溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇文章給大家分享的是有關有哪些大數據開發離線計算框架知識點,小編覺得挺實用的,因此分享給大家學習,希望大家閱讀完這篇文章后可以有所收獲,話不多說,跟著小編一起來看看吧。
大數據開發離線計算框架知識點總結,大數據在帶來發展機遇的同時,也帶來了新的挑戰,催生了新技術的發展和舊技術的革新。大數據離線計算技術應用于靜態數據的離線計算和處理,框架設計的初衷是為了解決大規模、非實時數據計算,更加關注整個計算框架的吞吐量。
大數據離線計算框架介紹:
一、MapReduce計算框架
Hadoop是一個分布式系統架構,由Apache基金會所開發,其核心主要包括兩個組件:HDFS和MapReduce,前者為海量存儲提供了存儲,而后者為海量的數據提供了計算。這里我們主要關注MapReduce。以下資料來源于Hadoop的官方說明文檔和論文。
MapReduce是一個使用簡易的軟件框架,基于它寫出來的應用程序能夠運行在由上千個商用機器組成的大型集群上,并以一種可靠容錯的方式并行處理上T級別的數據集。將計算過程分為兩個階段,Map和Reduce,Map階段并行處理輸入的數據,Reduce階段對Map結果進行匯總。
一個MapReduce作業通常會把輸入的數據集切分為若干獨立的數據塊,由Map任務以完全并行的方式處理它們。框架會對Map的輸出先進行排序,然后把結果輸入給Reduce任務。通常作業的輸入和輸出都會被存儲在文件系統中。整個框架負責任務的調度和監控,以及重新執行已經失敗的任務。
通常,MapReduce框架和分布式文件系統是運行在一組相同的節點上的,也就是說,計算節點和存儲節點通常在一起。這種配置允許框架在那些已經存好數據的節點上高效地調度任務,這可以使整個集群的網絡帶寬被非常高效地利用。
MapReduce框架由一個單獨的master JobTracker 和每個集群節點一個slave TaskTracker共同組成。master負責調度構成一個作業的所有任務,這些任務分布在不同的slave上,master監控它們的執行,重新執行已經失敗的任務。而slave僅負責執行由master指派的任務。
應用程序至少應該指明輸入/輸出的路徑,并通過實現合適的接口或抽象類提供map和reduce函數。再加上其他作業的參數,就構成了作業配置。然后,Hadoop的Job Client提交作業和配置信息給JobTracker,后者負責分發這些軟件和配置信息給slave、調度任務并監控它們的執行,同時提供狀態和診斷信息給Job Client。
應用程序通常會通過提供map和reduce來實現 Mapper和Reducer接口,它們組成作業的核心。map函數接受一個鍵值對,產生一組中間鍵值對。MapReduce框架會將map函數產生的中間鍵值對中鍵相同的值傳遞給一個reduce函數。reduce函數接受一個鍵,以及相關的一組值,將這組值進行合并產生一組規模更小的值。
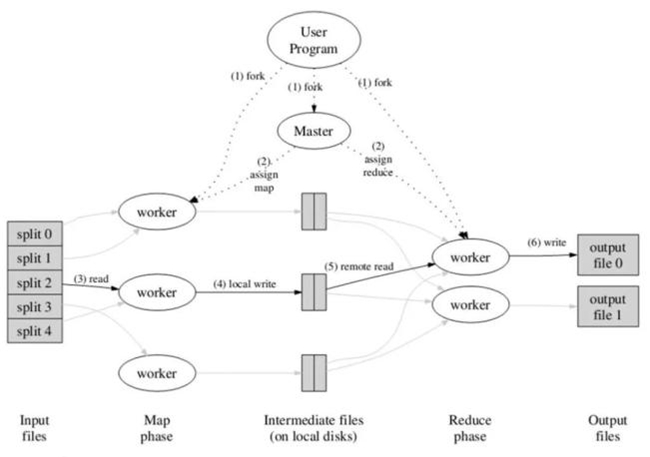
如圖1所示,MapReduce的工作流程中,一切都是從最上方的user program開始的,user program鏈接了MapReduce庫,實現了最基本的Map函數和Reduce函數。圖中執行的順序都用數字標記了。
二、Spark計算框架
Spark基于MapReduce算法實現的離線計算,擁有Hadoop MapReduce所具有的優點;但不同于MapReduce的是Job中間輸出結果可以保存在內存中,從而不再需要讀寫HDFS,因此Spark能更好地適用于數據挖掘與機器學習等需要迭代的Map Reduce的算法。
Spark中一個主要的結構是RDD(Resilient Distributed Datasets),這是一種只讀的數據劃分,并且可以在丟失之后重建。它利用了Lineage的概念實現容錯,如果一個RDD丟失了,那么有足夠的信息支持RDD重建。RDD可以被認為是提供了一種高度限制的共享內存,但是這些限制可以使得自動容錯的開支變得很低。
RDD使用Lineage的容錯機制,即每一個RDD都包含關于它是如何從其他RDD變換過來的以及如何重建某一塊數據的信息。RDD僅支持粗顆粒度變換,即僅記錄在單個塊上執行的單個操作,然后創建某個RDD的變換序列存儲下來,當數據丟失時,我們可以用變換序列來重新計算,恢復丟失的數據,以達到容錯的目的。
Spark中的應用程序稱為驅動程序,這些驅動程序可實現在單一節點上執行的操作或在一組節點上并行執行的操作。驅動程序可以在數據集上執行兩種類型的操作:動作和轉換。動作會在數據集上執行一個計算,并向驅動程序返回一個值;而轉換會從現有數據集中創建一個新的數據集。動作的示例包括執行一個Reduce操作以及在數據集上進行迭代。轉換示例包括Map操作和Cache操作。
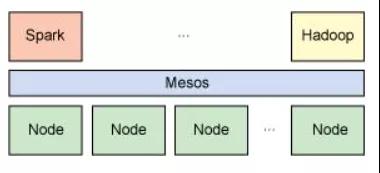
與Hadoop類似,Spark支持單節點集群或多節點集群。對于多節點操作,Spark依賴于Mesos集群管理器。Mesos為分布式應用程序的資源共享和隔離提供了一個有效平臺,參考圖2。
三、Dryad計算框架
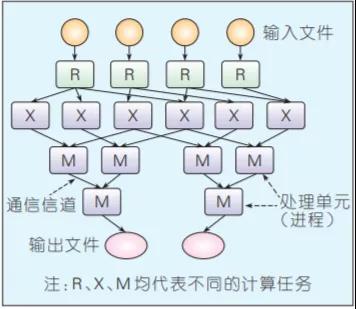
Dryad是構建微軟云計算基礎設施的核心技術。編程模型相比MapReduce更具一般性——用有向無環圖(DAG)描述任務的執行,其中用戶指定的程序是DAG圖的節點,數據傳輸的通道是邊,可通過文件、共享內存或者傳輸控制協議(TCP)通道來傳遞數據,任務相當于圖的生成器,可以合成任何圖,甚至在執行的過程中這些圖也可以發生變化,以響應計算過程中發生的事件。圖3給出了整個任務的處理流程。
Dryad在容錯方面支持良好,底層的數據存儲支持數據備份;在任務調度方面,Dryad的適用性更廣,不僅適用于云計算,在多核和多處理器以及異構集群上同樣有良好的性能;在擴展性方面,可伸縮于各種規模的集群計算平臺,從單機多核計算機到由多臺計算機組成的集群,甚至擁有數千臺計算機的數據中心。Microsoft借助Dryad,在大數據處理方面也形成了完整的軟件棧,部署了分布式存系統Cosmos,提供DryadLINQ編程語言,使普通程序員可以輕易進行大規模的分布式計算。
離線計算的數據量大且計算周期長,是在大量數據基礎上進行復雜的批量運算。離線計算的數據是不再會發生變化,通常離線計算的任務都是定時的,使用場景一般式對時效性要求比較低的。
以上就是有哪些大數據開發離線計算框架知識點,小編相信有部分知識點可能是我們日常工作會見到或用到的。希望你能通過這篇文章學到更多知識。更多詳情敬請關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





