溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
在討論某個數據庫時,存儲 ( Storage ) 和計算 ( Query Engine ) 通常是討論的熱點,也是愛好者們了解某個數據庫不可或缺的部分。每個數據庫都有其獨有的存儲、計算方式,今天就和圖圖來學習下圖數據庫 Nebula Graph 的存儲部分。
Nebula 的 Storage 包含兩個部分, 一是 meta 相關的存儲, 我們稱之為?Meta Service?,另一個是 data 相關的存儲, 我們稱之為?Storage Service。 這兩個服務是兩個獨立的進程,數據也完全隔離,當然部署也是分別部署, 不過兩者整體架構相差不大,本文最后會提到這點。 如果沒有特殊說明,本文中?Storage Service 代指 data 的存儲服務。接下來,大家就隨我一起看一下 Storage Service 的整個架構。 Let's go~
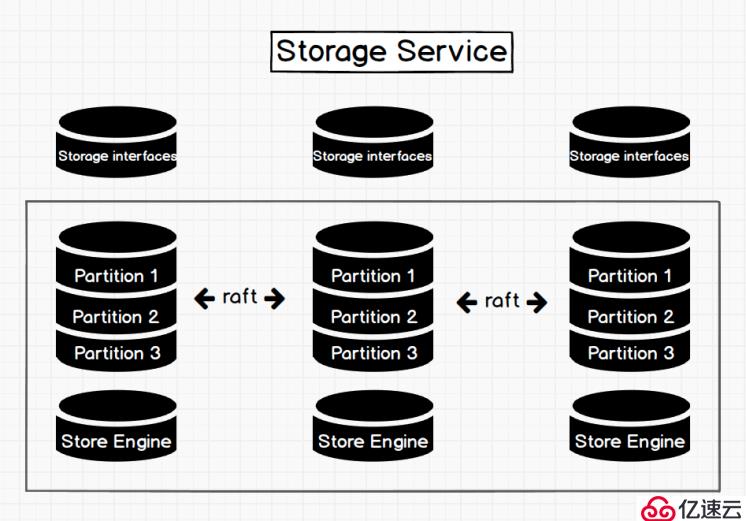 ?圖一? storage service 架構圖
?圖一? storage service 架構圖
如圖1 所示,Storage Service 共有三層,最底層是 Store Engine,它是一個單機版 local store engine,提供了對本地數據的?get?/?put?/?scan?/?delete?操作,相關的接口放在 KVStore / KVEngine.h 里面,用戶完全可以根據自己的需求定制開發相關 local store plugin,目前 Nebula 提供了基于 RocksDB 實現的? Store Engine。
在 local store engine 之上,便是我們的 Consensus 層,實現了 Multi Group Raft,每一個 Partition 都對應了一組 Raft Group,這里的 Partition 便是我們的數據分片。目前 Nebula 的分片策略采用了?靜態 Hash?的方式,具體按照什么方式進行 Hash,在下一個章節 schema 里會提及。用戶在創建 SPACE 時需指定 Partition 數,Partition 數量一旦設置便不可更改,一般來講,Partition 數目要能滿足業務將來的擴容需求。
在 Consensus 層上面也就是 Storage Service 的最上層,便是我們的 Storage interfaces,這一層定義了一系列和圖相關的 API。 這些 API 請求會在這一層被翻譯成一組針對相應 Partition 的 kv 操作。正是這一層的存在,使得我們的存儲服務變成了真正的圖存儲,否則,Storage Service 只是一個 kv 存儲罷了。而 Nebula 沒把 kv 作為一個服務單獨提出,其最主要的原因便是圖查詢過程中會涉及到大量計算,這些計算往往需要使用圖的 schema,而 kv 層是沒有數據 schema 概念,這樣設計會比較容易實現計算下推。
圖存儲的主要數據是點和邊,但 Nebula 存儲的數據是一張屬性圖,也就是說除了點和邊以外,Nebula 還存儲了它們對應的屬性,以便更高效地使用屬性過濾。
對于點來說,我們使用不同的 Tag 表示不同類型的點,同一個 VertexID 可以關聯多個 Tag,而每一個 Tag 都有自己對應的屬性。對應到 kv 存儲里面,我們使用 vertexID + TagID 來表示 key,? 我們把相關的屬性編碼后放在 value 里面,具體 key 的 format 如圖2 所示:
 ?圖二 Vertex Key Format
?圖二 Vertex Key Format
Type?:? 1 個字節,用來表示 key 類型,當前的類型有 data, index, system 等
Part ID?: 3 個字節,用來表示數據分片 Partition,此字段主要用于?Partition 重新分布(balance)?時方便根據前綴掃描整個 Partition 數據
Vertex ID?: 4 個字節, 用來表示點的 ID
Tag ID?: 4 個字節, 用來表示關聯的某個 tag
Timestamp?: 8 個字節,對用戶不可見,未來實現分布式事務 ( MVCC ) 時使用
在一個圖中,每一條邏輯意義上的邊,在 Nebula?Graph 中會建模成兩個獨立的 key-value,分別稱為 out-key 和in-key。out-key 與這條邊所對應的起點存儲在同一個 partition 上,in-key 與這條邊所對應的終點存儲在同一個partition 上。通常來說,out-key 和 in-key 會分布在兩個不同的 Partition 中。
兩個點之間可能存在多種類型的邊,Nebula 用 Edge Type?來表示邊類型。而同一類型的邊可能存在多條,比如,定義一個 edge type "轉賬",用戶?A 可能多次轉賬給 B, 所以 Nebula 又增加了一個 Rank 字段來做區分,表示 A 到 B 之間多次轉賬記錄。?Edge?key 的?format 如圖3 所示:
 ?圖三 Edge Key Format
?圖三 Edge Key Format
Type?:? 1 個字節,用來表示 key 的類型,當前的類型有 data, index, system 等。
Part ID?: 3 個字節,用來表示數據分片 Partition,此字段主要用于?Partition 重新分布(balance)?時方便根據前綴掃描整個 Partition 數據
Vertex ID?: 4 個字節, 出邊里面用來表示源點的 ID, 入邊里面表示目標點的 ID。
Edge Type?: 4 個字節, 用來表示這條邊的類型,如果大于 0 表示出邊,小于 0 表示入邊。
Rank?: 4 個字節,用來處理同一種類型的邊存在多條的情況。用戶可以根據自己的需求進行設置,這個字段可_存放交易時間_、交易流水號、或_某個排序權重_
Vertex ID?: 4 個字節,??出邊里面用來表示目標點的 ID, 入邊里面表示源點的 ID。
Timestamp?: 8 個字節,對用戶不可見,未來實現分布式做事務的時候使用。
針對 Edge Type 的值,若如果大于 0 表示出邊,則對應的 edge key format 如圖4 所示;若 Edge Type 的值小于 0,則對應的 edge key format 如圖5 所示
 ?圖4 出邊的 Key Format?
?圖4 出邊的 Key Format? ?圖5 入邊的 Key Format
?圖5 入邊的 Key Format
對于點或邊的屬性信息,有對應的一組 kv pairs,Nebula 將它們編碼后存在對應的 value 里。由于 Nebula 使用強類型 schema,所以在解碼之前,需要先去 Meta Service 中取具體的 schema 信息。另外,為了支持在線變更 schema,在編碼屬性時,會加入對應的 schema 版本信息,具體的編解碼細節在這里不作展開,后續會有專門的文章講解這塊內容。
OK,到這里我們基本上了解了 Nebula 是如何存儲數據的,那數據是如何進行分片呢?很簡單,對 Vertex ID?取模?即可。通過對 Vertex ID 取模,同一個點的所有_出邊_,_入邊_以及這個點上所有關聯的?_Tag 信息_都會被分到同一個 Partition,這種方式大大地提升了查詢效率。對于在線圖查詢來講,最常見的操作便是從一個點開始向外 BFS(廣度優先)拓展,于是拿一個點的出邊或者入邊是最基本的操作,而這個操作的性能也決定了整個遍歷的性能。BFS 中可能會出現按照某些屬性進行剪枝的情況,Nebula 通過將屬性與點邊存在一起,來保證整個操作的高效。當前許多的圖數據庫通過?Graph 500 或者 Twitter 的數據集試來驗證自己的高效性,這并沒有代表性,因為這些數據集沒有屬性,而實際的場景中大部分情況都是屬性圖,并且實際中的 BFS 也需要進行大量的剪枝操作。
為什么要自己做 KVStore,這是我們無數次被問起的問題。理由很簡單,當前開源的 KVStore 都很難滿足我們的要求:
性能,性能,性能:Nebula 的需求很直接:高性能 pure kv;
以 library 的形式提供:對于強 schema 的 Nebula 來講,計算下推需要 schema 信息,而計算下推實現的好壞,是 Nebula 是否高效的關鍵;
數據強一致:這是分布式系統決定的;
使用 C++實現:這由團隊的技術特點決定;
基于上述要求,Nebula 實現了自己的 KVStore。當然,對于性能完全不敏感且不太希望搬遷數據的用戶來說,Nebula 也提供了整個KVStore 層的 plugin,直接將 Storage Service 搭建在第三方的 KVStore 上面,目前官方提供的是 HBase 的 plugin。
Nebula KVStore 主要采用 RocksDB 作為本地的存儲引擎,對于多硬盤機器,為了充分利用多硬盤的并發能力,Nebula 支持自己管理多塊盤,用戶只需配置多個不同的數據目錄即可。分布式 KVStore 的管理由 Meta Service 來統一調度,它記錄了所有 Partition 的分布情況,以及當前機器的狀態,當用戶增減機器時,只需要通過 console 輸入相應的指令,Meta Service 便能夠生成整個 balance plan 并執行。(之所以沒有采用完全自動 balance 的方式,主要是為了減少數據搬遷對于線上服務的影響,balance 的時機由用戶自己控制。)
為了方便對于 WAL 進行定制,Nebula KVStore 實現了自己的 WAL 模塊,每個 partition 都有自己的 WAL,這樣在追數據時,不需要進行 wal split 操作, 更加高效。 另外,為了實現一些特殊的操作,專門定義了 Command Log 這個類別,這些 log 只為了使用 Raft 來通知所有 replica 執行某一個特定操作,并沒有真正的數據。除了 Command Log 外,Nebula 還提供了一類日志來實現針對某個 Partition 的 atomic operation,例如 CAS,read-modify-write,? 它充分利用了Raft 串行的特性。
關于多圖空間(space)的支持:一個 Nebula KVStore 集群可以支持多個 space,每個 space 可設置自己的 partition 數和 replica 數。不同 space 在物理上是完全隔離的,而且在同一個集群上的不同 space 可支持不同的 store engine 及分片策略。
作為一個分布式系統,KVStore 的 replication,scale out 等功能需 Raft 的支持。當前,市面上講 Raft 的文章非常多,具體原理性的內容,這里不再贅述,本文主要說一些 Nebula Raft 的一些特點以及工程實現。
由于 Raft 的日志不允許空洞,幾乎所有的實現都會采用 Multi Raft Group 來緩解這個問題,因此 partition 的數目幾乎決定了整個 Raft Group 的性能。但這也并不是說 Partition 的數目越多越好:每一個 Raft Group 內部都要存儲一系列的狀態信息,并且每一個 Raft Group 有自己的 WAL 文件,因此?Partition 數目太多會增加開銷。此外,當 Partition 太多時, 如果負載沒有足夠高,batch 操作是沒有意義的。比如,一個有 1w tps 的線上系統單機,它的單機 partition 的數目超過 1w,可能每個 Partition 每秒的 tps 只有 1,這樣 batch 操作就失去了意義,還增加了 CPU 開銷。 實現 Multi Raft Group 的最關鍵之處有兩點,**?第一是共享 Transport 層**,因為每一個 Raft Group 內部都需要向對應的 peer? 發送消息,如果不能共享 Transport 層,連接的開銷巨大;第二是線程模型,Mutli Raft Group 一定要共享一組線程池,否則會造成系統的線程數目過多,導致大量的 context switch 開銷。
對于每個 Partition來說,由于串行寫 WAL,為了提高吞吐,做 batch 是十分必要的。一般來講,batch 并沒有什么特別的地方,但是 Nebula 利用每個 part 串行的特點,做了一些特殊類型的 WAL,帶來了一些工程上的挑戰。
舉個例子,Nebula 利用 WAL 實現了無鎖的 CAS 操作,而每個 CAS 操作需要之前的 WAL 全部 commit 之后才能執行,所以對于一個 batch,如果中間夾雜了幾條 CAS 類型的 WAL, 我們還需要把這個 batch 分成粒度更小的幾個 group,group 之間保證串行。還有,command 類型的 WAL 需要它后面的 WAL 在其 commit 之后才能執行,所以整個 batch 劃分 group 的操作工程實現上比較有特色。焦作國醫胃腸醫院正規嗎_衛生局認證 焦作老品牌:https://www.jianshu.com/p/3c43af3bb611
Learner 這個角色的存在主要是為了?應對擴容?時,新機器需要"追"相當長一段時間的數據,而這段時間有可能會發生意外。如果直接以 follower 的身份開始追數據,就會使得整個集群的 HA 能力下降。 Nebula 里面 learner 的實現就是采用了上面提到的 command wal,leader 在寫 wal 時如果碰到 add learner 的 command, 就會將 learner 加入自己的 peers,并把它標記為 learner,這樣在統計多數派的時候,就不會算上 learner,但是日志還是會照常發送給它們。當然 learner 也不會主動發起選舉。
Transfer leadership 這個操作對于 balance 來講至關重要,當我們把某個?Paritition?從一臺機器挪到另一臺機器時,首先便會檢查 source 是不是 leader,如果是的話,需要先把他挪到另外的 peer 上面;在搬遷數據完畢之后,通常還要把 leader 進行一次 balance,這樣每臺機器承擔的負載也能保證均衡。
實現 transfer leadership, 需要注意的是 leader 放棄自己的 leadership,和 follower 開始進行 leader election 的時機。對于 leader 來講,當 transfer leadership command 在 commit 的時候,它放棄 leadership;而對于 follower 來講,當收到此 command 的時候就要開始進行 leader election, 這套實現要和 Raft 本身的 leader election 走一套路徑,否則很容易出現一些難以處理的 corner case。
為了避免腦裂,當一個 Raft Group 的成員發生變化時,需要有一個中間狀態, 這個狀態下 old group 的多數派與 new group 的多數派總是有 overlap,這樣就防止了 old group 或者新 group 單方面做出決定,這就是論文中提到的?joint consensus?。為了更加簡化,Diego Ongaro 在自己的博士論文中提出每次增減一個 peer 的方式,以保證 old group 的多數派總是與 new group 的多數派有 overlap。 Nebula 的實現也采用了這個方式,只不過 add member 與 remove member 的實現有所區別,具體實現方式本文不作討論,有興趣的同學可以參考 Raft Part class 里面?addPeer? /??removePeer? 的實現。
Snapshot 如何與 Raft 流程結合起來,論文中并沒有細講,但是這一部分我認為是一個 Raft 實現里最容易出錯的地方,因為這里會產生大量的 corner case。
舉一個例子,當 leader 發送 snapshot 過程中,如果 leader 發生了變化,該怎么辦? 這個時候,有可能 follower 只接到了一半的 snapshot 數據。 所以需要有一個?Partition 數據清理過程,由于多個?Partition?共享一份存儲,因此如何清理數據又是一個很麻煩的問題。另外,snapshot 過程中,會產生大量的 IO,為了性能考慮,我們不希望這個過程與正常的 Raft 共用一個 IO threadPool,并且整個過程中,還需要使用大量的內存,如何優化內存的使用,對于性能十分關鍵。由于篇幅原因,我們并不會在本文對這些問題展開講述,有興趣的同學可以參考?SnapshotManager? 的實現。
在 KVStore 的接口之上,Nebula 封裝有圖語義接口,主要的接口如下:
getNeighbors?:? 查詢一批點的出邊或者入邊,返回邊以及對應的屬性,并且需要支持條件過濾;
Insert vertex/edge?:? 插入一條點或者邊及其屬性;
getProps?: 獲取一個點或者一條邊的屬性;
這一層會將圖語義的接口轉化成 kv 操作。為了提高遍歷的性能,還要做并發操作。
在 KVStore 的接口上,Nebula 也同時封裝了一套 meta 相關的接口。Meta Service 不但提供了圖 schema 的增刪查改的功能,還提供了集群的管理功能以及用戶鑒權相關的功能。Meta Service?支持單獨部署,也支持使用多副本來保證數據的安全。
這篇文章給大家大致介紹了?Nebula Storage 層的整體設計, 由于篇幅原因, 很多細節沒有展開講, 歡迎大家到我們的微信群里提問,加入 Nebula Graph 交流群,請聯系 Nebula Graph 官方小助手微信號:NebulaGraphbot。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





