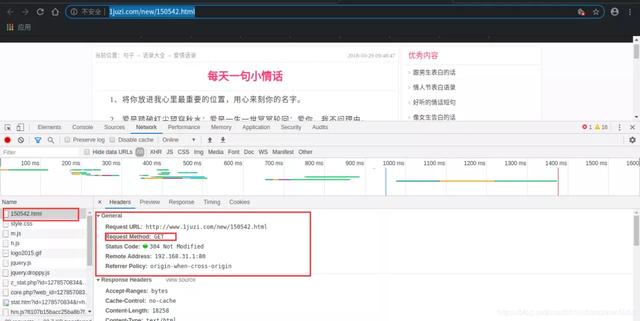
在Network欄目下找到我們請求的那個資源,在他的Headers中找到這個資源請求的方式,這里是GET。
使用urllib庫獲取資源
1、安裝urllib庫
這一步是怕你服務器里沒有urllib2庫,等會兒會造成麻煩才添加上的,如果你沒有添加該庫,請百度添加方法。
2、請求資源網站
代碼:
import urllib.request
url = "http://www.1juzi.com/new/150542.html"
html = urllib.request.urlopen(url).read()
print(html)結果:
......
<h2>??ììò???D??é?°</h2>
<div class="content"><div class="news"><script type="text/javascript">news1();</script></div>
<p>1?¢????·????òD?à?×???òaμ?????£?ó?D?à′?ì??μ???×??£</p>
<p>2?¢°?ê?ì¤??oì3?í?′?????£?°?ê?ò?éúò?êàú¤ú¤????£?°???£??ò2??êàíóé?£</p>
<p>3?¢ק??è??3£?óè??ò?êà?à°é£?óμ??è??3£??¤??ò?êà??°2?£</p>
<p>4?¢o??1ê?ò°D?£??ò?¤?±á?ò?±2×óμ?????£?′óó??????aê?£?2?????íá2??àD??£</p>
<p>5?¢?òoóà′??á???£??ò2?μ¢?ó??£??1?áóD±eè?μ¢?ó??£????ò2??êD?£??1ê??òà′μ¢?ó??°é?£</p>
<p>6?¢??μ???μ???ò??ì?ò?í2??a?ù′?£?óDμ???ê?μ?D?ì?£?ê?????±?á??ò£?ò??°?ò′ó2??á?a?ùμ??£?ùè?óDò???è??üè??òD??ê?é??μ???±????íê????£</p>
<p>7?¢???òμ??é?é?÷à?è¥?′o£2?òa?′à′??òa??à′?£</p>
<p>8?¢??ò?ìì???a??D?ì?£???ò??ì??±????D?ˉ£???ò??????a??μ£D??£óD??μ??D????o??£</p>
<p>9?¢2??ò?ùìy?é?è£?μ±?ò??è?£?òò?a??àá?12?×??£</p>
......小問號,你是否有很多朋友?
我們爬下來的都是亂碼,發給女神一堆亂碼,女神可能還會以為是我們給她發的暗語,說不定還要花時間去尋找解密方法,想想都累,不能這個樣子!
其實出現亂碼的原因主要網頁的編碼方式和我們爬取程序的編碼方式不一樣造成的,只要找到網頁的編碼方式就好。
3、設置解碼類型
有3種方式:
1.從網頁Content-Type中獲取編碼方式
2.第三方庫智能識別編碼,常用chardet等
3.猜測編碼
我們這里其實在請求頭的Content-Type里有編碼類型,但是為了保險起見,也是為了能應用到更多的資源網站,這里演示以下chardet的用法,猜測編碼的使用請自行百度。
chardet獲取編碼類型
代碼:
import urllib.request
import chardet
url = "http://www.1juzi.com/new/150542.html"
html = urllib.request.urlopen(url).read()
print("html頭中的charset:", chardet.detect(html))結果:
/usr/bin/python3.7 /home/baldwin/PycharmProjects/IAmADog/spider/Spider.py
html頭中的charset:{'encoding': 'GB2312', 'confidence': 0.99, 'language': 'Chinese'}
Process finished with exit code 0Get!!!編碼方式為GB2312!
設置解碼
代碼:
import urllib.request
import chardet
url = "http://www.1juzi.com/new/150542.html"
html = urllib.request.urlopen(url).read()
charset = chardet.detect(html).get("encoding")
htmlText = html.decode(charset,errors = 'ignore')
print(htmlText)結果:
......<h2>每天一句小情話</h2><div class="content"><div class="news"><script type="text/javascript">news1();</script></div><p>1、將你放進我心里最重要的位置,用心來刻你的名字。</p><p>2、愛是踏破紅塵望穿秋水;愛是一生一世冥冥輪回;愛你,我不問理由。</p><p>3、拽你入懷,予你一世相伴,擁你入懷,護你一世平安。</p><p>4、何止是野心,我預謀了一輩子的念想,從遇見你開始,不見黃土不死心。</p><p>5、我后來想了想,我不耽誤你,還會有別人耽誤你,那我不甘心,還是我來耽誤你吧。</p><p>6、見到你的那一刻我就不知所措,有的只是的心跳,是你改變了我,以前我從不會這樣的。假如有一個人能讓我心甘情愿地改變那就是你。</p><p>7、陪我到可可西里去看海不要未來只要你來。</p><p>8、每一天都為你心跳,每一刻都被你感動,每一秒都為你擔心。有你的感覺真好。</p>......
哦吼!搞定!
4、封裝代碼
剛才我們已經實現了資源的獲取,但是這樣的代碼用起來太不方便了,我們把它封裝在方法里:
......
import urllib.request
import chardet
def getHtml(url):
"""
獲取網頁html文本資源
:param url: 網頁鏈接
:return: 網頁文本資源
"""
html = urllib.request.urlopen(url).read()
charset = chardet.detect(html).get("encoding")
htmlText = html.decode(charset, errors='ignore')
return htmlText解析網頁資源
解析網頁的話,需要第三方插件Beautiful Soup來提取 xml 和 HTML 中的數據。
獲取content節點內容
我們想要的資源都在一個class為”content“的div節點下,我們現在先獲取這個節點的所有內容。
部分代碼:
soup = BeautifulSoup(htmlText,"html.parser")
"獲取content節點的內容"
div_node = soup.find('div', class_='content')
print(div_node.get_text)結果:
/usr/bin/python3.7 /home/baldwin/PycharmProjects/IAmADog/spider/Spider.py
<bound method Tag.get_text of <div class="content"><div class="news"><script type="text/javascript">news1();</script></div>
<p>1、將你放進我心里最重要的位置,用心來刻你的名字。</p>
<p>2、愛是踏破紅塵望穿秋水;愛是一生一世冥冥輪回;愛你,我不問理由。</p>
<p>3、拽你入懷,予你一世相伴,擁你入懷,護你一世平安。</p>
<p>4、何止是野心,我預謀了一輩子的念想,從遇見你開始,不見黃土不死心。</p>
<p>5、我后來想了想,我不耽誤你,還會有別人耽誤你,那我不甘心,還是我來耽誤你吧。</p>
......
<u>本文地址:<a href="http://www.1juzi.com/new/150542.html">每天一句小情話</a>http://www.1juzi.com/new/150542.html</u>
<li class="page"><a href="/aiqingyulu/">上一頁</a><span class="current">1</span><a href="/new/150543.html">2</a><a href="/new/150541.html">下一頁</a></li>
</div>
Process finished with exit code 02.4.3. 獲取p節點內容
上一步我們已經獲取到了我們的主要內容,然后總結可以看出我們想要的文本內容在P節點中,那么現在就來獲取它。
部分代碼:
soup = BeautifulSoup(htmlText,"html.parser")
"獲取div節點的內容"
div_node = soup.find('div', class_='content')
"獲取P節點內容"
p_node = div_node.find_all('p')
for content in p_node:
print(content.get_text())結果:
/usr/bin/python3.7 /home/baldwin/PycharmProjects/IAmADog/spider/Spider.py
1、將你放進我心里最重要的位置,用心來刻你的名字。
2、愛是踏破紅塵望穿秋水;愛是一生一世冥冥輪回;愛你,我不問理由。
3、拽你入懷,予你一世相伴,擁你入懷,護你一世平安。
4、何止是野心,我預謀了一輩子的念想,從遇見你開始,不見黃土不死心。
5、我后來想了想,我不耽誤你,還會有別人耽誤你,那我不甘心,還是我來耽誤你吧。
......
69、有時,愛也是種傷害,殘忍的人句子大全http://Www.1juzI.coM/,選擇傷害別人,善良的人,選擇傷害自己。
......
Process finished with exit code 04、處理數據
注意一下第69劇,這里面有網站的鏈接,把這個一起發給女神不就露餡了么,現在得想辦法給她刪掉。同時情話前面的編號也得刪掉。
刪除特定標簽
我們會查看一下數據就會發現,所有的鏈接都是在U標簽里的,那我們可以直接在獲取到div標簽內容后就把u標簽刪掉
"刪除特定標簽u"
[s.extract() for s in div_node('u')]刪除序號
我們發現,序號與情話之間是用頓號分割的,那么我們可以將每個P標簽下的內容用split分割并且取出第二個元素就好了。
部分代碼:
"獲取P節點內容"
p_node = div_node.find_all('p')
for content in p_node:
"以’、‘分割,并且取出第2個元素"
text = content.get_text().split("、",1)[1]
print(text)結果:
/usr/bin/python3.7 /home/baldwin/PycharmProjects/IAmADog/spider/Spider.py
將你放進我心里最重要的位置,用心來刻你的名字。
愛是踏破紅塵望穿秋水;愛是一生一世冥冥輪回;愛你,我不問理由。
拽你入懷,予你一世相伴,擁你入懷,護你一世平安。
何止是野心,我預謀了一輩子的念想,從遇見你開始,不見黃土不死心。
我后來想了想,我不耽誤你,還會有別人耽誤你,那我不甘心,還是我來耽誤你吧。
......
Process finished with exit code 0nice啊,到這一步你已經把我們需要的情話都提取出來了!!!
封裝數據備用
這樣一句一句的也不好處理啊!不如把它放到list里,等下定時任務的時候可以用的時候取出來就好。
部分代碼:
sentenceList = list()
......
"獲取P節點內容"
p_node = div_node.find_all('p')
for content in p_node:
"以’、‘分割,并且取出第2個元素"
text = content.get_text().split("、", 1)[1]
"追加到list尾部"
sentenceList.append(text)print(sentenceList):
/usr/bin/python3.7 /home/baldwin/PycharmProjects/IAmADog/spider/Spider.py
['將你放進我心里最重要的位置,用心來刻你的名字。', '愛是踏破紅塵望穿秋水;愛是一生一世冥冥輪回;愛你,我不問理由。', '拽你入懷,予你一世相伴,擁你入懷,護你一世平安。', '何止是野心,我預謀了一輩子的念想,從遇見你開始,不見黃土不死心。', ......]
Process finished with exit code 05、封裝(爬蟲代碼最終)
爬蟲是做好了,但是總覺得乖乖的,我等下還得在其他地方用,不如這里以面向對象的思想把爬蟲封裝一下。
import urllib.request
from bs4 import BeautifulSoup
import chardet
def __getHtml(url):
"""
私有方法:獲取網頁html文本資源
:param url: 網頁鏈接
:return: 網頁文本資源
"""
html = urllib.request.urlopen(url).read()
charset = chardet.detect(html).get("encoding")
htmlText = html.decode(charset, errors='ignore')
return htmlText
def __sloveHtml(htmlText):
"""
私有方法:解析HtmlText
:param htmlText: 傳入的資源
"""
sentenceList = list()
soup = BeautifulSoup(htmlText, "html.parser")
"獲取content節點的內容"
div_node = soup.find('div', class_='content')
"刪除特定標簽u"
[s.extract() for s in div_node('u')]
"獲取P節點內容"
p_node = div_node.find_all('p')
for content in p_node:
"以’、‘分割,并且取出第2個元素"
text = content.get_text().split("、", 1)[1]
"追加到list尾部"
sentenceList.append(text)
return sentenceList
def getSentenceList(url):
"""
Spider提供的公用方法,提供情話list
:param url: 獲取情話的地址
:return: 情話list
"""
return __sloveHtml(__getHtml(url))爬蟲總結
這一部分主要用到的類庫有:BeautifulSoup,urllib,chardet。
主要思想:封裝
手機短信發送發送
本來想用微信或者QQ發送來著,但是時隔兩年,qqbot、itchat、wxpy等第三方庫都失效了,沒辦法就來用手機短信發送好了。
1. Twilio
Twilio是一個做成開放插件的電話跟蹤服務(call-tracking service)
Twilio公司致力于幫助開發者在其應用里融入電話、短信等功能,該公司周二又推出了一項稱為Twilio Client的新服務,可幫助開發者整合靈活而低成本的網絡電話(VoIP)功能。
VoIP即Skype和谷歌電話等服務使用的技術,要提供VoIP服務通常需要準備相應的基礎設備,而Twilio Client免除了開發者的這一麻煩,可讓他們便捷地在應用里加入網絡電話元素。
安裝
安裝過程比較簡單,直接pip就好:
sudo pip3 install twilio
等待安裝完成
Successfully built twilio
Installing collected packages: PyJWT, twilio
Successfully installed PyJWT-1.7.1 twilio-6.38.1注冊并獲取三個重要參數
參考文章:https://zhuanlan.zhihu.com/p/67716042
簡單代碼實現發送短信實驗
代碼:
from twilio.rest import Client # 導包
account_sid = '你的account_sid'
auth_token = '你的auth_token'
client = Client(account_sid, auth_token)
message = client.messages.create(
from_='+×××××××××',
body='親愛的H,以后我每天都會給你發送一條信息哦!!!',
to='你要發送到的手機號(以+86開頭)'
)
print(message.sid)控制臺輸出:
/usr/bin/python3.7 /home/baldwin/PycharmProjects/IAmADog/qqsend/Send.py
SMfe64f40f2ac24b8ca82121d57147312c
Process finished with exit code 0手機接收短信:
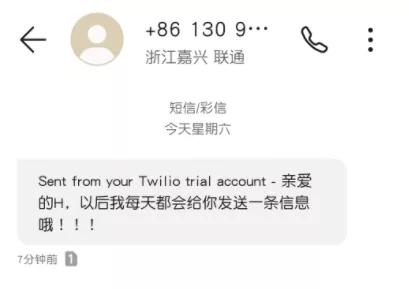
OK!到這里我們已經簡單實現了發送短信的功能,現在要去把這個功能封裝一下。
實現發送短信的功能
封裝代碼:
from twilio.rest import Client # 導包
def sendSMSMsg(content, tel):
"""
向某個手機號發送短信內容
:param content: 短信內容
:param tel: 手機號
"""
account_sid = '你的account_sid'
auth_token = '你的auth_token'
client = Client(account_sid, auth_token)
client.messages.create(
from_='+18634171608',
body=content,
to=tel
)
print('Send :', content, 'to tel:', tel, 'syccessfully!!!')
if __name__ == '__main__':
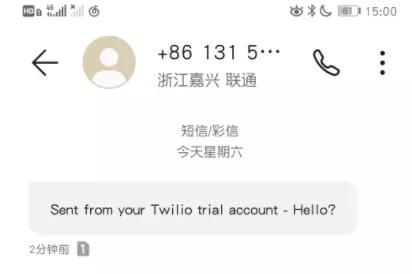
sendSMSMsg("Hello?" ,"+×××××××××")測試結果:
/usr/bin/python3.7 /home/baldwin/PycharmProjects/IAmADog/qqsend/Send.py
Send : Hello? to tel: +8618436354553 syccessfully!!!
Process finished with exit code 0手機接收短信:
發送短信總結
注冊twilio
獲取三個參數:account_sid,auth_token,TRIAL NUMBER
引入twilio
設置你要發送到的手機號和內容
操作還算是比較簡單的,這部分主要用到twilio庫。
定時發送短信
這一步算是我們的主程序了,在這一部分里,我們要使用之前的代碼先獲取情話list,再設置定時任務,每天固定的時間點把短信發到女神手機上。
Python定時任務
Python 中的定時任務框架還挺多的,我們現在的需求是每天早上8點鐘執行一個任務,在不到這個時間的時候不發送信息,為了簡便理解,我打算直接循環掃描系統當前時間,如果到了我們需要的那個時間點,就發送,不到的時候就一直掃描
代碼實現
import time
while True:
# 刷新
time_now = time.strftime("%H:%M:%S", time.localtime())
# 此處設置每天定時的時間
if time_now == "15:29:00":
# 需要執行的動作
print('定時任務執行一次')
time.sleep(2) # 因為以秒定時,所以暫停2秒,使之不會在1秒內執行多次結果:
/usr/bin/python3.7 /home/baldwin/PycharmProjects/IAmADog/DoWork.py
定時任務執行一次
Traceback (most recent call last):
File "/home/baldwin/PycharmProjects/IAmADog/DoWork.py", line 7, in <module>
time_now = time.strftime("%H:%M:%S", time.localtime())
KeyboardInterrupt
Process finished with exit code 1我是15:28:00的時候運行程序的,在設置時刻確實是執行了程序。
下面的異常是因為我手動退出了程序,這里不用管他。
具體實現發送情話
我們這里整理一下具體需求:
1.定時間點發送(上面已經實現了)
2.每次發送的時候從list中取出一個句子,下一次取出下一條,不能重復
3.list中的句子發送完畢之后要發短信通知我
取句子
思路:設置一個全局變量index,代表著下一條要發送的句子的下標,每次發送短信后,下標要增加1
發送完畢通知管理員
思路:每次進入任務但是發送短信之前都要比較index的值與list的長度(現在想起來,設計程序的時候用棧來儲存數據會更好),如果index已經越界,直接給管理員發短信通知。
實現
from spider import Spider
from send import Send
import time
TIME_TO_DO = '08:30:00' # 發送時間點
MSG_SUFFIX = '\n來自你的小可愛——Baldwin' # 短信后綴
SOURCE_URL = 'http://www.1juzi.com/new/150542.html' # 情話資源地址
SEND_TO_TEL = '+8618436354553' # 女神的手機號
SEND_TO_ME = '舔狗,給女神發的短信已經用光了,快來更新!!!'
MY_TEL = '+8618436354553' # 舔狗手機號
index = 0 # 下一條短信的下標
sentenceList = Spider.getSentenceList(SOURCE_URL) # 情話列表
while True:
# 刷新
time_now = time.strftime("%H:%M:%S", time.localtime())
# 此處設置每天定時的時間
if time_now == TIME_TO_DO:
# 需要執行的動作
# 判斷當前list有沒有用光
if index >= len(sentenceList):
# 用光了就短信通知我
Send.sendSMSMsg(SEND_TO_ME, MY_TEL)
# 跳出
break
# 給女神發短信
content = sentenceList[index] + MSG_SUFFIX
Send.sendSMSMsg(content, SEND_TO_TEL)
# 下標加一
index += 1
# 因為以秒定時,所以暫停2秒,使之不會在1秒內執行多次
time.sleep(2)debug模式下的各項測試:
短信發送測試
在idea debug模式下可以對time_now參數進行設置,把它設置成我們在前面要發送短信的那個時間點,成功進行了短信發送:
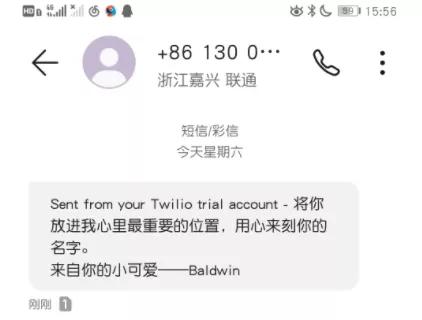
管理員通知測試
同樣的在debug模式下,設置index的值為len(sentenceList),程序進入通知管理員模塊中,這里不再演示。
封裝
from spider import Spider
from send import Send
import time
TIME_TO_DO = '08:30:00' # 發送時間點
MSG_SUFFIX = '\n來自你的小可愛——Baldwin' # 短信后綴
SOURCE_URL = 'http://www.1juzi.com/new/150542.html' # 情話資源地址
SEND_TO_TEL = '+8618436354553' # 女神的手機號
SEND_TO_ME = '舔狗,給女神發的短信已經用光了,快來更新!!!'
MY_TEL = '+8618436354553' # 舔狗手機號
def doSend():
index = 0 # 下一條短信的下標
sentenceList = Spider.getSentenceList(SOURCE_URL) # 情話列表
while True:
# 刷新
time_now = time.strftime("%H:%M:%S", time.localtime())
# 此處設置每天定時的時間
if time_now == TIME_TO_DO:
# 需要執行的動作
# 判斷當前list有沒有用光
if index >= len(sentenceList):
# 用光了就短信通知我
Send.sendSMSMsg(SEND_TO_ME, MY_TEL)
# 跳出
break
# 給女神發短信
content = sentenceList[index] + MSG_SUFFIX
Send.sendSMSMsg(content, SEND_TO_TEL)
# 下標加一
index += 1
# 因為以秒定時,所以暫停2秒,使之不會在1秒內執行多次
time.sleep(2)
# 主程序入口
if __name__ == '__main__':
doSend()小總結
這部分主要用到的模塊:time,然后記得要把前兩個我們自己做的模塊導入進來。
總結
這個程序相對來說還算是比較容易的,只要跟著文章一步步來基本上不互出問題。
最后只要運行我們最后一個模塊中主程序入口就好了,你也可以按照自己需求修改配置達到不同的效果。
我現在就去告訴女神去。
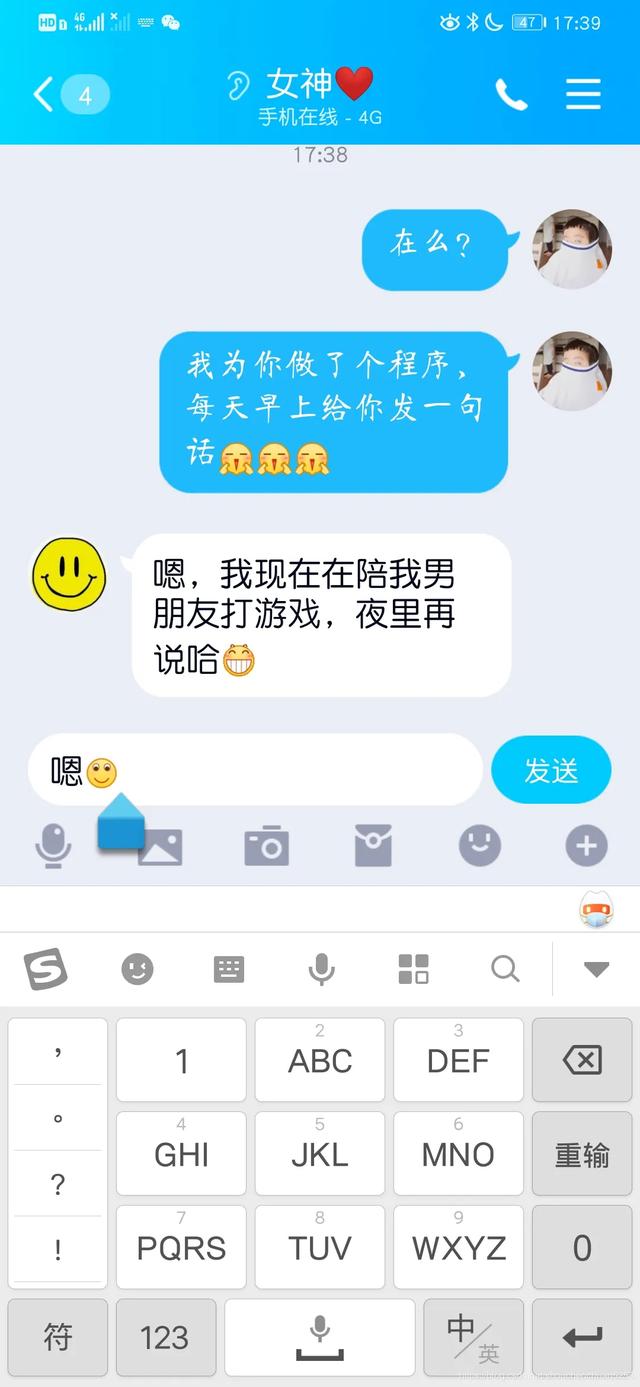
嘿嘿!女神秒回的,開心!
以上就是如何給用Python每天定時給女神發一句情話,小編相信有部分知識點可能是我們日常工作會見到或用到的。希望你能通過這篇文章學到更多知識。更多詳情敬請關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





