溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
作者 | 阿里云容器平臺高級技術專家 曾凡松(逐靈)
本文主要介紹阿里巴巴在大規模生產環境中落地 Kubernetes 的過程中,在集群規模上遇到的典型問題以及對應的解決方案,內容包含對 etcd、kube-apiserver、kube-controller 的若干性能及穩定性增強,這些關鍵的增強是阿里巴巴內部上萬節點的 Kubernetes 集群能夠平穩支撐?2019 年天貓 618 大促的關鍵所在。
從阿里巴巴最早期的 AI 系統(2013)開始,集群管理系統經歷了多輪的架構演進,到 2018 年全面的應用 Kubernetes ,這期間的故事是非常精彩的,有機會可以單獨給大家做一個分享。這里忽略系統演進的過程,不去討論為什么 Kubernetes 能夠在社區和公司內部全面的勝出,而是將焦點關注到應用 Kubernetes 中會遇到什么樣的問題,以及我們做了哪些關鍵的優化。
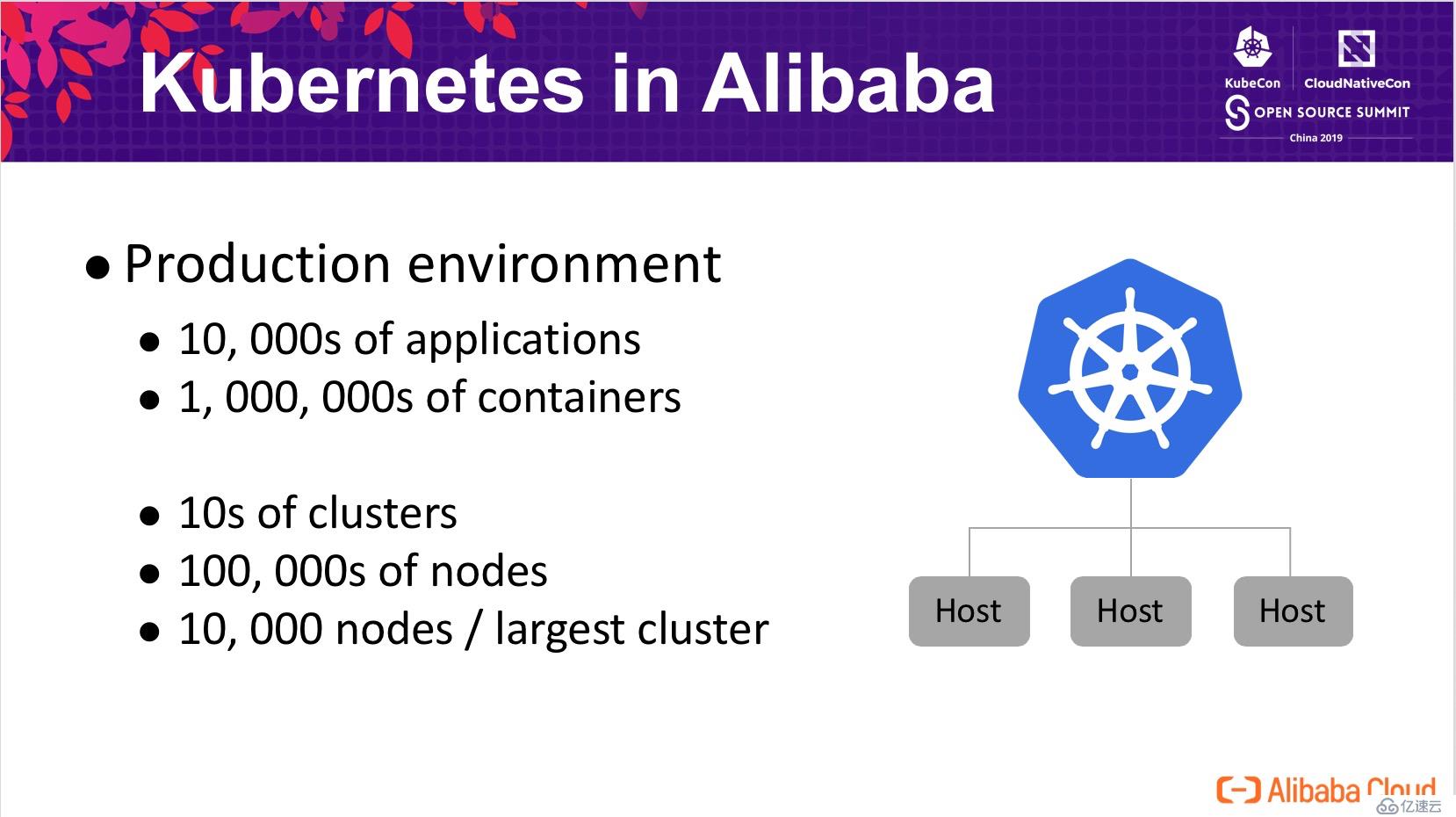
在阿里巴巴的生產環境中,容器化的應用超過了 10k 個,全網的容器在百萬的級別,運行在十幾萬臺宿主機上。支撐阿里巴巴核心電商業務的集群有十幾個,最大的集群有幾萬的節點。在落地 Kubernetes 的過程中,在規模上面臨了很大的挑戰,比如如何將 Kubernetes 應用到超大規模的生產級別。
羅馬不是一天就建成的,為了了解 Kubernetes 的性能瓶頸,我們結合阿里的生產集群現狀,估算了在 10k 個節點的集群中,預計會達到的規模:
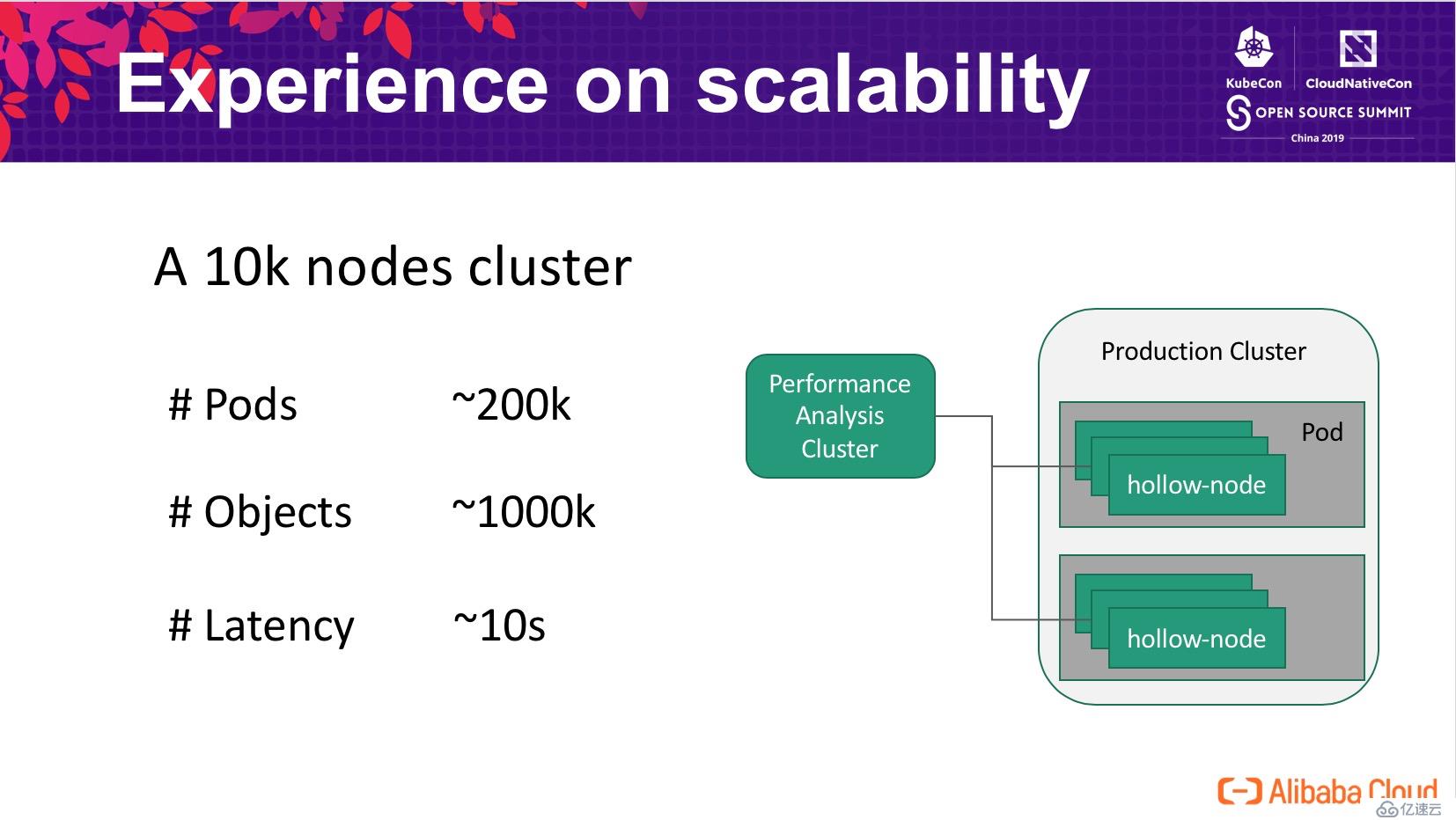
我們基于 Kubemark 搭建了大規模集群模擬的平臺,通過一個容器啟動多個(50個)Kubemark 進程的方式,使用了 200 個 4c 的容器模擬了 10k 節點的 kubelet。在模擬集群中運行常見的負載時,我們發現一些基本的操作比如 Pod 調度延遲非常高,達到了驚人的 10s 這一級別,并且集群處在非常不穩定的狀態。
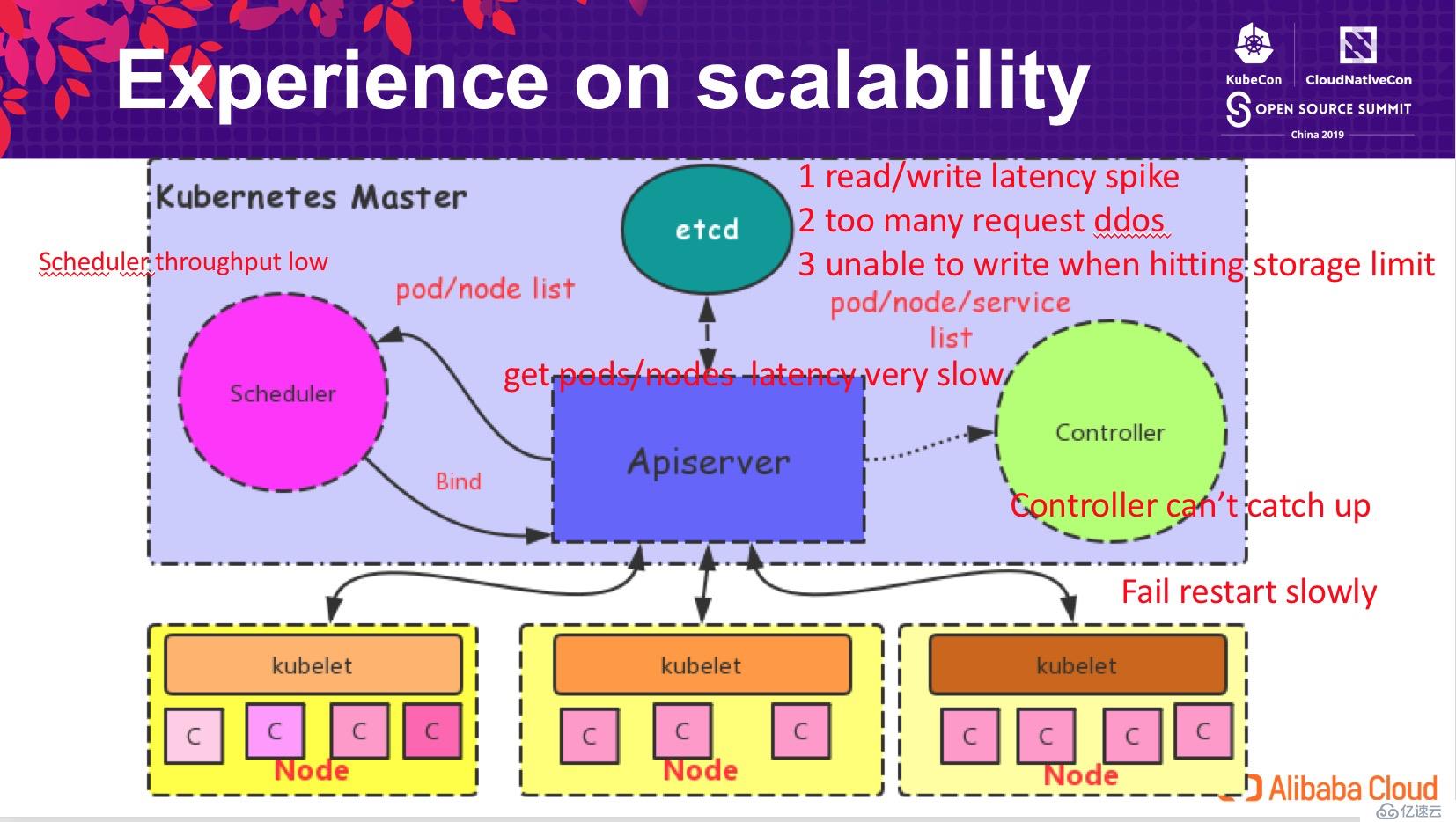
當 Kubernetes 集群規模達到 10k 節點時,系統的各個組件均出現相應的性能問題,比如:
為了解決這些問題,阿里云容器平臺在各方面都做了很大的努力,改進 Kubernetes 在大規模場景下的性能。
首先是 etcd 層面,作為 Kubernetes 存儲對象的數據庫,其對 Kubernetes 集群的性能影響至關重要。
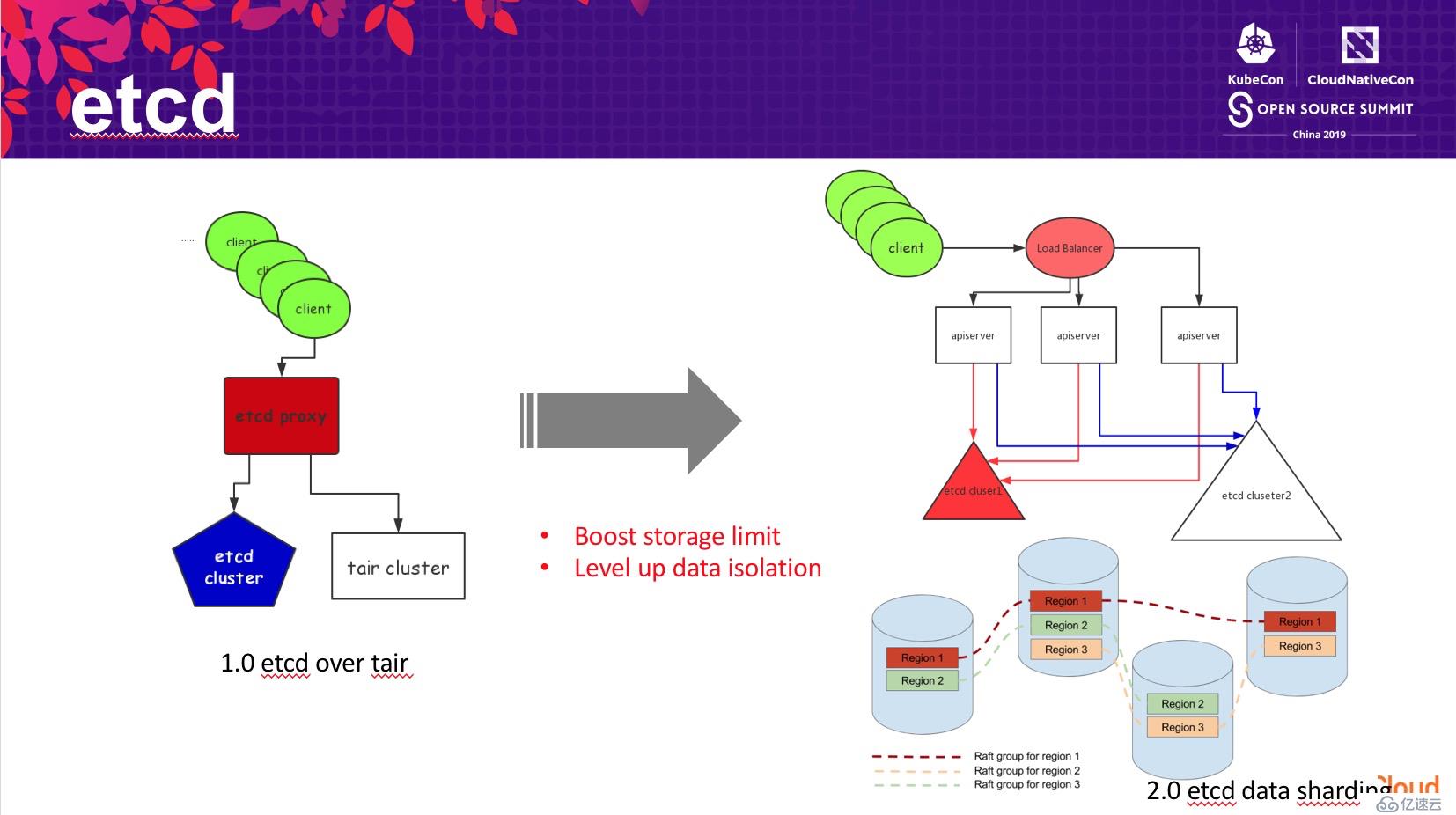
第一版本的改進,我們通過將 etcd 的數據轉存到 tair 集群中,提高了 etcd 存儲的數據總量。但這個方式有一個顯著的弊端是額外增加的 tair 集群,增加的運維復雜性對集群中的數據安全性帶來了很大的挑戰,同時其數據一致性模型也并非基于 raft 復制組,犧牲了數據的安全性。
第二版本的改進,我們通過將 API Server 中不同類型的對象存儲到不同的 etcd 集群中。從 etcd 內部看,也就對應了不同的數據目錄,通過將不同目錄的數據路由到不同的后端 etcd 中,從而降低了單個 etcd 集群中存儲的數據總量,提高了擴展性。
為了解決該問題,我們設計了基于 segregrated hashmap 的空閑頁面管理算法,hashmap 以連續 page 大小為 key, 連續頁面起始 page id 為? value。通過查這個 segregrated hashmap?實現 O(1) 的空閑 page 查找,極大地提高了性能。在釋放塊時,新算法嘗試和地址相鄰的 page 合并,并更新 segregrated hashmap。更詳細的算法分析可以見已發表在 CNCF 博客的博文:
https://www.cncf.io/blog/2019/05/09/performance-optimization-of-etcd-in-web-scale-data-scenario/
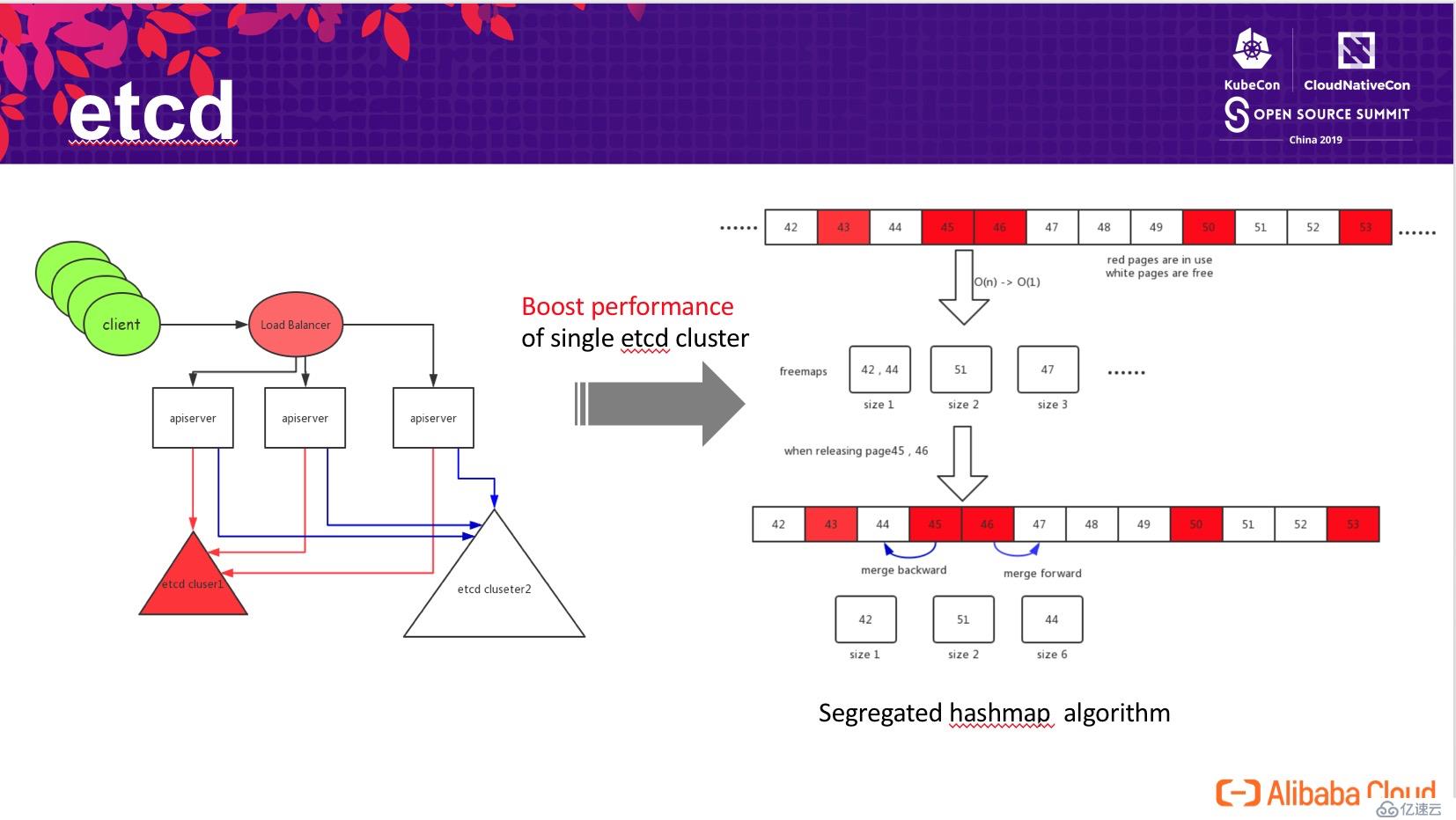
通過這個算法改進,我們可以將 etcd 的存儲空間從推薦的 2GB 擴展到 100GB,極大的提高了 etcd 存儲數據的規模,并且讀寫無顯著延遲增長。除此之外,我們也和谷歌工程師協作開發了 etcd raft learner(類 zookeeper observer)/fully concurrent read 等特性,在數據的安全性和讀寫性能上進行增強。這些改進已貢獻開源,將在社區 etcd 3.4 版本中發布。
在 Kubernetes 集群中,影響其擴展到更大規模的一個核心問題是如何有效的處理節點的心跳。在一個典型的生產環境中 (non-trival),kubelet 每 10s 匯報一次心跳,每次心跳請求的內容達到 15kb(包含節點上數十計的鏡像,和若干的卷信息),這會帶來兩大問題:
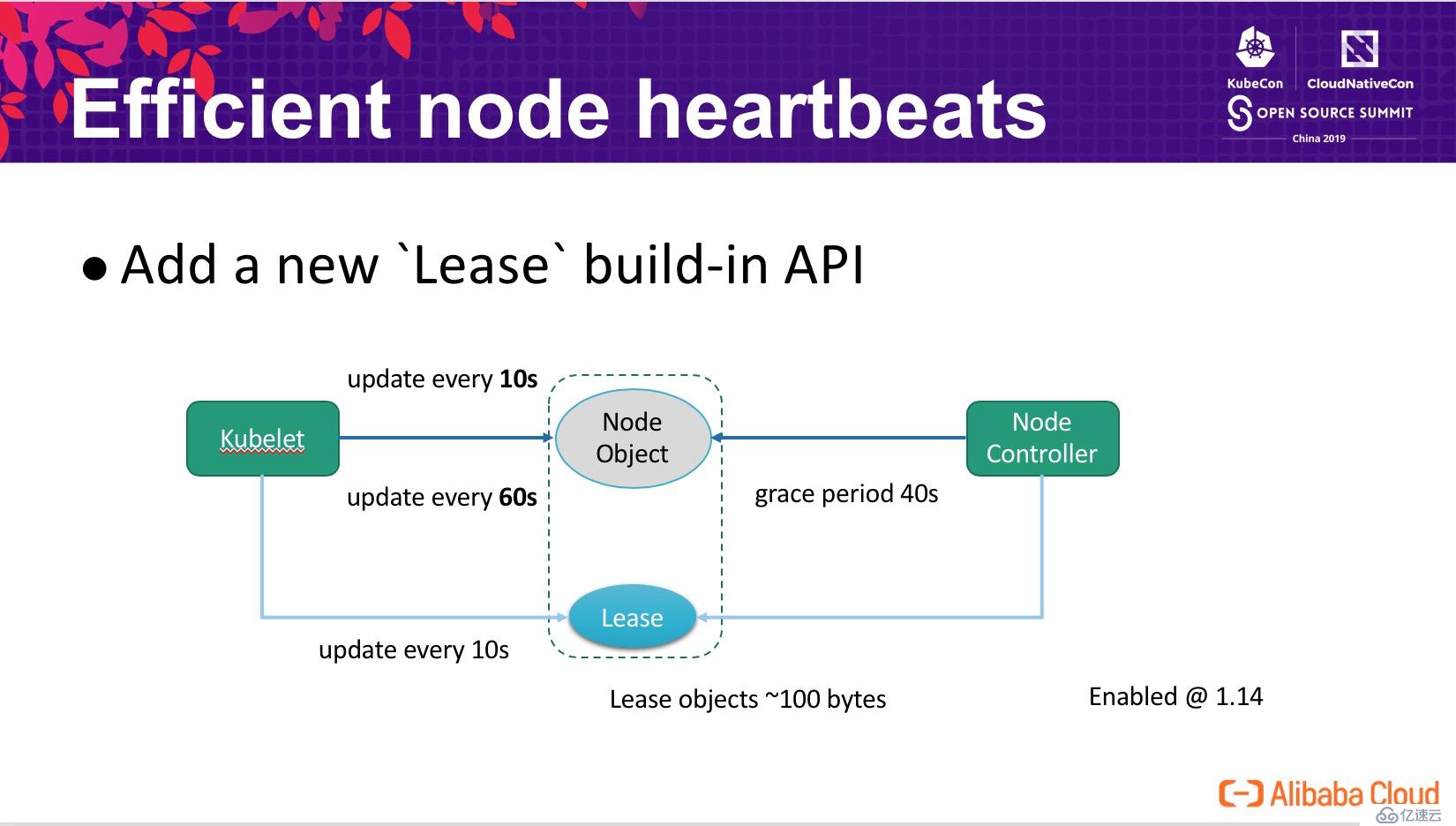
為了解決這個問題,Kubernetes 引入了一個新的 build-in Lease API?,將與心跳密切相關的信息從 node 對象中剝離出來,也就是上圖中的 Lease?。原本 kubelet 每 10s 更新一次 node 對象升級為:
因為 Lease?對象非常小,因此其更新的代價遠小于更新 node 對象。kubernetes 通過這個機制,顯著的降低了 API Server 的 CPU 開銷,同時也大幅減小了 etcd 中大量的 transaction logs,成功將其規模從 1000 擴展到了幾千個節點的規模,該功能在社區 Kubernetes-1.14 中已經默認啟用。
在生產集群中,出于性能和可用性的考慮,通常會部署多個節點組成高可用 Kubernetes 集群。但在高可用集群實際的運行中,可能會出現多個 API Server 之間的負載不均衡,尤其是在集群升級或部分節點發生故障重啟的時候。這給集群的穩定性帶來了很大的壓力,原本計劃通過高可用的方式分攤 API Server 面臨的壓力,但在極端情況下所有壓力又回到了一個節點,導致系統響應時間變長,甚至擊垮該節點繼而導致雪崩。
下圖為壓測集群中模擬的一個 case,在三個節點的集群,API Server 升級后所有的壓力均打到了其中一個 API Server 上,其 CPU 開銷遠高于其他兩個節點。
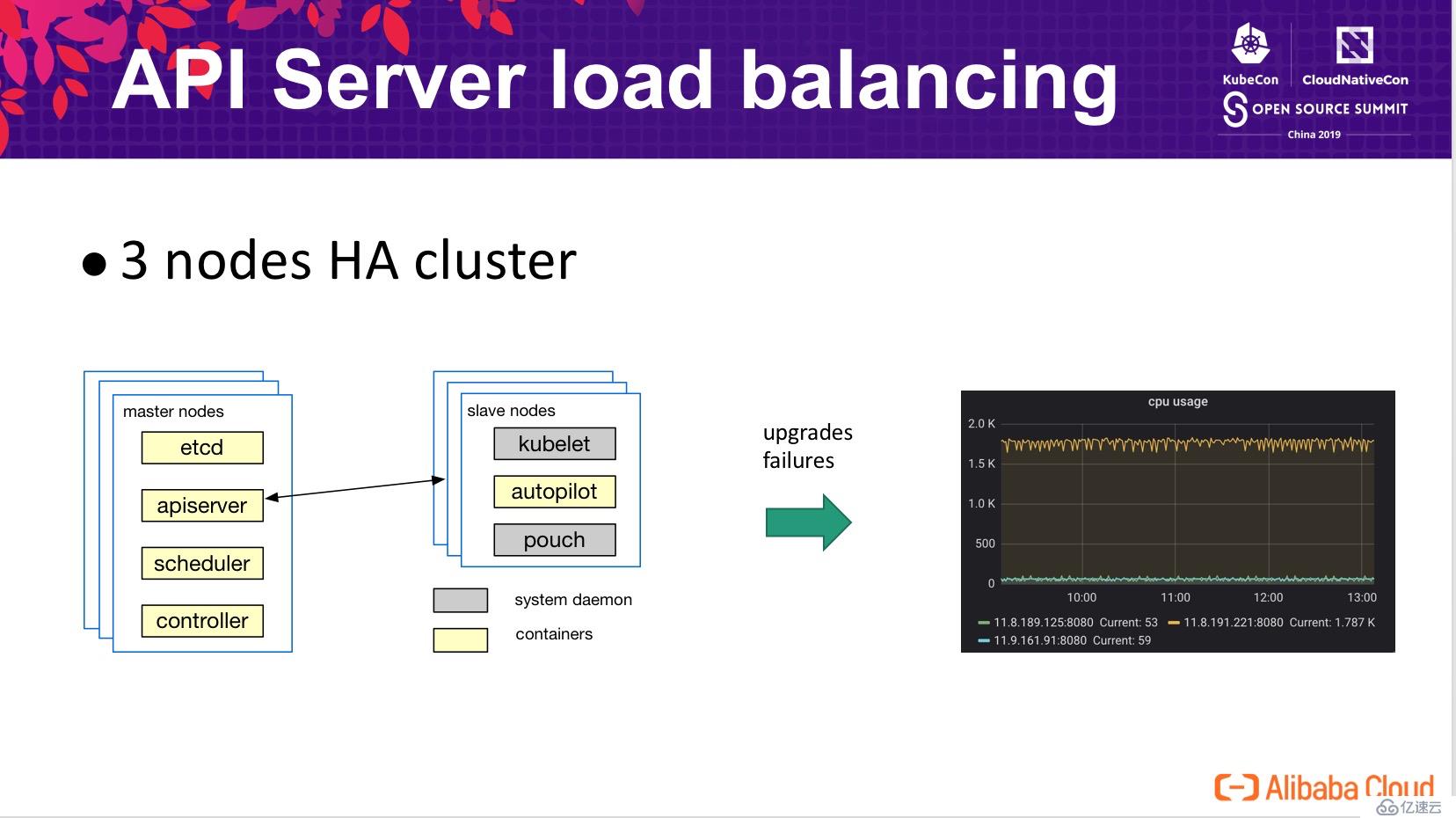
解決負載均衡問題,一個自然的思路就是增加 load balancer。前文的描述中提到,集群中主要的負載是處理節點的心跳,那我們就在 API Server 與 kubelet 中間增加 lb,有兩個典型的思路:
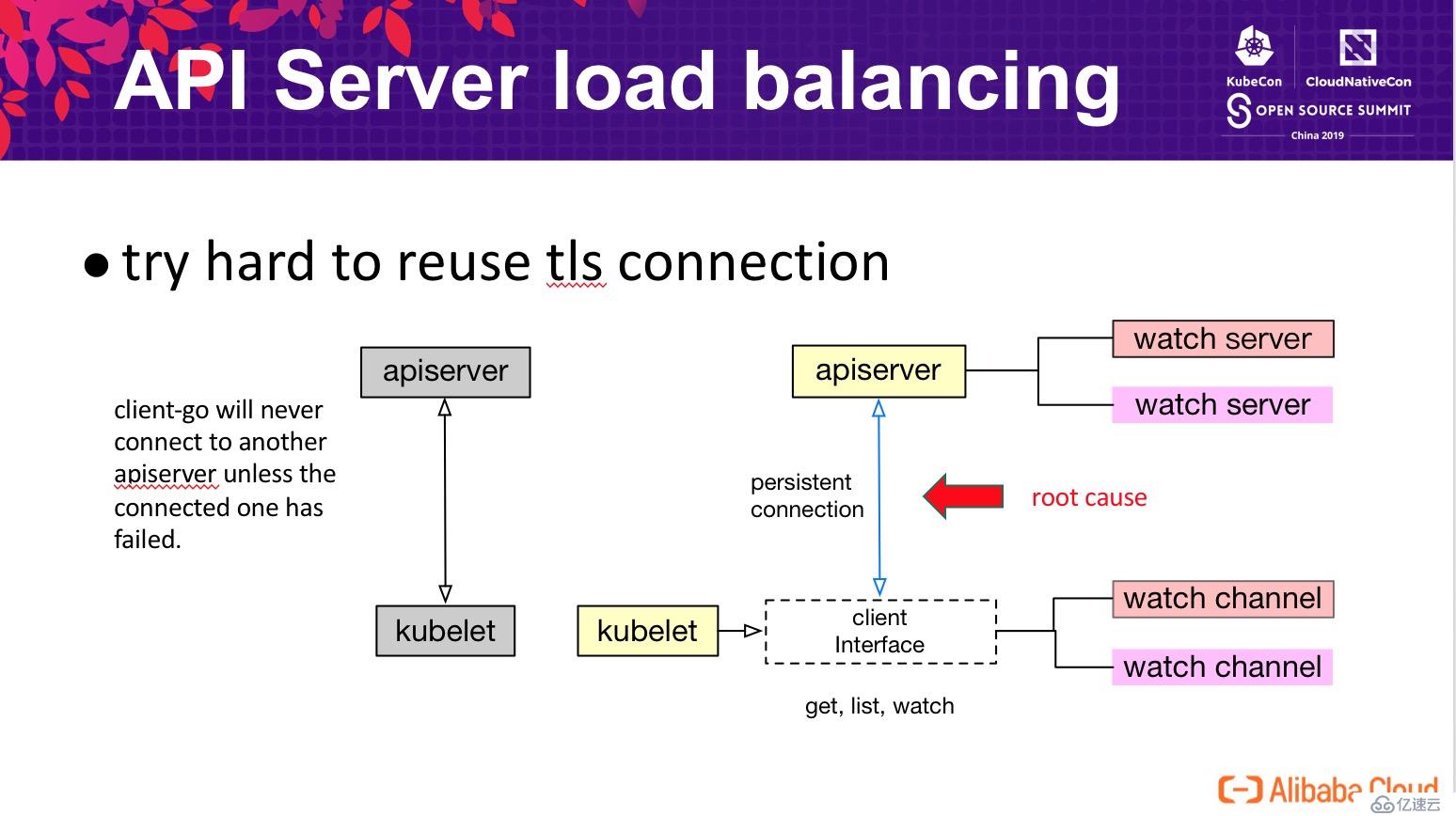
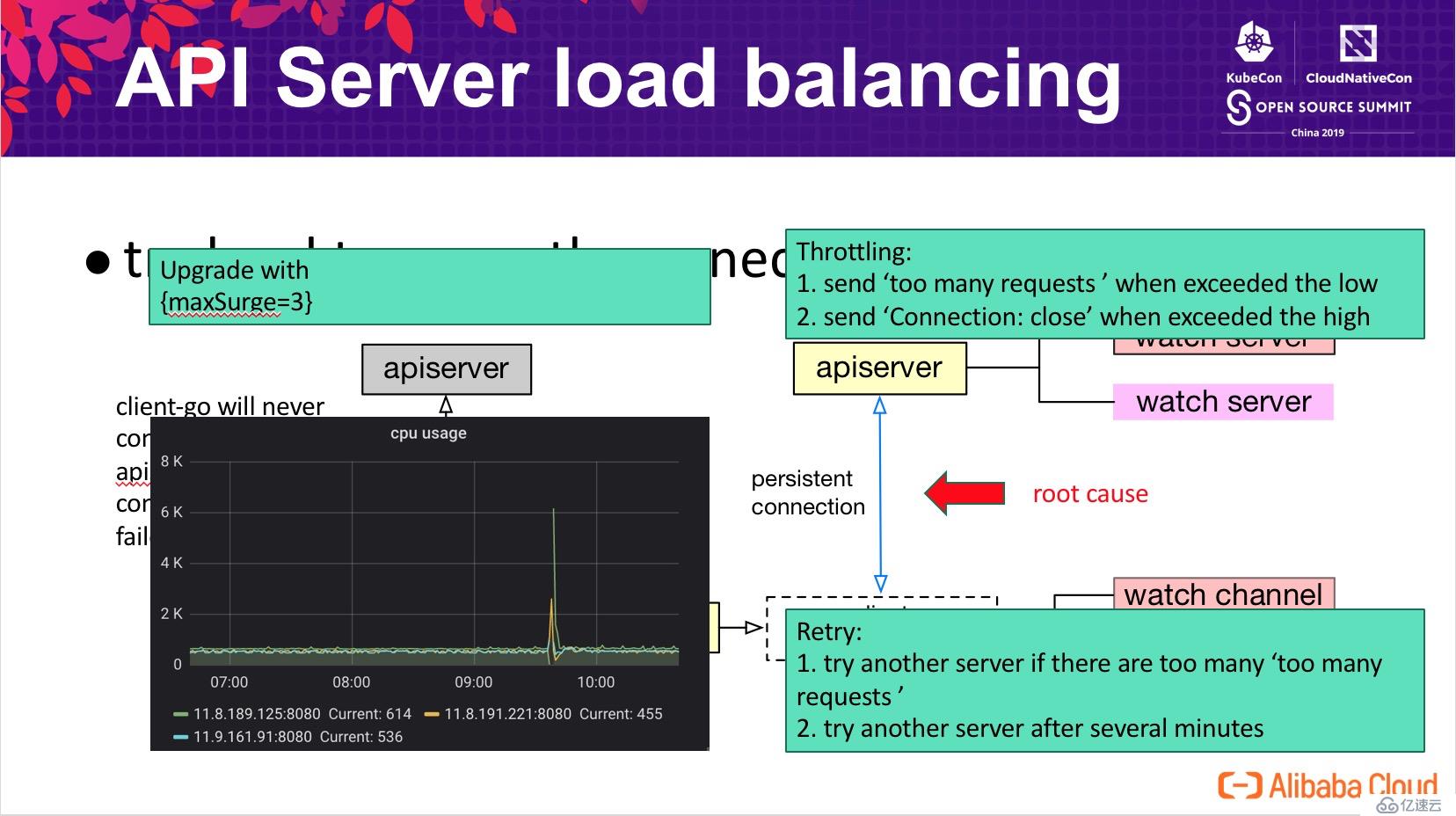
通過壓測環境驗證發現,增加 lb 并不能很好的解決上面提到的問題,我們必須要深入理解 Kubernetes 內部的通信機制。深入到 Kubernetes 中研究發現,為了解決 tls 連接認證的開銷,Kubernetes 客戶端做了很多的努力確保“盡量復用同樣的 tls 連接”,大多數情況下客戶端 watcher 均工作在下層的同一個 tls 連接上,僅當這個連接發生異常時,才可能會觸發重連繼而發生 API Server 的切換。其結果就是我們看到的,當 kubelet 連接到其中一個 API Server 后,基本上是不會發生負載切換。為了解決這個問題,我們進行了三個方面的優化:
409 - too many requests?提醒客戶端退避;當自身負載超過一個更高的閾值時,通過關閉客戶端連接拒絕請求;409?時,嘗試重建連接切換 API Server;定期地重建連接切換 API Server 完成洗牌;如上圖左下角監控圖所示,增強后的版本可以做到 API Server 負載基本均衡,同時在顯示重啟兩個節點(圖中抖動)時,能夠快速的自動恢復到均衡狀態。
List-Watch 是 Kubernetes 中 Server 與 Client 通信最核心一個機制,etcd 中所有對象及其更新的信息,API Server 內部通過 Reflector 去 watch?etcd 的數據變化并存儲到內存中,controller/kubelets 中的客戶端也通過類似的機制去訂閱數據的變化。
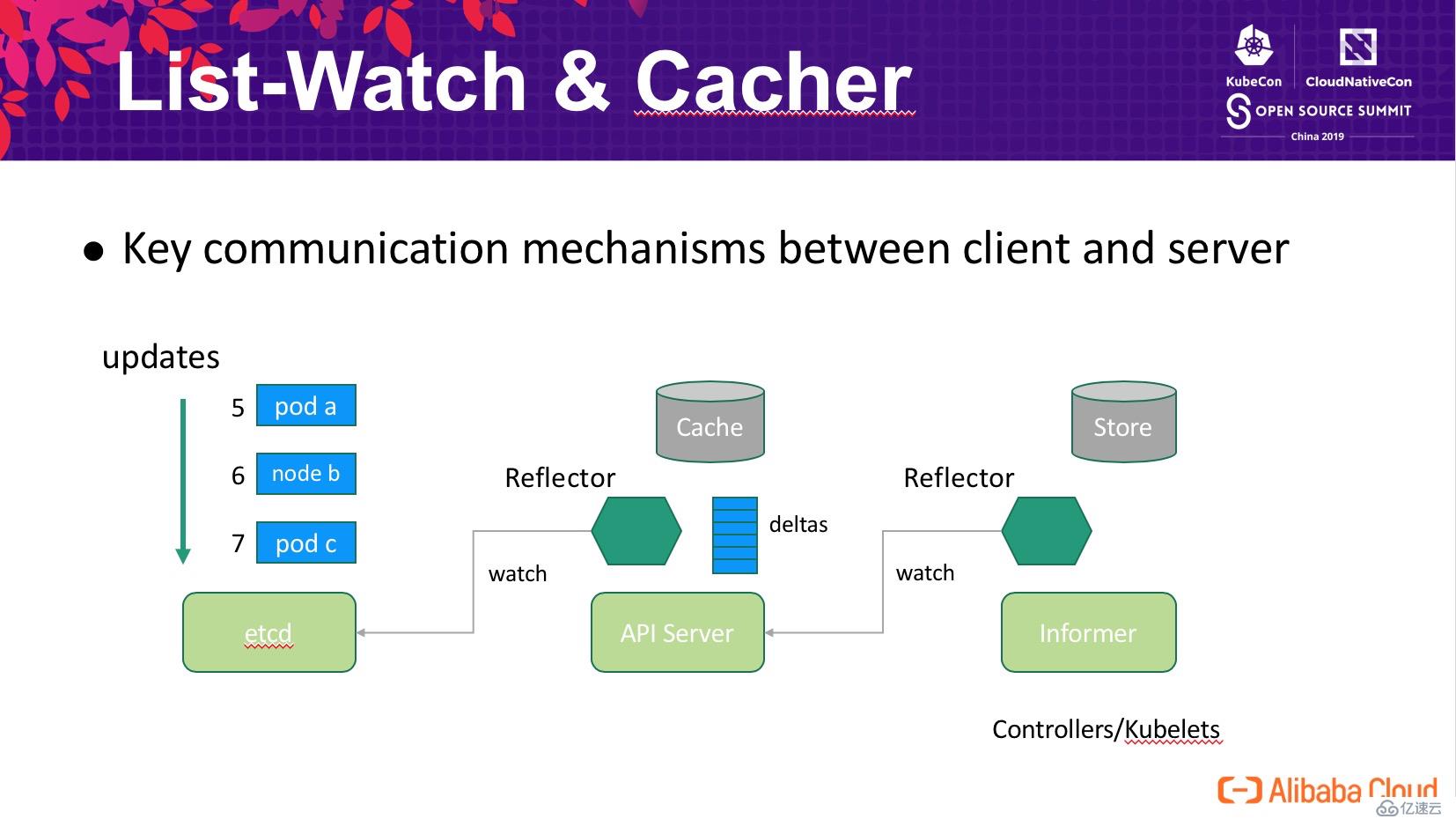
在 List-Watch 機制中面臨的一個核心問題是,當 Client 與 Server 之間的通信斷開時,如何確保重連期間的數據不丟,這在 Kubernetes 中通過了一個全局遞增的版本號 resourceVersion?來實現。如下圖所示 Reflector 中保存這當前已經同步到的數據版本,重連時 Reflector 告知 Server 自己當前的版本(5),Server 根據內存中記錄的最近變更歷史計算客戶端需要的數據起始位置(7)。
這一切看起來十分簡單可靠,但是...
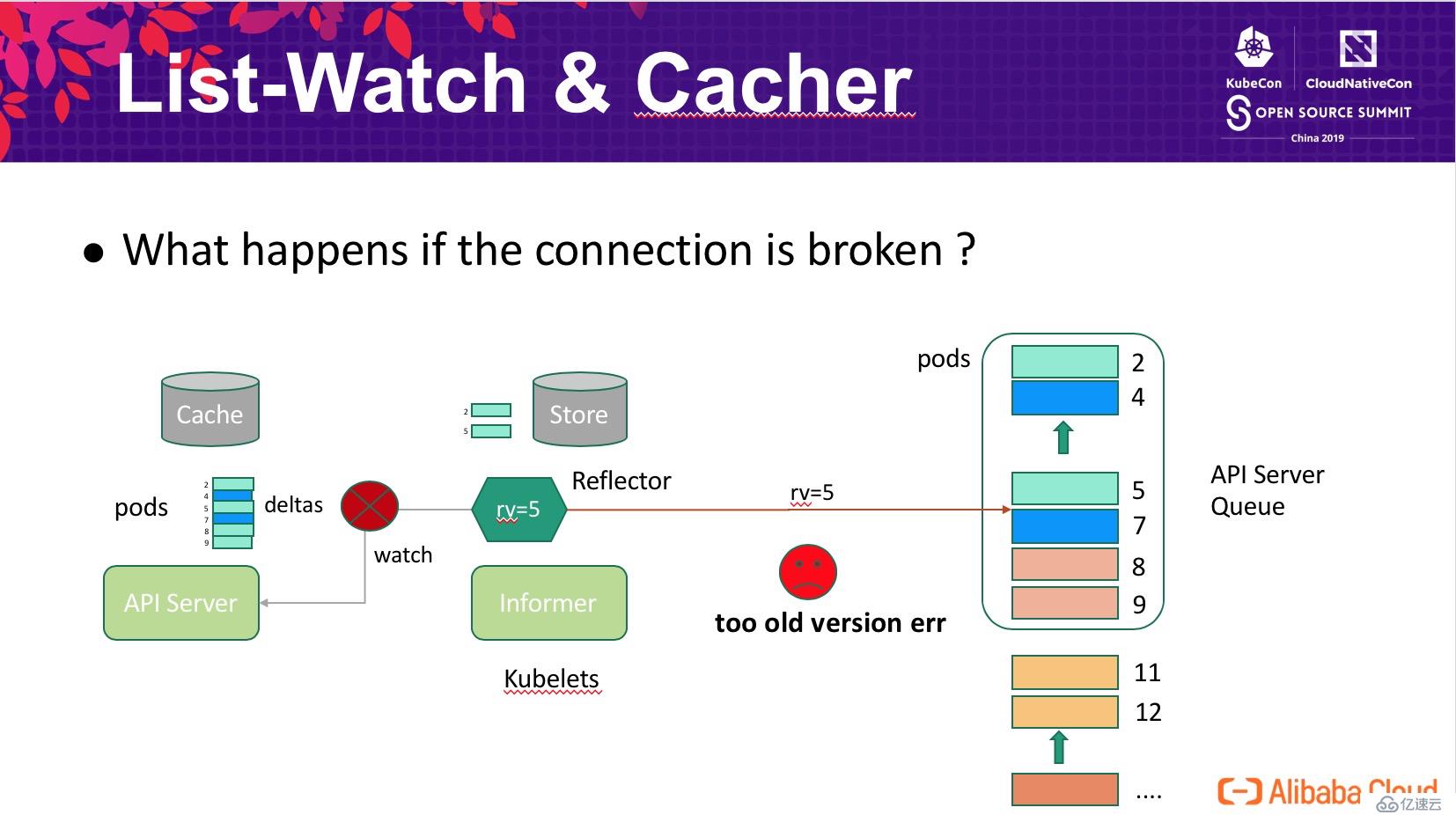
在 API Server 內部,每個類型的對象會存儲在一個叫做 storage?的對象中,比如會有:
每個類型的 storage 會有一個有限的隊列,存儲對象最近的變更,用于支持 watcher 一定的滯后(重試等場景)。一般來說,所有類型的類型共享一個遞增版本號空間(1, 2, 3, ..., n),也就是如上圖所示,pod 對象的版本號僅保證遞增不保證連續。Client 使用 List-Watch 機制同步數據時,可能僅關注 pods 中的一部分,最典型的 kubelet 僅關注和自己節點相關的 pods,如上圖所示,某個 kubelet 僅關注綠色的 pods (2, 5)。
因為 storage 隊列是有限的(FIFO),當 pods 的更新時隊列,舊的變更就會從隊列中淘汰。如上圖所示,當隊列中的更新與某個 Client 無關時,Client 進度仍然保持在 rv=5,如果 Client 在 5 被淘汰后重連,這時候 API Server 無法判斷 5 與當前隊列最小值(7)之間是否存在客戶端需要感知的變更,因此返回 Client too old version err?觸發 Client 重新 list 所有的數據。為了解決這個問題,Kubernetes 引入 Watch bookmark?機制:
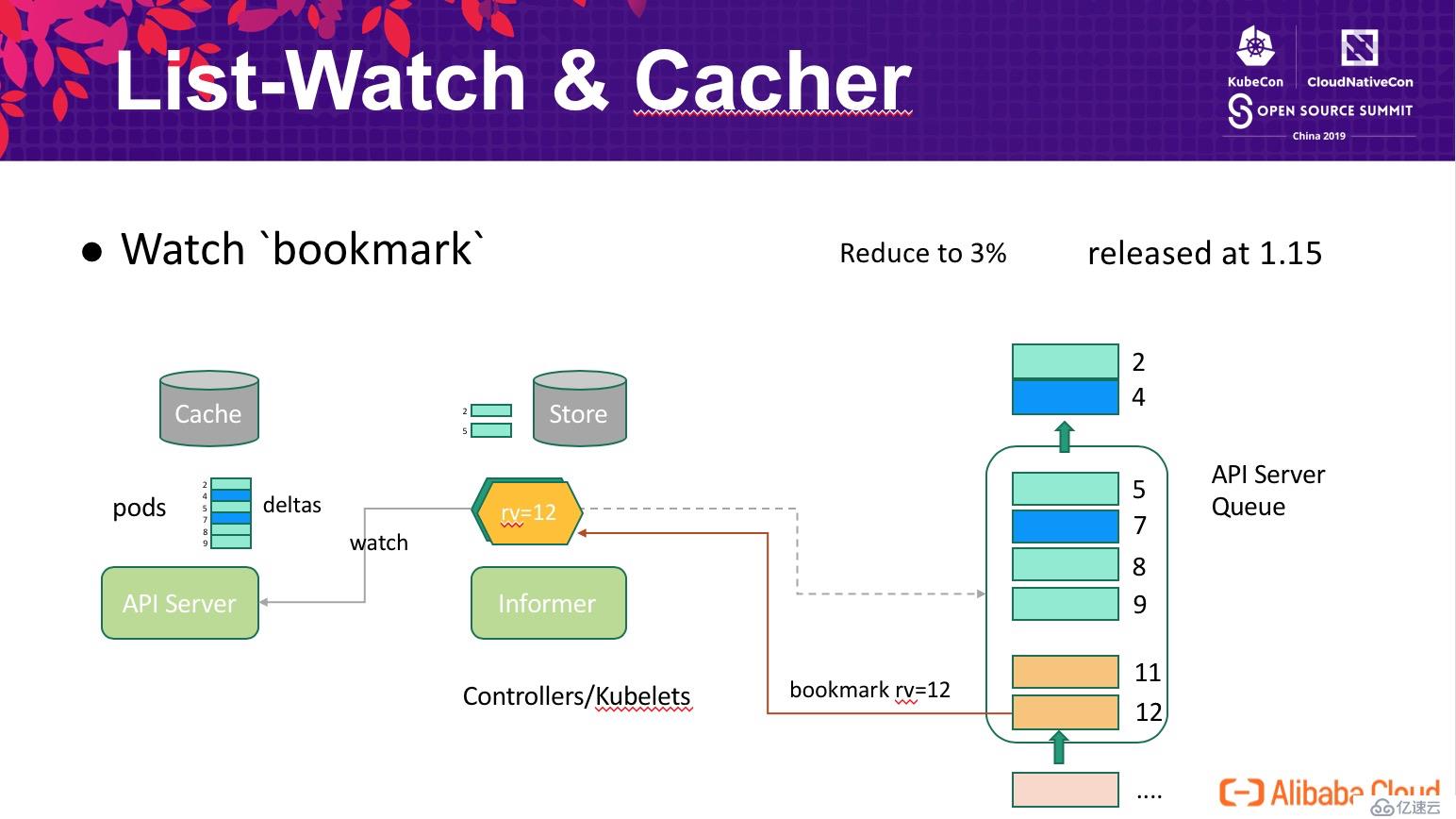
bookmark 的核心思想概括起來就是在 Client 與 Server 之間保持一個“心跳”,即使隊列中無 Client 需要感知的更新,Reflector 內部的版本號也需要及時的更新。如上圖所示,Server 會在合適的適合推送當前最新的 rv=12 版本號給 Client,使得 Client 版本號跟上 Server 的進展。bookmark 可以將 API Server 重啟時需要重新同步的事件降低為原來的 3%(性能提高了幾十倍),該功能有阿里云容器平臺開發,已經發布到社區 Kubernetes-1.15 版本中。
除 List-Watch 之外,另外一種客戶端的訪問模式是直接查詢 API Server,如下圖所示。為了保證客戶端在多個 API Server 節點間讀到一致的數據,API Server 會通過獲取 etcd 中的數據來支持 Client 的查詢請求。從性能角度看,這帶來了幾個問題:
Quorum read?,這個查詢開銷是集群級別,無法擴展的。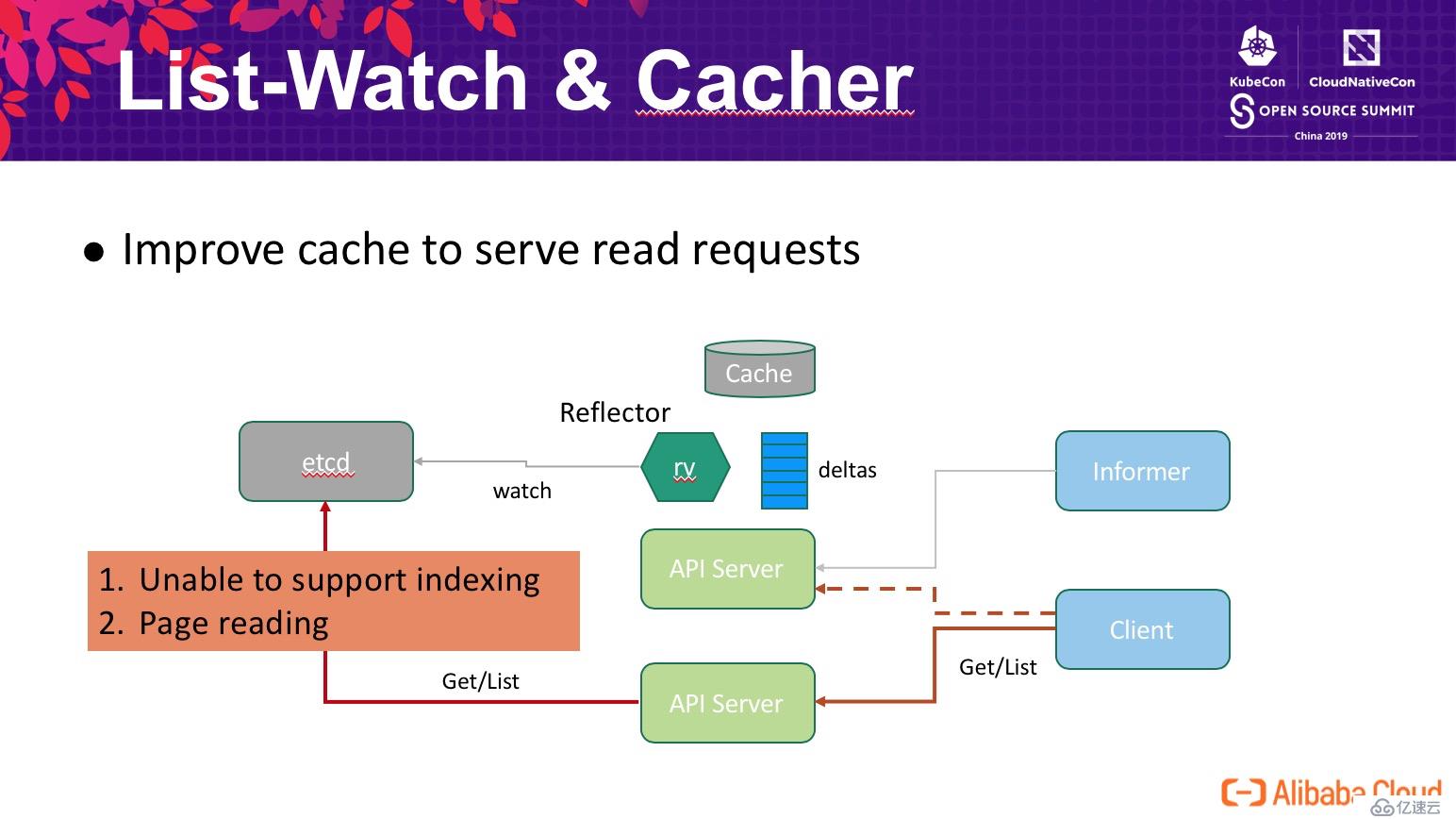
為了解決這個問題,我們設計了 API Server 與 etcd 的數據協同機制,確保 Client 能夠通過 API Server 的 cache 獲取到一致的數據,其原理如下圖所示,整體工作流程如下:
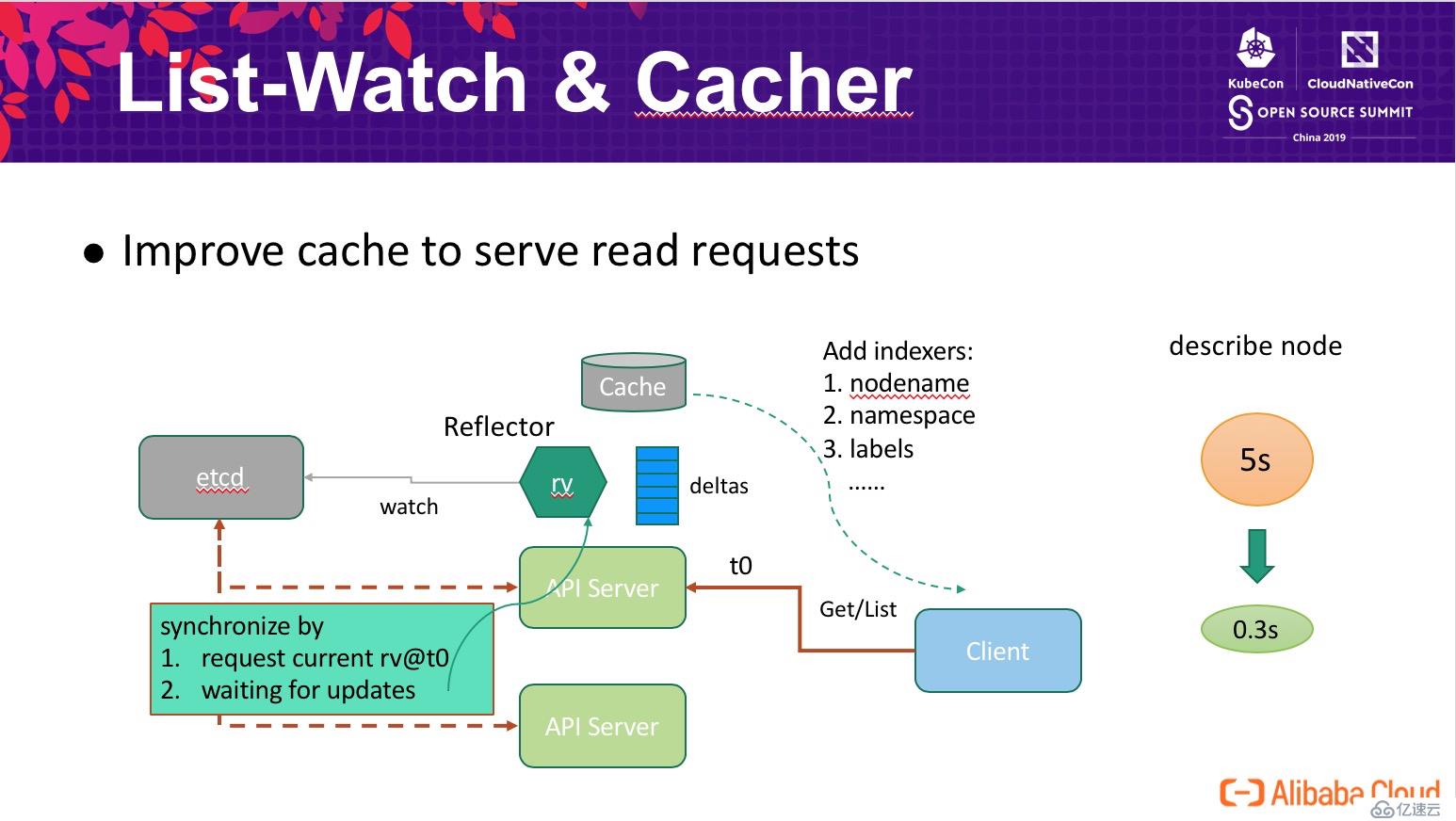
這個方式并未打破 Client 的一致性模型(感興趣的可以自己論證一下),同時通過 cache 響應用戶請求時我們可以靈活的增強查詢能力,比如支持 namespace nodename/labels 索引。該增強大幅提高了 API Server 的讀請求處理能力,在萬臺規模集群中典型的 describe node 的時間從原來的 5s 降低到 0.3s(觸發了 node name 索引),其他如 get nodes 等查詢操作的效率也獲得了成倍的增長。
在 10k node 的生產集群中,Controller 中存儲著近百萬的對象,從 API Server 獲取這些對象并反序列化的開銷是無法忽略的,重啟 Controller 恢復時可能需要花費幾分鐘才能完成這項工作,這對于阿里巴巴規模的企業來說是不可接受的。為了減小組件升級對系統可用性的影響,我們需要盡量的減小 controller 單次升級對系統的中斷時間,這里通過如下圖所示的方案來解決這個問題:
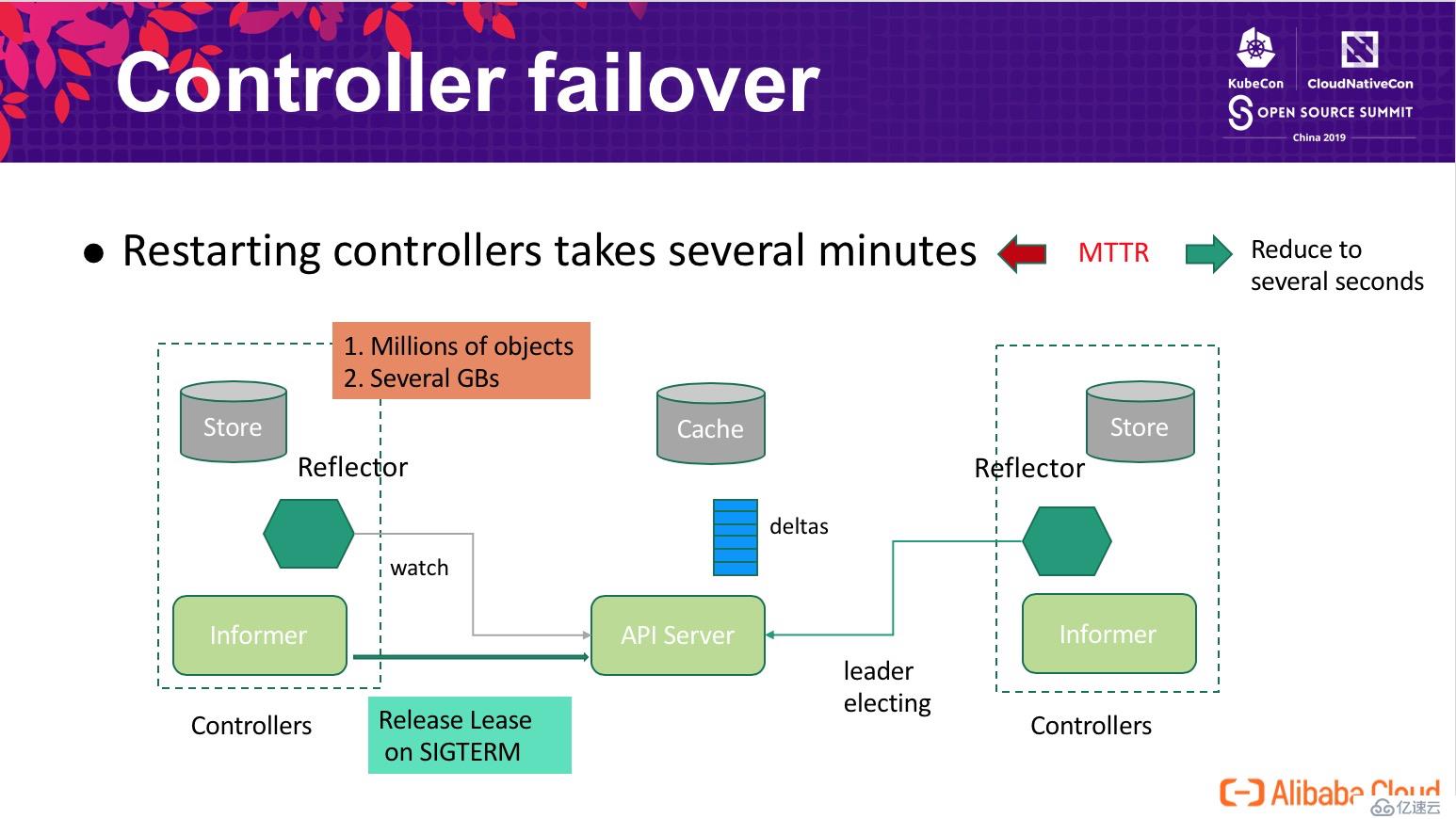
通過這個方案,我們將 controller 中斷時間降低到秒級別(升級時 < 2s),即使在異常宕機時,備僅需等待 leader lease 的過期(默認 15s),無需要花費幾分鐘重新同步數據。通過這個增強,顯著的降低了 controller MTTR,同時降低了 controller 恢復時對 API Server 的性能沖擊。該方案同樣適用于 scheduler。
由于歷史原因,阿里巴巴的調度器采用了自研的架構,因時間的關系本次分享并未展開調度器部分的增強。這里僅分享兩個基本的思路,如下圖所示:
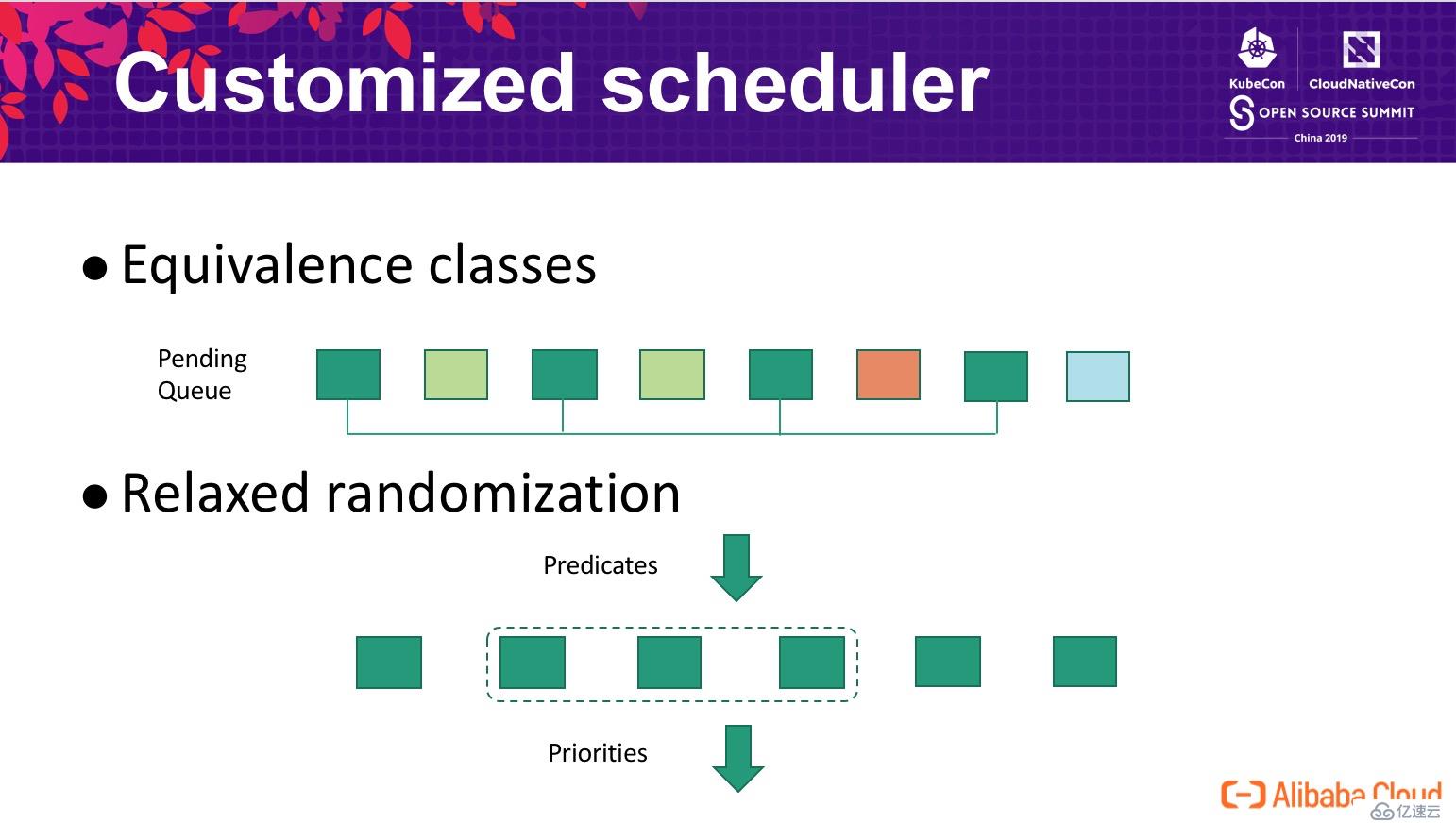
阿里巴巴通過一系列的增強與優化,成功將 Kubernetes 應用到生產環境并達到了單集群 10000 節點的超大規模,具體包括:
通過這一系列功能增強,阿里巴巴成功將內部最核心的業務運行在上萬節點的 Kubernetes 集群之上,并經歷了 2019 年天貓 618 大促的考驗。
作者簡介:
曾凡松(花名:逐靈),阿里云云原生應用平臺高級技術專家。
有豐富的分布式系統設計研發經驗。在集群資源調度這一領域,曾負責的自研調度系統管理了數十萬規模的節點,在集群資源調度、容器資源隔離、不同工作負載混部等方面有豐富的實踐經驗。當前主要負責 Kubernetes 在阿里內部的規模化落地,將 Kubernetes 應用于阿里內部的最核心電商業務,提高了應用發布效率及集群資源利用率,并穩定支撐了 2018 雙十一 及 2019 618 大促。
“ 阿里巴巴云原生微信公眾號(ID:Alicloudnative)關注微服務、Serverless、容器、Service Mesh 等技術領域、聚焦云原生流行技術趨勢、云原生大規模的落地實踐,做最懂云原生開發者的技術公眾號。”
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





