溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要講解了“Oracle數據庫SQL語句的執行過程”,文中的講解內容簡單清晰,易于學習與理解,下面請大家跟著小編的思路慢慢深入,一起來研究和學習“Oracle數據庫SQL語句的執行過程”吧!
1、用戶進程在客戶端執行SQL語句時,客戶端會把這條SQL語句發送給服務器端,讓服務器端的進程來處理這語句。也就是說,Oracle 客戶端是不會做任何的操作,他的主要任務就是把客戶端產生的一些SQL語句發送給服務器端。
2、服務器進程從用戶進程把信息接收到后,在 PGA 中就要此進程分配所需內存,存儲相關的信息,如在會話內存存儲相關的登錄信息等。雖然在客戶端也有一個數據庫進程,但是,這個進程的作用跟服務器上的進程作用是不相同的,服務器上的數據庫進程才會對SQL 語句進行相關的處理。當然客戶端的進程跟服務器的進程是一一對應的。也就是說,在客戶端連接上服務器后,在客戶端與服務器端都會形成一個進程,客戶端上的我們叫做客戶端進程,而服務器上的我們叫做服務器進程。
3、當客戶端把SQL語句傳送到服務器后,服務器進程會對該語句進行解析。這個解析的工作是在服務器端所進行的,解析過程又可細化。
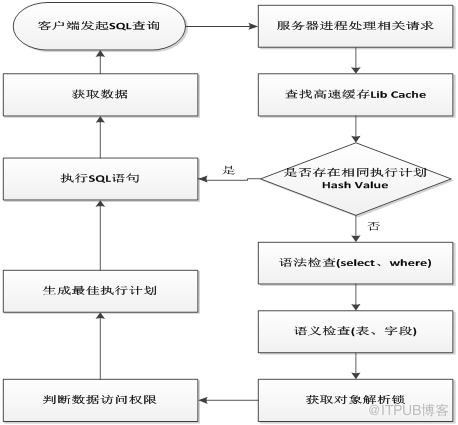
1)查詢高速緩存(library cache)
服務器進程在接到客戶端傳送過來的SQL語句時,不會直接去數據庫查詢。服務器進程把這個SQL語句的字符轉化為ASCII等效數字碼,接著這個ASCII碼被傳遞給一個HASH函數,并返回一個hash值,然后服務器進程將到shared pool中的library cache(高速緩存)中去查找是否存在相同的hash值。如果存在,服務器進程將使用這條語句已高速緩存在shared pool的library cache中的已分析過的版本來執行,省去后續的解析工作,這便是軟解析。若高速緩存中不存在,則需要進行后面的步驟,這便是硬解析。硬解析通常是昂貴的操作,大約占整個SQL執行的70%左右的時間,硬解析會生成執行樹,執行計劃,等等。
所以,采用高速數據緩存的話,可以提高SQL 語句的查詢效率。其原因有兩方面:一方面是從內存中讀取數據要比從硬盤中的數據文件中讀取數據效率要高,另一方面也是因為避免語句解析而節省了時間。
不過這里要注意一點,這個數據緩存跟有些客戶端軟件的數據緩存是兩碼事。有些客戶端軟件為了提高查詢效率,會在應用軟件的客戶端設置數據緩存。由于這些數據緩存的存在,可以提高客戶端應用軟件的查詢效率。但是,若其他人在服務器進行了相關的修改,由于應用軟件數據緩存的存在,導致修改的數據不能及時反映到客戶端上。從這也可以看出,應用軟件的數據緩存跟數據庫服務器的高速數據緩存不是一碼事。
2)語句合法性檢查(data dictionary cache)
當在高速緩存中找不到對應的SQL語句時,則服務器進程就會開始檢查這條語句的合法性。這里主要是對SQL語句的語法進行檢查,看看其是否合乎語法規則。如果服務器進程認為這條SQL語句不符合語法規則的時候,就會把這個錯誤信息反饋給客戶端。在這個語法檢查的過程中,不會對SQL語句中所包含的表名、列名等等進行檢查,只是檢查語法。
3)語言含義檢查(data dictionary cache)
若SQL 語句符合語法上的定義的話,則服務器進程接下去會對語句中涉及的表、索引、視圖等對象進行解析,并對照數據字典檢查這些對象的名稱以及相關結構,看看這些字段、表、視圖等是否在數據庫中。如果表名與列名不準確的話,則數據庫會就會反饋錯誤信息給客戶端。
所以,有時候我們寫select語句的時候,若語法與表名或者列名同時寫錯的話,則系統是先提示說語法錯誤,等到語法完全正確后再提示說列名或表名錯誤。
4)獲得對象解析鎖(control structer)
當語法、語義都正確后,系統就會對我們需要查詢的對象加鎖。這主要是為了保障數據的一致性,防止我們在查詢的過程中,其他用戶對這個對象的結構發生改變。
5)數據訪問權限的核對(data dictionary cache)
當語法、語義通過檢查之后,客戶端還不一定能夠取得數據,服務器進程還會檢查連接用戶是否有這個數據訪問的權限。若用戶不具有數據訪問權限的話,則客戶端就不能夠取得這些數據。要注意的是數據庫服務器進程先檢查語法與語義,然后才會檢查訪問權限。
6)確定最佳執行計劃
當語法與語義都沒有問題權限也匹配,服務器進程還是不會直接對數據庫文件進行查詢。服務器進程會根據一定的規則,對這條語句進行優化。在執行計劃開發之前會有一步查詢轉換,如:視圖合并、子查詢解嵌套、謂語前推及物化視圖重寫查詢等。為了確定采用哪個執行計劃,Oracle還需要收集統計信息確定表的訪問聯結方法等,最終確定可能的最低成本的執行計劃。
不過要注意,這個優化是有限的。一般在應用軟件開發的過程中,需要對數據庫的sql語句進行優化,這個優化的作用要大大地大于服務器進程的自我優化。
當服務器進程的優化器確定這條查詢語句的最佳執行計劃后, 就會將這條SQL語句與執行計劃保存到數據高速緩存(library cache)。如此,等以后還有這個查詢時,就會省略以上的語法、語義與權限檢查的步驟,而直接執行SQL語句,提高SQL語句處理效率。
4、綁定變量賦值
如果SQL語句中使用了綁定變量,掃描綁定變量的聲明,給綁定變量賦值,將變量值帶入執行計劃。若在解析的第一個步驟,SQL在高速緩沖中存在,則直接跳到該步驟。
5、語句執行
語句解析只是對SQL語句的語法進行解析,以確保服務器能夠知道這條語句到底表達的是什么意思。等到語句解析完成之后,數據庫服務器進程才會真正的執行這條SQL語句。
對于SELECT語句:
1)首先服務器進程要判斷所需數據是否在db buffer存在,如果存在且可用,則直接獲取該數據而不是從數據庫文件中去查詢數據,同時根據LRU 算法增加其訪問計數;
2)若數據不在緩沖區中,則服務器進程將從數據庫文件中查詢相關數據,并把這些數據放入到數據緩沖區中(buffer cache)。
其中,若數據存在于db buffer,其可用性檢查方式為:查看db buffer塊的頭部是否有事務,如果有事務,則從回滾段中讀取數據;如果沒有事務,則比較select的scn和db buffer塊頭部的scn,如果前者小于后者,仍然要從回滾段中讀取數據;如果前者大于后者,說明這是一非臟緩存,可以直接讀取這個db buffer塊的中內容。
對于UPDATE語句(insert、delete、update):
1)檢查所需的數據庫是否已經被讀取到緩沖區緩存中。如果已經存在緩沖區緩存,則直接執行步驟3;
2)若所需的數據庫并不在緩沖區緩存中,則服務器將數據塊從數據文件讀取到緩沖區緩存中;
3)對想要修改的表取得的數據行鎖定(Row Exclusive Lock),之后對所需要修改的數據行取得獨占鎖;
4)將數據的Redo記錄復制到redo log buffer;
5)產生數據修改的undo數據;
6)修改db buffer;
7)dbwr將修改寫入數據文件;
其中,第2步,服務器將數據從數據文件讀取到db buffer經經歷以下步驟:
a)首先服務器進程將在表頭部請求TM鎖(保證此事務執行過程其他用戶不能修改表的結構),如果成功加TM鎖,再請求一些行級鎖(TX鎖),如果TM、TX鎖都成功加鎖,那么才開始從數據文件讀數據。
b)在讀數據之前,要先為讀取的文件準備好buffer空間。服務器進程需要掃描LRU list尋找free db buffer,掃描的過程中,服務器進程會把發現的所有已經被修改過的db buffer注冊到dirty list中。如果free db buffer及非臟數據塊緩沖區不足時,會觸發dbwr將dirty buffer中指向的緩沖塊寫入數據文件,并且清洗掉這些緩沖區來騰出空間緩沖新讀入的數據。
c)找到了足夠的空閑buffer,服務器進程將從數據文件中讀入這些行所在的每一個數據塊(db block)(DB BLOCK是ORACLE的最小操作單元,即使你想要的數據只是DB BLOCK中很多行中的一行或幾行,ORACLE也會把這個DB BLOCK中的所有行都讀入Oracle DB BUFFER中)放入db buffer的空閑的區域或者覆蓋已被擠出LRU list的非臟數據塊緩沖區,并且排列在LRU列表的頭部,也就是在數據塊放入db buffer之前也是要先申請db buffer中的鎖存器,成功加鎖后,才能讀數據到db buffer。
若數據塊已經存在于db buffer cache(有時也稱db buffer或db cache),即使在db buffer中找到一個沒有事務,而且SCN比自己小的非臟緩存數據塊,服務器進程仍然要到表的頭部對這條記錄申請加鎖,加鎖成功才能進行后續動作,如果不成功,則要等待前面的進程解鎖后才能進行動作(這個時候阻塞是tx鎖阻塞)。
在記redo日志時,其具體步驟如下:
1)數據被讀入到db buffer后,服務器進程將該語句所影響的并被讀入db buffer中的這些行數據的rowid及要更新的原值和新值及scn等信息從PGA逐條的寫入redo log buffer中。在寫入redo log buffer之前也要事先請求redo log buffer的鎖存器,成功加鎖后才開始寫入。
2)當寫入達到redo log buffer大小的三分之一或寫入量達到1M或超過三秒后或發生檢查點時或者dbwr之前發生,都會觸發lgwr進程把redo log buffer的數據寫入磁盤上的redo file文件中(這個時候會產生log file sync等待事件)。
3)已經被寫入redo file的redo log buffer所持有的鎖存器會被釋放,并可被后來的寫入信息覆蓋,redo log buffer是循環使用的。Redo file也是循環使用的,當一個redo file寫滿后,lgwr進程會自動切換到下一redo file(這個時候可能出現log file switch(check point complete)等待事件)。如果是歸檔模式,歸檔進程還要將前一個寫滿的redo file文件的內容寫到歸檔日志文件中(這個時候可能出現log file switch(archiving needed)。
在為事務建立undo信息時,其具體步驟如下:
1)在完成本事務所有相關的redo log buffer之后,服務器進程開始改寫這個db buffer的塊頭部事務列表并寫入scn(一開始scn是寫在redo log buffer中的,并未寫在db buffer)。
2)然后copy包含這個塊的頭部事務列表及scn信息的數據副本放入回滾段中,將這時回滾段中的信息稱為數據塊的“前映像”,這個“前映像”用于以后的回滾、恢復和一致性讀。(回滾段可以存儲在專門的回滾表空間中,這個表空間由一個或多個物理文件組成,并專用于回滾表空間,回滾段也可在其它表空間中的數據文件中開辟)。
在修改信息寫入數據文件時,其具體步驟如下:
1)改寫db buffer塊的數據內容,并在塊的頭部寫入回滾段的地址。
2)將db buffer指針放入dirty list。如果一個行數據多次update而未commit,則在回滾段中將會有多個“前映像”,除了第一個“前映像”含有scn信息外,其他每個"前映像"的頭部都有scn信息和"前前映像"回滾段地址。一個update只對應一個scn,然后服務器進程將在dirty list中建立一條指向此db buffer塊的指針(方便dbwr進程可以找到dirty list的db buffer數據塊并寫入數據文件中)。接著服務器進程會從數據文件中繼續讀入第二個數據塊,重復前一數據塊的動作,數據塊的讀入、記日志、建立回滾段、修改數據塊、放入dirty list。
3)當dirty queue的長度達到閥值(一般是25%),服務器進程將通知dbwr把臟數據寫出,就是釋放db buffer上的鎖存器,騰出更多的free db buffer。前面一直都是在說明oracle一次讀一個數據塊,其實oracle可以一次讀入多個數據塊(db_file_multiblock_read_count來設置一次讀入塊的個數)
當執行commit時,具體步驟如下:
1)commit觸發lgwr進程,但不強制dbwr立即釋放所有相應db buffer塊的鎖。也就是說有可能雖然已經commit了,但在隨后的一段時間內dbwr還在寫這條sql語句所涉及的數據塊。表頭部的行鎖并不在commit之后立即釋放,而是要等dbwr進程完成之后才釋放,這就可能會出現一個用戶請求另一用戶已經commit的資源不成功的現象。
2)從Commit和dbwr進程結束之間的時間很短,如果恰巧在commit之后,dbwr未結束之前斷電,因為commit之后的數據已經屬于數據文件的內容,但這部分文件沒有完全寫入到數據文件中。所以需要前滾。由于commit已經觸發lgwr,這些所有未來得及寫入數據文件的更改會在實例重啟后,由smon進程根據重做日志文件來前滾,完成之前commit未完成的工作(即把更改寫入數據文件)。
3)如果未commit就斷電了,因為數據已經在db buffer更改了,沒有commit,說明這部分數據不屬于數據文件。由于dbwr之前觸發lgwr也就是只要數據更改,(肯定要先有log)所有dbwr在數據文件上的修改都會被先一步記入重做日志文件,實例重啟后,SMON進程再根據重做日志文件來回滾。
其實smon的前滾回滾是根據檢查點來完成的,當一個全部檢查點發生的時候,首先讓LGWR進程將redologbuffer中的所有緩沖(包含未提交的重做信息)寫入重做日志文件,然后讓dbwr進程將dbbuffer已提交的緩沖寫入數據文件(不強制寫未提交的)。然后更新控制文件和數據文件頭部的SCN,表明當前數據庫是一致的,在相鄰的兩個檢查點之間有很多事務,有提交和未提交的。
當執行rollback時,具體步驟如下:
服務器進程會根據數據文件塊和db buffer中塊的頭部的事務列表和SCN以及回滾段地址找到回滾段中相應的修改前的副本,并且用這些原值來還原當前數據文件中已修改但未提交的改變。如果有多個”前映像“,服務器進程會在一個“前映像”的頭部找到“前前映像”的回滾段地址,一直找到同一事務下的最早的一個“前映像”為止。一旦發出了commit,用戶就不能rollback,這使得commit后dbwr進程還沒有全部完成的后續動作得到了保障。
感謝各位的閱讀,以上就是“Oracle數據庫SQL語句的執行過程”的內容了,經過本文的學習后,相信大家對Oracle數據庫SQL語句的執行過程這一問題有了更深刻的體會,具體使用情況還需要大家實踐驗證。這里是億速云,小編將為大家推送更多相關知識點的文章,歡迎關注!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





