溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
前言
最近發現線上出現一個奇葩的問題,這問題讓筆者定位了好長時間,期間排查問題的過程還是挺有意思的,正好博客也好久不更新了,就以此為素材寫出了本篇文章。
我們的分庫分表中間件在經過一年的沉淀之后,已經到了比較穩定的階段。而且經過線上壓測的檢驗,單臺每秒能夠執行1.7W條sql。但線上情況還是有出乎我們意料的情況。有一個業務線反映,每天有幾條sql有長達十幾秒的超時。而且sql是主鍵更新或主鍵查詢,更奇怪的是出現超時的是不同的sql,似乎毫無規律可尋,如下圖所示: 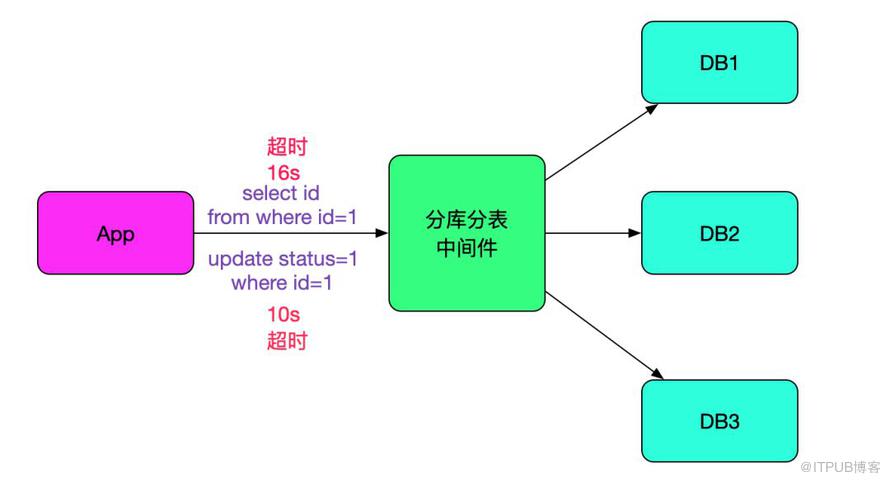
一個值得注意的點,就是此業務只有一部分流量走我們的中間件,另一部分還是直接走數據庫的,而超時的sql只會在連中間件的時候出現,如下圖所示: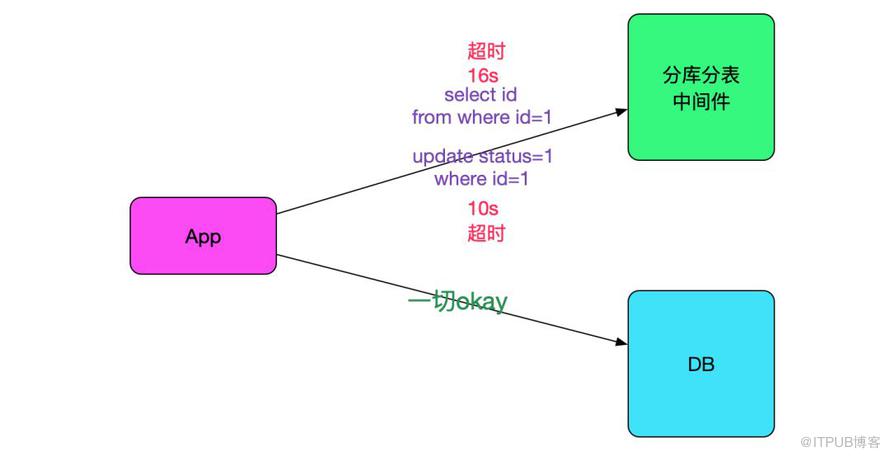
很明顯,是引入了中間件之后導致的問題。
由于數據庫中間件只關心sql,并沒有記錄對應應用的traceId,所以很難將對應的請求和sql對應起來。在這里,我們先粗略的統計了在應用端超時的sql的類型是否會有超時的情況。 分析了日志,發現那段時間所有的sql在往后端數據執行的時候都只有0.5ms,非常的快。如下圖所示: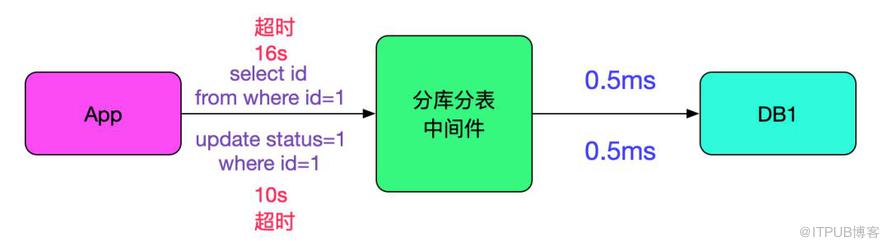
看來是中間件和數據庫之間的交互是正常的,那么繼續排查線索。
由于比較難綁定對應請求和中間件執行sql之間的關系,于是筆者就想著列出所有的異常情況,看看其時間點是否有規律,以排查一些批處理導致中間件性能下降的現象。下面是某幾條超時sql業務方給出的信息:
| 業務開始時間 | 執行sql的應用ip | 業務執行耗時(s) |
|---|---|---|
| 2018-12-24 09:45:24 | xx.xx.xx.247 | 11.75 |
| 2018-12-24 12:06:10 | xx.xx.xx.240 | 10.77 |
| 2018-12-24 12:07:19 | xx.xx.xx.138 | 13.71 |
| 2018-12-24 22:43:07 | xx.xx.xx.247 | 10.77 |
| 2018-12-24 22:43:04 | xx.xx.xx.245 | 13.71 |
看上去貌似沒什么規律,慢sql存在于不同的應用ip之上,排除某臺應用出問題的可能。 超時時間從早上9點到晚上22點都有發現超時,排除了某個點集中性能下降的可能。
筆者觀察了一堆數據一段時間,終于發現了一點小規律,如下面兩條所示:
| 業務開始時間 | 執行sql的應用ip | 業務執行耗時(s) |
|---|---|---|
| 2018-12-24 22:43:07 | xx.xx.xx.247 | 10.77 |
| 2018-12-24 22:43:04 | xx.xx.xx.245 | 13.71 |
這兩筆sql超時對應的時間點挺接近的,一個是22:43:07,一個是22:43:04,中間只差了3s,然后與后面的業務執行耗時相加,發現更接近了,讓我們重新整理下:
| 業務開始時間 | 執行sql的應用ip | 業務執行耗時(s) | 業務完成時間(s) |
|---|---|---|---|
| 2018-12-24 22:43:07 | xx.xx.xx.247 | 10.77 | 22:43:17.77 |
| 2018-12-24 22:43:04 | xx.xx.xx.245 | 13.71 | 22.43:17.71 |
發現這兩筆業務雖然開始時間不同,但確是同時完成的,這可能是個巧合,也可能是bug出現導致的結果。于是繼續看下是否有這些規律的慢sql,讓業務又提供了最近的慢sql,發現這種現象雖然少,但是確實發生了不止一次。筆者突然感覺到,這絕對不是巧合。
筆者聯想到我們中間件有好多臺,假設是中間件那邊卡住的話,如果在那一瞬間,有兩臺sql同時落到同一臺的話,中間件先卡住,然后在中間件恢復的那一瞬間,以0.5ms的速度執行完再返回就會導致這種現象。如下圖所示: 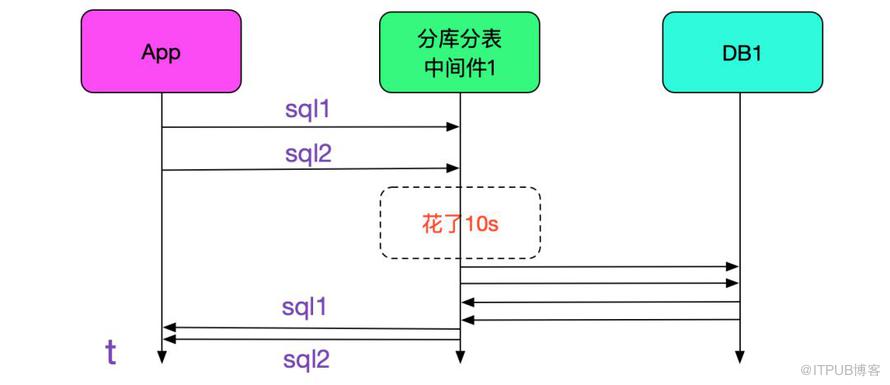
當然了還有另一種可能,就是sql先以0.5ms的速度執行完,然后中間件那邊卡住了,和上面的區別只是中間件卡的位置不同而已,另一種可能如下圖所示: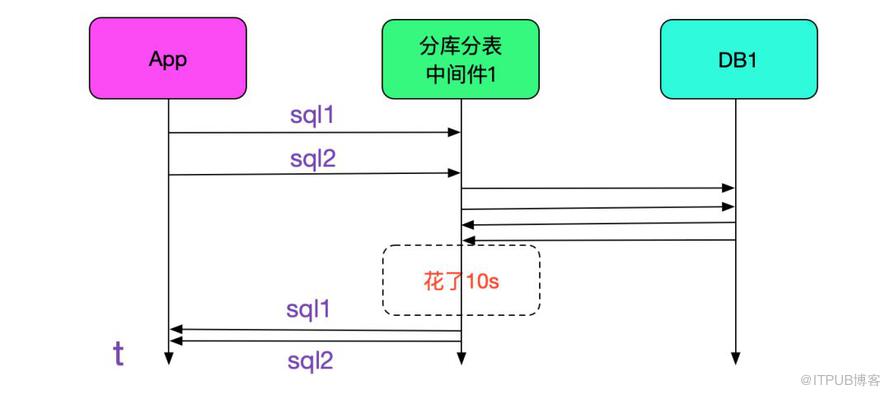
線上一共4臺中間件,在經歷了一堆復雜線上日志撈取分析相對應之后,發現那兩條sql確實落在了同一臺中間件上。為了保證猜想無誤,又找了兩條符合此規律的sql,同樣的也落在同一臺中間件上面,而且這兩臺中間件并不是同一臺,排除某臺機器有問題。如下圖所示: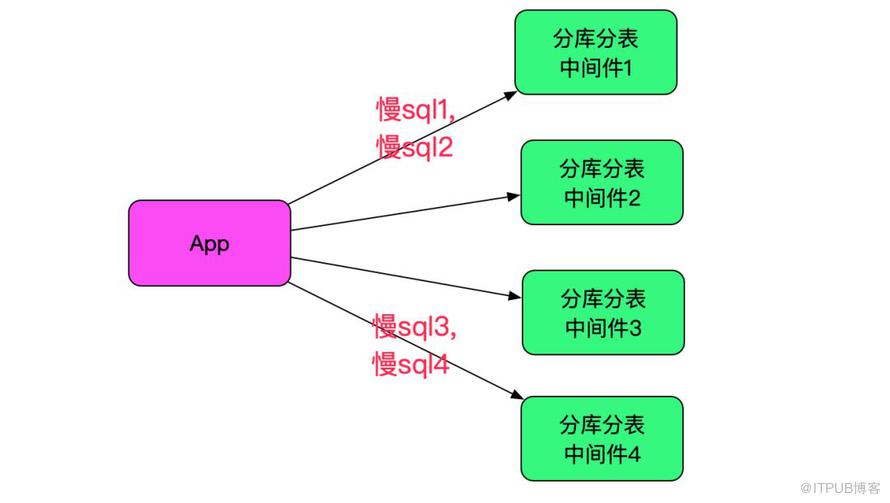
在上述發現的基礎上,又經歷了各種日志分析對應之后,終于找到了耗時sql日志和業務日志對應的關聯。然后發現一個關鍵信息。中間件在接收到sql時候會打印一條日志,發現在應用發出sql到接收到sql還沒來得及做后面的路由邏輯之前就差了10s左右,然后sql執行到返回確是非常快速的,如下圖所示: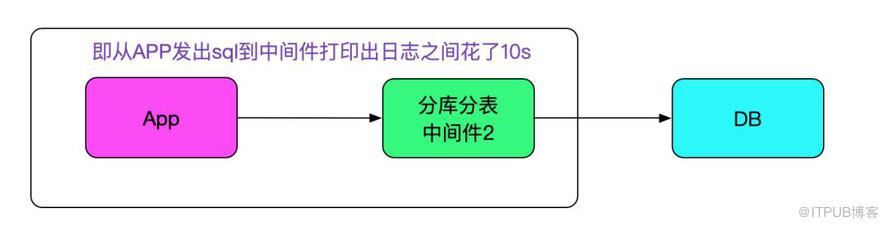
筆者撈取了那個時間點中間件的日志,發現除了這兩條sql之外,其它sql都很正常,整體耗時都在1ms左右,這又讓筆者陷入了思考之中。
在對當前中間件的日志做了各種思考各種分析之后,又發現一個詭異的點,發現在1s之內,處理慢sql對應的NIO線程的處理sql數量遠遠小于其它NIO線程。更進一步,發現在這1s的某個時間點之前,慢sql所在的NIO線程完全不打印任何日志,如下圖所示: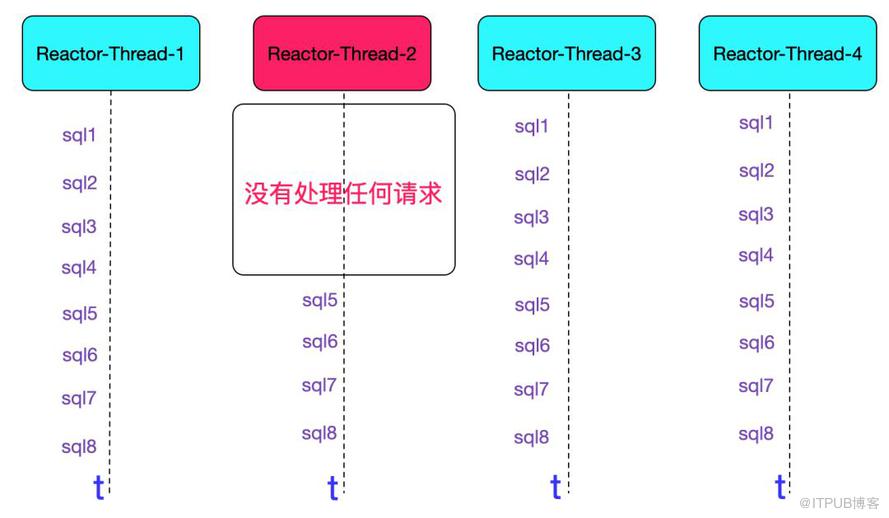
同時也發現兩條sql都落在對應的Reactor-Thread-2的線程里面,再往前回溯,發現近10s內的線程都沒有打印任何信息,好像什么都沒處理。如下圖所示:
感覺離真相越來越近了。這邊就很明顯了,reactor線程被卡住了!
筆者繼續順藤摸瓜,比較了一下幾個卡住的reactor線程最后打印的日志,發現這幾條日志對應的sql都很快返回了,沒什么異常。然后又比較了一下幾個卡住的reactor線程恢復后打印出來的第一條sql,發現貌似它們通過路由解析起來都很慢,達到了1ms(正常是0.01ms),然后找出了其對應的sql,發現這幾條sql都是150K左右的大小,按正常思路,這消失的10s應該就是處理這150K的sql了,如下圖所示: 
首先,這條sql在接入中間件之前就有,也就耗時0.5ms左右。而且中間件在往數據庫發送sql的過程中也是差不多的時間。如果說網絡有問題的話,那么這段時間應該會變長,此種情況暫不考慮。
筆者鑒于可能是中間件nio處理代碼的問題,構造了同樣的sql在線下進行復現,發現執行很快毫無壓力。筆者一度懷疑是線上環境的問題,traceroute了一下發現網絡基本和線下搭建的環境一樣,都是APP機器直連中間件機器,MTU都是1500,中間也沒任何路由。思路一下又陷入了停滯。
思考良久無果之后。筆者覺得排查一下是否是構造的場景有問題,突然發現,線上是用的prepareStatement,而筆者在命令行里面用的是statement,兩者是有區別的,prepare是按照select ?,?,?帶參數的形式而statement直接是select 1,2,3這樣的形式。
而在我們的中間件中,由于后端的數據庫對使用prepareStatement的sql具有較大的性能提升,我們也支持了prepareStatement。而且為了能夠復用原來的sql解析代碼,我們會在接收到對應的sql和參數之后將其還原成不帶?的sql算出路由到的數據庫節點后,再將原始的帶?的sql和參數prepare到對應的數據庫,如下圖所示: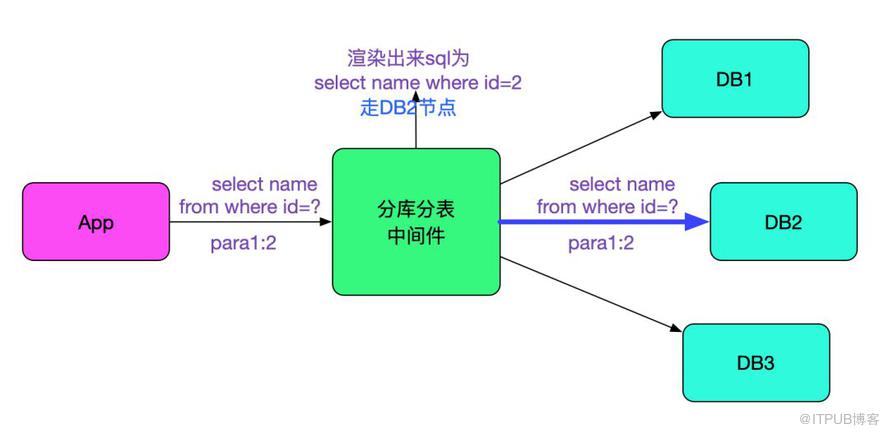
筆者重新構造了prepareStatement場景之后,發現在150K的sql下,確實耗時達到了10s,感覺終于見到曙光了。
由于是線下,在各種地方打日志之后,終于發現耗時就是在這個將帶?的sql渲染為不帶問號的sql上面。下面是代碼示意:
String sql="select ?,?,?,?,?,?...?,?,?...";for(int i=0 ; i < paramCount;i++){
sql = sql.replaceFirst("\\?",param[i]);
}return sql;這個replaceFirst在字符串特別大,需要替換的字符頻率出現的特別多的時候方面有巨大的性能消耗。之前就發現replaceFirst這個操作里面有正則的操作導致特殊符號不能正確渲染sql(另外參數里面帶?也不能正確渲染),于是其改成了用split ?的方式進行sql的渲染。但是這個版本并沒有在此應用對應的集群上使用。可能也正是這些額外的正則操作導致了這個replaceFirst性能在這種情況下特別差。
將其改成新版本后,新代碼如下所示:
String splits[] = sql.split("\\?");String result="";for(int i=0;i<splits.length;i++){ if(i<paramNumber){
result+=splits[i]+getParamString(paramNumber);
}else{
result+=splits[i];
}
}return result;這個解析時間從10s下降至2s,但感覺還是不夠滿意。
經同事提醒,試下StringBuilder。由于此應用使用的是jdk1.8,筆者一直覺得jdk1.8已經可以直接用原生的字符串拼接不需要用StringBuilder了。但還是試了一試,發現從2s下降至8ms!
改成StringBuilder的代碼后如下所示:
String splits[] = sql.split("\\?");
StringBuilder builder = new StringBuilder();for(int i=0;i<splits.length;i++){ if(i<paramNumber){
builder.append(splits[i]).append(getParamString(paramNumber));
}else{
builder.append(splits[i]);
}
}return builder.toString();筆者查了下資料,發現jdk 1.8雖然做了優化,但是每做一次拼接還是新建了一個StringBuilder,所以在大字符串頻繁拼接的場景還是需要用一個StringBuilder,以避免額外的性能損耗。
IO線程不能做任何耗時的操作,這樣會導致整個吞吐量急劇下降,對應分庫分表這種基礎組件在編寫代碼的時候必須要仔細評估,連java原生的replaceFirst也會在特定情況下出現巨大的性能問題,不能遺漏任何一個點,否則就是下一個坑。
每一次復雜Bug的分析過程都是一次挑戰,解決問題最重要也是最困難的是定位問題。而定位問題需要的是在看到現象時候能夠浮現出的各種思路,然后通過日志等信息去一條條否決自己的思路,直至達到唯一的那個問題點。
轉自 | https://my.oschina.net/alchemystar/blog/2994406
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





