溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
I 客戶端把語句發給服務器端執行
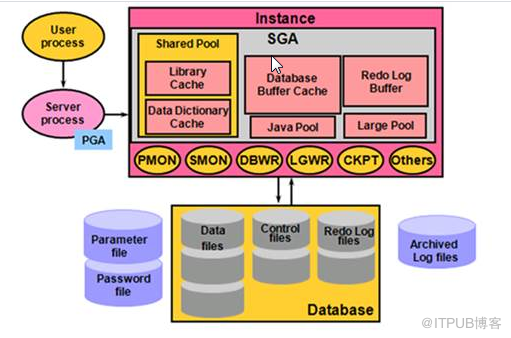
1 當我們在客戶端執行SQL語句時,客戶端會把這條SQL語句通過service process進程發送給服務器端,讓服務器端的進程來處理這語句。在PGA 中分為UGA和CGA 。
UGA 用戶全局區,用戶 私有信息,大小20m, 軟軟解析session_cached_cursors控制軟軟解析的個數,50-100。
CGA排序order by、位圖合并等
客戶端的進程跟服務器的進程是一一對應的。也就是說,在客戶端連接上服務器后,在客戶端與服務器端都會形成一個進程,客戶端上的我們叫做客戶端進程,而服務器上的我們叫做服務器進程。
II語句解析
1
當客戶端把SQL語句傳送到服務器后,服務器進程會對該語句進行解析。這個解析的工作是在服務器端所進行的,解析動作又可分為很多小動作。
service process在接到客戶端傳送過來的SQL語句時,不會直接去數據庫查詢。service process進程把這個SQL語句的字符轉化為ASCII等效數字碼,接著這個ASCII碼被傳遞給一個HASH函數,并返回一個hash值,然后服務器進程將到shared pool中的library cache(高速緩存)中去查找是否存在相同的hash值。如果存在,服務器進程將使用這條語句已高速緩存在SHARED POOL的library cache中的已分析過的版本來執行,省去后續的解析工作,這便是 軟解析。若調整緩存中不存在,則需要進行后面的步驟,這便是 硬解析。硬解析通常是昂貴的操作,大約占整個SQL執行的70%左右的時間,會消耗cup資源,硬解析會生成執行樹,執行計劃,等等。
執行過3次軟解析后,就成為
軟軟解析。
2) 語法合理性檢查( row cache)
當在高速緩存中找不到對應的SQL語句時,則服務器進程就會開始檢查這條語句的合法性。這里主要是對SQL語句的語法進行檢查,如果服務器進程認為語句不符合語法規則的時候,就會把這個錯誤信息反饋給客戶端。
3)語言含義檢查(row cache)
若SQL 語句符合語法上的定義的話,則服務器進程接下去會對語句中涉及的表、索引、視圖等對象進行解析,并對照數據字典檢查這些對象的名稱以及相關結構,看看這些字段、表、視圖等是否在數據庫中。如果表名與列名不準確的話,則數據庫會就會反饋錯誤信息給客戶端。
所以,有時候我們寫select語句的時候,若語法與表名或者列名同時寫錯的話,則系統是先提示說語法錯誤,等到語法完全正確后再提示說列名或表名錯誤。
當語法、語義都正確后,系統就會對我們需要查詢的對象加鎖。這主要是為了保障數據的一致性,防止我們在查詢的過程中,其他用戶對這個對象的結構發生改變。
當語法、語義通過檢查之后,客戶端還不一定能夠取得數據,服務器進程還會檢查連接用戶是否有這個數據訪問的權限。若用戶不具有數據訪問權限的話,則客戶端就不能夠取得這些數據。要注意的是數據庫服務器進程先檢查語法與語義,然后才會檢查訪問權限。
當語法與語義都沒有問題權限也匹配,服務器進程還是不會直接對數據庫文件進行查詢。服務器進程會根據一定的規則,對這條語句進行優化。
當服務器進程的優化器確定這條查詢語句的最佳執行計劃后, 就會將這條SQL語句與執行計劃保存到數據高速緩存(library cache)。如此,等以后還有這個查詢時,就會省略以上的語法、語義與權限檢查的步驟,而直接執行SQL語句,提高SQL語句處理效率。
III 綁定變量賦值
如果SQL語句中使用了綁定變量,掃描綁定變量的聲明,給綁定變量賦值,將變量值帶入執行計劃。若在解析的第一個步驟,SQL在高速緩沖中存在,則直接跳到該步驟。
IIII語句執行
對于SELECT 語句:
1)首先服務器進程要判斷所需數據是否在 buffer cache存在,如果存在且可用,則直接獲取該數據而不是從數據庫文件中去查詢數據,同時根據LRU 算法增加其訪問計數;
2)若數據不在緩沖區中,則service process進程將從數據庫文件中查詢相關數據,并通過service process進程把這些數據放入到數據緩沖區中(buffer cache) ,方便后人。
對于DML 語句(insert 、delete 、update ):
1)檢查所需的數據庫是否已經被讀取到緩沖區緩存中。如果已經存在緩沖區緩存,則直接執行步驟3;
2)若所需的數據庫并不在緩沖區緩存中,則service process把數據文件讀取到緩沖區緩存中;
3)對想要修改的表取得的數據行鎖定(Row Exclusive Lock),之后對所需要修改的數據行取得獨占鎖;
4)將數據產生的Redo記錄到redo log buffer;
5)產生數據修改的undo數據;
6)修改buffer cache;
7)dbwr將修改buffer cache寫入數據文件;
IV 提取數據
當語句執行完成之后,查詢到的數據還是在服務器進程中,還沒有被傳送到客戶端的用戶進程。所以,在服務器端的進程中,有一個專門負責數據提取的一段代碼。他的作用就是把查詢到的數據結果返回給用戶端進程,從而完成整個查詢動作。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





