溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本文轉自互聯網
本系列文章將整理到我在GitHub上的《Java面試指南》倉庫,更多精彩內容請到我的倉庫里查看
https://github.com/h3pl/Java-Tutorial
喜歡的話麻煩點下Star哈
文章首發于我的個人博客:
www.how2playlife.com
本文是微信公眾號【Java技術江湖】的《探索Redis設計與實現》其中一篇,本文部分內容來源于網絡,為了把本文主題講得清晰透徹,也整合了很多我認為不錯的技術博客內容,引用其中了一些比較好的博客文章,如有侵權,請聯系作者。
該系列博文會告訴你如何從入門到進階,Redis基本的使用方法,Redis的基本數據結構,以及一些進階的使用方法,同時也需要進一步了解Redis的底層數據結構,再接著,還會帶來Redis主從復制、集群、分布式鎖等方面的相關內容,以及作為緩存的一些使用方法和注意事項,以便讓你更完整地了解整個Redis相關的技術體系,形成自己的知識框架。
如果對本系列文章有什么建議,或者是有什么疑問的話,也可以關注公眾號【Java技術江湖】聯系作者,歡迎你參與本系列博文的創作和修訂。
轉自網絡,侵刪
早期的RDBMS被設計為運行在單個CPU之上,讀寫操作都由經單個數據庫實例完成,復制技術使得數據庫的讀寫操作可以分散在運行于不同CPU之上的獨立服務器上,Redis作為一個開源的、優秀的key-value緩存及持久化存儲解決方案,也提供了復制功能,本文主要介紹Redis的復制原理及特性。
數據庫復制指的是發生在不同數據庫實例之間,單向的信息傳播的行為,通常由被復制方和復制方組成,被復制方和復制方之間建立網絡連接,復制方式通常為被復制方主動將數據發送到復制方,復制方接收到數據存儲在當前實例,最終目的是為了保證雙方的數據一致、同步。
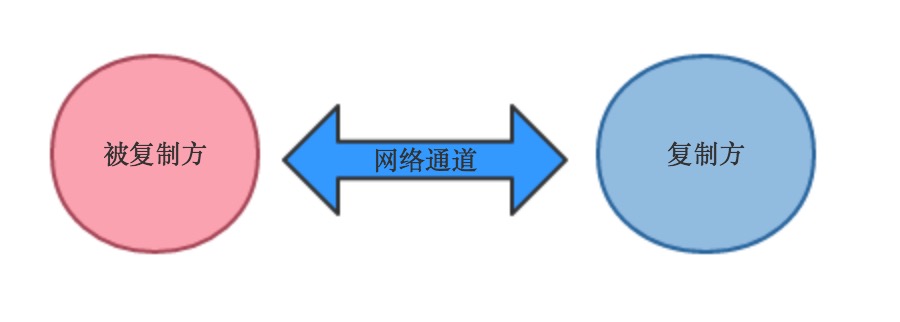
復制示意圖
Redis的復制方式有兩種,一種是主(master)-從(slave)模式,一種是從(slave)-從(slave)模式,因此Redis的復制拓撲圖會豐富一些,可以像星型拓撲,也可以像個有向無環:
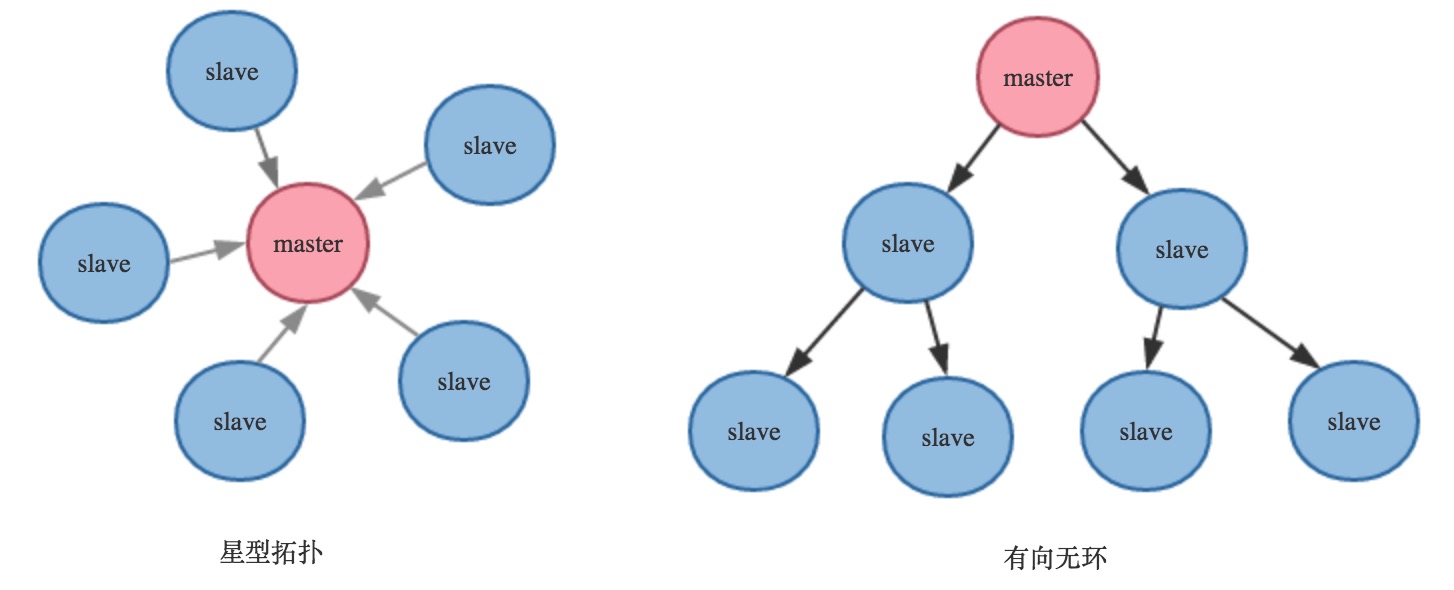
Redis集群復制結構圖
通過配置多個Redis實例獨立運行、定向復制,形成Redis集群,master負責寫、slave負責讀。
通過配置多個Redis實例,數據備份在不同的實例上,主庫專注寫請求,從庫負責讀請求,這樣的好處主要體現在下面幾個方面:
在一個Redis集群中,如果master宕機,slave可以介入并取代master的位置,因此對于整個Redis服務來說不至于提供不了服務,這樣使得整個Redis服務足夠安全。
在一個Redis集群中,master負責寫請求,slave負責讀請求,這么做一方面通過將讀請求分散到其他機器從而大大減少了master服務器的壓力,另一方面slave專注于提供讀服務從而提高了響應和讀取速度。
通過增加slave機器可以橫向(水平)擴展Redis服務的整個查詢服務的能力。
復制提供了高可用性的解決方案,但同時引入了分布式計算的復雜度問題,認為有兩個核心問題:
上面兩個問題,尤其是第一個問題是Redis服務實現一直在演變,致力于解決的一個問題。
Redis提供了提高數據一致性的解決方案,本文后面會進行介紹,一致性程度的增加雖然使得我能夠更信任數據,但是更好的一致性方案通常伴隨著性能的損失,從而減少了吞吐量和服務能力。然而我們希望系統的性能達到最優,則必須要犧牲一致性的程度,因此Redis的復制實時性和數據一致性是存在矛盾的。
舉個例子,我們有四臺redis實例,M1,R1、R2、R3,其中M1為master,R1、R2、R3分別為三臺slave redis實例。在M1啟動如下:
./redis-server ../redis8000.conf --port 8000
下面分別為R1、R2、R3的啟動命令:
./redis-server ../redis8001.conf --port 8001 --slaveof 127.0.0.1 8000 ./redis-server ../redis8002.conf --port 8002 --slaveof 127.0.0.1 8000 ./redis-server ../redis8003.conf --port 8003 --slaveof 127.0.0.1 8000
這樣,我們就成功的啟動了四臺Redis實例,master實例的服務端口為8000,R1、R2、R3的服務端口分別為8001、8002、8003,集群圖如下:
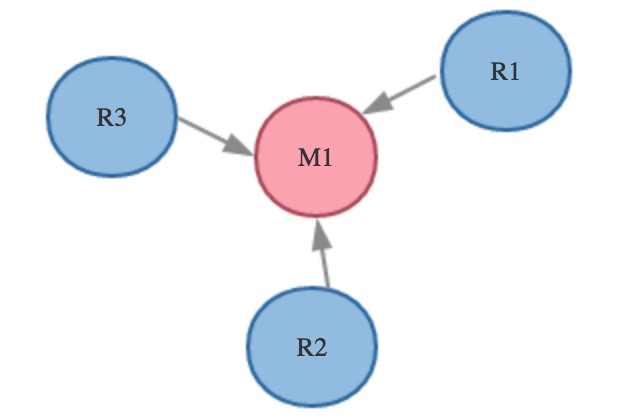
Redis集群復制拓撲
上面的命令在slave啟動的時候就指定了master機器,我們也可以在slave運行的時候通過slaveof命令來指定master機器。
Redis復制主要由SYNC命令實現,復制過程如下圖:
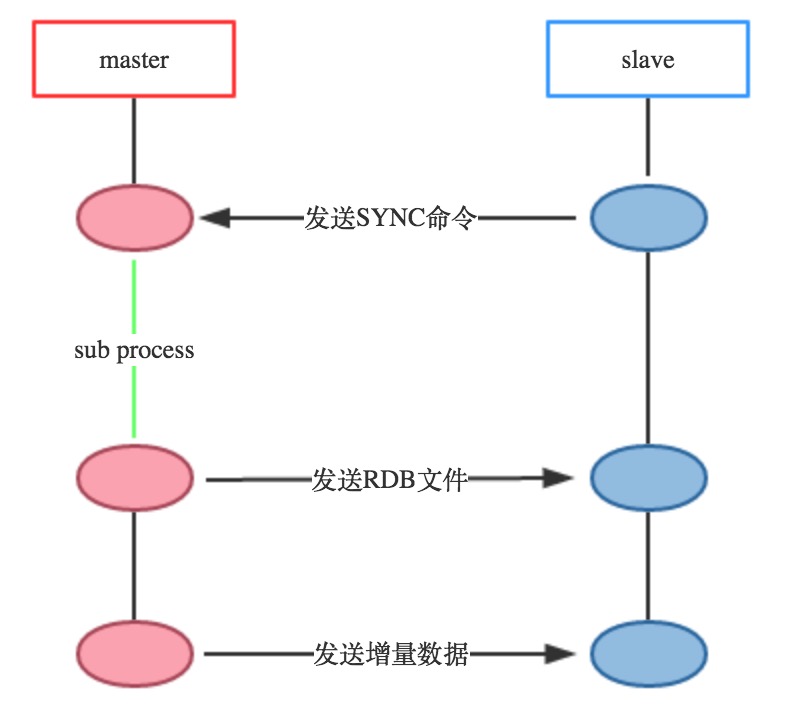
Redis復制過程
上圖為Redis復制工作過程:
值得注意的是,當slave跟master的連接斷開時,slave可以自動的重新連接master,在redis2.8版本之前,每當slave進程掛掉重新連接master的時候都會開始新的一輪全量復制。如果master同時接收到多個slave的同步請求,則master只需要備份一次RDB文件。
上面復制過程介紹的最后提到,slave和master斷開了、當slave和master重新連接上之后需要全量復制,這個策略是很不友好的,從Redis2.8開始,Redis提供了增量復制的機制:
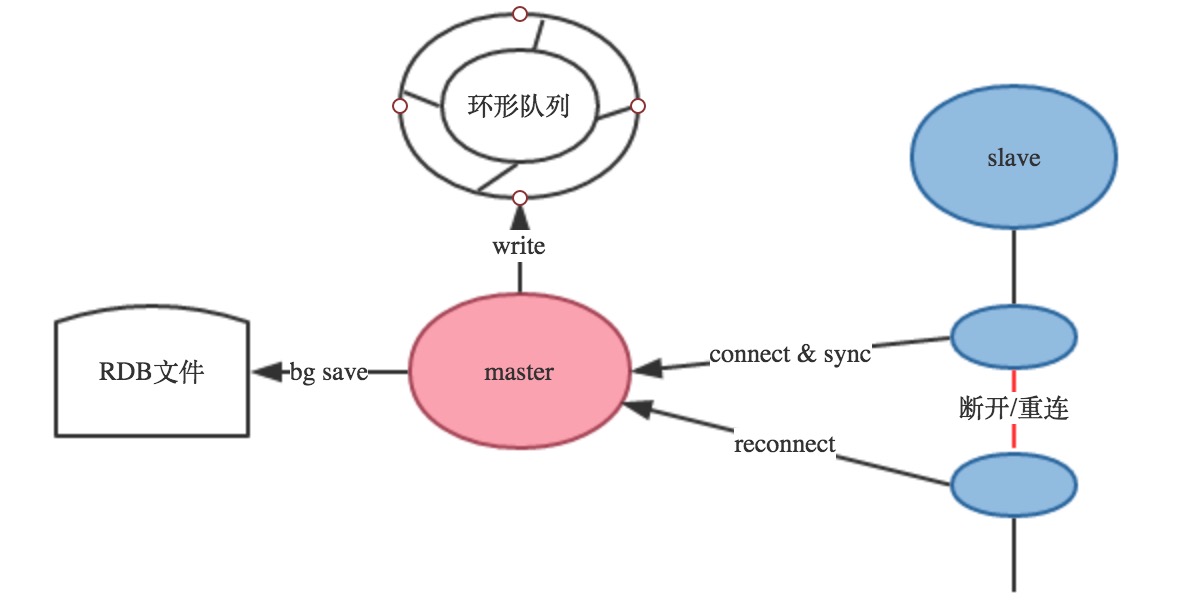
增量復制機制
master除了備份RDB文件之外還會維護者一個環形隊列,以及環形隊列的寫索引和slave同步的全局offset,環形隊列用于存儲最新的操作數據,當slave和maste斷開重連之后,會把slave維護的offset,也就是上一次同步到哪里的這個值告訴master,同時會告訴master上次和當前slave連接的master的runid,滿足下面兩個條件,Redis不會全量復制:
滿足上面兩個條件,Redis就不會全量復制,這樣的好處是大大的提高的性能,不做無效的功。
增量復制是由psync命令實現的,slave可以通過psync命令來讓Redis進行增量復制,當然最終是否能夠增量復制取決于環形隊列的大小和slave的斷線時間長短和重連的這個master是否是之前的master。
環形隊列大小配置參數:
repl-backlog-size 1mb
Redis同時也提供了當沒有slave需要同步的時候,多久可以釋放環形隊列:
repl-backlog-ttl 3600
免持久化機制官方叫做Diskless Replication,前面基于RDB文件寫磁盤的方式可以看出,Redis必須要先將RDB文件寫入磁盤,才進行網絡傳輸,那么為什么不能直接通過網絡把RDB文件傳送給slave呢?免持久化復制就是做這個事情的,而且在Redis2.8.18版本開始支持,當然目前還是實驗階段。
值得注意的是,一旦基于Diskless Replication的復制傳送開始,新的slave請求需要等待這次傳輸完畢才能夠得到服務。
是否開啟Diskless Replication的開關配置為:
repo-diskless-sync no
為了讓后續的slave能夠盡量趕上本次復制,Redis提供了一個參數配置指定復制開始的時間延遲:
repl-diskless-sync-delay 5
自從Redis2.6版本開始,支持對slave的只讀模式的配置,默認對slave的配置也是只讀。只讀模式的slave將會拒絕客戶端的寫請求,從而避免因為從slave寫入而導致的數據不一致問題。
和MySQL復制策略有點類似,Redis復制本身是異步的,但也提供了半同步的復制策略,半同步復制策略在Redis復制中的語義是這樣的:
允許用戶給出這樣的配置:在maste接受寫操作的時候,只有當一定時間間隔內,至少有N臺slave在線,否則寫入無效。
上面功能的實現基于Redis下面特性:
我們可以通過下面配置來指定時間間隔和N這個值:
min-slaves-to-write <number of slaves>min-slaves-max-lag <number of seconds>
當配置了上面兩個參數之后,一旦對于一個寫操作沒有滿足上面的兩個條件,則master會報錯,并且將本次寫操作視為無效。這有點像CAP理論中的“C”,即一致性實現,雖然半同步策略不能夠完全保證master和slave的數據一致性,但是相對減少了不一致性的窗口期。
本文在理解Redis復制概念和復制的優缺點的基礎之上介紹了當前Redis復制工作原理以及主要特性,希望能夠幫助大家。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





