溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
【演講實錄】銀行PB級別海量非結構化數據管理實踐
郝大為
近期,巨杉數據庫的技術總監郝大為受邀在第七屆數據技術嘉年華中做了“銀行PB級別海量非結構化數據管理實踐”為主題的演講,分享了巨杉數據庫有關金融行業數據庫管理以及金融級數據庫技術與應用的一些實踐及思考。
數據爆炸:數據呈現急劇增長,對數據存儲的數據量,并發性和響應速度都提出了更高要求。以大型商業銀行為例,通常它們擁有成百上千個業務系統以及上億用戶的海量數據,且數量呈現指數級增長,從TB級別增加到PB級別,未來很快就會增加至EB級別,這些都需要有效的管理以及實現實時訪問。
數據融合:不僅是金融行業,在過去,各個業務的數據都是以孤島的形式獨立存在,而我們需要的是跨業務、跨業務系統的數據統一管理和維護,甚至需要統一架構支撐下的數據溝通交流。打破數據孤島就成為金融行業的切實需求。

非結構化數據:非結構數據在金融行業數據量上的占比逐漸占絕對優勢的一種數據存在的形式。圖像、圖片、語音、有格式的文檔都是非結構化數據,非結構化數據量每年增長80%左右。數據量的快速增加,再加上對銀行業兩地三中心數據安全的要求,對非結構化數據的存儲和管理的要求就提高了。這也是金融業的行業需求。
隨著銀行遠程開戶、柜面無紙化、雙錄、會計檔案管理等系統的建立和升級,影像系統除了滿足商業銀行在線業務系統不斷提升的訪問性能需求外,還需要提供作為在線系統的高可用、災備甚至“雙活”能力,以保證系統數據絕對安全。
金融級數據庫核心能力
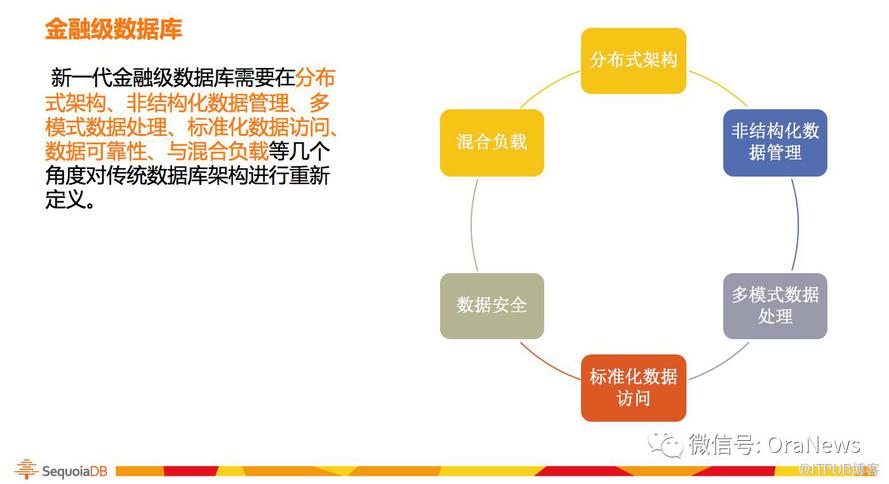
面對金融行業的新需求,新一代金融級數據庫需要在分布式架構、非結構化數據管理、多模式數據處理、標準化數據訪問、數據可靠性、與混合負載等幾個角度對傳統數據庫架構進行重新定義。
1)分布式架構
由于傳統數據庫的單點架構無法滿足新型金融科技應用對數據量與并發能力的需求,新一代金融級數據庫必須采用分布式架構來應對該類挑戰。分布式架構,將海量數據均勻存儲在多臺物理設備中,以避免單一設備所造成的瓶頸。同時,分布式數據庫的靈活擴展能力,為金融業務增長提供了彈性的容量與性能支持,在大規模數據應用中具有明顯的技術優勢。
我們以巨杉分布式架構為例,無論是數據還是文件系統等元數據都要進行分布式存儲,同時元數據的管理也應該是分布式、高可用、沒有單點故障的。分布式架構必須具備彈性拓展和性能線性增長,同事分布式架構可以有效降低TCO、總體應用成本。分布式架構有很好的管理能力,可以降低開發運維的成本。
2)多模式數據管理---非結構化數據管理
如今,在金融業務“互聯網化”和“零售化”的趨勢下,金融機構開始向用戶提供更多個性化、定制化的產品與服務。特別是非結構化數據,增長最為迅猛。
通常來說,結構化數據特指表單類型的數據存儲結構,典型應用包括銀行核心交易等傳統業務;而半結構化數據則在用戶畫像、物聯網設備日志采集、應用點擊流分析等場景中得到大規模使用;非結構化數據則對應著海量的的圖片、視頻、和文檔處理等業務,在金融科技的發展下增長迅速。
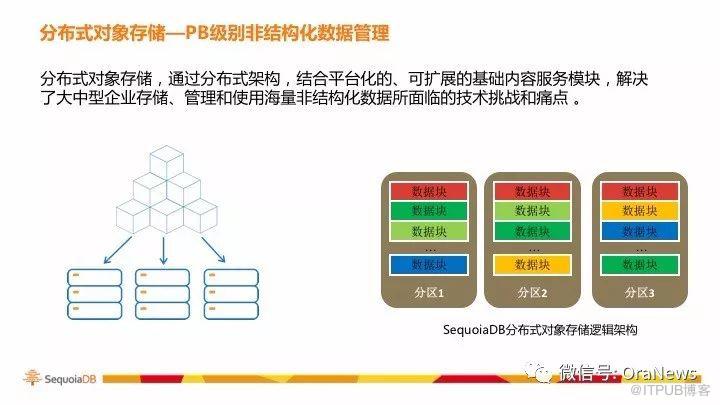
為了實現金融業務數據的統一管理和數據融合,新型數據庫需要具備多模式(Multi-Model)數據管理和存儲的能力,以滿足應用程序對于結構化、半結構化、非結構化數據的管理需求。
多模式數據管理能力,使得金融級數據庫能夠進行跨部門、跨業務的數據統一存儲與管理,實現多業務數據融合,支撐多樣化的金融服務。
3)標準數據訪問與混合負載
根據Gartner的最新定義,混合負載(HTAP Hybrid Transactional/Analytical Processing)在保留原有在線交易功能的同時,也強調了數據庫原生計算分析的能力。支持混合負載的數據庫能夠避免在傳統架構中,在線與離線數據庫之間大量的數據交互,同時也能夠針對最新的業務數據進行實時統計分析。

為了避免在線實時讀寫與批處理作業之間的資源干擾,混合負載型數據庫通常使用讀寫分離或內存處理技術實現。一般來說,分布式數據庫的多副本架構天然支持讀寫分離技術,而基于傳統架構的數據庫往往采用內存處理技術進行實現。
4)數據安全
伴隨著在企業內部價值的不斷提升,數據已經成為了金融企業的生命線與核心資產。作為承載著企業關鍵數據的數據庫,其安全性、可靠性、穩定性一直是金融級數據庫的核心價值。
數據安全領域重要的一個概念是容災能力,銀監會就要求銀行業要符合兩地三中心的要求。這其實是一個數據多副本的思想,任何一個副本丟失我們還有其他副本可以支撐數據管理的需求,數據服務的需求。這對于金融企業顯得尤其重要。
金融級數據庫應用案例
1)銀行業分布式影像平臺
銀行業影像平臺案例,是在某大型股份制銀行實施的,該平臺底層基于巨杉數據庫,目前已經投入生產。
巨杉數據庫適合于結構化、非結構化、半結構化數據存儲。在應用層面提供對外的影像文件管理服務能力,有兩臺或者更多臺具備負載均衡和高可用能力的應用服務器,服務器上對接的是銀行內部業務系統,當需要查非結構化數據時就可以接入影像管理平臺,巨杉數據庫支撐的是PB級的數據存儲,同時支持了高可用。
此外,巨杉數據庫支持多索引,毫秒級別實時數據訪問,這么大數據量下依然提供這么大的訪問性能,總體應用成本跟過去影像平臺對比可以降低三分之一,這是整個巨杉數據庫分布式的架構決定的。
2)證券超高并發數據訪問
證券交易主要特點是頻度高,每天可能有上億條交易數據。證券交易場景一般都是結構化數據,大量結構化數據進入系統提高高并發的結構能力。
這個系統可以幫助用戶查詢證券交易的所有歷史交易明細,并且查詢的返回速度依然很高,在海量數據情況下可能做到百毫秒以內的查詢范圍。
實現結果:
· 平均每日超過2億條記錄寫入
· 高峰時段,同時有超過百億級別的數據需要被檢索、調用
· 系統保存3年內所有交易和持有數據
· 峰值并發量超過10000
· 高峰時段,查詢返回時間小于100ms
3)銀行海量數據管理
關于銀行海量數據的管理平臺,實際上是銀行多業務系統的結構化數據組成一個統一的查詢平臺,用戶可以通過這個平臺去查詢業務,而不再需要查詢原有業務系統,這樣原有業務系統數據庫的負載就降下來了。原有業務系統數據庫只保存需要在線交易的那部分數據,其他的數據全部儲存在巨杉數據庫。
SequoiaDB利用其橫向擴展、支持標準SQL以及雙引擎的機制,能夠在存儲海量歷史數據的同時對外提供在線查詢與分析能力,這就使得銀行能將傳統的離線數據做到近線化,將冷數據有效地使用起來。
巨杉數據庫的多家銀行客戶使用SequoiaDB提供高并發的數據查詢和訪問功能,使銀行客戶能夠在柜臺、網銀、手機銀行上隨時隨地查詢開戶以來所有的交易歷史。同時,該平臺可以提供司法查詢的能力,使銀行IT部門不需要為了復雜多變的查詢請求,在歷史帶庫與數據庫之間疲于奔命。
4)其他案例
在政府行業,巨杉數據庫可以對電子證件進行集中存儲和查詢,可以幫助行政服務大廳或者其他政府部門查詢信息,提升工作的效率。
在交通領域,大量攝像頭實時采集的圖片和視頻數據需要存儲,并且現在還增加了實時處理分析套牌違規等行為,這背后也需要強大的數據存儲管理查詢或者存儲引擎支撐海量的數據,巨杉數據庫能夠有效滿足這種需求。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





