溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這期內容當中小編將會給大家帶來有關PostgreSQL中怎么實時干預搜索排序,文章內容豐富且以專業的角度為大家分析和敘述,閱讀完這篇文章希望大家可以有所收獲。
PostgreSQL是一個歷史悠久的數據庫,最早由加州大學伯克利分校的Michael Stonebraker教授領導設計,具備與Oracle類似的功能、性能、架構以及穩定性。
阿里云HybridDB for PostgreSQL,提供大規模并行處理(MPP)數據倉庫服務, 支持多核并行計算、向量計算、圖計算、JSON,JSONB全文檢索。
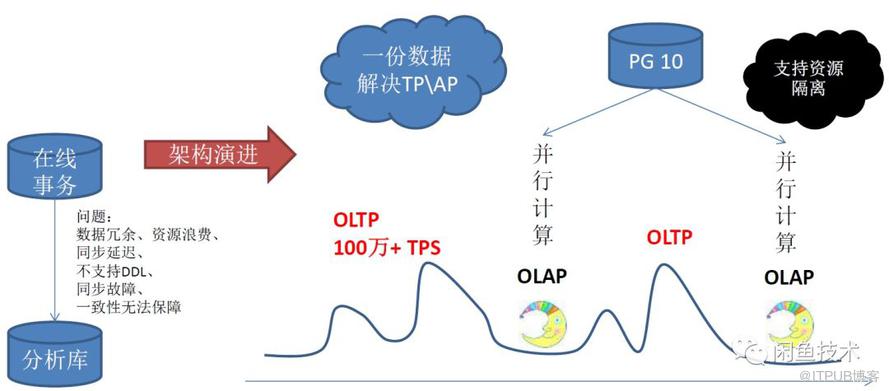
PostgreSQL高效的并行處理能力,基于JSON格式數據合并能力以及Notify實時消息能力,給我們提供了具體實現思路。因此基于上文提到業務挑戰,我們梳理了相關實現方案。
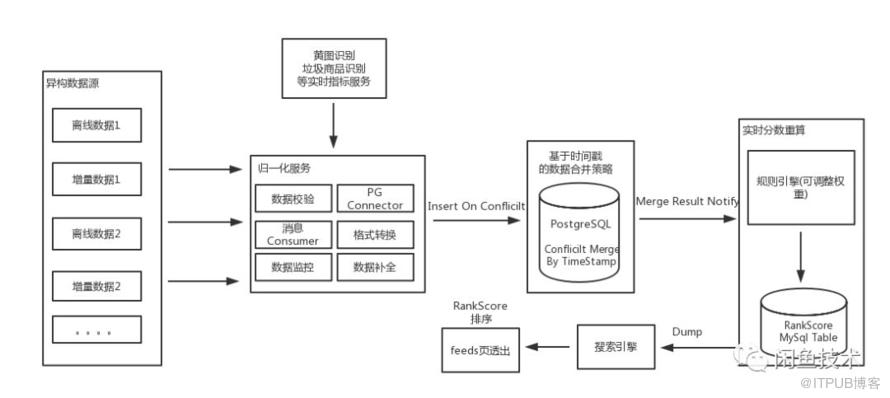
仔細分析整體方案,歸納起來涉及的方面有:
異構數據源接入
歸一化服務
數據合并策略
實時分數重算
閑魚商品相關的數據非常豐富,有各種異構數據源,如全量的離線商品數據,實時商品變更數據,各種算法維度數據等,在實現上可通過阿里云大數據平臺,binlog監聽工具等進行統一處理。
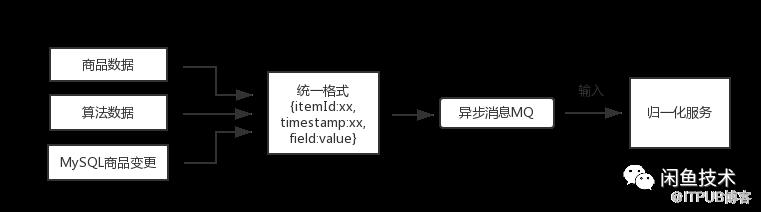
如上圖所示,所有異構數據源都按照統一格式,通過異步消息,輸入到歸一化服務,該方案的優點是不管全量數據還是增量數據都統一走消息服務,簡化接入流程,同時通過消息中間層進行解耦,提高穩定性。
歸一化服務接收上游異構數據源消息,通過數據校驗模塊、數據補全模塊、標準格式轉換模塊、數據監控模塊為下游輸送正確的數據。
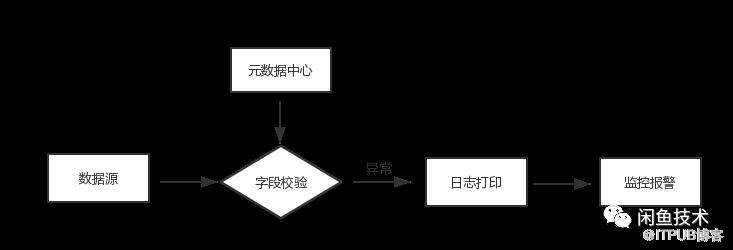
數據校驗模 如下圖所示,數據源結合元數據中心進行字段級別的校驗,如字段名稱,數據類型,數據范圍、默認值等,引入元數據中心最大優勢是可以細粒度的控制數據源,防止臟數據、不需要的數據污染下游。
數據補全模塊 數據源通常需要實時補全一些數據干預指標,如用戶編輯商品,需實時分析打標是否有黃圖,商品價格預測等,整個干預流程要以pipeline的形式,暴露擴展點,允許插入干預能力。
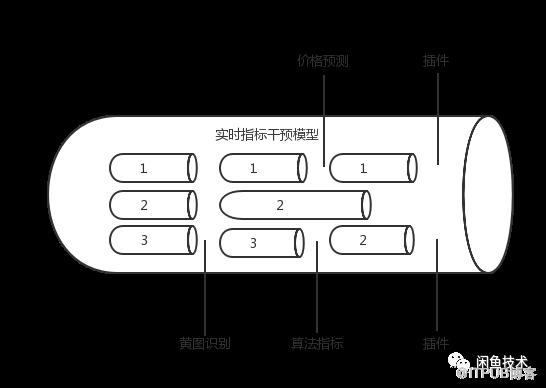
標準格式轉換模塊 標準格式轉換模塊將數據源統一按標準的格式轉換成JSON結構,便于下游統一數據合并。
數據監控模塊 數據監控模塊記錄數據源的每一條數據以及異常數據記錄,并將數據投遞到監控系統,監控每個異構數據源異常數據,流量異常情況,第一時間發現并恢復問題。
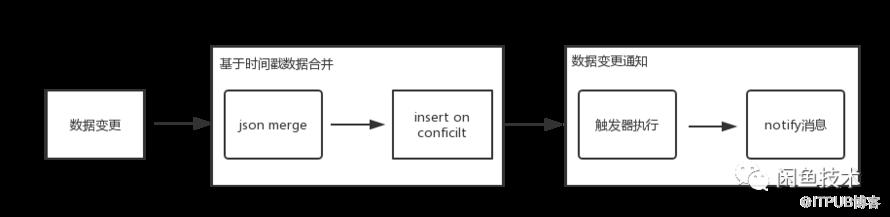
數據合并策略主要包括基于時間戳的數據合開和數據變更通知兩個先后處理流程,在數據合并流程會遇到一個核心問題,即如何快速有效的解決每個字段的沖突合并,基于時間戳統一merge。這里首先會涉及到數據存儲結構,參考如下表設計結構:
create table Test (id int8 primary key, -- 商品IDatt jsonb -- 商品屬性);
屬性設計為JSON,JSON里面是K-V的屬性對,如下屬性結構示例,V里面是數組,包含K的值以及這對屬性的最后更新時間,更新時間用于merge update,當屬性發生變化時才更新,沒有發生變化時,不更新。這種設計優點:
字段級別細粒度merge,保證最小集數據實時性
高擴展性,表不需要增減字段
屬性結構示例
{"count": [100, "2017-01-01 10:10:00"], "price": [8880, "2018-01-04 10:10:12"], "newatt": [120, "2017-01-01 12:22:00"]}定義完存儲結構, 接下來利用PostgreSQL的JSON處理能力進行數據merge,參考如下merge udf 偽代碼:
create or replace function merge_json(jsonb, jsonb) returns jsonb as $$ select jsonb_object_agg(key,value) from ( select coalesce(a.key, b.key) as key, case when coalesce(jsonb_array_element(a.value,1)::text::timestamp, '1970-01-01'::timestamp) > coalesce(jsonb_array_element(b.value,1)::text::timestamp, '1970-01-01'::timestamp) then a.value else b.value end from jsonb_each($1) a full outer join jsonb_each($2) b using (key) ) t; $$ language sql strict ;
定義完merge方法后,我們在數據源有數據變更時直接調用。
insert into a values
(1, '{"price":[1000, "2019-01-01 10:10:12"], "newatt": ["hello", "2018-01-01"]}')
on conflict (id)
do update set
att = merge_json(a.att, excluded.att)
where
a.att <> merge_json(a.att, excluded.att);從上面可以看出當商品ID出現沖突時,會調用merge_json 進行數據合并,至此數據合并流程完成,接下來需要將合并結果實時通知下游,可以利用PostgreSQL的觸發品和Notify機制來處理。
觸發器設計
//觸發器要執行的udf
CREATE OR REPLACE FUNCTION notify1() returns trigger AS $function$
declare
begin
perform pg_notify(
'a', -- 異步消息通道名字
format('CLASS:notify, ID:%s, ATT:%s', NEW.id, NEW.att) -- 消息內容
);
return null;
end
$function$ language plpgsql strict;
//創建觸發器
create trigger tg1 after insert or update on Test for each row execute procedure notify1();可以看出當數據插入或更新會觸發trigger 執行nofity1 函數創建異步nofity消息,并向指定的通道發送通知,下游應用可通過jdbc監聽相應的通道,接收消息,進行后續實時打分流程,參考如下偽代碼:
this.pgconn = conn.unwrap(org.postgresql.PGConnection.class);
Statement stmt = conn.createStatement();
stmt.execute("LISTEN a");
stmt.close();
org.postgresql.PGNotification notifications[] = pgconn.getNotifications();
if (notifications != null) {
for (int i=0; i < notifications.length; i++) {
System.out.println("Got notification: " + notifications[i].getName());
}
}另外PostgreSQL并發處理性能非常高效,綁定觸發器后會增加PostgreSQL的數據寫入時長,但是壓測結果來看,依然能夠滿足我們的業務寫入性能要求,
以1000萬數據測試結果為例:

數據實時打分干預搜索
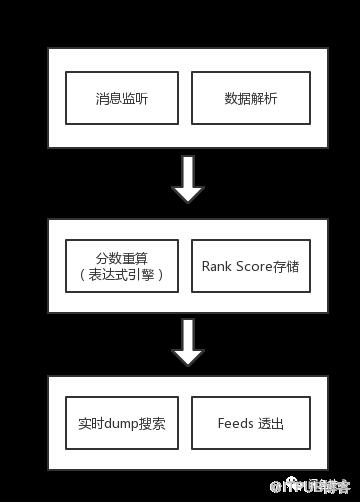
服務層在監聽到Notify消息,解析消息數據,通過規則引擎對各指標權重進行分數重算,計算綜合分數,打到搜索tag表,搜索引擎實時監測tag表,將綜合分數dump到搜索引擎,實時干擾排序結果。
上述就是小編為大家分享的PostgreSQL中怎么實時干預搜索排序了,如果剛好有類似的疑惑,不妨參照上述分析進行理解。如果想知道更多相關知識,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





