溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章將為大家詳細講解有關如何理解MYSQL-GroupCommit 和 2pc提交,文章內容質量較高,因此小編分享給大家做個參考,希望大家閱讀完這篇文章后對相關知識有一定的了解。
組提交(group commit)是MYSQL處理日志的一種優化方式,主要為了解決寫日志時頻繁刷磁盤的問題。組提交伴隨著MYSQL的發展不斷優化,從最初只支持redo log 組提交,到目前5.6官方版本同時支持redo log 和binlog組提交。組提交的實現大大提高了mysql的事務處理性能,將以innodb 存儲引擎為例,詳細介紹組提交在各個階段的實現原理。
redo log的組提交
WAL(Write-Ahead-Logging)是實現事務持久性的一個常用技術,基本原理是在提交事務時,為了避免磁盤頁面的隨機寫,只需要保證事務的redo log寫入磁盤即可,這樣可以通過redo log的順序寫代替頁面的隨機寫,并且可以保證事務的持久性,提高了數據庫系統的性能。雖然WAL使用順序寫替代了隨機寫,但是,每次事務提交,仍然需要有一次日志刷盤動作,受限于磁盤IO,這個操作仍然是事務并發的瓶頸。
組提交思想是,將多個事務redo log的刷盤動作合并,減少磁盤順序寫。Innodb的日志系統里面,每條redo log都有一個LSN(Log Sequence Number),LSN是單調遞增的。每個事務執行更新操作都會包含一條或多條redo log,各個事務將日志拷貝到log_sys_buffer時(log_sys_buffer 通過log_mutex
保護),都會獲取當前最大的LSN,因此可以保證不同事務的LSN不會重復。那么假設三個事務Trx1,Trx2和Trx3的日志的最大LSN分別為LSN1,LSN2,LSN3(LSN1<lsn2<lsn3),它們同時進行提交,那么如果trx3日志先獲取到log_mutex進行落盤,它就可以順便把[lsn1---lsn3]這段日志也刷了,這樣trx1和trx2就不用再次請求磁盤io。組提交的基本流程如下: </lsn2<lsn3),它們同時進行提交,那么如果trx3日志先獲取到log_mutex進行落盤,它就可以順便把[lsn1---lsn3]這段日志也刷了,這樣trx1和trx2就不用再次請求磁盤io。組提交的基本流程如下:<>
獲取 log_mutex
若flushed_to_disk_lsn>=lsn,表示日志已經被刷盤,跳轉5
若 current_flush_lsn>=lsn,表示日志正在刷盤中,跳轉5后進入等待狀態
將小于LSN的日志刷盤(flush and sync)
退出log_mutex
備注:lsn表示事務的lsn,flushed_to_disk_lsn和current_flush_lsn分別表示已刷盤的LSN和正在刷盤的LSN。
redo log 組提交優化
我們知道,在開啟binlog的情況下,prepare階段,會對redo log進行一次刷盤操作(innodb_flush_log_at_trx_commit=1),確保對data頁和undo 頁的更新已經刷新到磁盤;commit階段,會進行刷binlog操作(sync_binlog=1),并且會對事務的undo log從prepare狀態設置為提交狀態(可清理狀態)。通過兩階段提交方式(innodb_support_xa=1),可以保證事務的binlog和redo log順序一致。二階段提交過程中,mysql_binlog作為協調者,各個存儲引擎和mysql_binlog作為參與者。故障恢復時,掃描最后一個binlog文件(進行rotate binlog文件時,確保老的binlog文件對應的事務已經提交),提取其中的xid;重做檢查點以后的redo日志,讀取事務的undo段信息,搜集處于prepare階段的事務鏈表,將事務的xid與binlog中的xid對比,若存在,則提交,否則就回滾。
通過上述的描述可知,每個事務提交時,都會觸發一次redo flush動作,由于磁盤讀寫比較慢,因此很影響系統的吞吐量。淘寶童鞋做了一個優化,將prepare階段的刷redo動作移到了commit(flush-sync-commit)的flush階段之前,保證刷binlog之前,一定會刷redo。這樣就不會違背原有的故障恢復邏輯。移到commit階段的好處是,可以不用每個事務都刷盤,而是leader線程幫助刷一批redo。如何實現,很簡單,因為log_sys->lsn始終保持了當前最大的lsn,只要我們刷redo刷到當前的log_sys->lsn,就一定能保證,將要刷binlog的事務redo日志一定已經落盤。通過延遲寫redo方式,實現了redo log組提交的目的,而且減少了log_sys->mutex的競爭。目前這種策略已經被官方mysql5.7.6引入。
兩階段提交
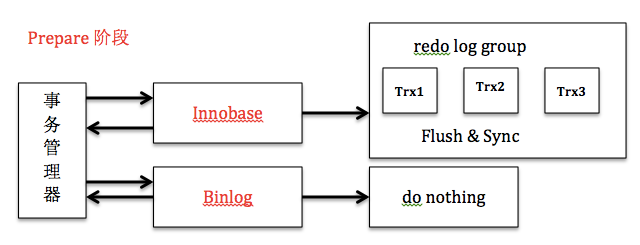
在單機情況下,redo log組提交很好地解決了日志落盤問題,那么開啟binlog后,binlog能否和redo log一樣也開啟組提交?首先開啟binlog后,我們要解決的一個問題是,如何保證binlog和redo log的一致性。因為binlog是Master-Slave的橋梁,如果順序不一致,意味著Master-Slave可能不一致。MYSQL通過兩階段提交很好地解決了這一問題。Prepare階段,innodb刷redo log,并將回滾段設置為Prepared狀態,binlog不作任何操作;commit階段,innodb釋放鎖,釋放回滾段,設置提交狀態,binlog刷binlog日志。出現異常,需要故障恢復時,若發現事務處于Prepare階段,并且binlog存在則提交,否則回滾。通過兩階段提交,保證了redo log和binlog在任何情況下的一致性。
binlog的組提交
回到上節的問題,開啟binlog后,如何在保證redo log-binlog一致的基礎上,實現組提交。因為這個問題,5.6以前,mysql在開啟binlog的情況下,無法實現組提交,通過一個臭名昭著的prepare_commit_mutex,將redo log和binlog刷盤串行化,串行化的目的也僅僅是為了保證redo log-Binlog一致,但這種實現方式犧牲了性能。這個情況顯然是不能容忍的,因此各個mysql分支,mariadb,facebook,perconal等相繼出了補丁改進這一問題,mysql官方版本5.6也終于解決了這一問題。由于各個分支版本解決方法類似,我主要通過分析5.6的實現來說明實現方法。
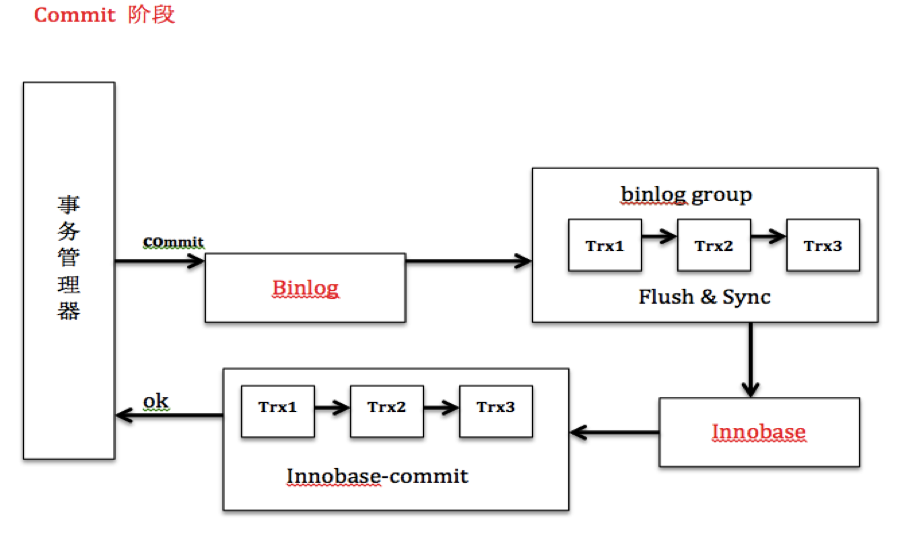
binlog組提交的基本思想是,引入隊列機制保證innodb commit順序與binlog落盤順序一致,并將事務分組,組內的binlog刷盤動作交給一個事務進行,實現組提交目的。binlog提交將提交分為了3個階段,FLUSH階段,SYNC階段和COMMIT階段。每個階段都有一個隊列,每個隊列有一個mutex保護,約定進入隊列第一個線程為leader,其他線程為follower,所有事情交由leader去做,leader做完所有動作后,通知follower刷盤結束。binlog組提交基本流程如下:
FLUSH 階段
1) 持有Lock_log mutex [leader持有,follower等待]
2) 獲取隊列中的一組binlog(隊列中的所有事務)
3) 將binlog buffer到I/O cache
4) 通知dump線程dump binlog
SYNC階段
1) 釋放Lock_log mutex,持有Lock_sync mutex[leader持有,follower等待]
2) 將一組binlog 落盤(sync動作,最耗時,假設sync_binlog為1)
COMMIT階段
1) 釋放Lock_sync mutex,持有Lock_commit mutex[leader持有,follower等待]
2) 遍歷隊列中的事務,逐一進行innodb commit
3) 釋放Lock_commit mutex
4) 喚醒隊列中等待的線程
說明:由于有多個隊列,每個隊列各自有mutex保護,隊列之間是順序的,約定進入隊列的一個線程為leader,因此FLUSH階段的leader可能是SYNC階段的follower,但是follower永遠是follower。
通過上文分析,我們知道MYSQL目前的組提交方式解決了一致性和性能的問題。通過二階段提交解決一致性,通過redo log和binlog的組提交解決磁盤IO的性能。下面我整理了Prepare階段和Commit階段的框架圖供各位參考。
參考文檔
http://mysqlmusings.blogspot.com/2012/06/binary-log-group-commit-in-mysql-56.html
http://www.lupaworld.com/portal.php?mod=view&aid=250169&page=all
http://www.oschina.net/question/12_89981
http://kristiannielsen.livejournal.com/12254.html
http://blog.chinaunix.net/uid-26896862-id-3432594.html
http://www.csdn.net/article/2015-01-16/2823591
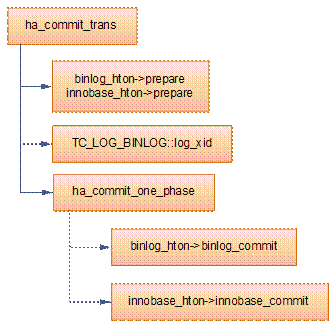
MySQL的事務提交邏輯主要在函數ha_commit_trans中完成。事務的提交涉及到binlog及具體的存儲的引擎的事務提交。所以MySQL用2PC來保證的事務的完整性。MySQL的2PC過程如下:

T@4 : | | | | >trans_commit T@4 : | | | | | enter: stmt.ha_list: , all.ha_list: T@4 : | | | | | debug: stmt.unsafe_rollback_flags: T@4 : | | | | | debug: all.unsafe_rollback_flags: T@4 : | | | | | >trans_check T@4 : | | | | | <trans_check 49 T@4 : | | | | | info: clearing SERVER_STATUS_IN_TRANS T@4 : | | | | | >ha_commit_trans T@4 : | | | | | | info: all=1 thd->in_sub_stmt=0 ha_info=0x0 is_real_trans=1 T@4 : | | | | | | >MYSQL_BIN_LOG::commit T@4 : | | | | | | | enter: thd: 0x2b9f4c07beb0, all: yes, xid: 0, cache_mngr: 0x0 T@4 : | | | | | | | >ha_commit_low T@4 : | | | | | | | | >THD::st_transaction::cleanup T@4 : | | | | | | | | | >free_root T@4 : | | | | | | | | | | enter: root: 0x2b9f4c07d660 flags: 1 T@4 : | | | | | | | | | <free_root 396 T@4 : | | | | | | | | <thd::st_transaction::cleanup 2521 T@4 : | | | | | | | <ha_commit_low 1535 T@4 : | | | | | | <mysql_bin_log::commit 6383 T@4 : | | | | | | >THD::st_transaction::cleanup T@4 : | | | | | | | >free_root T@4 : | | | | | | | | enter: root: 0x2b9f4c07d660 flags: 1 T@4 : | | | | | | | <free_root 396 T@4 : | | | | | | <thd::st_transaction::cleanup 2521 T@4 : | | | | | <ha_commit_trans 1458 T@4 : | | | | | debug: reset_unsafe_rollback_flags T@4 : | | | | <trans_commit 233</ha_commit_trans<> T@4 : | | | | >MDL_context::release_transactional_locks T@4 : | | | | | >MDL_context::release_locks_stored_before T@4 : | | | | | <mdl_context::release_locks_stored_before 2771 T@4 : | | | | | >MDL_context::release_locks_stored_before T@4 : | | | | | <mdl_context::release_locks_stored_before 2771 T@4 : | | | | <mdl_context::release_transactional_locks 2926 T@4 : | | | | >set_ok_status T@4 : | | | | <set_ok_status 446 T@4 : | | | | THD::enter_stage: /usr/src/mysql-5.6.28/sql/sql_parse.cc:4996 T@4 : | | | | >PROFILING::status_change T@4 : | | | | <profiling::status_change 354 T@4 : | | | | >trans_commit_stmt T@4 : | | | | | enter: stmt.ha_list: , all.ha_list: T@4 : | | | | | enter: stmt.ha_list: , all.ha_list: T@4 : | | | | | debug: stmt.unsafe_rollback_flags: T@4 : | | | | | debug: all.unsafe_rollback_flags: T@4 : | | | | | debug: add_unsafe_rollback_flags: 0 T@4 : | | | | | >MYSQL_BIN_LOG::commit
(1)先調用binglog_hton和innobase_hton的prepare方法完成第一階段,binlog_hton的papare方法實際上什么也沒做,innodb的prepare將事務狀態設為TRX_PREPARED,并將redo log刷磁盤 (innobase_xa_prepare à trx_prepare_for_mysql à trx_prepare_off_kernel)。
(2)如果事務涉及的所有存儲引擎的prepare都執行成功,則調用TC_LOG_BINLOG::log_xid將SQL語句寫到binlog,此時,事務已經鐵定要提交了。否則,調用ha_rollback_trans回滾事務,而SQL語句實際上也不會寫到binlog。
(3)最后,調用引擎的commit完成事務的提交。實際上binlog_hton->commit什么也不會做(因為(2)已經將binlog寫入磁盤),innobase_hton->commit則清除undo信息,刷redo日志,將事務設為TRX_NOT_STARTED狀態(innobase_commit à innobase_commit_low à trx_commit_for_mysql à trx_commit_off_kernel)。
//ha_innodb.cc static int innobase_commit( /*============*/ /* out: 0 */ THD* thd, /* in: MySQL thread handle of the user for whom the transaction should be committed */ bool all) /* in: TRUE - commit transaction FALSE - the current SQL statement ended */ { ... trx->mysql_log_file_name = mysql_bin_log.get_log_fname(); trx->mysql_log_offset = (ib_longlong)mysql_bin_log.get_log_file()->pos_in_file; ... } |
函數innobase_commit提交事務,先得到當前的binlog的位置,然后再寫入事務系統PAGE(trx_commit_off_kernel à trx_sys_update_mysql_binlog_offset)。
InnoDB將MySQL binlog的位置記錄到trx system header中:
//trx0sys.h /* The offset of the MySQL binlog offset info in the trx system header */ #define TRX_SYS_MYSQL_LOG_INFO (UNIV_PAGE_SIZE - 1000) #define TRX_SYS_MYSQL_LOG_MAGIC_N_FLD 0 /* magic number which shows if we have valid data in the MySQL binlog info; the value is ..._MAGIC_N if yes */ #define TRX_SYS_MYSQL_LOG_OFFSET_HIGH 4 /* high 4 bytes of the offset within that file */ #define TRX_SYS_MYSQL_LOG_OFFSET_LOW 8 /* low 4 bytes of the offset within that file */ #define TRX_SYS_MYSQL_LOG_NAME 12 /* MySQL log file name */ |
5.3.2 事務恢復流程
Innodb在恢復的時候,不同狀態的事務,會進行不同的處理(見trx_rollback_or_clean_all_without_sess函數):
<1>對于TRX_COMMITTED_IN_MEMORY的事務,清除回滾段,然后將事務設為TRX_NOT_STARTED;
<2>對于TRX_NOT_STARTED的事務,表示事務已經提交,跳過;
<3>對于TRX_PREPARED的事務,要根據binlog來決定事務的命運,暫時跳過;
<4>對于TRX_ACTIVE的事務,回滾。
MySQL在打開binlog時,會檢查binlog的狀態(TC_LOG_BINLOG::open)。如果binlog沒有正常關閉(LOG_EVENT_BINLOG_IN_USE_F為1),則進行恢復操作,基本流程如下:
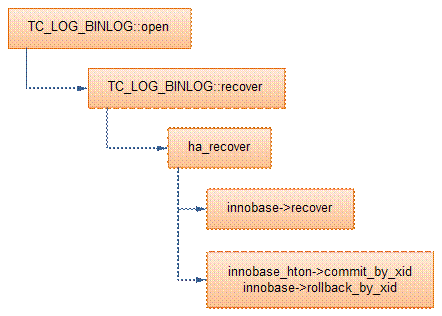
<1>掃描binlog,讀取XID_EVENT事務,得到所有已經提交的XA事務列表(實際上事務在innodb可能處于prepare或者commit);
<2>對每個XA事務,調用handlerton::recover,檢查存儲引擎是否存在處于prepare狀態的該事務(見innobase_xa_recover),也就是檢查該XA事務在存儲引擎中的狀態;
<3>如果存在處于prepare狀態的該XA事務,則調用handlerton::commit_by_xid提交事務;
<4>否則,調用handlerton::rollback_by_xid回滾XA事務。
5.3.3 幾個參數討論
(1)sync_binlog
Mysql在提交事務時調用MYSQL_LOG::write完成寫binlog,并根據sync_binlog決定是否進行刷盤。默認值是0,即不刷盤,從而把控制權讓給OS。如果設為1,則每次提交事務,就會進行一次刷盤;這對性能有影響(5.6已經支持binlog group),所以很多人將其設置為100。
bool MYSQL_LOG::flush_and_sync()
{
int err=0, fd=log_file.file;
safe_mutex_assert_owner(&LOCK_log);
if (flush_io_cache(&log_file))
return 1;
if (++sync_binlog_counter >= sync_binlog_period && sync_binlog_period)
{
sync_binlog_counter= 0;
err=my_sync(fd, MYF(MY_WME));
}
return err;
}
(2) innodb_flush_log_at_trx_commit
該參數控制innodb在提交事務時刷redo log的行為。默認值為1,即每次提交事務,都進行刷盤操作。為了降低對性能的影響,在很多生產環境設置為2,甚至0。
trx_flush_log_if_needed_low( /*========================*/ lsn_t lsn) /*!< in: lsn up to which logs are to be
flushed. */ { switch (srv_flush_log_at_trx_commit) { case 0: /* Do nothing */ break; case 1: /* Write the log and optionally flush it to disk */ log_write_up_to(lsn, LOG_WAIT_ONE_GROUP,
srv_unix_file_flush_method != SRV_UNIX_NOSYNC); break; case 2: /* Write the log but do not flush it to disk */ log_write_up_to(lsn, LOG_WAIT_ONE_GROUP, FALSE); break; default:
ut_error;
}
}
If the value of innodb_flush_log_at_trx_commit is 0, the log buffer is written out to the log file once per second and the flush to disk operation is performed on the log file, but nothing is done at a transaction commit. When the value is 1 (the default), the log buffer is written out to the log file at each transaction commit and the flush to disk operation is performed on the log file. When the value is 2, the log buffer is written out to the file at each commit, but the flush to disk operation is not performed on it. However, the flushing on the log file takes place once per second also when the value is 2. Note that the once-per-second flushing is not 100% guaranteed to happen every second, due to process scheduling issues.
The default value of 1 is required for full ACID compliance. You can achieve better performance by setting the value different from 1, but then you can lose up to one second worth of transactions in a crash. With a value of 0, any mysqld process crash can erase the last second of transactions. With a value of 2, only an operating system crash or a power outage can erase the last second of transactions.
(3) innodb_support_xa
用于控制innodb是否支持XA事務的2PC,默認是TRUE。如果關閉,則innodb在prepare階段就什么也不做;這可能會導致binlog的順序與innodb提交的順序不一致(比如A事務比B事務先寫binlog,但是在innodb內部卻可能A事務比B事務后提交),這會導致在恢復或者slave產生不同的數據。
int
innobase_xa_prepare(
/*================*/
/* out: 0 or error number */
THD* thd, /* in: handle to the MySQL thread of the user
whose XA transaction should be prepared */
bool all) /* in: TRUE - commit transaction
FALSE - the current SQL statement ended */
{
…
if (!thd->variables.innodb_support_xa) {
return(0);
}
ver mysql 5.7
bool trans_xa_commit(THD *thd)
{ bool res= TRUE; enum xa_states xa_state= thd->transaction.xid_state.xa_state;
DBUG_ENTER("trans_xa_commit"); if (!thd->transaction.xid_state.xid.eq(thd->lex->xid))
{ /* xid_state.in_thd is always true beside of xa recovery procedure.
Note, that there is no race condition here between xid_cache_search
and xid_cache_delete, since we always delete our own XID
(thd->lex->xid == thd->transaction.xid_state.xid).
The only case when thd->lex->xid != thd->transaction.xid_state.xid
and xid_state->in_thd == 0 is in the function
xa_cache_insert(XID, xa_states), which is called before starting
client connections, and thus is always single-threaded. */ XID_STATE *xs= xid_cache_search(thd->lex->xid);
res= !xs || xs->in_thd; if (res)
my_error(ER_XAER_NOTA, MYF(0)); else {
res= xa_trans_rolled_back(xs);
ha_commit_or_rollback_by_xid(thd, thd->lex->xid, !res);
xid_cache_delete(xs);
}
DBUG_RETURN(res);
} if (xa_trans_rolled_back(&thd->transaction.xid_state))
{
xa_trans_force_rollback(thd);
res= thd->is_error();
} else if (xa_state == XA_IDLE && thd->lex->xa_opt == XA_ONE_PHASE)
{ int r= ha_commit_trans(thd, TRUE); if ((res= MY_TEST(r)))
my_error(r == 1 ? ER_XA_RBROLLBACK : ER_XAER_RMERR, MYF(0));
} else if (xa_state == XA_PREPARED && thd->lex->xa_opt == XA_NONE)
{
MDL_request mdl_request; /* Acquire metadata lock which will ensure that COMMIT is blocked
by active FLUSH TABLES WITH READ LOCK (and vice versa COMMIT in
progress blocks FTWRL).
We allow FLUSHer to COMMIT; we assume FLUSHer knows what it does. */ mdl_request.init(MDL_key::COMMIT, "", "", MDL_INTENTION_EXCLUSIVE,
MDL_TRANSACTION); if (thd->mdl_context.acquire_lock(&mdl_request,
thd->variables.lock_wait_timeout))
{
ha_rollback_trans(thd, TRUE);
my_error(ER_XAER_RMERR, MYF(0));
} else {
DEBUG_SYNC(thd, "trans_xa_commit_after_acquire_commit_lock"); if (tc_log)
res= MY_TEST(tc_log->commit(thd, /* all */ true)); else res= MY_TEST(ha_commit_low(thd, /* all */ true)); if (res)
my_error(ER_XAER_RMERR, MYF(0));
}
} else {
my_error(ER_XAER_RMFAIL, MYF(0), xa_state_names[xa_state]);
DBUG_RETURN(TRUE);
}
thd->variables.option_bits&= ~OPTION_BEGIN;
thd->transaction.all.reset_unsafe_rollback_flags();
thd->server_status&=
~(SERVER_STATUS_IN_TRANS | SERVER_STATUS_IN_TRANS_READONLY);
DBUG_PRINT("info", ("clearing SERVER_STATUS_IN_TRANS"));
xid_cache_delete(&thd->transaction.xid_state);
thd->transaction.xid_state.xa_state= XA_NOTR;
DBUG_RETURN(res);
}
5.3.4 安全性/性能討論
上面3個參數不同的值會帶來不同的效果。三者都設置為1(TRUE),數據才能真正安全。sync_binlog非1,可能導致binlog丟失(OS掛掉),從而與innodb層面的數據不一致。innodb_flush_log_at_trx_commit非1,可能會導致innodb層面的數據丟失(OS掛掉),從而與binlog不一致。
關于性能分析,可以參考
http://www.mysqlperformanceblog.com/2011/03/02/what-is-innodb_support_xa/
http://www.mysqlperformanceblog.com/2009/01/21/beware-ext3-and-sync-binlog-do-not-play-well-together/
在事務提交時innobase會調用ha_innodb.cc 中的innobase_commit,而innobase_commit通過調用trx_commit_complete_for_mysql(trx0trx.c)來調用log_write_up_to(log0log.c),也就是當innobase提交事務的時候就會調用log_write_up_to來寫redo log
innobase_commit中 if (all # 如果是事務提交 || (!thd_test_options(thd, OPTION_NOT_AUTOCOMMIT | OPTION_BEGIN))) {
通過下面的代碼實現事務的commit串行化 if (innobase_commit_concurrency > 0) {
pthread_mutex_lock(&commit_cond_m);
commit_threads++; if (commit_threads > innobase_commit_concurrency) {
commit_threads--;
pthread_cond_wait(&commit_cond, &commit_cond_m);
pthread_mutex_unlock(&commit_cond_m); goto retry;
} else {
pthread_mutex_unlock(&commit_cond_m);
}
}
trx->flush_log_later = TRUE; # 在做提交操作時禁止flush binlog 到磁盤
innobase_commit_low(trx);
trx->flush_log_later = FALSE;
先略過innobase_commit_low調用 ,下面開始調用trx_commit_complete_for_mysql做write日志操作
trx_commit_complete_for_mysql(trx); #開始flush log
trx->active_trans = 0;
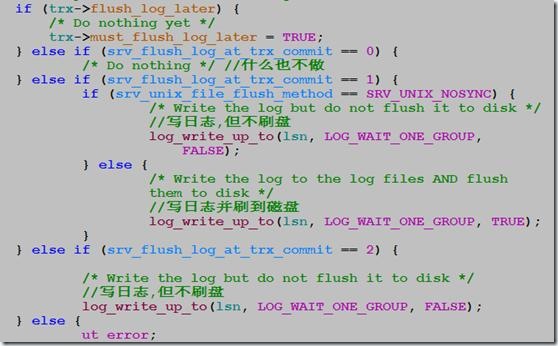
在trx_commit_complete_for_mysql中,主要做的是對系統參數srv_flush_log_at_trx_commit值做判斷來調用
log_write_up_to,或者write redo log file或者write&&flush to disk if (!trx->must_flush_log_later) { /* Do nothing */ } else if (srv_flush_log_at_trx_commit == 0) { #flush_log_at_trx_commit=0,事務提交不寫redo log /* Do nothing */ } else if (srv_flush_log_at_trx_commit == 1) { #flush_log_at_trx_commit=1,事務提交寫log并flush磁盤,如果flush方式不是SRV_UNIX_NOSYNC (這個不是很熟悉) if (srv_unix_file_flush_method == SRV_UNIX_NOSYNC) { /* Write the log but do not flush it to disk */ log_write_up_to(lsn, LOG_WAIT_ONE_GROUP, FALSE);
} else { /* Write the log to the log files AND flush them to
disk */ log_write_up_to(lsn, LOG_WAIT_ONE_GROUP, TRUE);
}
} else if (srv_flush_log_at_trx_commit == 2) { #如果是2,則只write到redo log /* Write the log but do not flush it to disk */ log_write_up_to(lsn, LOG_WAIT_ONE_GROUP, FALSE);
} else {
ut_error;
}
那么下面看log_write_up_to if (flush_to_disk #如果flush到磁盤,則比較當前commit的lsn是否大于已經flush到磁盤的lsn && ut_dulint_cmp(log_sys->flushed_to_disk_lsn, lsn) >= 0) {
mutex_exit(&(log_sys->mutex)); return;
} if (!flush_to_disk #如果不flush磁盤則比較當前commit的lsn是否大于已經寫到所有redo log file的lsn,或者在只等一個group完成條件下是否大于已經寫到某個redo file的lsn && (ut_dulint_cmp(log_sys->written_to_all_lsn, lsn) >= 0 || (ut_dulint_cmp(log_sys->written_to_some_lsn, lsn) >= 0 && wait != LOG_WAIT_ALL_GROUPS))) {
mutex_exit(&(log_sys->mutex)); return;
}
#下面的代碼判斷是否log在write,有的話等待其完成 if (log_sys->n_pending_writes > 0) { if (flush_to_disk # 如果需要刷新到磁盤,如果正在flush的lsn包括了commit的lsn,只要等待操作完成就可以了 && ut_dulint_cmp(log_sys->current_flush_lsn, lsn) >= 0) { goto do_waits;
} if (!flush_to_disk # 如果是刷到redo log file的那么如果在write的lsn包括了commit的lsn,也只要等待就可以了 && ut_dulint_cmp(log_sys->write_lsn, lsn) >= 0) { goto do_waits;
}
...... if (!flush_to_disk # 如果在當前IO空閑情況下 ,而且不需要flush到磁盤,那么 如果下次寫的位置已經到達buf_free位置說明wirte操作都已經完成了,直接返回 && log_sys->buf_free == log_sys->buf_next_to_write) {
mutex_exit(&(log_sys->mutex)); return;
}
下面取到group,設置相關write or flush相關字段,并且得到起始和結束位置的block號
log_sys->n_pending_writes++;
group = UT_LIST_GET_FIRST(log_sys->log_groups);
group->n_pending_writes++; /* We assume here that we have only
one log group! */ os_event_reset(log_sys->no_flush_event);
os_event_reset(log_sys->one_flushed_event);
start_offset = log_sys->buf_next_to_write;
end_offset = log_sys->buf_free;
area_start = ut_calc_align_down(start_offset, OS_FILE_LOG_BLOCK_SIZE);
area_end = ut_calc_align(end_offset, OS_FILE_LOG_BLOCK_SIZE);
ut_ad(area_end - area_start > 0);
log_sys->write_lsn = log_sys->lsn; if (flush_to_disk) {
log_sys->current_flush_lsn = log_sys->lsn;
}
log_block_set_checkpoint_no調用設置end_offset所在block的LOG_BLOCK_CHECKPOINT_NO為log_sys中下個檢查點號
log_block_set_flush_bit(log_sys->buf + area_start, TRUE); # 這個沒看明白
log_block_set_checkpoint_no(
log_sys->buf + area_end - OS_FILE_LOG_BLOCK_SIZE,
log_sys->next_checkpoint_no);
保存不屬于end_offset但在其所在的block中的數據到下一個空閑的block
ut_memcpy(log_sys->buf + area_end,
log_sys->buf + area_end - OS_FILE_LOG_BLOCK_SIZE,
OS_FILE_LOG_BLOCK_SIZE);
對于每個group調用log_group_write_buf寫redo log buffer while (group) {
log_group_write_buf(
group, log_sys->buf + area_start,
area_end - area_start,
ut_dulint_align_down(log_sys->written_to_all_lsn,
OS_FILE_LOG_BLOCK_SIZE),
start_offset - area_start);
log_group_set_fields(group, log_sys->write_lsn); # 計算這次寫的lsn和offset來設置group->lsn和group->lsn_offset
group = UT_LIST_GET_NEXT(log_groups, group);
}
...... if (srv_unix_file_flush_method == SRV_UNIX_O_DSYNC) { # 這個是什么東西 /* O_DSYNC means the OS did not buffer the log file at all:
so we have also flushed to disk what we have written */ log_sys->flushed_to_disk_lsn = log_sys->write_lsn;
} else if (flush_to_disk) {
group = UT_LIST_GET_FIRST(log_sys->log_groups);
fil_flush(group->space_id); # 最后調用fil_flush執行flush到磁盤
log_sys->flushed_to_disk_lsn = log_sys->write_lsn;
}
接下來看log_group_write_buf做了點什么
在log_group_calc_size_offset中,從group中取到上次記錄的lsn位置(注意是log files組成的1個環狀buffer),并計算這次的lsn相對于上次的差值
# 調用log_group_calc_size_offset計算group->lsn_offset除去多個LOG_FILE頭部長度后的大小,比如lsn_offset落在第3個log file上,那么需要減掉3*LOG_FILE_HDR_SIZE的大小
gr_lsn_size_offset = (ib_longlong)
log_group_calc_size_offset(group->lsn_offset, group);
group_size = (ib_longlong) log_group_get_capacity(group); # 計算group除去所有LOG_FILE_HDR_SIZE長度后的DATA部分大小
# 下面是典型的環狀結構差值計算 if (ut_dulint_cmp(lsn, gr_lsn) >= 0) {
difference = (ib_longlong) ut_dulint_minus(lsn, gr_lsn);
} else {
difference = (ib_longlong) ut_dulint_minus(gr_lsn, lsn);
difference = difference % group_size;
difference = group_size - difference;
}
offset = (gr_lsn_size_offset + difference) % group_size;
# 最后算上每個log file 頭部大小,返回真實的offset return(log_group_calc_real_offset((ulint)offset, group));
接著看
# 如果需要寫的內容超過一個文件大小 if ((next_offset % group->file_size) + len > group->file_size) {
write_len = group->file_size # 寫到file末尾 - (next_offset % group->file_size);
} else {
write_len = len; # 否者寫len個block
}
# 最后真正的內容就是寫buffer了,如果跨越file的話另外需要寫file log file head部分 if ((next_offset % group->file_size == LOG_FILE_HDR_SIZE) && write_header) { /* We start to write a new log file instance in the group */ log_group_file_header_flush(group,
next_offset / group->file_size,
start_lsn);
srv_os_log_written+= OS_FILE_LOG_BLOCK_SIZE;
srv_log_writes++;
}
# 調用fil_io來執行buffer寫 if (log_do_write) {
log_sys->n_log_ios++;
srv_os_log_pending_writes++;
fil_io(OS_FILE_WRITE | OS_FILE_LOG, TRUE, group->space_id,
next_offset / UNIV_PAGE_SIZE,
next_offset % UNIV_PAGE_SIZE, write_len, buf, group);
srv_os_log_pending_writes--;
srv_os_log_written+= write_len;
srv_log_writes++;
然而我們考慮如下序列(Copy from worklog…)
Trx1 ------------P----------C--------------------------------> | Trx2 ----------------P------+---C----------------------------> | | Trx3 -------------------P---+---+-----C----------------------> | | | Trx4 -----------------------+-P-+-----+----C-----------------> | | | | Trx5 -----------------------+---+-P---+----+---C-------------> | | | | | Trx6 -----------------------+---+---P-+----+---+---C----------> | | | | | | Trx7 -----------------------+---+-----+----+---+-P-+--C-------> | | | | | | |
在之前的邏輯中,trx5 和 trx6是可以并發執行的,因為他們擁有相同的序列號;Trx4無法和Trx5并行,因為他們的序列號不同。同樣的trx6和trx7也無法并行。當發現一個無法并發的事務時,就需要等待前面的事務執行完成才能繼續下去,這會影響到備庫的TPS。
但是理論上trx4應該可以和trx5和trx6并行,因為trx4先于trx5和trx6 prepare,如果trx5 和trx6能進入Prepare階段,證明其和trx4是沒有沖突的。
解決方案:
0.增加兩個全局變量:
/* Committed transactions timestamp */
Logical_clock max_committed_transaction;
/* "Prepared" transactions timestamp */
Logical_clock transaction_counter;
每個事務對應兩個counter:last_committed 及 sequence_number
1.每次rotate或打開新的binlog時
MYSQL_BIN_LOG::open_binlog:
max_committed_transaction.update_offset(transaction_counter.get_timestamp());
transaction_counter.update_offset(transaction_counter.get_timestamp());
—>更新max_committed_transaction和transaction_counter的offset為當前的state值(或者說,為上個Binlog文件最大的transaction counter值)
2.每執行一條DML語句完成時,更新當前會話的last_committed= mysql_bin_log.max_committed_transaction
參考函數: binlog_prepare (參數all為false)
3. 事務提交時,寫入binlog之前
binlog_cache_data::flush:
trn_ctx->sequence_number= mysql_bin_log.transaction_counter.step();
其中transaction_counter遞增1
4.寫入binlog
將sequence_number 和 last_committed寫入binlog
MYSQL_BIN_LOG::write_gtid
記錄binlog文件的seq number 和last committed會減去max_committed_transaction.get_offset(),也就是說,每個Binlog文件的序列號總是從(last_committed, sequence_number)=(0,1)開始
5.引擎層提交每個事務前更新max_committed_transaction
如果當前事務的sequence_number大于max_committed_transaction,則更新max_committed_transaction的值
MYSQL_BIN_LOG::process_commit_stage_queue –> MYSQL_BIN_LOG::update_max_committed
6.備庫并發檢查
函數:Mts_submode_logical_clock::schedule_next_event
假設初始狀態下transaction_counter=1, max_committed_transaction=1, 以上述流程為例,每個事務的<last_committed, sequence_number>序列為:
Trx1 prepare: last_commited = max_committed_transaction = 1;
Trx2 prepare: last_commited = max_committed_transaction = 1;
Trx3 prepare: last_commited = max_committed_transaction = 1;
Trx1 commit: sequence_number=++transaction_counter = 2, (transaction_counter=2, max_committed_transaction=2), write(1,2)
Trx4 prepare: last_commited =max_committed_transaction = 2;
Trx2 commit: sequence_number=++transaction_counter= 3, (transaction_counter=3, max_committed_transaction=3), write(1,3)
Trx5 prepare: last_commited = max_committed_transaction = 3;
Trx6 prepare: last_commited = max_committed_transaction = 3;
Trx3 commit: sequence_number=++transaction_counter= 4, (transaction_counter=4, max_committed_transaction=4), write(1,4)
Trx4 commit: sequence_number=++transaction_counter= 5, (transaction_counter=5, max_committed_transaction=5), write(2, 5)
Trx5 commit: sequence_number=++transaction_counter= 6, (transaction_counter=6, max_committed_transaction=6), write(3, 6)
Trx7 prepare: last_commited = max_committed_transaction = 6;
Trx6 commit: sequence_number=++transaction_counter= 7, (transaction_counter=7, max_committed_transaction=7), write(3, 7)
Trx7 commit: sequence_number=++transaction_counter= 8, (transaction_counter=8, max_committed_transaction=8), write(6, 8)
并發規則:
因此上述序列中可以并發的序列為:
trx1 1…..2
trx2 1………….3
trx3 1…………………….4
trx4 2………………………….5
trx5 3………………………………..6
trx6 3………………………………………………7
trx7 6……………………..8
備庫并行規則:當分發一個事務時,其last_committed 序列號比當前正在執行的事務的最小sequence_number要小時,則允許執行。
因此,
a)trx1執行,last_commit<2的可并發,trx2, trx3可繼續分發執行
b)trx1執行完成后,last_commit < 3的可以執行, trx4可分發
c)trx2執行完成后,last_commit < 4的可以執行, trx5, trx6可分發
d)trx3、trx4、trx5完成后,last_commit < 7的可以執行,trx7可分發
關于如何理解MYSQL-GroupCommit 和 2pc提交就分享到這里了,希望以上內容可以對大家有一定的幫助,可以學到更多知識。如果覺得文章不錯,可以把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





