溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要講解了“Python的Scrapy框架知識點有哪些”,文中的講解內容簡單清晰,易于學習與理解,下面請大家跟著小編的思路慢慢深入,一起來研究和學習“Python的Scrapy框架知識點有哪些”吧!
Scrapy是一個快速、高層次的屏幕抓取和web抓取的框架,可用于數據挖掘、監測和自動化檢測,任何人都可以根據需要去進行修改。
1.Scrapy引擎(Scrapy Engine):負責控制數據流在系統的所以組件中的流動,并在相應動作發生時觸發事件。
2.調度器(Scheduler):從引擎接受reques并將其入隊,便于以后請求它們提供給引擎。
3.下載器(Downloader):負責獲取網頁數據并且提供給引擎,然后提供給Spider。
4.Spiders: 指Scrapy用戶編寫用于分析response并且提取item或額外跟進的URL類人。每個Spider負責處理一些特定網站。
5.Item Pipeline:負責處理被Spider提取出來的item。典型的處理有清潔、驗證及持久化
6.下載器中間件(Downloader Middlewares):指在引擎及下載器之間的特定鉤子(specific hook),處理Downloader 傳遞給引擎的response。它提供一個簡便的機制,通過插入自定義代碼來擴展Scrapy功能。
7.Spiders中間件(Spider Middlewares):指在引擎及Spider之間的特定鉤子(specific hook),處理Spider 的輸入(response)和輸出(items及requests)。它提供一個簡便的機制,通過插入自定義代碼來擴展Scrapy功能。
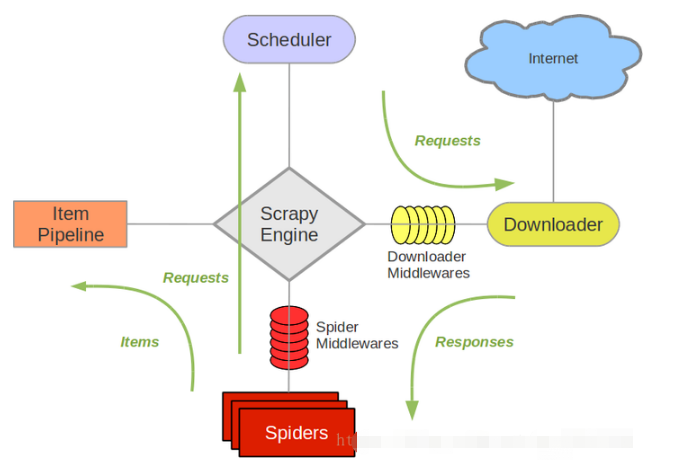
1.引擎向spider要URL
2.引擎將要爬取的URL給調度器
3.調度器會將URL生成請求對象放入指定的隊列中
4.從隊列中出隊一個請求
5.引擎將請求交給下載器進行處理
6.下載器發送請求獲取互聯網數據
7.下載器將數據返回給引擎
8.引擎將數據再次給到spiders
9.spiders通過xpath解析該數據,得到數據或URL
10.spiders將數據或URL給到引擎
11.引擎判斷該數據是URL還是數據,交給管道處理,URL交給調度器處理
12.當調度器里沒有任何數據之后,整個程序停止
下面是我根據工作原理畫的可以結合去看:

感謝各位的閱讀,以上就是“Python的Scrapy框架知識點有哪些”的內容了,經過本文的學習后,相信大家對Python的Scrapy框架知識點有哪些這一問題有了更深刻的體會,具體使用情況還需要大家實踐驗證。這里是億速云,小編將為大家推送更多相關知識點的文章,歡迎關注!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





