溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
單表優化
除非單表數據未來會一直不斷上漲,否則不要一開始就考慮拆分,拆分會帶來邏輯、部署、運維的各種復雜度。
一般以整型值為主的表在千萬級以下,字符串為主的表在五百萬以下是沒有太大問題的。
而事實上很多時候 MySQL 單表的性能依然有不少優化空間,甚至能正常支撐千萬級以上的數據量。
字段
關于字段:
盡量使用 TINYINT、SMALLINT、MEDIUM_INT作為整數類型而非 INT,如果非負則加上 UNSIGNED。
VARCHAR 的長度只分配真正需要的空間。
使用枚舉或整數代替字符串類型。
盡量使用 TIMESTAMP 而非 DATETIME。
單表不要有太多字段,建議在 20 以內。
避免使用 NULL 字段,很難查詢優化且占用額外索引空間。
用整型來存 IP。
索引
關于索引:
索引并不是越多越好,要根據查詢有針對性的創建,考慮在 WHERE 和 ORDER BY 命令上涉及的列建立索引,可根據 EXPLAIN 來查看是否用了索引還是全表掃描。
應盡量避免在 WHERE 子句中對字段進行 NULL 值判斷,否則將導致引擎放棄使用索引而進行全表掃描。
值分布很稀少的字段不適合建索引,例如“性別”這種只有兩三個值的字段。
字符字段只建前綴索引。
字符字段最好不要做主鍵。
不用外鍵,由程序保證約束。
盡量不用 UNIQUE,由程序保證約束。
使用多列索引時注意順序和查詢條件保持一致,同時刪除不必要的單列索引。
查詢 SQL
關于查詢 SQL:
可通過開啟慢查詢日志來找出較慢的 SQL。
不做列運算:SELECT id WHERE age + 1 = 10,任何對列的操作都將導致表掃描,它包括數據庫教程函數、計算表達式等等,查詢時要盡可能將操作移至等號右邊。
SQL 語句盡可能簡單:一條 SQL只能在一個 CPU 運算;大語句拆小語句,減少鎖時間;一條大 SQL 可以堵死整個庫。
不用SELECT *。
OR 改寫成 IN:OR 的效率是 n 級別,IN 的效率是 log(n) 級別,IN 的個數建議控制在 200 以內。
不用函數和觸發器,在應用程序實現。
避免 %xxx 式查詢。
少用 JOIN。
使用同類型進行比較,比如用 '123' 和 '123' 比,123 和 123 比。
盡量避免在 WHERE 子句中使用!=或<>操作符,否則引擎將放棄使用索引而進行全表掃描。
對于連續數值,使用 BETWEEN 不用 IN:SELECT id FROM t WHERE num BETWEEN 1 AND 5。
列表數據不要拿全表,要使用 LIMIT 來分頁,每頁數量也不要太大。
引擎
目前廣泛使用的是 MyISAM 和 InnoDB 兩種引擎:
MyISAM
MyISAM 引擎是 MySQL 5.1 及之前版本的默認引擎,它的特點是:
不支持行鎖,讀取時對需要讀到的所有表加鎖,寫入時則對表加排它鎖。
不支持事務。
不支持外鍵。
不支持崩潰后的安全恢復。
在表有讀取查詢的同時,支持往表中插入新紀錄。
支持 BLOB 和 TEXT 的前 500 個字符索引,支持全文索引。
支持延遲更新索引,極大提升寫入性能。
對于不會進行修改的表,支持壓縮表,極大減少磁盤空間占用。
InnoDB
InnoDB 在 MySQL 5.5 后成為默認索引,它的特點是:
支持行鎖,采用 MVCC 來支持高并發。
支持事務。
支持外鍵。
支持崩潰后的安全恢復。
不支持全文索引。
PS:據說 InnoDB 已經在 MySQL 5.6.4 支持全文索引了。
總體來講,MyISAM 適合 SELECT 密集型的表,而 InnoDB 適合 INSERT 和 UPDATE 密集型的表。
系統調優參數
可以使用下面幾個工具來做基準測試:
sysbench:一個模塊化,跨平臺以及多線程的性能測試工具。
https://github.com/akopytov/sysbench
iibench-mysql:基于 Java 的 MySQL / Percona / MariaDB 索引進行插入性能測試工具。
https://github.com/tmcallaghan/iibench-mysql
tpcc-mysql:Percona 開發的 TPC-C 測試工具。
https://github.com/Percona-Lab/tpcc-mysql
調優參數內容較多,具體可參考官方文檔,這里介紹一些比較重要的參數:
back_log:back_log 值可以指出在 MySQL 暫時停止回答新請求之前的短時間內多少個請求可以被存在堆棧中。
也就是說,如果 MySQL 的連接數據達到 max_connections 時,新來的請求將會被存在堆棧中,以等待某一連接釋放資源,該堆棧的數量即 back_log,如果等待連接的數量超過 back_log,將不被授予連接資源。可以從默認的 50 升至 500。
wait_timeout:數據庫連接閑置時間,閑置連接會占用內存資源。可以從默認的 8 小時減到半小時。
max_user_connection:最大連接數,默認為 0 無上限,最好設一個合理上限。
thread_concurrency:并發線程數,設為 CPU 核數的兩倍。
skip_name_resolve:禁止對外部連接進行 DNS 解析,消除 DNS 解析時間,但需要所有遠程主機用 IP 訪問。
key_buffer_size:索引塊的緩存大小,增加會提升索引處理速度,對 MyISAM 表性能影響最大。
對于內存 4G 左右,可設為 256M 或 384M,通過查詢 show status like 'key_read%',保證 key_reads / key_read_requests 在 0.1% 以下最好。
innodb_buffer_pool_size:緩存數據塊和索引塊,對 InnoDB 表性能影響最大。
通過查詢 show status like 'Innodb_buffer_pool_read%',保證 (Innodb_buffer_pool_read_requests – Innodb_buffer_pool_reads) / Innodb_buffer_pool_read_requests 越高越好。
innodb_additional_mem_pool_size:InnoDB 存儲引擎用來存放數據字典信息以及一些內部數據結構的內存空間大小。
當數據庫對象非常多的時候,適當調整該參數的大小以確保所有數據都能存放在內存中提高訪問效率,當過小的時候,MySQL 會記錄 Warning 信息到數據庫的錯誤日志中,這時就需要調整這個參數大小。
innodb_log_buffer_size:InnoDB 存儲引擎的事務日志所使用的緩沖區,一般來說不建議超過 32MB。
query_cache_size:緩存 MySQL 中的 ResultSet,也就是一條 SQL 語句執行的結果集,所以僅僅只能針對 Select 語句。
當某個表的數據有任何變化,都會導致所有引用了該表的 Select 語句在 Query Cache 中的緩存數據失效。
所以,當我們數據變化非常頻繁的情況下,使用 Query Cache 可能得不償失。
根據命中率(Qcache_hits/(Qcache_hits+Qcache_inserts)*100))進行調整,一般不建議太大,256MB 可能已經差不多了,大型的配置型靜態數據可適當調大。可以通過命令 show status like 'Qcache_%' 查看目前系統 Query Cache 使用大小。
read_buffer_size:MySQL 讀入緩沖區大小。對表進行順序掃描的請求將分配一個讀入緩沖區,MySQL 會為它分配一段內存緩沖區。
如果對表的順序掃描請求非常頻繁,可以通過增加該變量值以及內存緩沖區大小提高其性能。
sort_buffer_size:MySQL 執行排序使用的緩沖大小。如果想要增加 ORDER BY 的速度,首先看是否可以讓 MySQL 使用索引而不是額外的排序階段。如果不能,可以嘗試增加 sort_buffer_size 變量的大小。
read_rnd_buffer_size:MySQL 的隨機讀緩沖區大小。當按任意順序讀取行時(例如按照排序順序),將分配一個隨機讀緩存區。
進行排序查詢時,MySQL 會首先掃描一遍該緩沖,以避免磁盤搜索,提高查詢速度,如果需要排序大量數據,可適當調高該值。
但 MySQL 會為每個客戶連接發放該緩沖空間,所以應盡量適當設置該值,以避免內存開銷過大。
record_buffer:每個進行一個順序掃描的線程為其掃描的每張表分配這個大小的一個緩沖區。如果你做很多順序掃描,可能想要增加該值。
thread_cache_size:保存當前沒有與連接關聯但是準備為后面新的連接服務的線程,可以快速響應連接的線程請求而無需創建新的。
table_cache:類似于 thread_cache _size,但用來緩存表文件,對 InnoDB 效果不大,主要用于 MyISAM。
升級硬件
Scale Up,這個不多說了,根據 MySQL 是 CPU 密集型還是 I/O 密集型,通過提升 CPU 和內存、使用 SSD,都能顯著提升 MySQL 性能。
讀寫分離
也是目前常用的優化,從庫讀主庫寫,一般不要采用雙主或多主引入很多復雜性,盡量采用文中的其他方案來提高性能。同時目前很多拆分的解決方案同時也兼顧考慮了讀寫分離。
緩存
緩存可以發生在這些層次:
MySQL 內部:在系統調優參數介紹了相關設置。
數據訪問層:比如 MyBatis 針對 SQL 語句做緩存,而 Hibernate 可以精確到單個記錄,這里緩存的對象主要是持久化對象 Persistence Object。
應用服務層:可以通過編程手段對緩存做到更精準的控制和更多的實現策略,這里緩存的對象是數據傳輸對象 Data Transfer Object。
Web 層:針對 Web 頁面做緩存。
瀏覽器客戶端:用戶端的緩存。
可以根據實際情況在一個層次或多個層次結合加入緩存。這里重點介紹下服務層的緩存實現。
目前主要有兩種方式:
直寫式(Write Through):在數據寫入數據庫后,同時更新緩存,維持數據庫與緩存的一致性。
這也是當前大多數應用緩存框架如 Spring Cache 的工作方式。這種實現非常簡單,同步好,但效率一般。
回寫式(Write Back):當有數據要寫入數據庫時,只會更新緩存,然后異步批量的將緩存數據同步到數據庫上。
這種實現比較復雜,需要較多的應用邏輯,同時可能會產生數據庫與緩存的不同步,但效率非常高。
表分區
MySQL 在 5.1 版引入的分區是一種簡單的水平拆分,用戶需要在建表的時候加上分區參數,對應用是透明的無需修改代碼。
對用戶來說,分區表是一個獨立的邏輯表,但是底層由多個物理子表組成,實現分區的代碼實際上是通過對一組底層表的對象封裝,但對 SQL 層來說是一個完全封裝底層的黑盒子。
MySQL 實現分區的方式也意味著索引也是按照分區的子表定義,沒有全局索引。
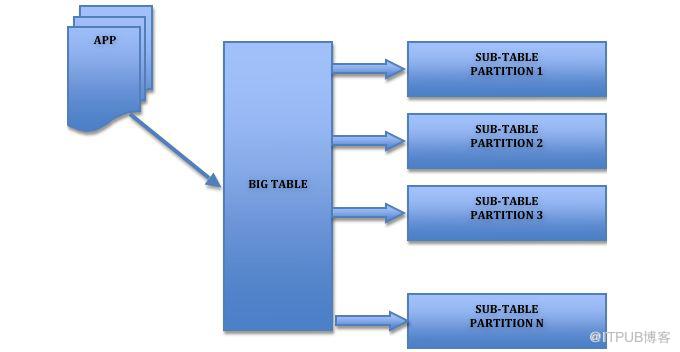
用戶的 SQL 語句是需要針對分區表做優化,SQL 條件中要帶上分區條件的列,從而使查詢定位到少量的分區上,否則就會掃描全部分區。
可以通過 EXPLAIN PARTITIONS 來查看某條 SQL 語句會落在那些分區上,從而進行 SQL 優化。
如下圖 5 條記錄落在兩個分區上:
mysql> explain partitions select count(1) from user_partition where id in (1,2,3,4,5);
+----+-------------+----------------+------------+-------+---------------+---------+---------+------+------+--------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+----------------+------------+-------+---------------+---------+---------+------+------+--------------------------+
| 1 | SIMPLE | user_partition | p1,p4 | range | PRIMARY | PRIMARY | 8 | NULL | 5 | Using where; Using index |
+----+-------------+----------------+------------+-------+---------------+---------+---------+------+------+--------------------------+
1 row in set (0.00 sec)
分區的好處是:
可以讓單表存儲更多的數據。
分區表的數據更容易維護,可以通清除整個分區批量刪除大量數據,也可以增加新的分區來支持新插入的數據。另外,還可以對一個獨立分區進行優化、檢查、修復等操作。
部分查詢能夠從查詢條件確定只落在少數分區上,速度會很快。
分區表的數據還可以分布在不同的物理設備上,從而高效利用多個硬件設備。
可以使用分區表來避免某些特殊瓶頸,例如 InnoDB 單個索引的互斥訪問、 ext3 文件系統的 inode 鎖競爭。
可以備份和恢復單個分區。
分區的限制和缺點:
一個表最多只能有 1024 個分區。
如果分區字段中有主鍵或者唯一索引的列,那么所有主鍵列和唯一索引列都必須包含進來。
分區表無法使用外鍵約束。
NULL 值會使分區過濾無效。
所有分區必須使用相同的存儲引擎。
分區的類型:
RANGE 分區:基于屬于一個給定連續區間的列值,把多行分配給分區。
LIST 分區:類似于按 RANGE 分區,區別在于 LIST 分區是基于列值匹配一個離散值集合中的某個值來進行選擇。
HASH 分區:基于用戶定義的表達式的返回值來進行選擇的分區,該表達式使用將要插入到表中的這些行的列值進行計算。這個函數可以包含 MySQL 中有效的、產生非負整數值的任何表達式。
KEY 分區:類似于按 HASH 分區,區別在于 KEY 分區只支持計算一列或多列,且 MySQL 服務器提供其自身的哈希函數。必須有一列或多列包含整數值。
分區適合的場景有:最適合的場景數據的時間序列性比較強,則可以按時間來分區。
如下所示:
CREATE TABLE members (
firstname VARCHAR(25) NOT NULL,
lastname VARCHAR(25) NOT NULL,
username VARCHAR(16) NOT NULL,
email VARCHAR(35),
joined DATE NOT NULL
)PARTITION BY RANGE( YEAR(joined) ) (
PARTITION p0 VALUES LESS THAN (1960),
PARTITION p1 VALUES LESS THAN (1970),
PARTITION p2 VALUES LESS THAN (1980),
PARTITION p3 VALUES LESS THAN (1990),
PARTITION p4 VALUES LESS THAN MAXVALUE
);
查詢時加上時間范圍條件的效率會非常高,同時對于不需要的歷史數據能很容易的批量刪除。
如果數據有明顯的熱點,而且除了這部分數據,其他數據很少被訪問到,那么可以將熱點數據單獨放在一個分區,讓這個分區的數據能夠有機會都緩存在內存中,查詢時只訪問一個很小的分區表,能夠有效使用索引和緩存。
另外 MySQL 有一種早期的簡單的分區實現 - 合并表(merge table),限制較多且缺乏優化,不建議使用,應該用新的分區機制來替代。
垂直拆分
垂直分庫是根據數據庫里面的數據表的相關性進行拆分,比如:一個數據庫里面既存在用戶數據,又存在訂單數據,那么垂直拆分可以把用戶數據放到用戶庫、把訂單數據放到訂單庫。
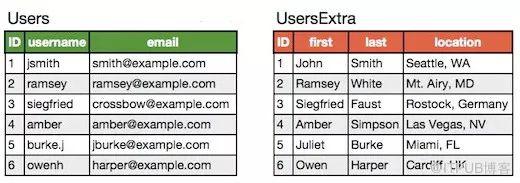
垂直分表是對數據表進行垂直拆分的一種方式,常見的是把一個多字段的大表按常用字段和非常用字段進行拆分,每個表里面的數據記錄數一般情況下是相同的,只是字段不一樣,使用主鍵關聯。
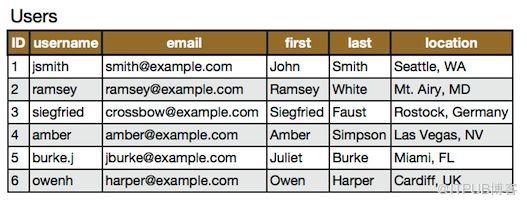
比如原始的用戶表是:
垂直拆分后是:
垂直拆分的優點是:
可以使得行數據變小,一個數據塊(Block)就能存放更多的數據,在查詢時就會減少 I/O 次數(每次查詢時讀取的 Block 就少)。
可以達到最大化利用 Cache 的目的,具體在垂直拆分的時候可以將不常變的字段放一起,將經常改變的放一起。
數據維護簡單。
缺點是:
主鍵出現冗余,需要管理冗余列。
會引起表連接 JOIN 操作(增加 CPU 開銷)可以通過在業務服務器上進行 JOIN 來減少數據庫壓力。
依然存在單表數據量過大的問題(需要水平拆分)。
事務處理復雜。
水平拆分
水平拆分是通過某種策略將數據分片來存儲,分庫內分表和分庫兩部分,每片數據會分散到不同的 MySQL 表或庫,以達到分布式的效果,能夠支持非常大的數據量。前面的表分區本質上也是一種特殊的庫內分表。
庫內分表,由于沒有把表的數據分布到不同的機器上,僅僅是單純的解決了單一表數據過大的問題。
因此對于減輕 MySQL 服務器的壓力來說,并沒有太大的作用,大家還是競爭同一個物理機上的 IO、CPU、網絡,這個就要通過分庫來解決。
前面垂直拆分的用戶表如果進行水平拆分,結果是:
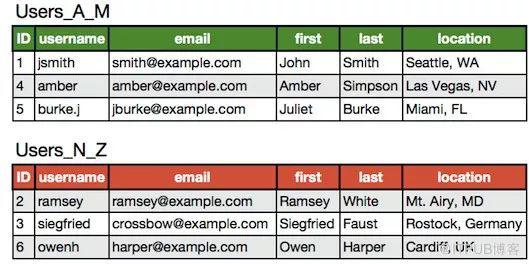
實際情況中往往會是垂直拆分和水平拆分的結合,即將 Users_A_M 和 Users_N_Z 再拆成 Users 和 UserExtras,這樣一共四張表。
水平拆分的優點是:
不存在單庫大數據和高并發的性能瓶頸。
應用端改造較少。
提高了系統的穩定性和負載能力。
缺點是:
分片事務一致性難以解決。
跨節點 JOIN 性能差,邏輯復雜。
數據多次擴展難度跟維護量極大。
分片原則
分片原則如下:
能不分就不分,參考單表優化。
分片數量盡量少,分片盡量均勻分布在多個數據結點上,因為一個查詢 SQL 跨分片越多,則總體性能越差,雖然要好于所有數據在一個分片的結果,只在必要的時候進行擴容,增加分片數量。
分片規則需要慎重選擇做好提前規劃,分片規則的選擇,需要考慮數據的增長模式,數據的訪問模式,分片關聯性問題,以及分片擴容問題。
最近的分片策略為范圍分片,枚舉分片,一致性 Hash 分片,這幾種分片都有利于擴容。
盡量不要在一個事務中的 SQL 跨越多個分片,分布式事務一直是個不好處理的問題。
查詢條件盡量優化,盡量避免 Select * 的方式,大量數據結果集下,會消耗大量帶寬和 CPU 資源,查詢盡量避免返回大量結果集,并且盡量為頻繁使用的查詢語句建立索引。
通過數據冗余和表分區來降低跨庫 JOIN 的可能。
這里特別強調一下分片規則的選擇問題,如果某個表的數據有明顯的時間特征,比如訂單、交易記錄等。
他們通常比較合適用時間范圍分片,因為具有時效性的數據,我們往往關注其近期的數據,查詢條件中往往帶有時間字段進行過濾。
比較好的方案是,當前活躍的數據,采用跨度比較短的時間段進行分片,而歷史性的數據,則采用比較長的跨度存儲。
總體上來說,分片的選擇是取決于最頻繁的查詢 SQL 的條件,因為不帶任何 Where 語句的查詢 SQL,會遍歷所有的分片,性能相對最差,因此這種 SQL 越多,對系統的影響越大,所以我們要盡量避免這種 SQL 的產生。
解決方案
由于水平拆分牽涉的邏輯比較復雜,當前也有了不少比較成熟的解決方案。這些方案分為兩大類:客戶端架構和代理架構。
客戶端架構
通過修改數據訪問層,如 JDBC、Data Source、MyBatis,通過配置來管理多個數據源,直連數據庫,并在模塊內完成數據的分片整合,一般以 Jar 包的方式呈現。
這是一個客戶端架構的例子:
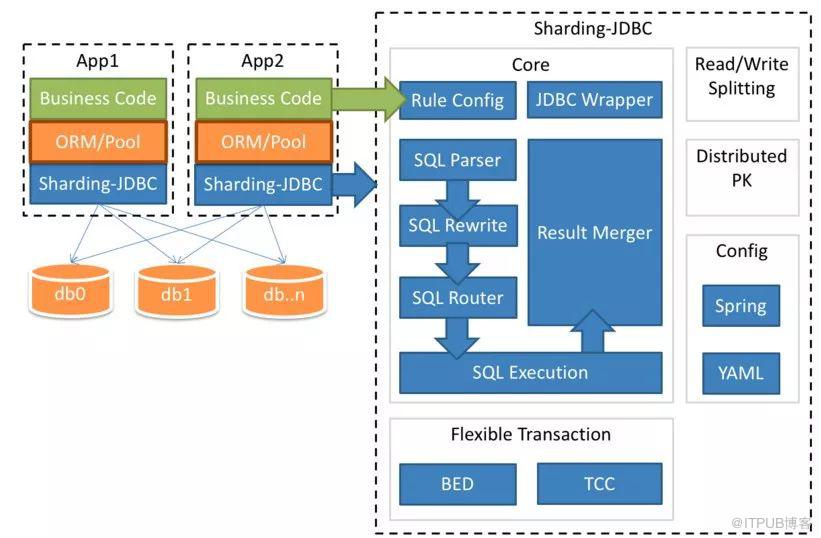
可以看到分片的實現是和應用服務器在一起的,通過修改 Spring JDBC 層來實現。
客戶端架構的優點是:
應用直連數據庫,降低外圍系統依賴所帶來的宕機風險。
集成成本低,無需額外運維的組件。
缺點是:
限于只能在數據庫訪問層上做文章,擴展性一般,對于比較復雜的系統可能會力不從心。
將分片邏輯的壓力放在應用服務器上,造成額外風險。
代理架構
通過獨立的中間件來統一管理所有數據源和數據分片整合,后端數據庫集群對前端應用程序透明,需要獨立部署和運維代理組件。
這是一個代理架構的例子:
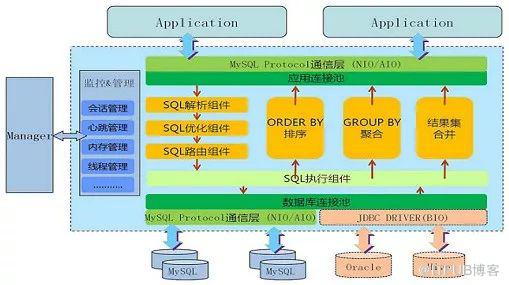
代理組件為了分流和防止單點,一般以集群形式存在,同時可能需要 ZooKeeper 之類的服務組件來管理。
代理架構的優點是:
能夠處理非常復雜的需求,不受數據庫訪問層原來實現的限制,擴展性強。
對于應用服務器透明且沒有增加任何額外負載。
缺點是:
需部署和運維獨立的代理中間件,成本高。
應用需經過代理來連接數據庫,網絡上多了一跳,性能有損失且有額外風險。
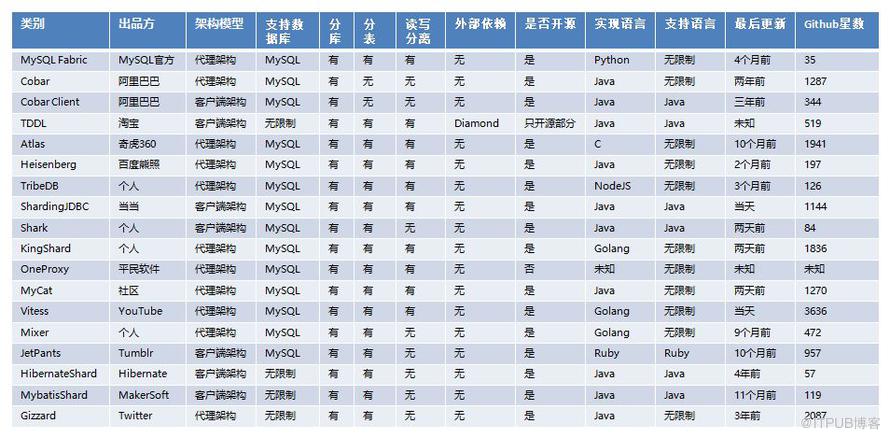
各方案比較
目前來說,業界還是有很多的方案可供選擇,但應該如何進行選擇?
我認為,可以按以下思路來考慮:
確定是使用客戶端架構還是代理架構。中小型規模或是比較簡單的場景傾向于選擇客戶端架構,復雜場景或大規模系統傾向選擇代理架構。
具體功能是否滿足,比如需要跨節點 ORDER BY,那么支持該功能的優先考慮。
不考慮一年內沒有更新的產品,說明開發停滯,甚至無人維護和技術支持。
最好按大公司→社區→小公司→個人這樣的出品方順序來選擇。
選擇口碑較好的,比如 Github 星數、使用者數量質量和使用者反饋。
開源的優先,往往項目有特殊需求可能需要改動源代碼。
按照上述思路,推薦以下選擇:
客戶端架構:ShardingJDBC
代理架構:MyCat 或者 Atlas
兼容 MySQL 且可水平擴展的數據庫
目前也有一些開源數據庫兼容 MySQL 協議,如:
TiDB
Cubrid
但其工業品質和 MySQL 尚有差距,且需要較大的運維投入,如果想將原始的 MySQL 遷移到可水平擴展的新數據庫中,可以考慮一些云數據庫:
阿里云 PetaData
阿里云 OceanBase
騰訊云 DCDB
在 MySQL 上做 Sharding 是一種戴著鐐銬的跳舞,事實上很多大表本身對 MySQL 這種 RDBMS 的需求并不大,并不要求 ACID。
可以考慮將這些表遷移到 NoSQL,徹底解決水平擴展問題,例如:
日志類、監控類、統計類數據
非結構化或弱結構化數據
對事務要求不強,且無太多關聯操作的數據
參考資料:
Mysql那點事
Mysql策略
MySQL:MySQL 5.6 Reference Manual
作者:請叫我頭頭哥
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





