溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
市場占有率
ASM自動存儲管理技術已經面世10多個年頭,目前已經廣泛使用于各個領域的數據庫存儲解決方案。 到2014年為止,ASM在RAC上的采用率接近60%,在單機環境中也超過了25%。
RAC集群環境中3種存儲解決方案: ASM、集群文件系統和裸設備; 雖然仍有部分用戶堅持使用古老的裸設備,但隨著版本的升級,更多用戶開始采用ASM這種ORACLE提供的免費解決方案。
在國內使用ASM的場景一般均采用 External Redundancy(11gR2除了存放ocr/votedisk 的DG外)。 一般在10.2.0.5和11.2.0.2之后的版本上ASM,還是較為穩定的。
下圖為部分在產品環境中使用ASM的國外知名企業:

ASM FILE
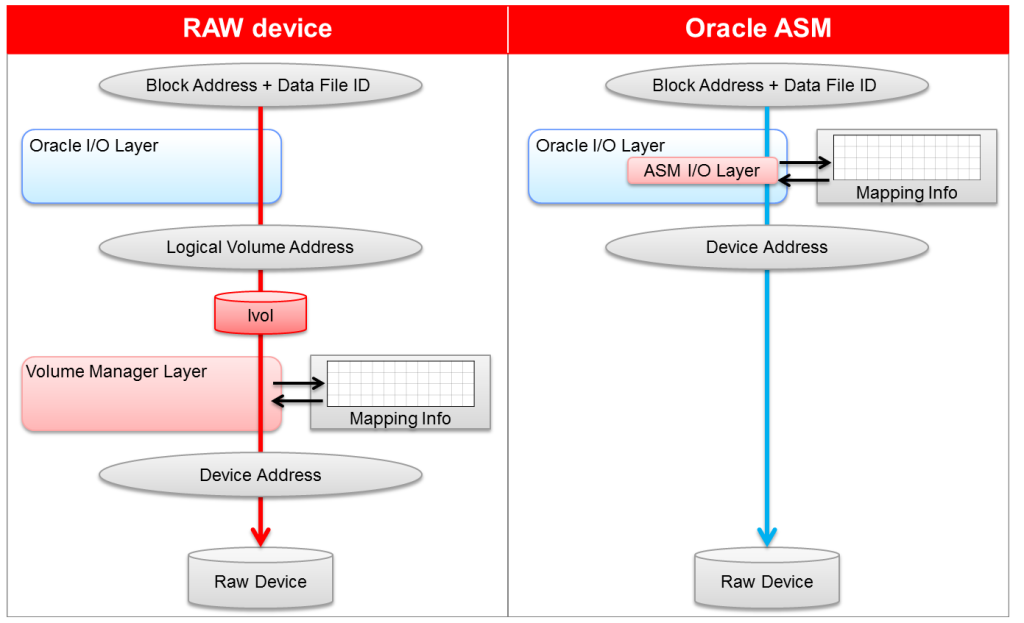
ORACLE RDBMS Kernel內核與ASM在高層交互是基于ASM中存放的文件即ASM FILE。 這和ORACLE RDBMS去使用文件系統或其他邏輯卷的方式沒有什么區別。 ASM中可以存放 數據文件,日志文件,控制文件,歸檔日志等等,對于數據庫文件的存放基本和文件系統沒啥2樣。
一個ASM FILE的名字一般以一個”+”和DiskGroup名字開頭。 當ORACLE RDBMS KERNEL內核的文件I/O層碰到一個以”+”開頭的文件時,就會走到相關ASM的代碼層中 而不是調用依賴于操作系統的文件系統I/O。 僅僅在File I/O層面才會認識到這是一個ASM 中的文件,而其上層的內核代碼看來ASM FILE和OS FILE都是一樣的。
ASM對ROWID和SEGMENT等RDBMS元素沒有影響,不過是數據文件存放在ASM中,ASM并不會打破ORACLE數據庫中的這些經典元素。
在一個ASM Diskgroup中僅僅允許存放已知的ORACLE文件類型。假設一個文件通過FTP拷貝到ASM Diskgroup中,則該文件的第一個塊將被檢驗以便確認其類型,以及收集其他信息來構建這個文件的完整ASM文件名。 如果其文件頭無法被識別,則該文件在DiskGroup中的創建將會報錯。
僅有以下的文件類型可以存放在ASM Diskgroup中:
ORACLE 的2進制可執行文件和ASCII文件,例如alert.log和其他trace文件,則不推薦也不能存放在ASM Diskgroup里。
File Blocks
所有被ASM所支持的文件類型仍以其file block作為讀和寫的基本單位。在ASM中的文件仍保持其原有的 Block Size 例如 Datafile 仍是 2k~32k(默認8k),ASM并不能影響這些東西。
值得一提的是在ASM FILE NUmber 1 的FILEDIR中記錄了每一種FILE TYPE對應的BLOCK SIZE,例如:
kfbh.endian: 1 ; 0x000: 0x01
kfbh.hard: 130 ; 0x001: 0x82
kfbh.type: 4 ; 0x002: KFBTYP_FILEDIR
kfbh.datfmt: 1 ; 0x003: 0x01
kfbh.block.blk: 256 ; 0x004: blk=256
kfbh.block.obj: 1 ; 0x008: file=1
kfbh.check: 567282485 ; 0x00c: 0x21d00b35
kfbh.fcn.base: 220023 ; 0x010: 0x00035b77
kfbh.fcn.wrap: 0 ; 0x014: 0x00000000
kfbh.spare1: 0 ; 0x018: 0x00000000
kfbh.spare2: 0 ; 0x01c: 0x00000000
kfffdb.node.incarn: 838529807 ; 0x000: A=1 NUMM=0x18fd7987
kfffdb.node.frlist.number: 4294967295 ; 0x004: 0xffffffff
kfffdb.node.frlist.incarn: 0 ; 0x008: A=0 NUMM=0x0
kfffdb.hibytes: 20 ; 0x00c: 0x00000014
kfffdb.lobytes: 8192 ; 0x010: 0x00002000
kfffdb.xtntcnt: 35488 ; 0x014: 0x00008aa0
kfffdb.xtnteof: 35488 ; 0x018: 0x00008aa0 kfffdb.blkSize: 8192 ; 0x01c: 0x00002000 kfffdb.flags: 17 ; 0x020: O=1 S=0 S=0 D=0 C=1 I=0 R=0 A=0
kfffdb.fileType: 2 ; 0x021: 0x02
kfffdb.dXrs: 17 ; 0x022: SCHE=0x1 NUMB=0x1
kfffdb.iXrs: 17 ; 0x023: SCHE=0x1 NUMB=0x1
kfffdb.dXsiz[0]: 20000 ; 0x024: 0x00004e20
這里的kfffdb.blkSize即是 一個數據文件的Block Size。
由于這個blocksize 總是2的次方,所以一個block總是在 一個AU allocation Unit中,而不會跨2個AU。
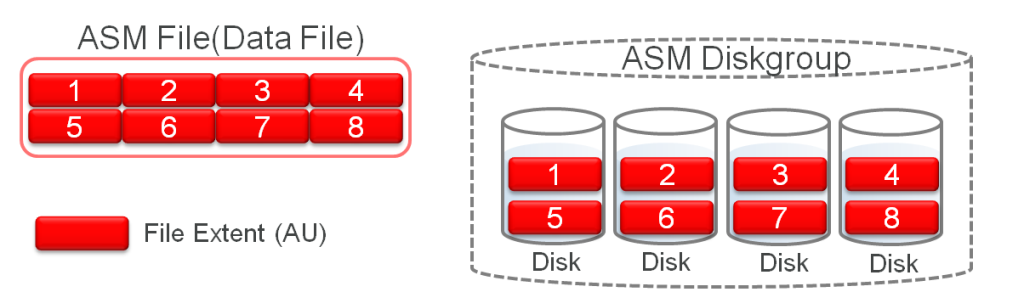
Data Extents
數據盤區Data Extents 是裸的存儲,用以存放文件內容。每一個Data Extent在 11g之前對應某一個ASM disk上的一個Allocation Unit , 在11g之后 一個Extent可以對應多個AU,具體見《【Oracle ASM】Variable Extent Size 原理》。

Extent Map
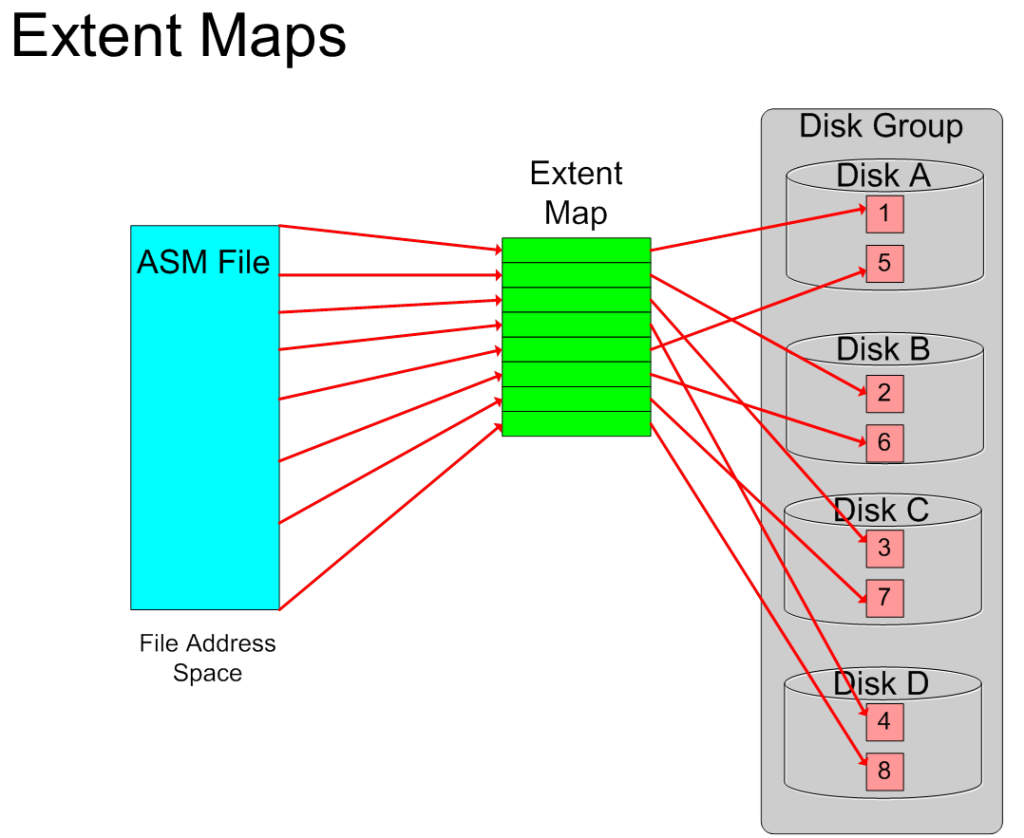
Extent Map盤區圖是盤區指針的列表,這些指針將支出所有屬于一個文件的數據盤區。這些盤區是真正存放數據的裸存儲空間。每一個盤區指針給出其所在的磁盤號和AU信息。為了保證可信,每一個盤區指針也會包含一個checksum byte來確認本指針未損壞。當這個checksum值和實際存放的Extent信息不匹配時可能出現ORA-600錯誤,例如ORA-00600: internal error code, arguments: [kffFdLoadXmap_86], [256], [0], [1], [68], [54], [29], [], [], [], [], []。
Virtual Data Extents
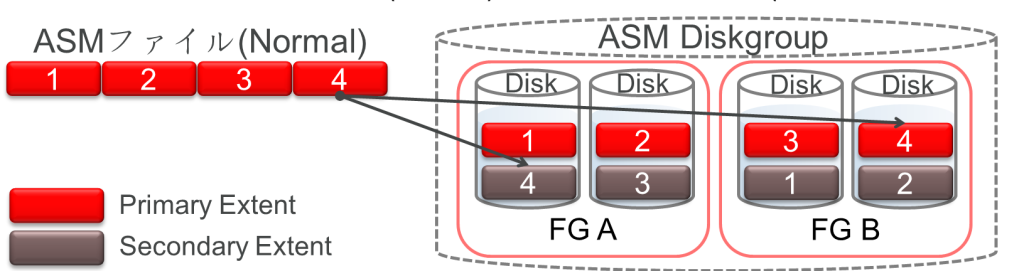
虛擬數據盤區 Virtual Data Extent是幾個data extent的集合,這些data Extent中包含了相同的數據。 鏡像Mirror是在虛擬Extent級別實現的。每一個虛擬extent為文件塊提供一個盤區地址空間。每一個寫入到文件塊均是寫入到一個虛擬extent中每一個Online在線的data extent中。 每一個對文件塊的讀取也是被重定位到一個虛擬extent中的主鏡像extent (primary Extent),除非primary extent所在Disk被OFFLINE了。 對于沒有冗余度(即external redundancy disk group上的FILE)的文件而言,一個虛擬Extent實際就是一個data Extent。
對于Normal redundancy+普通數據庫文件而言, 一個虛擬Extent實際就是2個Data Extent。
對于High redundancy+普通數據庫文件而言, 一個虛擬Extent實際就是3個Data Extent。
粗粒度條帶化Coarse Grain Striping
粗粒度條帶化就是對虛擬data Extent的簡單聯接。類似于傳統卷管理器使用1MB作為stripe size。
細粒度條帶化Fine Grain Striping
細粒度與粗粒度的區別在于,文件塊不是線性地布局在每一個虛擬Extent上,而是文件將以1/8個虛擬Extent成長,由此文件塊被在diskgroup內以1/8的條帶化深度分布。 由此當該文件的block size 為8k,則block 0~15在虛擬Virtual Extent 0上面,而block 16-31 在Vritual Extent 1上面,blocks 112-127在vritual extent 7, block 128-143在block 0-15之后仍在virtual extent 0上。

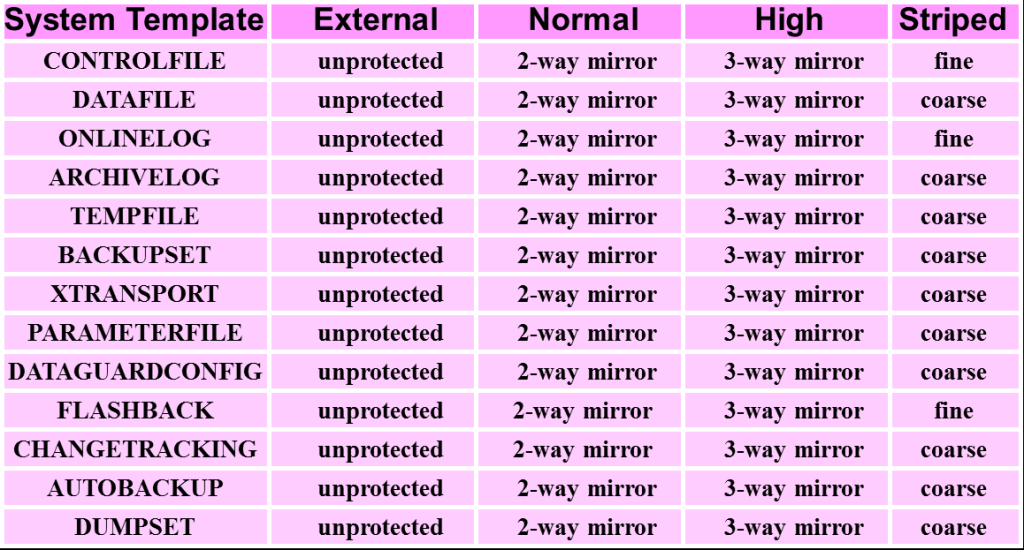
File Templates
File Template文件模板當文件被創建時用以指定 條帶化 (coarse 或 FINE) 和冗余度(external, normal, high)。 ORACLE默認已經為每一個ORACLE數據庫文件提供了默認模板。可以修改默認模板 也可以客制化模板。修改模板只影響新創建的文件,而不是現有文件。 創建文件時可以指定使用某一個模板。
默認的模板如下:
Failure Group
ASM提供冗余,failure group用來保證單點錯誤不會造成同一數據的多份拷貝同時不可用。 如果ASM使用的多個ASM DISK LUN屬于同一硬件 例如同一磁盤陣列,該硬件故障會導致這多個盤均不可用,則該硬件的失敗應當被容錯, 在ASM中一般將這些盤規劃到同一個failure group中。多份冗余拷貝不會存放在同一個failure group的磁盤中,換句話說一個failure group中只有一份數據的拷貝,不會有第二份。
由于Failure Group的配置很大程度上與用戶的本地規劃有關,所以ASM允許用戶自己指定Failure group的規劃、組成。 但是如果用戶自己沒有指定Failure Group的規劃,那么ASM會自動分配磁盤到必要的Failure Group。
使用External Redundancy的Diskgroup沒有Failure Group。Normal redundancy Disk Groups要求至少2個Failure Group,High Redundancy Disk Groups要求3個Failure Group。
如果Normal redundancy Disk Groups中有多于2個的Failure Group,例如 Failure Group A、B、C,則一個Virtual Extent會自動在A、B、C之間找2個Failure Group存放2個mirror extent,不會存放3份拷貝。
High Redundancy Disk Groups與之類似。
實際上,國內對ASM的運行,絕大多數不依賴于ASM實現redundancy,而是使用 External Redundancy的, 在Maclean遇到的場景中External Redundancy占了70%以上。
實際應用中 Normal/High一般會和多個存儲控制器Controller 結合來分配failure group,或者存在多路存儲可用。
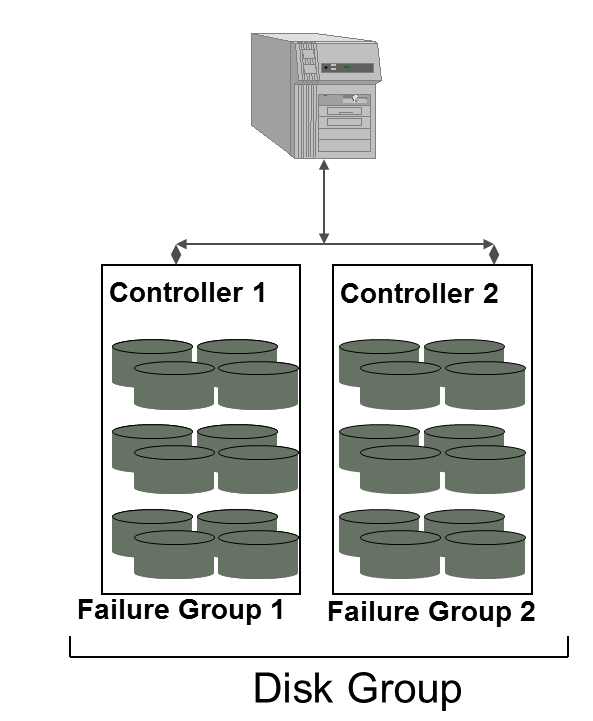
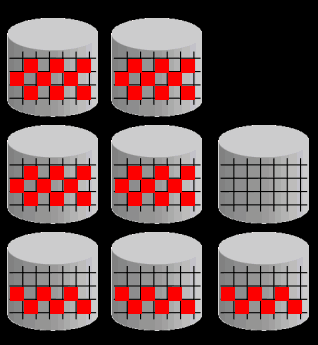
以下為一個示例, 一個normal redundancy 的Diskgroup 中存在8個Disk,并使用2個Failure Group:
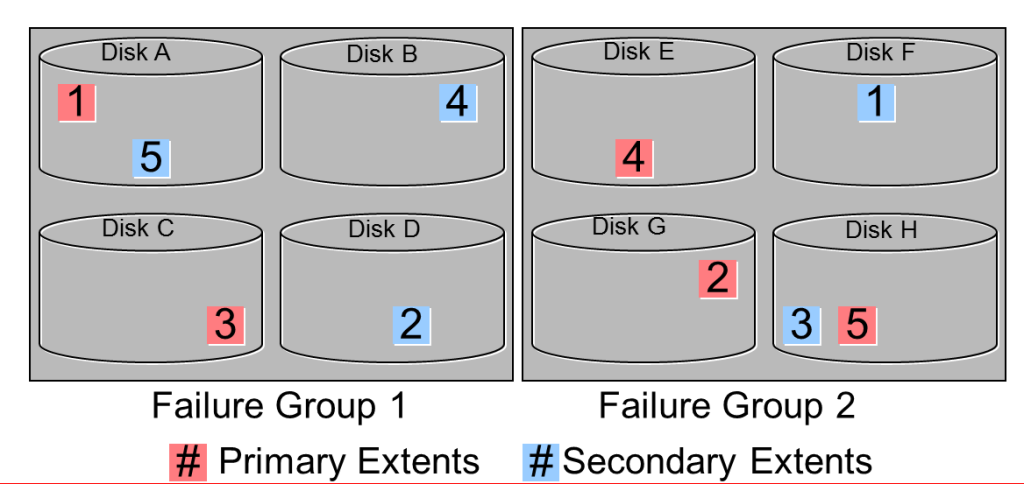
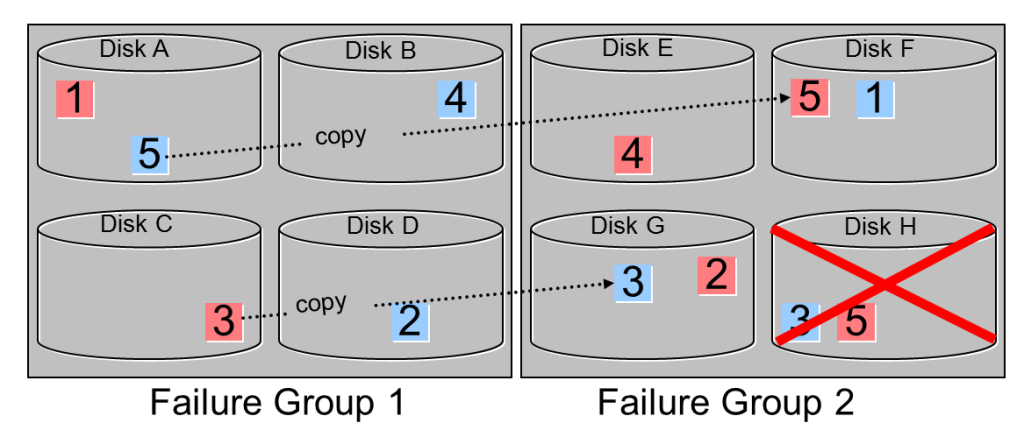
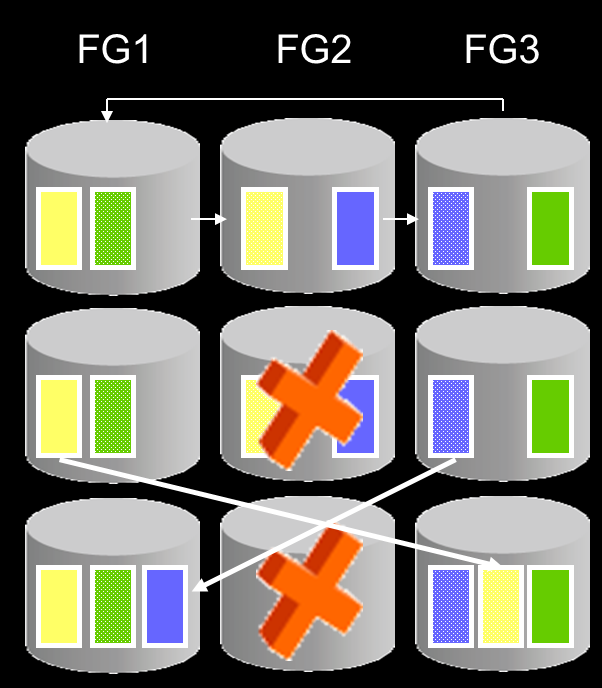
當磁盤Disk H失敗,這個失敗要求在失敗磁盤上所有的Extent均被修復, Extent 3和5會從現存的拷貝中復制到Failgroup 2 中可用的區域。在此例子中,Extent 5被從Disk A拷貝到Disk F,extent 3從Disk C 拷貝到Disk G,最后還會將失敗的磁盤從Diskgroup中drop出去。
Disk Partners
Disk Partnership是一種基于2個磁盤之間的對稱關系,存在于high 或 normal的redundancy diskgroup中。Diskgroup中的Disk與同一個Diskgroup內的其他幾個disk組成結伴關系。ASM會自動創建和維護這種關系。鏡像拷貝數據僅僅在已經與主數據鏡像primary data extent組成partners關系的磁盤上分配。
Disk partnering用來減少由于同時2個磁盤故障導致的數據丟失的概率。原因在于當ASM配置中使用了較多的磁盤時(例如上千個),如果如果數據鏡像是隨機尋找次級磁盤來存放鏡像拷貝,當2個磁盤丟失時有較大概率丟失數據。原因是如果采取隨機存放鏡像數據的話,出現數據的 primary和鏡像數據同時存在于2個正好失敗的磁盤上的概率是很高的。 如果我們不采取disk partnering,2個磁盤失敗所造成的數據丟失的概率大大增加。
Disk partnering策略限制了用來保護某個磁盤數據拷貝的磁盤數目。ASM為一個磁盤限制了disk partners的總數為8。 這個數目越小,則雙磁盤同時失敗造成數據丟失概率越小。 但是這個數目越小,也會造成其他不便。所以ORACLE ASM研發團隊最終選擇了8這個數字。
ASM從本disk所在Failure group之外的FG 中挑選partners disk,由于一個ASM DISK有多個partners,所以其多個partners disk可能有的在同一個failure Group中。Partners被盡可能多的選擇在不同的Failure Group中,這樣做的目的也很明確,提高磁盤失敗時的容錯能力。askmaclean.com
如果一個ASM DISK失敗了,其保護的extents可以通過其partners來重建。由于有多個partners所以其額外的I/O負載是在多個ASM disk中均衡損耗的。 這減少了修復故障的失敗時間,因為更多的磁盤參與進來,可以獲得更高的I/O吞吐量,所以加快了重構丟失數據鏡像的速度。Partners被盡可能多的選擇在不同的Failure Group中,這樣做可以讓重建丟失磁盤的負載均勻分布在盡可能多的硬盤資源上。 以上這些考慮均是基于同時不會有2個failgroup同時失敗這個前提假設。
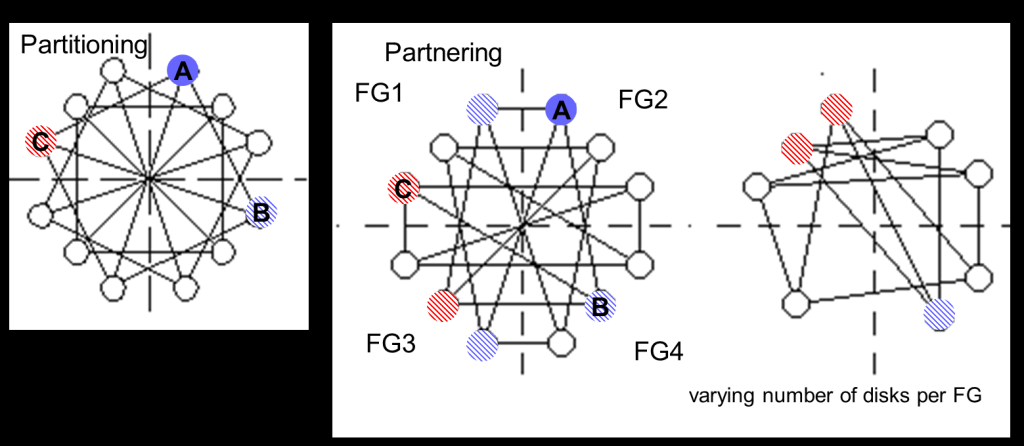
注意Partnering不是分區partitioning,Partnering僅僅是一種對稱關系。如果Disk A將Disk B列出partner,則相對地Disk B也將Disk A列為partner。 但是partnering不是一種臨時的關系。 同時假設disk A 和 Disk B是partners, 而Disk B和Disk C也是partners, 但這并不代表A和C是partners。
實際如果對partnering relationship有足夠的傳遞性則可能表現為分區,如下圖中的例子。但是分區僅僅是partnering可以提供的一種可能性。
partitioning分區僅僅是Partnering的特殊表現,Partnering本身已經能夠保證在Disk磁盤以不規則的幾何安排方式組織時仍能同一負載均衡,其移除了當額外的容量需要增加到現有系統時的許多限制。當然這仍不能保證在所有配置下都很完美,但ASM會基于現有給定的配置采取最佳的方案。
下面為一個Partning的例子:
ASM mirror 保護
ASM mirror 鏡像保護可避免因丟失個別磁盤而丟失數據。每一個文件均有自己的ASM鏡像策略屬性, 對于該文件所轄的所有virtual extent來說同樣基于該鏡像策略。文件創建時會設置這個鏡像策略屬性,今后都無法修改。 ASM鏡像要比操作系統鏡像磁盤要來的靈活一些,至少它可以在文件級別指定需要的冗余度。
ASM mirror區分鏡像extent的primary和secondary拷貝,但在更新extent時會同時寫所有的拷貝鏡像。 ASM總是先嘗試讀取primary 拷貝,僅當primary拷貝不可用時去讀取secondary拷貝。
ASM metadata
Asm Metadata是存在于ASM disk header用以存放ASM Diskgroup 控制信息的數據,Metadata包括了該磁盤組中有哪些磁盤,多少可用的空間,其中存放的File的名字,一個文件有哪些Extent等等信息。
由于Asm metadata就存放在ASM DISK HEADER,所以ASM disk group是自解釋的。所有的metadata元數據均存放在一個個metadata block中(默認block size 4096)。這些信息包括該metadata block的類型以及其邏輯位置。同樣有checksum信息來確認block是否被損壞。所有的metadata block均是4k大小。實際使用時ASM實例會緩存這些ASm metadata。askmaclean.com
ASM Instance
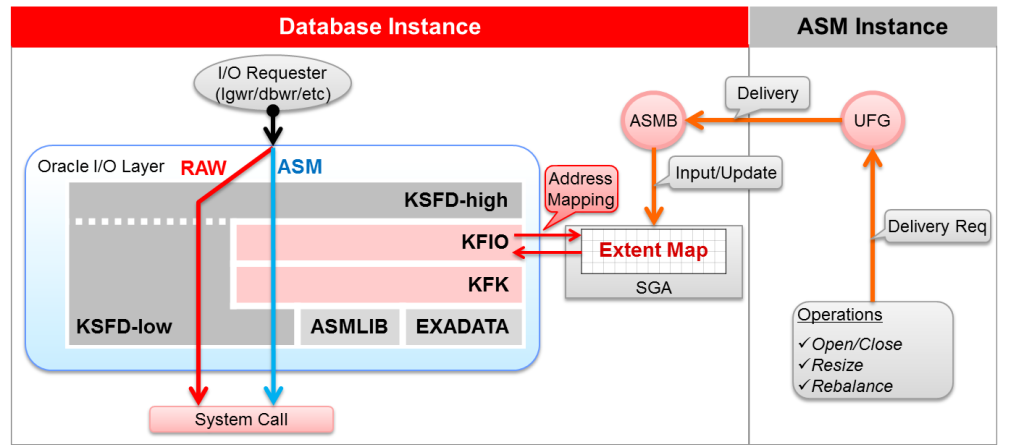
ASM instance的主要任務之一就是管理ASM metadata元數據; ASM Instance類似于ORACLE RDBMS INSTANCE 有其SGA和大多數主要后臺進程。在10.2中使用與RDBMS一樣的2進制軟件,到11.2中分家。但ASM instance加載的不是數據庫,而是Disk Group; 并負責告訴RDBMS database instance必要的ASM 文件信息。 ASM實例和DB實例均需要訪問ASM DISK。 ASM實例管理metadata元數據,這些元數據信息足以描述ASM 中的FILE的信息。 數據庫實例仍舊直接訪問文件,雖然它需要通過ASM實例來獲得例如 文件Extent Map 盤區圖等信息,但I/O仍由其自行完成,而不是說使用了ASM之后DB的文件I/O需要通過ASM來實現; 其僅僅是與ASM instance交互來獲得文件位置、狀態等信息。
有一些操作需要ASM實例介入處理,例如DB實例需要創建一個數據文件,則數據庫服務進程直接連接到ASM實例來實現一些操作; 每一個數據庫維護一個連接池到其ASM實例,來避免文件操作導致的反復連接。
ASM metadata通過一個獨立的ASM實例來管理以便減少其被損壞的可能。ASM instance很相似于db instance,雖然它一般只使用ORACLE KERNEL內核的一小部分代碼,則其遇到bug或導致buffer cache訛誤或者寫出訛誤到磁盤的概率由此比DB實例要小。 數據庫實例自己從來不更新ASM metadata。ASM metadata中每一個指針一般都有check byte以便驗證。
和DB RAC一樣,ASM instance 自己可以被集群化,一樣是使用ORACLE Distributed Lock Manager(DLM)分布式鎖管理器架構。在一個集群中每一個節點上可以有一個ASM instance。如果一個節點上有多個數據庫、多個實例,則他們共享使用一個ASM instance 。
如果一個節點上的ASM instance失敗了,則所有使用該ASM instance 均會失敗。但其他節點上的ASM和數據庫實例將做recover并繼續操作。
Disk Discovery
Disk Discovery磁盤發現是指從OS層面找到那些ASM值得訪問的磁盤。也用來找到那些需要被mount的diskgroup名下的磁盤ASM DISK,以及管理員希望將其加入到diskgroup中的Disk,或管理員會考慮將其加入到diskgroup的Disk。Discovery 使用一個discovery string( asm_diskstring)作為輸入參數,并返回一系列可能的DISK。注意一個是要指定asm_diskstring,另一個是要求這些disk的權限可以被oracle/grid用戶使用。精確的asm_diskstring discovery語法取決于操作系統平臺和ASMLIB庫。OS可接受的路徑名生成的匹配,一般對于discovery strings也是可用的。一般推薦這個路徑名下最好只有ASM Disk,來避免管理上的問題。
ASM實例會打開和讀取由asm_diskstring指定的路徑名匹配到的每一個文件并讀取前4k的block, 這樣做的目的是判斷disk header的狀態;如果它發現這是一個ASM disk header則會認為這是一個可以mount的diskgroup的一部分。如果發現這4k的block其無法識別,則認為該disk可以加入到ASM diskgroup中(candidate)。
ASM實例需要通過一個初始化參數來指定這個discovery strings,實際就是asm_diskstring; 注意 asm_diskstring中可以加入多個路徑字符串,例如 ‘/dev/raw*’,’/dev/asm-disk*’ ; 同樣的磁盤不會被發現2次(除非你欺騙ASM)。 在RAC cluster中如果一個磁盤不是在整個cluster范圍內都可見,那么這個磁盤無法被加入到RAC的ASM DISKGROUP 中。 在實際使用中每一個節點上的磁盤名字可以不一樣,但其實際介質要被操作系統識別,但是實際MACLEAN也強烈建議你保持每個節點上磁盤的名字一樣,否則管理很麻煩。 所以這里引入UDEV等規則是有必要的。
Disk Group Mount 加載磁盤組
在數據庫實例可以用Diskgroup上的文件之前,需要ASM實例去 mount 這個本地diskgroup。 Mount Diskgroup牽扯到發現所有的磁盤并找到上面已經有metadata數據的disk,并嘗試將對應到一個diskgroup的DISK mount起來。 能 mount起來的前提還需要驗證metadata來確保現在已經有足夠數量的磁盤在哪里,例如使用3個DISK創建的external diskgroup ,當前OS下面只掛了2個Disk,則顯然不能mount這個diskgroup。 之后還需要初始化SGA以便之后更新和管理這些metadata。
可以顯示地去dismount一個diskgroup,但是如果diskgroup上的文件正在被client (例如DB)使用則dismount會報錯。如果在ASM冗余算法容錯能力內丟失磁盤,則不會導致diskgroup被強制dismount。但是如果超出了容錯能力則會被強制dismount。 這種強制dismount會導致使用其上文件的DB instance被kill。
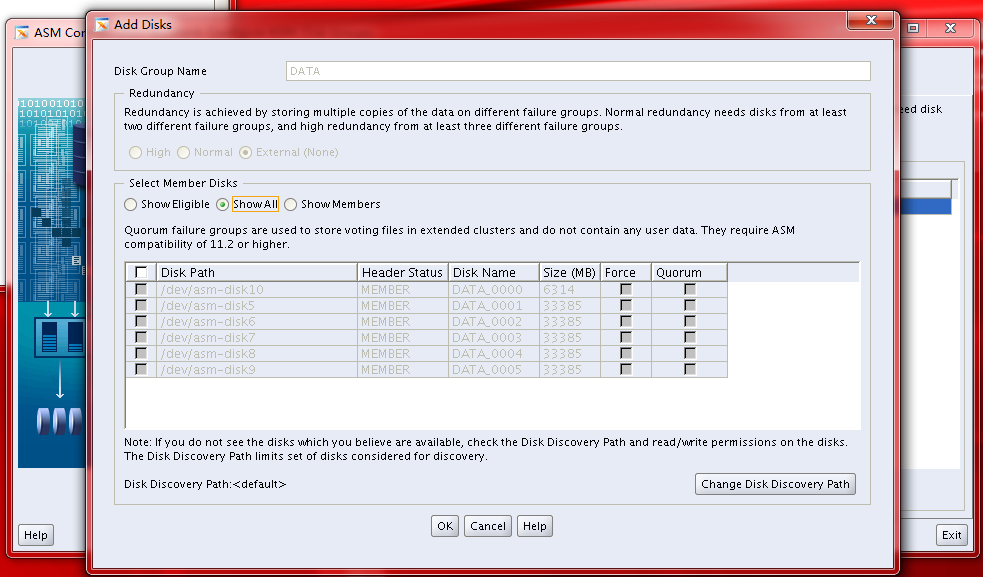
Disk ADD 增加磁盤
加入一個磁盤到現有的Diskgroup 來擴空間和增加吞吐量是很常見的需求。最簡單的加入磁盤命令如 : alter diskgroup Data add disk ‘/dev/asm-disk5’; 如前文所述在RAC cluster中如果一個磁盤不是在整個cluster范圍內都可見,那么這個磁盤無法被加入到RAC的ASM DISKGROUP 中。
如果add disk指定的磁盤的disk header發現了其他diskgroup的信息或者操作系統的一些信息,則需要alter diskgroup Data add disk ‘/dev/asm-disk5’ force ; 加入FORCE選項。實際使用中盡可能避免使用FORCE選項。
需要注意的事add disk命令返回后只代表disk header已經完成必要的metadata寫入,但不代表該磁盤已經完成了rebalance操作。后續的rebalance會被引發并移動數據到新加入的磁盤中。一般推薦如果你要加入多個ASM DISK,那么在同一時間加入,而不是分多次加入。 但是一般不推薦同時做add disk和drop disk。
Disk Drop踢盤
可以從現有的Diskgroup里drop出disk,這些disk可以用作它途;當然由于asm disk失敗,導致ASM實例自動drop 該失敗的asm disk也是常見的。若一個ASM DISK常發生一些非致命的錯誤,則一般推薦將該Disk drop出來,以避免如果某天發生真的磁盤失敗導致可能的數據丟失。 但是需要注意drop disk時 不要指定其路徑名,而是指定ASM DISK NAME。
drop disk命令可能較短時間內返回,但是diskgroup必須完成rebalance后這個磁盤才能被挪作他用。rebalance將讀取即將被drop掉disk的數據,并拷貝這些數據到其他磁盤上。FORCE選項可以用于避免讀取該正被drop的磁盤。該FORCE選項當磁盤發生失敗或磁盤確實需要立即被挪用。原來那些需要被拷貝的extent,使用FORCE選項后會從冗余的備份中讀取,所以external redundancy不支持使用FORCE選項。當然如果使用FORCE選項最后會導致在NORMAL/HIGH冗余的Diskgroup下造成數據丟失的話,則FORCE選項也將不可用。
DROP DISK NOFORCE:

DROP DISK FORCE:
對磁盤的寫入如果發生了嚴重的錯誤那么也會導致ASM自動強制去DROP該Disk。如果該disk的drop會造成數據丟失,那么diskgroup被強制dismount,該dismount也會造成數據庫實例被kill。
Rebalance
rebalance diskgroup將在diskgroup范圍內將數據在其DISK上移動,以保證文件們均勻分布在diskgroup中的所有磁盤上,同時也會考慮到每一個ASM DISK的大小。 當文件均勻地分布在所有磁盤上,則各個磁盤的使用量也會很接近。如此以保證負載均衡。rebalance的算法既不基于I/O統計信息也不基于其他統計結果; 完全取決于Diskgroup中disk的大小。
一旦diskgroup中發生了一些存儲配置變化 例如disk add/drop/resize均會自動觸發一次rebalance。power參數將決定有多少slave進程并發參數數據移動。所有的slave進程均從發生rebalance的實力啟動并工作。rebalance可以手動調控,即便已經在進行一次rebalance中了,也可以指定其他節點上的實例做rebalance,只要管路員想要這樣做。如果實例意外crash,那么未結束的rebalance將自動重新啟動。
注意rebalance中的每一次extent 移動均會與數據庫實例做協調,因為數據庫實例可能同時需要讀取或者寫這個 extent,所以數據庫在rebalance 同時能正常工作。 其對數據庫的影響一般較小,原因是同一時間只有一個extent被鎖定以便移動,且僅僅是阻塞寫入。
ASMLIB
ASMLIB是通過在Linux上安裝asmlib包來提供標準I/O接口,以便ASM發現和訪問ASM disk。 關于ASMLIB詳見:
關于udev與asmlib 以及Multipath的問題,提問前先看這個
Disk Header
一個ASM DISK的最前面4096字節為disk header,對于ASM而言是block 0 (blkn=0);許多操作系統會保留LUN的第一個block來存放分區表或其他OS信息。 一般不讓ASM基礎到這個block,因為ASM會毫不猶豫地覆蓋這個block。在一些指定的平臺上ORACLE從代碼層跳過這些操作系統塊,但實際操作時一般的慣例是只給ASM用那些上面沒有分區表的LUN DISK。
對于這一點詳細的展開是,例如你在AIX操作系統上使用PV作為ASM DISK,則PV上不能有PVID,同時如果一個PV已經分給ASM用了,但是由于系統管理員的疏忽而給PV分配了一個PVID,則該PV 頭部的ASM disk header會被覆蓋掉,這將直接導致disk header丟失;如果是External Redundancy那么這個diskgroup就直接mount不起來了。所以對那些會影響ASM disk header的操作要慎之又慎,同時最好定期備份disk header。
ASM disk header描述了該ASM disk和diskgroup的屬性,通過對現有disk header的加載,ASM實例可以知道這個diskgroup的整體信息。
下面是一個典型的disk header的一部分, 其disk number為0 ,redundancy為KFDGTP_HIGH,diskname為DATA1_0000,diskgroup name 為DATA1,failgroup name為DATA1_0000:
kfbh.endian: 1 ; 0x000: 0x01 kfbh.hard: 130 ; 0x001: 0x82 kfbh.type: 1 ; 0x002: KFBTYP_DISKHEAD kfbh.datfmt: 1 ; 0x003: 0x01 kfbh.block.blk: 0 ; 0x004: blk=0 kfbh.block.obj: 2147483648 ; 0x008: disk=0 kfbh.check: 3107059325 ; 0x00c: 0xb931f67d kfbh.fcn.base: 0 ; 0x010: 0x00000000 kfbh.fcn.wrap: 0 ; 0x014: 0x00000000 kfbh.spare1: 0 ; 0x018: 0x00000000 kfbh.spare2: 0 ; 0x01c: 0x00000000 kfdhdb.driver.provstr: ORCLDISK ; 0x000: length=8 kfdhdb.driver.reserved[0]: 0 ; 0x008: 0x00000000 kfdhdb.driver.reserved[1]: 0 ; 0x00c: 0x00000000 kfdhdb.driver.reserved[2]: 0 ; 0x010: 0x00000000 kfdhdb.driver.reserved[3]: 0 ; 0x014: 0x00000000 kfdhdb.driver.reserved[4]: 0 ; 0x018: 0x00000000 kfdhdb.driver.reserved[5]: 0 ; 0x01c: 0x00000000 kfdhdb.compat: 186646528 ; 0x020: 0x0b200000 kfdhdb.dsknum: 0 ; 0x024: 0x0000 kfdhdb.grptyp: 3 ; 0x026: KFDGTP_HIGH kfdhdb.hdrsts: 3 ; 0x027: KFDHDR_MEMBER kfdhdb.dskname: DATA1_0000 ; 0x028: length=10 kfdhdb.grpname: DATA1 ; 0x048: length=5 kfdhdb.fgname: DATA1_0000 ; 0x068: length=10 kfdhdb.capname: ; 0x088: length=0 kfdhdb.crestmp.hi: 32999670 ; 0x0a8: HOUR=0x16 DAYS=0x7 MNTH=0x2 YEAR=0x7de kfdhdb.crestmp.lo: 1788720128 ; 0x0ac: USEC=0x0 MSEC=0x36d SECS=0x29 MINS=0x1a kfdhdb.mntstmp.hi: 32999670 ; 0x0b0: HOUR=0x16 DAYS=0x7 MNTH=0x2 YEAR=0x7de kfdhdb.mntstmp.lo: 1812990976 ; 0x0b4: USEC=0x0 MSEC=0x3 SECS=0x1 MINS=0x1b kfdhdb.secsize: 512 ; 0x0b8: 0x0200 kfdhdb.blksize: 4096 ; 0x0ba: 0x1000 kfdhdb.ausize: 4194304 ; 0x0bc: 0x00400000 kfdhdb.mfact: 454272 ; 0x0c0: 0x0006ee80 kfdhdb.dsksize: 32375 ; 0x0c4: 0x00007e77 kfdhdb.pmcnt: 2 ; 0x0c8: 0x00000002 kfdhdb.fstlocn: 1 ; 0x0cc: 0x00000001 kfdhdb.altlocn: 2 ; 0x0d0: 0x00000002 kfdhdb.f1b1locn: 2 ; 0x0d4: 0x00000002 kfdhdb.redomirrors[0]: 0 ; 0x0d8: 0x0000 kfdhdb.redomirrors[1]: 0 ; 0x0da: 0x0000 kfdhdb.redomirrors[2]: 0 ; 0x0dc: 0x0000 kfdhdb.redomirrors[3]: 0 ; 0x0de: 0x0000 kfdhdb.dbcompat: 186646528 ; 0x0e0: 0x0b200000 kfdhdb.grpstmp.hi: 32999670 ; 0x0e4: HOUR=0x16 DAYS=0x7 MNTH=0x2 YEAR=0x7de kfdhdb.grpstmp.lo: 1783335936 ; 0x0e8: USEC=0x0 MSEC=0x2e3 SECS=0x24 MINS=0x1a kfdhdb.vfstart: 0 ; 0x0ec: 0x00000000 kfdhdb.vfend: 0 ; 0x0f0: 0x00000000 kfdhdb.spfile: 0 ; 0x0f4: 0x00000000 kfdhdb.spfflg: 0 ; 0x0f8: 0x00000000 kfdhdb.ub4spare[0]: 0 ; 0x0fc: 0x00000000 kfdhdb.ub4spare[1]: 0 ; 0x100: 0x00000000 kfdhdb.ub4spare[2]: 0 ; 0x104: 0x00000000 kfdhdb.ub4spare[3]: 0 ; 0x108: 0x00000000
下面的信息是在同一個diskgroup中的所有disk的header上均會復制一份的:
下面的信息是每一個asm disk獨有的:
Freespace Table
AU=0 的blkn=1 包含的是free space table;其中包含了該AU中allocation table中每一個block上大致的可用剩余FREE SPACE可用空間信息。通過參考free space table可以避免在已經分配完的allocation table中查找空間。
[oracle@mlab2 dbs]$ kfed read /oracleasm/asm-disk01 blkn=1 aun=0 aus=4194304|less
kfbh.endian: 1 ; 0x000: 0x01
kfbh.hard: 130 ; 0x001: 0x82 kfbh.type: 2 ; 0x002: KFBTYP_FREESPC kfbh.datfmt: 2 ; 0x003: 0x02
kfbh.block.blk: 1 ; 0x004: blk=1
kfbh.block.obj: 2147483648 ; 0x008: disk=0
kfbh.check: 3847932395 ; 0x00c: 0xe55ac9eb
kfbh.fcn.base: 22557 ; 0x010: 0x0000581d
kfbh.fcn.wrap: 0 ; 0x014: 0x00000000
kfbh.spare1: 0 ; 0x018: 0x00000000
kfbh.spare2: 0 ; 0x01c: 0x00000000
kfdfsb.aunum: 0 ; 0x000: 0x00000000
kfdfsb.max: 1014 ; 0x004: 0x03f6
kfdfsb.cnt: 73 ; 0x006: 0x0049
kfdfsb.bound: 0 ; 0x008: 0x0000
kfdfsb.flag: 1 ; 0x00a: B=1
kfdfsb.ub1spare: 0 ; 0x00b: 0x00
kfdfsb.spare[0]: 0 ; 0x00c: 0x00000000
kfdfsb.spare[1]: 0 ; 0x010: 0x00000000
kfdfsb.spare[2]: 0 ; 0x014: 0x00000000
kfdfse[0].fse: 0 ; 0x018: FREE=0x0 FRAG=0x0
kfdfse[1].fse: 0 ; 0x019: FREE=0x0 FRAG=0x0
kfdfse[2].fse: 0 ; 0x01a: FREE=0x0 FRAG=0x0
kfdfse[3].fse: 0 ; 0x01b: FREE=0x0 FRAG=0x0
kfdfse[4].fse: 0 ; 0x01c: FREE=0x0 FRAG=0x0
kfdfse[5].fse: 0 ; 0x01d: FREE=0x0 FRAG=0x0
kfdfse[6].fse: 0 ; 0x01e: FREE=0x0 FRAG=0x0
kfdfse[7].fse: 0 ; 0x01f: FREE=0x0 FRAG=0x0
kfdfse[8].fse: 0 ; 0x020: FREE=0x0 FRAG=0x0
kfdfse[9].fse: 0 ; 0x021: FREE=0x0 FRAG=0x0
kfdfse[10].fse: 0 ; 0x022: FREE=0x0 FRAG=0x0
kfdfse[11].fse: 119 ; 0x023: FREE=0x7 FRAG=0x7
kfdfse[12].fse: 16 ; 0x024: FREE=0x0 FRAG=0x1
kfdfse[13].fse: 16 ; 0x025: FREE=0x0 FRAG=0x1
kfdfse[14].fse: 16 ; 0x026: FREE=0x0 FRAG=0x1
kfdfse[15].fse: 16 ; 0x027: FREE=0x0 FRAG=0x1
kfdfse[16].fse: 16 ; 0x028: FREE=0x0 FRAG=0x1
kfdfse[17].fse: 16 ; 0x029: FREE=0x0 FRAG=0x1
kfdfse[18].fse: 16 ; 0x02a: FREE=0x0 FRAG=0x1
kfdfse[19].fse: 16 ; 0x02b: FREE=0x0 FRAG=0x1
kfdfse[20].fse: 16 ; 0x02c: FREE=0x0 FRAG=0x1
kfdfse[21].fse: 16 ; 0x02d: FREE=0x0 FRAG=0x1
kfdfse[22].fse: 16 ; 0x02e: FREE=0x0 FRAG=0x1
kfdfse[23].fse: 16 ; 0x02f: FREE=0x0 FRAG=0x1
kfdfse[24].fse: 16 ; 0x030: FREE=0x0 FRAG=0x1
kfdfse[25].fse: 16 ; 0x031: FREE=0x0 FRAG=0x1
kfdfse[26].fse: 16 ; 0x032: FREE=0x0 FRAG=0x1
kfdfse[27].fse: 16 ; 0x033: FREE=0x0 FRAG=0x1
kfdfse[28].fse: 16 ; 0x034: FREE=0x0 FRAG=0x1
aunum_kfdfsb First AU of first ATB of this FSB
max_kfdfsb Max number of FSEs per FSB
cnt_kfdfsb Number of FSEs up to end of disk
spare_kfdfsb spares for future
kfdfse – Kernel Files Disk Free Space Entry.
max_kfdfsb describes the number of free space entries which would
be used in this free space table if the disk were large enough to
provide all of the AUs which can be described by a single physical
metadata AU. cnt_kfdfsb describes the number of free space entries
which correspond to AUs which are actually present on the disk. In
the case where there are additional physical metadata AUs beyond the
one containing this kfdfsb, then max_kfdfsb will equal cnt_kfdfsb.
There are complications with the interpretation of cnt_kfdfsb when
a disk is being grown or shrunk. It is possible in these cases to
have allocated AUs past the range indicated by cnt_kfdfsb which have
not yet been relocated into the new area of the disk.
The Free Space Table provides a summary of which allocation table
blocks have free space. There is one kfdfse in the FST for each
Allocation Table block described by the FST.
The first key parameter is the stripe width of the array. Stripe width refers to the number of parallel stripes that can be written to or read from simultaneously. This is of course equal to the number of disks in the array. So a four-disk striped array would have a stripe width of four.
Allocation Table
Aun=0的后254個metadata block用以存放AU分配信息。 每一個metadata描述448個AU的狀態, 如果一個AU已經分配給一個文件,則allocation table 記錄其ASM文件號和data extent號。對于還是FREE的AU則被link到free list上。
kfbh.endian: 1 ; 0x000: 0x01 kfbh.hard: 130 ; 0x001: 0x82 kfbh.type: 3 ; 0x002: KFBTYP_ALLOCTBL kfbh.datfmt: 2 ; 0x003: 0x02 kfbh.block.blk: 2 ; 0x004: blk=2 kfbh.block.obj: 2147483648 ; 0x008: disk=0 kfbh.check: 2376540464 ; 0x00c: 0x8da72130 kfbh.fcn.base: 44495 ; 0x010: 0x0000adcf kfbh.fcn.wrap: 0 ; 0x014: 0x00000000 kfbh.spare1: 0 ; 0x018: 0x00000000 kfbh.spare2: 0 ; 0x01c: 0x00000000 kfdatb.aunum: 0 ; 0x000: 0x00000000 kfdatb.shrink: 448 ; 0x004: 0x01c0 kfdatb.ub2pad: 0 ; 0x006: 0x0000 kfdatb.auinfo[0].link.next: 112 ; 0x008: 0x0070 kfdatb.auinfo[0].link.prev: 112 ; 0x00a: 0x0070 kfdatb.auinfo[1].link.next: 120 ; 0x00c: 0x0078 kfdatb.auinfo[1].link.prev: 120 ; 0x00e: 0x0078 kfdatb.auinfo[2].link.next: 136 ; 0x010: 0x0088 kfdatb.auinfo[2].link.prev: 136 ; 0x012: 0x0088 kfdatb.auinfo[3].link.next: 20 ; 0x014: 0x0014 kfdatb.auinfo[3].link.prev: 20 ; 0x016: 0x0014 kfdatb.auinfo[4].link.next: 168 ; 0x018: 0x00a8 kfdatb.auinfo[4].link.prev: 168 ; 0x01a: 0x00a8 kfdatb.auinfo[5].link.next: 296 ; 0x01c: 0x0128 kfdatb.auinfo[5].link.prev: 296 ; 0x01e: 0x0128 kfdatb.auinfo[6].link.next: 552 ; 0x020: 0x0228 kfdatb.auinfo[6].link.prev: 3112 ; 0x022: 0x0c28 kfdatb.spare: 0 ; 0x024: 0x00000000 kfdate[0].discriminator: 1 ; 0x028: 0x00000001 kfdate[0].allo.lo: 0 ; 0x028: XNUM=0x0 kfdate[0].allo.hi: 8388608 ; 0x02c: V=1 I=0 H=0 FNUM=0x0 kfdate[1].discriminator: 1 ; 0x030: 0x00000001 kfdate[1].allo.lo: 0 ; 0x030: XNUM=0x0 kfdate[1].allo.hi: 8388608 ; 0x034: V=1 I=0 H=0 FNUM=0x0 kfdate[2].discriminator: 1 ; 0x038: 0x00000001 kfdate[2].allo.lo: 0 ; 0x038: XNUM=0x0 kfdate[2].allo.hi: 8388609 ; 0x03c: V=1 I=0 H=0 FNUM=0x1 kfdate[3].discriminator: 1 ; 0x040: 0x00000001 kfdate[3].allo.lo: 8 ; 0x040: XNUM=0x8 kfdate[3].allo.hi: 8388611 ; 0x044: V=1 I=0 H=0 FNUM=0x3 kfdate[4].discriminator: 1 ; 0x048: 0x00000001 kfdate[4].allo.lo: 19 ; 0x048: XNUM=0x13 kfdate[4].allo.hi: 8388611 ; 0x04c: V=1 I=0 H=0 FNUM=0x3 kfdate[5].discriminator: 1 ; 0x050: 0x00000001 kfdate[5].allo.lo: 29 ; 0x050: XNUM=0x1d kfdate[5].allo.hi: 8388611 ; 0x054: V=1 I=0 H=0 FNUM=0x3 kfdate[6].discriminator: 1 ; 0x058: 0x00000001 kfdate[6].allo.lo: 30 ; 0x058: XNUM=0x1e kfdate[6].allo.hi: 8388611 ; 0x05c: V=1 I=0 H=0 FNUM=0x3 kfdate[7].discriminator: 1 ; 0x060: 0x00000001 kfdate[7].allo.lo: 0 ; 0x060: XNUM=0x0 kfdate[7].allo.hi: 8388612 ; 0x064: V=1 I=0 H=0 FNUM=0x4 kfdate[8].discriminator: 1 ; 0x068: 0x00000001
Partner and Status Table
一般來說aun=1 是保留給Partner and Status Table(PST)的拷貝使用的。 一般5個ASM DISK將包含一份PST拷貝。多數的PST內容必須相同且驗證有效。否則無法判斷哪些ASM DISK實際擁有相關數據。
在 PST中每一條記錄對應Diskgroup中的一個ASM DISK。每一條記錄會對一個ASM disk枚舉其partners的ASM DISK。同時會有一個flag來表示該DISK是否是ONLINE可讀寫的。這些信息對recovery是否能做很重要。
PST表的Blkn=0是PST的header,存放了如下的信息:
PST的最后一個塊是heartbeat block,當diskgroup mount時其每3秒心跳更新一次。
以下為PST header
kfed read /oracleasm/asm-disk01 aun=1 blkn=0 aus=4194304 |less kfbh.endian: 1 ; 0x000: 0x01 kfbh.hard: 130 ; 0x001: 0x82 kfbh.type: 17 ; 0x002: KFBTYP_PST_META kfbh.datfmt: 2 ; 0x003: 0x02 kfbh.block.blk: 1024 ; 0x004: blk=1024 kfbh.block.obj: 2147483648 ; 0x008: disk=0 kfbh.check: 3813974007 ; 0x00c: 0xe3549ff7 kfbh.fcn.base: 0 ; 0x010: 0x00000000 kfbh.fcn.wrap: 0 ; 0x014: 0x00000000 kfbh.spare1: 0 ; 0x018: 0x00000000 kfbh.spare2: 0 ; 0x01c: 0x00000000 kfdpHdrPairBv1.first.super.time.hi:32999670 ; 0x000: HOUR=0x16 DAYS=0x7 MNTH=0x2 YEAR=0x7de kfdpHdrPairBv1.first.super.time.lo:1788841984 ; 0x004: USEC=0x0 MSEC=0x3e4 SECS=0x29 MINS=0x1a kfdpHdrPairBv1.first.super.last: 2 ; 0x008: 0x00000002 kfdpHdrPairBv1.first.super.next: 2 ; 0x00c: 0x00000002 kfdpHdrPairBv1.first.super.copyCnt: 5 ; 0x010: 0x05 kfdpHdrPairBv1.first.super.version: 1 ; 0x011: 0x01 kfdpHdrPairBv1.first.super.ub2spare: 0 ; 0x012: 0x0000 kfdpHdrPairBv1.first.super.incarn: 1 ; 0x014: 0x00000001 kfdpHdrPairBv1.first.super.copy[0]: 0 ; 0x018: 0x0000 kfdpHdrPairBv1.first.super.copy[1]: 1 ; 0x01a: 0x0001 kfdpHdrPairBv1.first.super.copy[2]: 2 ; 0x01c: 0x0002 kfdpHdrPairBv1.first.super.copy[3]: 3 ; 0x01e: 0x0003 kfdpHdrPairBv1.first.super.copy[4]: 4 ; 0x020: 0x0004 kfdpHdrPairBv1.first.super.dtaSz: 15 ; 0x022: 0x000f kfdpHdrPairBv1.first.asmCompat:186646528 ; 0x024: 0x0b200000 kfdpHdrPairBv1.first.newCopy[0]: 0 ; 0x028: 0x0000 kfdpHdrPairBv1.first.newCopy[1]: 0 ; 0x02a: 0x0000 kfdpHdrPairBv1.first.newCopy[2]: 0 ; 0x02c: 0x0000 kfdpHdrPairBv1.first.newCopy[3]: 0 ; 0x02e: 0x0000 kfdpHdrPairBv1.first.newCopy[4]: 0 ; 0x030: 0x0000 kfdpHdrPairBv1.first.newCopyCnt: 0 ; 0x032: 0x00 kfdpHdrPairBv1.first.contType: 1 ; 0x033: 0x01 kfdpHdrPairBv1.first.spares[0]: 0 ; 0x034: 0x00000000 kfdpHdrPairBv1.first.spares[1]: 0 ; 0x038: 0x00000000 kfdpHdrPairBv1.first.spares[2]: 0 ; 0x03c: 0x00000000 kfdpHdrPairBv1.first.spares[3]: 0 ; 0x040: 0x00000000 kfdpHdrPairBv1.first.spares[4]: 0 ; 0x044: 0x00000000 kfdpHdrPairBv1.first.spares[5]: 0 ; 0x048: 0x00000000 kfdpHdrPairBv1.first.spares[6]: 0 ; 0x04c: 0x00000000 kfdpHdrPairBv1.first.spares[7]: 0 ; 0x050: 0x00000000 kfdpHdrPairBv1.first.spares[8]: 0 ; 0x054: 0x00000000 kfdpHdrPairBv1.first.spares[9]: 0 ; 0x058: 0x00000000 kfdpHdrPairBv1.first.spares[10]: 0 ; 0x05c: 0x00000000 kfdpHdrPairBv1.first.spares[11]: 0 ; 0x060: 0x00000000 kfdpHdrPairBv1.first.spares[12]: 0 ; 0x064: 0x00000000 kfdpHdrPairBv1.first.spares[13]: 0 ; 0x068: 0x00000000 kfdpHdrPairBv1.first.spares[14]: 0 ; 0x06c: 0x00000000 kfdpHdrPairBv1.first.spares[15]: 0 ; 0x070: 0x00000000 kfdpHdrPairBv1.first.spares[16]: 0 ; 0x074: 0x00000000 kfdpHdrPairBv1.first.spares[17]: 0 ; 0x078: 0x00000000 kfdpHdrPairBv1.first.spares[18]: 0 ; 0x07c: 0x00000000 kfdpHdrPairBv1.first.spares[19]: 0 ; 0x080: 0x00000000
以下為PST table block:
kfed read /oracleasm/asm-disk02 aun=1 blkn=3 aus=4194304 |less kfbh.endian: 1 ; 0x000: 0x01 kfbh.hard: 130 ; 0x001: 0x82 kfbh.type: 18 ; 0x002: KFBTYP_PST_DTA kfbh.datfmt: 2 ; 0x003: 0x02 kfbh.block.blk: 1027 ; 0x004: blk=1027 kfbh.block.obj: 2147483649 ; 0x008: disk=1 kfbh.check: 4204644293 ; 0x00c: 0xfa9dc7c5 kfbh.fcn.base: 0 ; 0x010: 0x00000000 kfbh.fcn.wrap: 0 ; 0x014: 0x00000000 kfbh.spare1: 0 ; 0x018: 0x00000000 kfbh.spare2: 0 ; 0x01c: 0x00000000 kfdpDtaEv1[0].status: 127 ; 0x000: I=1 V=1 V=1 P=1 P=1 A=1 D=1 kfdpDtaEv1[0].fgNum: 1 ; 0x002: 0x0001 kfdpDtaEv1[0].addTs: 2022663849 ; 0x004: 0x788f66a9 kfdpDtaEv1[0].partner[0]: 49154 ; 0x008: P=1 P=1 PART=0x2 kfdpDtaEv1[0].partner[1]: 49153 ; 0x00a: P=1 P=1 PART=0x1 kfdpDtaEv1[0].partner[2]: 49155 ; 0x00c: P=1 P=1 PART=0x3 kfdpDtaEv1[0].partner[3]: 49166 ; 0x00e: P=1 P=1 PART=0xe kfdpDtaEv1[0].partner[4]: 49165 ; 0x010: P=1 P=1 PART=0xd kfdpDtaEv1[0].partner[5]: 49164 ; 0x012: P=1 P=1 PART=0xc kfdpDtaEv1[0].partner[6]: 49156 ; 0x014: P=1 P=1 PART=0x4 kfdpDtaEv1[0].partner[7]: 49163 ; 0x016: P=1 P=1 PART=0xb kfdpDtaEv1[0].partner[8]: 10000 ; 0x018: P=0 P=0 PART=0x2710 kfdpDtaEv1[0].partner[9]: 0 ; 0x01a: P=0 P=0 PART=0x0 kfdpDtaEv1[0].partner[10]: 0 ; 0x01c: P=0 P=0 PART=0x0 kfdpDtaEv1[0].partner[11]: 0 ; 0x01e: P=0 P=0 PART=0x0 kfdpDtaEv1[0].partner[12]: 0 ; 0x020: P=0 P=0 PART=0x0 kfdpDtaEv1[0].partner[13]: 0 ; 0x022: P=0 P=0 PART=0x0 kfdpDtaEv1[0].partner[14]: 0 ; 0x024: P=0 P=0 PART=0x0 kfdpDtaEv1[0].partner[15]: 0 ; 0x026: P=0 P=0 PART=0x0 kfdpDtaEv1[0].partner[16]: 0 ; 0x028: P=0 P=0 PART=0x0 kfdpDtaEv1[0].partner[17]: 0 ; 0x02a: P=0 P=0 PART=0x0 kfdpDtaEv1[0].partner[18]: 0 ; 0x02c: P=0 P=0 PART=0x0 kfdpDtaEv1[0].partner[19]: 0 ; 0x02e: P=0 P=0 PART=0x0 kfdpDtaEv1[1].status: 127 ; 0x030: I=1 V=1 V=1 P=1 P=1 A=1 D=1 kfdpDtaEv1[1].fgNum: 2 ; 0x032: 0x0002 kfdpDtaEv1[1].addTs: 2022663849 ; 0x034: 0x788f66a9 kfdpDtaEv1[1].partner[0]: 49155 ; 0x038: P=1 P=1 PART=0x3 kfdpDtaEv1[1].partner[1]: 49152 ; 0x03a: P=1 P=1 PART=0x0 kfdpDtaEv1[1].partner[2]: 49154 ; 0x03c: P=1 P=1 PART=0x2 kfdpDtaEv1[1].partner[3]: 49166 ; 0x03e: P=1 P=1 PART=0xe kfdpDtaEv1[1].partner[4]: 49157 ; 0x040: P=1 P=1 PART=0x5 kfdpDtaEv1[1].partner[5]: 49156 ; 0x042: P=1 P=1 PART=0x4 kfdpDtaEv1[1].partner[6]: 49165 ; 0x044: P=1 P=1 PART=0xd kfdpDtaEv1[1].partner[7]: 49164 ; 0x046: P=1 P=1 PART=0xc kfdpDtaEv1[1].partner[8]: 10000 ; 0x048: P=0 P=0 PART=0x2710 kfdpDtaEv1[1].partner[9]: 0 ; 0x04a: P=0 P=0 PART=0x0 kfdpDtaEv1[1].partner[10]: 0 ; 0x04c: P=0 P=0 PART=0x0 kfdpDtaEv1[1].partner[11]: 0 ; 0x04e: P=0 P=0 PART=0x0 kfdpDtaEv1[1].partner[12]: 0 ; 0x050: P=0 P=0 PART=0x0 kfdpDtaEv1[1].partner[13]: 0 ; 0x052: P=0 P=0 PART=0x0 kfdpDtaEv1[1].partner[14]: 0 ; 0x054: P=0 P=0 PART=0x0 kfdpDtaEv1[1].partner[15]: 0 ; 0x056: P=0 P=0 PART=0x0 kfdpDtaEv1[1].partner[16]: 0 ; 0x058: P=0 P=0 PART=0x0
aun=1 的最后第二個block中備份了一份KFBTYP_DISKHEAD
[oracle@mlab2 hzy]$ kfed read /oracleasm/asm-disk02 aun=1 blkn=1022 aus=4194304 |less kfbh.endian: 1 ; 0x000: 0x01 kfbh.hard: 130 ; 0x001: 0x82 kfbh.type: 1 ; 0x002: KFBTYP_DISKHEAD kfbh.datfmt: 1 ; 0x003: 0x01 kfbh.block.blk: 1022 ; 0x004: blk=1022 kfbh.block.obj: 2147483649 ; 0x008: disk=1 kfbh.check: 3107059260 ; 0x00c: 0xb931f63c kfbh.fcn.base: 0 ; 0x010: 0x00000000 kfbh.fcn.wrap: 0 ; 0x014: 0x00000000 kfbh.spare1: 0 ; 0x018: 0x00000000 kfbh.spare2: 0 ; 0x01c: 0x00000000 kfdhdb.driver.provstr: ORCLDISK ; 0x000: length=8 kfdhdb.driver.reserved[0]: 0 ; 0x008: 0x00000000 kfdhdb.driver.reserved[1]: 0 ; 0x00c: 0x00000000 kfdhdb.driver.reserved[2]: 0 ; 0x010: 0x00000000 kfdhdb.driver.reserved[3]: 0 ; 0x014: 0x00000000 kfdhdb.driver.reserved[4]: 0 ; 0x018: 0x00000000 kfdhdb.driver.reserved[5]: 0 ; 0x01c: 0x00000000 kfdhdb.compat: 186646528 ; 0x020: 0x0b200000 kfdhdb.dsknum: 1 ; 0x024: 0x0001 kfdhdb.grptyp: 3 ; 0x026: KFDGTP_HIGH kfdhdb.hdrsts: 3 ; 0x027: KFDHDR_MEMBER kfdhdb.dskname: DATA1_0001 ; 0x028: length=10 kfdhdb.grpname: DATA1 ; 0x048: length=5 kfdhdb.fgname: DATA1_0001 ; 0x068: length=10 kfdhdb.capname: ; 0x088: length=0 kfdhdb.crestmp.hi: 32999670 ; 0x0a8: HOUR=0x16 DAYS=0x7 MNTH=0x2 YEAR=0x7de kfdhdb.crestmp.lo: 1788720128 ; 0x0ac: USEC=0x0 MSEC=0x36d SECS=0x29 MINS=0x1a kfdhdb.mntstmp.hi: 32999670 ; 0x0b0: HOUR=0x16 DAYS=0x7 MNTH=0x2 YEAR=0x7de kfdhdb.mntstmp.lo: 1812990976 ; 0x0b4: USEC=0x0 MSEC=0x3 SECS=0x1 MINS=0x1b kfdhdb.secsize: 512 ; 0x0b8: 0x0200 kfdhdb.blksize: 4096 ; 0x0ba: 0x1000 kfdhdb.ausize: 4194304 ; 0x0bc: 0x00400000
AUN=1 的最后一個block為KFBTYP_HBEAT 心跳表:
[oracle@mlab2 hzy]$ kfed read /oracleasm/asm-disk02 aun=1 blkn=1023 aus=4194304 |less kfbh.endian: 1 ; 0x000: 0x01 kfbh.hard: 130 ; 0x001: 0x82 kfbh.type: 19 ; 0x002: KFBTYP_HBEAT kfbh.datfmt: 2 ; 0x003: 0x02 kfbh.block.blk: 2047 ; 0x004: blk=2047 kfbh.block.obj: 2147483649 ; 0x008: disk=1 kfbh.check: 1479766671 ; 0x00c: 0x5833728f kfbh.fcn.base: 0 ; 0x010: 0x00000000 kfbh.fcn.wrap: 0 ; 0x014: 0x00000000 kfbh.spare1: 0 ; 0x018: 0x00000000 kfbh.spare2: 0 ; 0x01c: 0x00000000 kfdpHbeatB.instance: 1 ; 0x000: 0x00000001 kfdpHbeatB.ts.hi: 32999734 ; 0x004: HOUR=0x16 DAYS=0x9 MNTH=0x2 YEAR=0x7de kfdpHbeatB.ts.lo: 3968041984 ; 0x008: USEC=0x0 MSEC=0xe1 SECS=0x8 MINS=0x3b kfdpHbeatB.rnd[0]: 1065296177 ; 0x00c: 0x3f7f2131 kfdpHbeatB.rnd[1]: 857037208 ; 0x010: 0x33155998 kfdpHbeatB.rnd[2]: 2779184235 ; 0x014: 0xa5a6fc6b kfdpHbeatB.rnd[3]: 2660793989 ; 0x018: 0x9e987e85
如下場景中PST 可能被重定位:
Extents Set
extents set 是data extent的集合,以此來維護virtual extent的冗余拷貝。ASM FILE1 中的extent 指針在extent map中是連續的,如下面的數據:
SQL> select pxn_kffxp,xnum_kffxp from x$kffxp where number_kffxp=257;
PXN_KFFXP XNUM_KFFXP
---------- ----------
0 0
1 0
2 0
3 1
4 1
5 1
6 2
7 2
8 2
9 3
10 3
以上查詢中PXN_KFFXP為文件號257文件的物理extent號,而XNUM_KFFXP為邏輯extent號。 此文件位于一個High redundancy diskgroup上,所以一個extent set 包含3份相同的virtual extent數據。
可以把上述查詢就看做文件號257文件的extent map,其邏輯extent號是連續遞增的。
在一個extent sets中第一個extent就是primary extent。 在external redundancy模式下僅有一個primary extent。Normal redundancy下有一個二級extent在primary之后,high的情況下有2個二級extent。
對于normal redundancy下的文件,每一個extent set 都由2個分布在不同磁盤同時也是2個不同failure group的data extent組成。這2個data extent在extent map上是緊挨著的。primary extent的extent number總是偶數,其唯一的一個二級extent總是奇數。當一個extent被移動時一般會引發extent set中所有extent對應的移動,以滿足冗余要求。
High Redundancy diskgroup默認使用三路鏡像。三路鏡像下的Vritual Extent有一個primary和2個二級secondary data extents。secondary data extents需要存放在不同的failure group,所以其要求至少三個failure group來實現high redundancy。
在特殊情況下可能存在data extent的丟失,例如當failure group不可用導致無處可放時。
secondary extent將被均勻分配在primary extent對應的disk partners上;即便有磁盤失敗仍能保持對extent set的寫出是負載均衡的。
File Directory (file #1)
具體請參考 深入了解Oracle ASM(二):ASM File number 1 文件目錄 http://www.askmaclean.com/archives/asm-file-number-1-the-file-directory.html
ASM實例啟動
在ASM文件可以通過ASM實例來訪問之前,ASM實例必須先啟動。 在11.2下 不管是RAC還是StandAlone環境下ASM實例都會隨系統BOOT自動啟動。 啟動一個ASM實例和啟動一個數據庫實例類似。 SGA和一組后臺進程在啟動過程中被創建出來。初始化參數instance_type決定了是ASM 實例還是數據庫實例。除非STARTUP時使用了 NOMOUNT選項,否則默認STARTUP會執行ALTER DISKGROUP ALL MOUNT。
ASM實例啟動過程中將加入到CSS中的+ASM成員組中。這將允許本實例與其他+ASM實例共享鎖。數據庫實例不會加入到這個成員組中,因為數據庫實例的實例名不能以”+”開頭。
Discovery 發現磁盤
Discovery 過程是在找到磁盤以便后續的操作。Discovery 到DISK STRING匹配的位置去找尋磁盤,并返回那些其認為合適的磁盤。對discovery一般存在于2種場景下; 第一種是使用asm_diskstring中指定的所有字符串來找出所有ASM實例必要訪問的磁盤。 第二種是指定磁盤路徑用以create diskgroup或者add disk to diskgroup。
第一種discovery也叫做shallow discovery, 只會返回asm_diskstring指定下的磁盤。第二種也叫做deep discovery,是讀取每一個磁盤的第一個塊。 disk header在這里用以分類磁盤是否可用,是被ASM外的其他東西實用(例如LVM),還是已經被其他diskgroup實用。discovery操作并不會 mount diskgroup或者寫任何磁盤頭。
Create Disk Group 創建磁盤組
創建diskgroup 需要指定多個磁盤路徑,且這些磁盤需要通過如下的檢測:
所有的磁盤均會以寫入一個disk header的形式來驗證。該 disk header中mount timestamp為0 ,由此可知diskgroup還沒有被mount 過。之后free space block和allocation table blocks 元數據塊將被寫入。
其中部分磁盤被選出來 存放Partnership and Status Table ,PST 表。 PST被初始化記錄所有的磁盤為在線狀態。High redundancy disk group 每一個failure group對應一個 PST,最多5個拷貝。 normal redundancy group至多3個PST拷貝。external redundancy disk group有一個PST。
接著后續的metadata block將被初始化,并均勻分布在新創建的diskgroup的所有磁盤上。
【Oracle ASM Metadata】Alias Directory (file #6)
【Oracle ASM】Continuing Operations Directory (file #4)
【Oracle ASM Metadata】Template Directory (file #5)
【Oracle ASM】ASM FILE NUMBER 3 Active Change Directory
深入了解Oracle ASM(二):ASM File number 1 文件目錄
【Oracle ASM】ASM FILE NUMBER #2 DISK Directory
當diskgroup完全初始化完成后mount timestamp將寫入到disk header。 這將標記diskgroup已經格式好并可以被mount。其他實例也可以mount該disk group。
Drop Disk Group
diskgroup 可以被drop掉的前提是其上所有的文件都處于關閉狀態且僅有本地實例在mount它。 可以通過在集群件的所有ASM上通信來確認這2點。drop diskgroup會在該DG下所有的磁盤頭寫入header_status為FORMER狀態。
Mount Disk Group
Mount Disk Group使Disk Group其對本地ASM 實例和連接到該實例的數據庫實例可用。 在該diskgroup中的文件在 OPEN/create/delete之前必須先被本地ASM實例mount; 一般啟動ASM時同時mount 多個diskgroup較高效。 典型情況下是ASM_DISKGROUPS匹配到的所有的diskgroup均通過ALTER DISKGROUP ALL MOUNT 在ASM實例啟動時被mount 。
下面是mount 一個diskgroup的步驟:
Discovery
會通過ASM_DISKSTRING.做一個deep discovery; 每一個disk header均包含了其所屬于的diskgroup;該步驟應當要找到所有要被mount 的diskgroup下屬的所有磁盤。 在disk header上獲得如下信息:
當discovery時若發現2個磁盤的disk header一樣則可能報錯,這樣做的目的是為了避免損壞disk group。
注意從diskgroup創建之后每一個ASM DISK的OS設備名可能發生變化,或者在集群中的每個節點上都不一樣,這不要緊只需要discovery能找到它們并通過驗證即可。
第一次mount的實例
會通過Instance Lock實例鎖來判斷ASM實例是否是第一個mount 該diskgroup的,還是已經被其他ASM實例 mount 了。如果是第一個做mount的,那么鎖會被以排他持有直到mount disk group初始化完成,以防止其他實例也在該過程中做mount。 如果不是第一個mount的,那么要等第一個mount的ASM完成其mount操作。
PST discovery
當diskgroup的一組磁盤被找到,必須要找到包含PST的那些磁盤。 每一個磁盤上的AUN=1的第一個塊將被讀取。這樣來識別那些盤在AUN=1中存有PST拷貝。必須找到多數相同的PST拷貝來保證讀出一個有效的PST。
例如如果有5個PST, 則需要找到3份內容一樣的 PST并讀出。
一旦PST被讀取后,ASM實例將知道mount disk group必須要哪些個些disk number。
Heartbeat
如果是第一個mount的實例,那么會做一個heartbeat check心跳檢查。這是為了防止2個不同主機上的實例都認為其實第一個mount該diskgroup的,這種現象可能發生在lock manager配置不當的場景中。當disk group被實例mount時,PST 表上的最后一個塊即心跳塊每3秒被寫入新的值,這種寫入是由已經mount該DG的實例中的一個執行 。 若一個實例自認為第一個mount,但是缺發現了heartbeat則其mount 失敗。若其發現沒有heartbeat,則其將開始heartbeat。
Header validation
若是第一個mount dg的實例則一個新的mount 時間戳timestamp被寫入到各個磁盤。 若不是第一個mount的實例,則會驗證該mount timestamp。這保證2個實例可能找到對一個磁盤的多份完全相同的拷貝時,仍能分辨出其實是不同的磁盤。
若是第一個mount的實例,則可能存在這種情況:上一次mount以來的部分磁盤變得不可用了; 但這些磁盤在PST中仍標記為在線的,但卻找不到它們了。這個差異將被ASM發現并將丟失的磁盤OFFLINE掉,前提是其redundancy允許這些磁盤OFFLINE。
若不是第一個mount的實例則在PST中所有標記為ONLINE 的磁盤均需要被其所發現。若其他實例能發現DG下的所有磁盤,那么本實例必須也能看到。
Redo recovery
若本實例時第一個mount DG的, 則其有義務做crash recovery。若ACD 中的任意redo thread 在他們的檢查點記錄中標記為打開狀態,則它們需要被recover。 這個工序和數據庫的crash recovery很像。在檢查點和最后寫入記錄之間的redo將被掃描,來找出那些塊需要恢復。這些塊將被讀取并應用 redo。
Redo thread selection
ACD中需要找出一塊未使用的區域來存放本實例生成的redo。 若是第一個mount DG的實例則需要保證所有thread 都處于關閉狀態,由此最小的thread將必然可用。 若不是第一個MOUNT DG的實例則可能整個ACD均已被使用。 若遇到此場景,則mount 中的實例將要求已mount 實例去擴展ACD。一旦ACD擴容了新區域以便存放生成的redo,則另一個redo thread將以寫出到checkpoint block的形式來標記為OPEN。
First done
若是第一個mount DG的實例,將開始允許其他實例也能mount該DG。 若第一個實例到這一步之前就crash了,則其他實例將認為自己是第一個mount DG的實例。則若在多于2個實例的集群中后續的mount可以并行運行了。
Registration
實例將自己已mount的DG信息注冊到CSS中。嘗試訪問這些DG的數據庫實例將發現這些CSS注冊信息并連接到ASM實例以便訪問DG。
COD recovery
若是第一個mount DG的實例,其會檢查COD中的記錄,若發現任何操作需要回滾,則將其回滾。若有一個 rebalance作業仍在過程中,則該實例的 RBAL將重新啟動rebalance。
Dismount Disk Group
如同mount是ASM實例本地操作,dismount也是這樣。正常情況下當本地數據庫實例還有訪問diskgroup中文件時是不允許常規的dismount的。 若如果沒有文件被打開訪問,則ASM buffer cache中的臟塊將被寫出到磁盤,且在ACD中的checkpoint記錄將被標記為線程已關閉。且SGA中描述diskgroup的部分將被釋放。
強制FORCE Dismount Disk Group也是常有的事情,當某個磁盤失敗導致冗余算法無法容忍時就會自動觸發強制dismount。 舉個例子來說,當external redundancy下數據未做任何鏡像,則當ASM中cache無法寫出時除了強制dismount外沒有其他選擇。
Add Disk
增加磁盤add disk的命令將針對 指定的discovery strings去識別磁盤,若此時發現的磁盤已經是disk group的一部分,則將被默許為忽略掉。 磁盤將允許被加入到diskgroup,前提是:
當所有的磁盤均被以上驗證過后,下面的步驟將被執行:
當rebalance開始時這個add disk操作就被返回。 磁盤并不完全參與到disk group 中,直到rebalance結束。
ASM Drop Disk
磁盤可以從diskgroup中drop出來的前提是 有足夠的未用空間在剩余的磁盤上。 即便其仍在被活躍使用也還是可以被 drop的。 當磁盤仍在工作,但是對于diskgroup不是必須的時可以做常規的drop。若磁盤失敗時則可以用FORCE選項。 Drop磁盤將影響所有mount diskgroup 的實例。其不是一個實例本地操作。
ASM DROP Normal 常規drop
常規drop disk下磁盤將被標記為不可再分配,且開始一個rebalance。 drop命令當rebalance開始時即返回。在 rebalance過程中該drop中的磁盤將不斷被移動其上的內容到其他磁盤上。 當rebalance 完成時該磁盤將被從disk group中移除并可以復用。 可以通過查詢V$ASM_DISK來確認磁盤是否還是disk group的一部分。
當rebalance還在進行中時,disk將處于正被drop的狀態,即dropping。 還可以通過命令 alter diskgroup undrop來反轉這個還未完成的drop命令的效果。 如此則磁盤上不可再分配的標記將被移除,并會重啟一個rebalance。 這個重啟的rebalance將重新評估我們正在drop的磁盤的partnerships,并可能將數據data extent移回到正被dropping的磁盤上。 這個重啟的rebalance 僅僅需要撤銷之前rebalance所做的工作即可, 因此其所耗時間取決于之前的drop工作的rebalance的工作量。 最后的分配情況可能與開始有著些許區別,但其仍將是平衡的。
ASM DROP Force 強制drop
對于Normal 或者 High Redundancy disk group而言一個磁盤可以使用FORCE選項被DROP。FORCE 選項對于external redundancy 的disk group而言是不可用的, 原因是無法正常從被drop掉的disk上將數據重構出來。 對于normal或者high redundancy的disk group而言如果有一個或者多個磁盤partners已經OFFLINE了,則可能也不允許FORCE DROP。 總是當FORCE DROP可能造成丟失文件上數據的時候都不允許使用。
FORCE DROP會立即將磁盤狀態置為OFFLINE。該磁盤上的所有extent都將脫離其對應的extent set集合,這意味著冗余度的降低。 該磁盤將從disk directory中被移除,PST中也是這樣。
該磁盤的disk header將被寫入信息來表明其不再是disk group的一部分。 rebalance也會被啟動。 當drop force命令返回時,意味著磁盤已經完全從disk group中移除了,可以被重用,也可以從操作系統上斷開了。
發生操作的disk group上所有文件的冗余度要直到rebalance才能重新完善。 與常規的drop不同,顯然force drop是無法被undrop的。磁盤將完全被從disk group移除,所以undrop也無法撤銷此操作; 所能做的是將該磁盤重新加入到diskgroup, add disk。
數據庫實例如何連接到ASM
當數據庫實例嘗試打開或者創建名字以“+”開頭的文件時, 它會通過CSS來查看disk group和mount該DG的ASM實例的信息。 如果數據庫實例之前訪問過其他Disk Group里的文件,則將使用同一個ASM實例。 如果這是第一次訪問ASM上的文件,數據庫實例就需要連接到ASM實例了。 下面為數據庫實例準備訪問ASM上文件的步驟:
后臺進程ASMB啟動并connect連接到ASM實例。 數據庫實例所打開的任意文件的extent map盤區圖被發送給ASMB后臺進程。 其有義務去維護extent map。若發生任何extent移位,則ASM實例將更新發送給數據庫實例的ASMB進程。I/O統計信息定期由ASMB進程反饋給ASM實例。
RBAL后臺進程啟動,其對disk group下的所有磁盤做全局打開操作,其類似于DBWR進程全局打開數據文件。此全局打開允許數據庫實例訪問diskgroup中的任意文件。 若還有其他disk group需要被訪問,則 RBAL也將打開對應diskgroup下的所有磁盤。 對add加入或者drop的磁盤,RBAL也會打開和關閉它們。 關于磁盤的訊息先是發送給ASMB,之后ASMB轉發給RBAL。
會創建一個連接池,一組slave進程將建立到ASM實例的連接。數據庫進程若需要發送信息給ASM實例,則需要使用這些slave進程。 舉個例子來說,打開一個文件,將通過slave給ASM發送一個OPEN的請求。 但對于長時間運行的操作例如創建文件,則不使用slave。
ASM file Create文件創建
文件創建這個過程,是數據庫發送請求給ASM實例,ASM創建文件并響應該請求。
創建文件時會為其分配空間并打開文件以便讀寫。一旦文件完成初始化,則創建被提交。 如果創建文件未被提交則文件會被自動刪除。 其步驟如下:
數據庫進程調用服務層代碼來創建一個文件名以”+”開頭的文件, 系統將自動返回一個生成的名字。 如果文件名里給出了完全路徑則一個用戶別名將被創建并返回。該調用同樣包括 文件類型、塊大小、初始文件大小和構建系統聲稱文件名的其他信息。
數據庫進程連接到ASM實例,此處不用connection pool連接池,原因是文件創建要求保持在同一連接內。 這避免了使用過多連接池連接而可能造成的死鎖。
數據庫進程發送創建請求給ASM實例,需要等待新文件的extent map被加載到數據庫實例中
ASM前臺進程為新文件分配一個文件目錄下的記錄,并在COD continuing operations directory中創建一個回滾記錄,以便刪除該文件。 如果連接被打斷,ASM前臺進程崩潰,或者數據庫中止該創建,則回滾該操作時將自動刪除該文件。
ASM進程為該文件分配extent,以便其均勻分布在disk group中的所有磁盤上。
ASM實例發送extent map 給數據庫實例的ASMB進程
ASM前臺進程將文件名返回給數據庫進程,數據庫進程會保持與ASM進程之間的連接為打開
數據庫進程為新的文件初始化內容,可給出resize請求以便擴大或收縮該文件
當文件的內容和大小都初始化后,一個提交該創建的請求將發送給ASM前臺進程
ASM前臺進程在 alias目錄下創建系統生成文件名的記錄。 如果還有用戶指定的 alias,則該alias文件名也將加入到alias directory
ASM將該文件標記為創建成功的,并刪除回滾記錄
由于提交創建也將關閉文件,故 ASM實例告訴數據庫ASMB進程要釋放其extent map
ASM前臺進程返回一個成功創建文件的信息給數據庫進程。 數據庫進程關閉到ASM實例的連接,其將終止對應的ASM前臺進程
以上文件被成功創建并可以被任何進程打開了
Extent Allocation 盤區分配
分配盤區Allocating extents,將文件均勻地發布在disk Group中的所有磁盤上。 每一個磁盤有一個權重,這個權重是基于其大小的。extent set下屬的data extents必須分配在disk partnerships之間。 每一個extent set的primary extent分配時會按照磁盤的權重來分布文件。則文件的下一個primary extent將盡可能分配在那些使文件分布更平衡的磁盤上。這樣同一個文件在同一個磁盤上的primary extent會盡可能遠。
對于Normal 或者 high redundancy的 文件的secondary extents必須為primary extent多冗余拷貝而分配。secondary extents理想是均勻分布在primary extent所在盤的partners disk上,同樣也要基于磁盤權重。對于high redundancy還有一個要求,就是2個secondary extents需要分配在不同的failure group上。
FILE Delete ASM文件刪除
ASM上的文件可以通過 數據庫實例 或者在ASM實例中輸入一條SQL命令來刪除。 數據庫實例可以通過連接池中的slave進程來發送一個delete 刪除請求。若該文件還處于打開狀態則文件暫時不能刪除。 針對一個打開的文件,每一個ASM實例將持有一個全局鎖來避免其被刪除。 回滾記錄也將介入,以保證如果刪除開始,其必須完成。
FILE OPEN ASM文件打開
當一個數據庫實例下的進程打開一個ASM 文件時,它會使用連接池slave進程來發送請求給ASM實例。 ASM前臺進程會查看alias directory下的文件,或使用系統生成的文件名中的文件號和incarnation信息。 ASM前臺進程獲取文件鎖并發送extent map給數據庫的 ASMB進程,并存在SGA中。 一旦extent map加載成功,ASM將返回成功信息給數據庫進程。 數據庫進程使用extent map來將文件訪問轉換為適合的磁盤IO。每一個extent指針存有一個check檢測值,來捕獲是否存在損壞的extent map。
若果數據庫實例的一個進程打開一個文件,則其他進程可以使用同一個extent map。因此僅僅有第一個進程需要與ASM 實例聯系。數據庫實例的其他進程是坐享其成的。
FILE Close 關閉文件
當數據庫實例中的所有進程均關閉了一個文件,則connection pool連接池slave進程將發送一個close信息給ASM實例。 ASM實例會通知數據庫的ASMB進程要關閉extent map和釋放extent map所占內存。當ASMB關閉進程后其將釋放文件鎖。
I/O 錯誤
Normal或者 high redundancy的disk group可以容忍多種 IO錯誤。 處理這些IO錯誤的方式 基于 I/O的類型:是讀還是寫?以及 其I/O 的原因。 最常見的處理方式是當發生I/O錯誤則將問題磁盤OFFLINE掉。 如果將磁盤OFFLINE掉將造成部分數據不可用,則強制性的Disk Group Dismount將被發動。 這樣做則從其他節點或者待問題修復后,嘗試恢復重新寫入變得可能。 在external redundancy下磁盤不能被offline。 normal redundancy下2個互為partners的磁盤不能同時OFFLINE。high redundancy下2個partners可以OFFLINE,其他partners不能再OFFLINE。 如果一個錯誤引發disk group被強制dismount,則沒有磁盤將被OFFLINE。如果normal disk group下2份數據寫入都有問題,則也不會吧磁盤OFFLINE。
一個磁盤要OFFLINE的話,首先要求所有的數據庫實例和ASM實例均在自己的SGA中將其標記為OFFLINE的,避免其仍正在被讀取。 由于 I/O錯誤導致磁盤OFFLINE的行為,直到所有進程均停止讀取該磁盤才被認為是完成的。
ASM FILE read 文件讀取
注意文件數據的讀取仍是數據庫實例自己完成的,而不是ASM實例。 典型情況下總是讀取primary extent除非對應的磁盤OFFLINE了。 如果primary extent 所在磁盤OFFLINE了或者讀取失敗了,則會使用secondary extents。 如果primary 和 secondary extents都讀取失敗,則一個I/O錯誤將返回給 client。 文件讀取失敗一般不會造成磁盤OFFLINE或者disk group dismount。
ASM FILE Write 寫文件
文件數據寫入同樣仍由數據庫實例自己完成,而非ASM實例。若任何寫出發生IO錯誤,則該錯誤將通過connection pool slave連接池子進程發送給ASM實例。 ASM實例要么把磁盤OFFLINE,要么dismount diskgroup,且通過ASMB的連接來更新磁盤狀態。 數據庫進程或者重新發起之前的寫出。由于寫出不會再寫到OFFLINE的磁盤上,所以重試寫出一般會成功,除非diskgroup也給dismount了。
Instance Recovery實例恢復
ASM實例恢復instance recovery 與數據庫實例恢復很類似。最大的區別在于ASM實例會mount多個disk group,且不同的disk group又可以為多個實例所用。Instance recovery是基于每一個disk group為基礎的。在RAC中若一個實例強制dismount了一個disk group,則另一個ASM實例必須做該disk group的instance recovery,甚至于之前dismount該diskgroup的實例沒有終止。ASM實例只為其已經 mount的disk group做instance recovery。RAC中,如果一個ASM實例已經mount了2個disk group且意外崩潰了,則這2個disk group的恢復工作可能有集群的其他ASM實例來完成。
instance recovery實例恢復首先掃描ACD中的redo來構建需要做恢復的塊的列表。 redo將被應用到塊,塊將被寫回到diskgroup中。 之后新的鎖可以被請求以便訪問diskgroup上的元數據metadata。注意ASM實例的instance recovery僅僅與 ASM metadata有關。 文件中的數據還是由數據庫實例自己恢復的。
在redo應用之后正執行該instance recovery的ASM實例將檢測COD中的數據,如果之前有rebalance正在之前崩潰的實例中運行的話, 則考慮如果必要重啟該 rebalance 。 之前崩潰的ASM實例所留下的任意回滾操作都將被完成。
Rebalance
當一個或者多個磁盤 被 加入,drop,或者resize時disk group要做rebalance來保證所有存儲均勻地使用。Rebalance移動數據的依據不是 I/O統計信息,也不是其他統計的結果。 完全基于disk group中各個磁盤的大小。當存儲配置發生變化時其自動開始,當然也可以手動來發起。一般不推薦手動介入,需要手動介入的是當需要修改 rebalance power,或者將rebalance操作變換到其他節點上執行時。 手動介入時命令在哪個實例上執行,rebalance就發生在哪個實例上。
下面是rebalance 的簡要步驟:
Repartner 重新配對
當一個磁盤加入到diskgroup中時,其需要配對partners,這樣它本身存放數據的primary extent,其配對partners磁盤才能存儲鏡像拷貝。由于理想情況下每一個磁盤已經擁有了最大數目的配對partners,新增加磁盤配對關系的話往往意味著要打破一些現有的partners配對。 當正在drop磁盤時,其現有的配對關系partnerships將不得不被打破。這將造成一些磁盤的配對數目小于理想數。 因此rebalance的第一步是重新計算一個新的配對組合集合。 這個新的partnerships基于移動最少量數據的依據被選擇出來。這也是為什么最好增加和drop多個磁盤最好是同一時間發起的原因。
Calculate weights計算權重
rebalance的目標是讓disk group 中的每一個磁盤均以同樣的比例分配。因此更大的磁盤就要存放更多的文件數據。 這里會為每一個磁盤計算一個權重,來決定其上存放多少量的數據。權重受到磁盤大小和配對關系的影響。
Scan files 掃描文件
rebalance是一個文件、一個文件做的,文件的extent map將被掃描來判斷其應當如何平衡。為了實現平衡,現有的extent set可能被移動到其他磁盤上,以便歸于平衡。 這通常結果是移動到最新加入的磁盤中。也可能為了新的配對關系來做必要的移動。
Extent relocation 盤區移位
移位一個extent 是需要協調發生到該 extent上的任意I/O的。 集群中的所有ASM實例均會被通知開始移位的信息。 此信息也將被轉發給所有有打開該文件的數據庫實例的ASMB進程,這樣就鎖住了對應的extent。任何新的寫入到對應extent的操作將被阻塞, 但讀取則不被影響。當relocate操作結束后,已有的寫出操作將被重新觸發。 extent 盤區是被從舊的位置讀取并寫出到新的位置 基于1MB的I/O。在 relocation完成后解鎖的信息將傳達并包含有新的盤區指針。 extent map將被更新 且其上面lock的標記將被清楚。 任何未完成的寫入將被允許繼續工作。 任何活動的查詢將被重新觸發,原因是舊有的extent可能已經被其他數據重用了。
可能有多個slave進程在同一時間做relocation,power limit參數控制slave進程數目。
Restart重新開始
同時時間只能有一個 rebalance。若進行中的rebalance被打斷,那么其一般會自動重啟。若正在做rebalance的一個節點發生失敗,則rebalance將從其殘局重啟。如果管理員手動修改了power limit 也會引起重啟。如果在rebalance過程中發生了另一個存儲變更,則整個rebalance將從開頭重啟
Check Disk Group檢測磁盤組
check disk group 命令比對一個 disk group中的冗余數據結構來保證沒有損壞發生。 在檢測過程中數據結構將被鎖住,檢測中將發生下面的動作:
PST將被驗證來確保所有的配對關系是對稱的且有效的。 如果disk A以Disk B作為partner,則Disk B也是Disk A的partner。 如果Disk B不存在或者 Disk A不在Disk B的partner 列表上,則生成錯誤。 A和B當然在不同的failure groups上。
Extent Map 將對照allocation tables做檢查。所有在線的磁盤的allocation tables將被掃描,且extent map上每一個已經分配的AU將被確認。一個已經分配的 AU的allocation tables記錄指出了使用該AU的文件號和data extent信息。文件的extent map中的磁盤和AU信息將被驗證。如果文件不存在,或者extent map指向不同的AU,都將導致報錯。 同時檢測也會發現那些看上去已經被分配,但是不屬于任何文件的一部分的AU。
Allocation tables將對照Extent Map做檢查。所有文件的extent maps將被掃描,且每一個data extent的分配記錄將被確認指向了文件extent。data extent的extent map記錄給出了分配該extent的磁盤號和AU號。allocation table記錄將被驗證。 如果磁盤過小,或者AU實際上沒被分配,或者AU其實分配給了其他文件,或者AU其實是分配給其他extent的,都會導致報錯。 該檢測可以發現被分配了2次的AU,或者雖然標記為空閑但實際已經被使用的AU。
所有的extent set都對照著配對關系partnerships做一次驗證。每一個extent set中的每一個secondary extent都被驗證是否在含有primary extent的磁盤的partner上。 這將發現丟失配對關系的情況。
若以上任何問題發生,則將報錯,但檢測會持續下去。修復不一致往往需要靠手動操作,例如使用KFED。
相關文章鏈接:
Asm Instance Parameter Best Practice
為什么RHEL 6上沒有ASMLIB?
Unix上如何查看文件名開頭為”+asm”的TRACE文件
asm_power_limit對IO的影響
針對11.2 RAC丟失OCR和Votedisk所在ASM Diskgroup的恢復手段
10g ASM lost disk log
11gR2 RAC ASM啟動揭秘
在11gR2 RAC中修改ASM DISK Path磁盤路徑
在Linux 6上使用UDEV解決RAC ASM存儲設備名問題
Script:找出ASM中的Spfile參數文件
如何診斷ASMLIB故障
Script:收集ASM診斷信息
Comparation between ASM note [ID 373242.1] and note [ID 452924.1]
Why ASMLIB and why not?
ASM file metadata operation等待事件
幾個關于oracle 11g ASM的問題
利用UDEV服務解決RAC ASM存儲設備名
Discover Your Missed ASM Disks
Oracle內部視圖X$KFFXP
Fixed X$ Tables in ASM
了解AMDU工具生成的MAP文件
使用AMDU工具從無法MOUNT的DISKGROUP中抽取數據文件
深入了解Oracle ASM(一):基礎概念
About Me
...............................................................................................................................
● 本文整理自網絡 http://www.askmaclean.com/archives/know-oracle-asm-basic-html.html
● 本文在itpub(http://blog.itpub.net/26736162)、博客園(http://www.cnblogs.com/lhrbest)和個人微信公眾號(xiaomaimiaolhr)上有同步更新
● 本文itpub地址:http://blog.itpub.net/26736162/abstract/1/
● 本文博客園地址:http://www.cnblogs.com/lhrbest
● 本文pdf版及小麥苗云盤地址:http://blog.itpub.net/26736162/viewspace-1624453/
● 數據庫筆試面試題庫及解答:http://blog.itpub.net/26736162/viewspace-2134706/
● QQ群:230161599 微信群:私聊
● 聯系我請加QQ好友(646634621),注明添加緣由
● 于 2017-06-02 09:00 ~ 2017-06-30 22:00 在魔都完成
● 文章內容來源于小麥苗的學習筆記,部分整理自網絡,若有侵權或不當之處還請諒解
● 版權所有,歡迎分享本文,轉載請保留出處
...............................................................................................................................
拿起手機使用微信客戶端掃描下邊的左邊圖片來關注小麥苗的微信公眾號:xiaomaimiaolhr,掃描右邊的二維碼加入小麥苗的QQ群,學習最實用的數據庫技術。

免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。









