溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章給大家介紹ESXI主機紫屏分析方法是什么,內容非常詳細,感興趣的小伙伴們可以參考借鑒,希望對大家能有所幫助。
相信VMware的工程師對紫屏不會陌生,紫屏死機(PSoDs, Purple Screen of Death)是發生在ESXI上的一種故障,類似于微軟Windows操作系統的藍屏。紫屏情況通常是由于硬件和軟件故障導致的,比如軟件bug、CPU、內存泄露等原因。當發生紫屏故障時整個ESXI主機會突然崩潰,當紫屏故障發生后管理員能做的只有記錄紫屏信息以及重啟主機,也就是說ESXI主機上面的虛擬機將會受到影響;如果有HA機制的話則會遷移到其他可用的ESXI主機。
當發現ESXI主機出現紫屏現狀時第一時間應該將紫屏的信息記錄下來,簡單的辦法就是將當前的屏幕信息截圖或者拍照下來,因為里面包括很多重要的信息;在里面可以顯示和了解到ESXI版本和build號、異常類型、寄存器轉儲(register dump)、崩潰時每個CPU正在跑什么、回溯追蹤(back-trace)、服務器運行時間、錯誤日志、內存硬件信息等。當將ESXI主機重啟后,還可以通過ESXI主機的/root或者//var/core/獲取vmkernel-zdump文件,當發生紫屏后會有一個以vmkernel-zdump開頭(命名)的文件,可以將該文件提交給VMware的技術支持幫助進行故障分析;同時也可以額借助通過vmkdump工具提取 VMkernel日志信息、尋找與PSoDs有關的線索,從而判斷PSoDs發生的原因。關于提取和識別vmkernel-zdump查閱官方KB:https://kb.vmware.com/s/article/1006796?lang=zh_CN
通過紫屏后屏幕信息都可以獲取到很多關鍵信息,管理員可以快速的借助這些信息進行故障定位和排查。錯誤會顯示在紫色診斷屏幕中。紫色診斷屏幕大致如下所示:
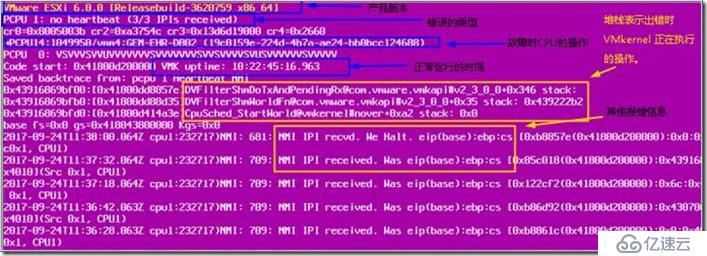
通過以上內容可以查看到幾個關鍵信息
· 產品和內部版本:VMware ESX Server [Releasebuild-3620759
紫色診斷屏幕中的此部分表示出錯的產品和內部版本。在本示例中,產品是ESXI,版本號是3620759,也就是ESXI 6.0 U2
· 錯誤消息:PCPU 1 locked up.Failed to ack TLB invalidate
紫色診斷屏幕的此部分表示報告的錯誤消息。只能報告有限數量的錯誤消息。本文稍后會討論這些錯誤消息。
· CPU 寄存器:frame=0x3a37d98 ip=0x625e94 cr2=0x0 cr3=0x40c66000 cr4=0x16ces=0xffffffff ds=0xffffffff fs=0xffffffff gs=0xffffffffeax=0xffffffff ebx=0xffffffff ecx=0xffffffff edx=0xffffffffebp=0x3a37ef4 esi=0xffffffff edi=0xffffffff err=-1 eflags=0xffffffff
出錯時,這些值存儲在物理 CPU 寄存器中。這些寄存器中的信息千差萬別,具體取決于出現的 VMkernel 錯誤
· 物理 CPU:*0:1037/helper1-4 1:1107/vmm0:Fagi 2:1121/vmware-vm 3:1122/mks:Franc
紫色診斷屏幕的此部分表示 VMkernel 出錯期間運行指令的物理 CPU。在本示例中,0 旁邊的 * 表示發生故障時物理 CPU 0 正在運行操作。新版本 ESX 不再使用 *,而是使用前綴字母 CPU。例如,如果新版本 VMware ESX 同樣出現上述錯誤,則同一行會顯示為:CPU0:1037/helper1-4 cpu1:1107/vmm0:Fagi cpu2:1121/vmware-vm cpu3:1122/mks:Franc。
紫色診斷屏幕的此部分還描述了出錯時 CPU 上運行的環境(進程)。在上述示例中,用戶環境正在運行 helper1-4。
注意:進程名稱可能已截斷。
· 堆棧跟蹤:0x3a37ef4:[0x625e94]Panic+0x17 stack: 0x833ab4, 0x3a37f10, 0x3a37f480x3a37f04:[0x625e94]Panic+0x17 stack: 0x833ab4, 0x1, 0x14a03a00x3a37f48:[0x64bfa4]TLBDoInvalidate+0x38f stack: 0x3a37f54, 0x40, 0x20x3a37f70:[0x66da4d]XMapForceFlush+0x64 stack: 0x0, 0x4d3a, 0x00x3a37fac:[0x652b8b]helpFunc+0x2d2 stack: 0x1, 0x14a4580, 0x00x3a37ffc:[0x750902]CpuSched_StartWorld+0x109 stack: 0x0, 0x0, 0x00x3a38000:[0x0]blk_dev+0xfd76461f stack: 0x0, 0x0, 0x0
堆棧表示出錯時 VMkernel 正在執行的操作。在本示例中,VMkernel 正在嘗試清除內存頁表 (TLB)。此信息是一個重要工具,有助于通過評估出錯時內核所執行的操作來診斷紫色屏幕錯誤。
· 正常運行時間:VMK uptime: 7:05:43:45.014 TSC: 1751259712918392
此部分表示自上次啟動以來服務器運行的時間。在本示例中,ESXI 主機已運行了 7 天 5 小時 43 分 45.014 秒。TSC 值是服務器啟動之后經過的 CPU 時鐘頻率循環次數。
· 核心轉儲:Starting coredump to disk Starting coredump to disk Dumping using slot 1 of 1...using slot 1 of 1... log
紫色診斷屏幕的此部分表示正復制到 vmkcore 分區的 VMkernel 內存內容。
上面介紹了如何查看和理解紫屏的屏幕信息,其中比較關鍵的就是關于錯誤信息的字段,接下來我們可以通過紫色屏幕生成的 VMkernel 錯誤消息可用于確定問題原因。不過,產生的錯誤消息數是有限的。以下是已知的 VMkernel 錯誤消息列表。
l 類型:控制臺警告
錯誤示例:COS Error: Oops
描述:ESX 主機出現故障并在出現服務控制臺警告時顯示紫色屏幕。與大多數紫色屏幕錯誤不同的是,該錯誤并非由 VMkernel 觸發。相反,它由服務控制臺觸發,并發生在 Linux 級別。這些紫色屏幕錯誤包含來自 Linux 內核的其他信息。有關控制臺警告的詳細信息,請參見 Understanding an "Oops" purple diagnostic screen (1006802)。
l 類型:檢測信號丟失
錯誤示例:Lost Heartbeat
描述:ESX VMkernel 和服務控制臺 Linux 內核同時在 ESX 上運行。服務控制臺 Linux 內核會運行一個稱為 vmnixhbd 的進程,只要 VMkernel 能夠分配和釋放內存頁,該進程便會向 VMkernel 發送檢測信號。如果在 30 分鐘超時時間之前未收到檢測信號,VMkernel 會觸發 COS 嚴重錯誤以及表明檢測信號丟失的紫色診斷屏幕。有關檢測信號丟失的詳細信息,請參見 Understanding a "Lost Heartbeat" purple diagnostic screen (1009525)。
l 類型:斷言
錯誤示例:ASSERT bora/vmkernel/main/pframe_int.h:527
描述:斷言錯誤屬于軟件錯誤,因為它們都與程序所基于的假設條件有關。此類型的紫色屏幕錯誤主要是由軟件錯誤導致的。有關斷言錯誤消息的詳細信息,請參見 Understanding ASSERT and NOT_IMPLEMENTED purple diagnostic screens (1019956)。
l 類型:未執行
錯誤示例:
NOT_IMPLEMENTED /build/mts/release/bora-84374/bora/vmkernel/main/util.c:83
描述:代碼遇到超出設計處理范圍的情形時會出現未執行錯誤消息。有關詳細信息,請參見 Understanding ASSERT and NOT_IMPLEMENTED purple diagnostic screens (1019956)。
l 類型:轉數已超出/可能出現死鎖
錯誤示例:Spin count exceeded (iplLock) - possible deadlock
描述:線程嘗試在代碼關鍵部分執行時,VMware ESX 主機可能在紫色診斷屏幕上報告轉數已超出且可能出現死鎖。由于線程正嘗試進入關鍵部分,因此,它需要執行自旋鎖操作,以便先輪詢互斥鎖,然后再執行代碼。線程在執行自旋鎖操作期間會繼續輪詢互斥鎖,但是,互斥鎖輪詢次數存在一定限制。有關轉數已超出錯誤的詳細信息,請參見 Understanding a "Spin count exceeded" purple diagnostic screen (1020105)。
l 類型:無法確認 TLB 是否失效
錯誤示例:PCPU 1 locked up.Failed to ack TLB invalidate.
描述:物理 CPU 在嘗試清除內存頁表時出現故障。有關詳細信息,請參見 Understanding a Failed to ack TLB invalidate purple diagnostic screen (1020214)。
紫色診斷屏幕還會以異常的形式出現。異常處理程序是一種計算機硬件機制,旨在處理正常執行流(除零、頁面錯誤等)發生變動的某些情形。該處理程序并無跟蹤機制,因此您需要通過日志記錄確定處理程序是否出現問題(或通過單步調試)。以下是常見異常列表:
l 類型:異常 13(一般保護錯誤)
錯誤示例:#GP Exception(13) in world 4130:helper13-0 @ 0x41803399e303
描述:在以下任一情況下都會出現一般保護錯誤(異常 13):正在請求的頁面不屬于請求該頁的程序(未映射到程序內存中),或者程序無權在頁面上執行讀取或寫入操作。有關異常 13 或頁面錯誤的詳細信息,請參見 Understanding Exception 13 and Exception 14 purple diagnostic screen events (1020181)。
l 類型:異常 14(頁面錯誤)
錯誤示例:#PF Exception type 14 in world 136:helper0-0 @ 0x4a8e6e
描述:正在請求的頁面未成功加載到內存時出現頁面錯誤(異常 14)。有關異常 14 或頁面錯誤的詳細信息,請參見 Understanding Exception 13 and Exception 14 purple diagnostic screen events (1020181)。
l 類型:異常 18(計算機檢查異常)
錯誤示例:Machine Check Exception: Unable to continue
錯誤示例:Hardware (Machine) Error
描述:計算機檢查異常 (MCE) 由硬件生成并通過主機進行報告。出現 MCE 事件時,請咨詢您的硬件供應商。通過評估顯示的信息,可以確定報告錯誤的單個組件。有關 MCE 的詳細信息,請參見 Decoding Machine Check Exception (MCE) output after a purple screen error (1005184)。
同一ESXI主機上出可能現多個紫色診斷屏幕時,可以使用多個紫色診斷屏幕示例確定問題與硬件還是與軟件有關。為此,請確定紫色診斷屏幕的以下部分是否存在一些模式:
l 錯誤消息和堆棧跟蹤:
如果多個 vmkernel 錯誤中的錯誤消息和堆棧變化很大,則表明同一錯誤并不總是軟件造成的。盡管不是十分確鑿,但這很可能意味著硬件問題。
如果多個 vmkernel 中的錯誤消息和堆棧始終相同,則表明同一錯誤都是由軟件造成的。盡管不是十分確鑿,但這很可能意味著軟件問題。有關出現的錯誤消息的詳細信息,請參見上述特定錯誤消息部分。
l 物理 CPU:
如果多個 vmkernel 錯誤中的物理 CPU 值始終相同,則表明軟件總是在同一個物理 CPU 上出現錯誤。盡管不是十分確鑿,但這很可能意味著 CPU 問題。有關詳細信息,請參見 KB1003560
l 環境:
如果多個 vmkernel 錯誤中的環境值始終相同,則表明 vmkernel 從同一環境接收指令時出現錯誤。盡管不是十分確鑿,但這很可能意味著發送指令的環境可能觸發了 VMkernel 錯誤。
異常類型 0 #DE:除法錯誤(Divide Error)
異常類型 1 #DB:調試異常
異常類型 2 NMI:不可屏蔽中斷
異常類型 3 #BP:斷點異常
異常類型 4 #OF:溢出(INTO 指令)
異常類型 5 #BR:界限檢查(BOUND 指令)
異常類型 6 #UD:Opcode 無效
異常類型 7 #NM:協處理器不可用
異常類型 8 #DF:雙重故障
異常類型 10 #TS:TSS 無效
異常類型 11 #NP:分段不存在
異常類型 12 #SS:堆棧分段錯誤
異常類型 13 #GP:一般保護錯誤
異常類型 14 #PF:頁面錯誤
異常類型16 #MF:協處理器錯誤
異常類型 17 #AC:對齊檢查
異常類型 18 #MC:計算機檢查異常
異常類型 19 #XF:SIMD 浮點異常
異常類型 20-31:預留
異常類型 32-255:用戶定義(時鐘調度程序)
在實際環境中遇到過以下提示的紫屏情況,通過屏幕中的信息可以獲知以下幾點信息,故障的ESXI主機是esxi 6.0 U2(build 3620759),該主機自上次開機來正常運行了35:18:32:21也就是35天18小時32分。
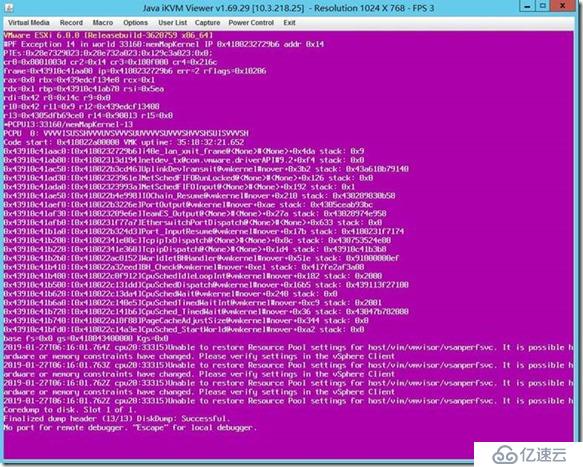
同時關于該紫屏的關鍵代碼信息是PF Exception 14 in world 33168:memMapKernal 根據該關鍵代碼信息可以在VMware的KB庫中查到以下
https://kb.vmware.com/s/article/1020181?lang=zh_CN#q=esxi%E7%B4%AB%E5%B1%8F
https://kb.vmware.com/s/article/2071752?lang=zh_CN#q=esxi%E7%B4%AB%E5%B1%8F
根據KB介紹,信息可能如下:
如果要請求的頁面未成功載入內存,則會出現頁面錯誤(異常 14)。存在正常狀態和非正常狀態兩種頁面錯誤:
正常狀態頁面錯誤會導致頁面從交換內存載入物理內存。這樣便允許程序在數據正確載入物理內存后繼續執行。
如果頁面未載入內存,并且操作系統無法將頁面從交換內存載入物理內存,則會出現非正常狀態頁面錯誤。
再配合后面的MemMapKernal字段大概可以判斷本次的紫屏想象是由ESXI主機中的內存異常導致的,可能是內存載入或內存溢出,也有可能是在本示例中的Horizon View中虛擬內存共享機制導致的系統紫屏故障。
關于ESXI主機紫屏分析方法是什么就分享到這里了,希望以上內容可以對大家有一定的幫助,可以學到更多知識。如果覺得文章不錯,可以把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





