溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
作者 | 聲東 阿里云售后技術專家
文章來源:Docker,點擊查看原文。
以我的經驗來講,理解 Kubernetes 集群服務的概念,是比較不容易的一件事情。尤其是當我們基于似是而非的理解,去排查服務相關問題的時候,會非常不順利。
這體現在,對于新手來說,ping 不通服務的 IP 地址這樣基礎的問題,都很難理解;而就算對經驗很豐富的工程師來說,看懂服務相關的 iptables 配置,也是有相當的挑戰的。
今天這邊文章,我來深入解釋一下 Kubernetes 集群服務的原理與實現,便于大家理解。
概念上來講,Kubernetes 集群的服務,其實就是負載均衡、或反向代理。這跟阿里云的負載均衡產品,有很多類似的地方。和負載均衡一樣,服務有它的 IP 地址以及前端端口;服務后邊會掛載多個容器組 Pod 作為其“后端服務器”,這些“后端服務器”有自己的 IP 以及監聽端口。
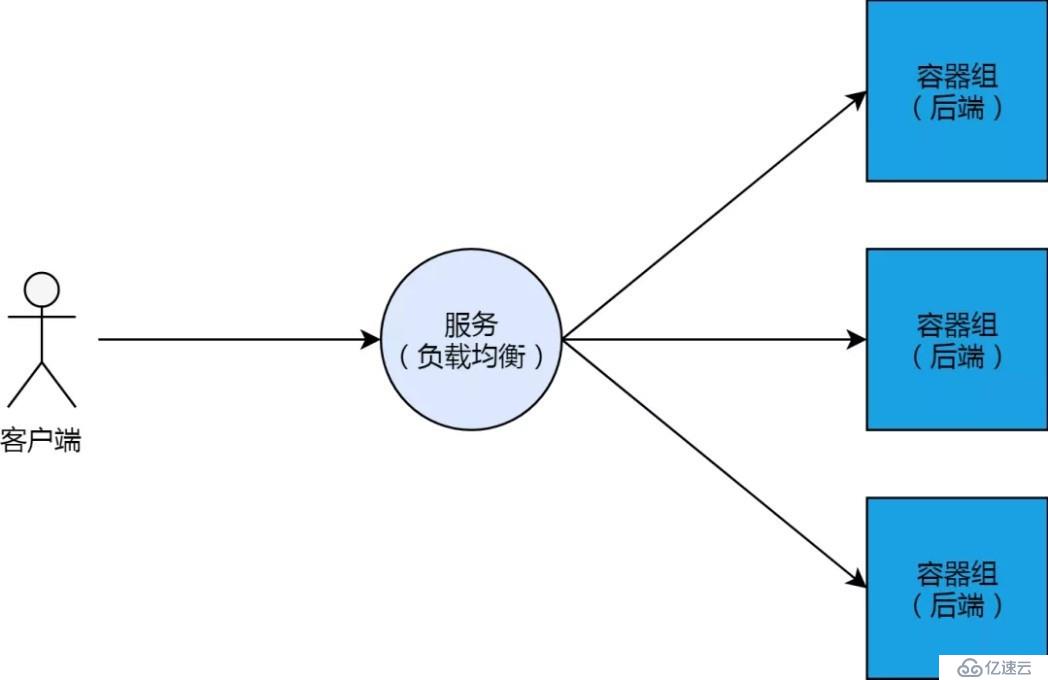
當這樣的負載均衡和后端的架構,與 Kubernetes 集群結合的時候,我們可以想到的最直觀的實現方式,就是集群中某一個節點專門做負載均衡(類似 LVS)的角色,而其他節點則用來負載后端容器組。
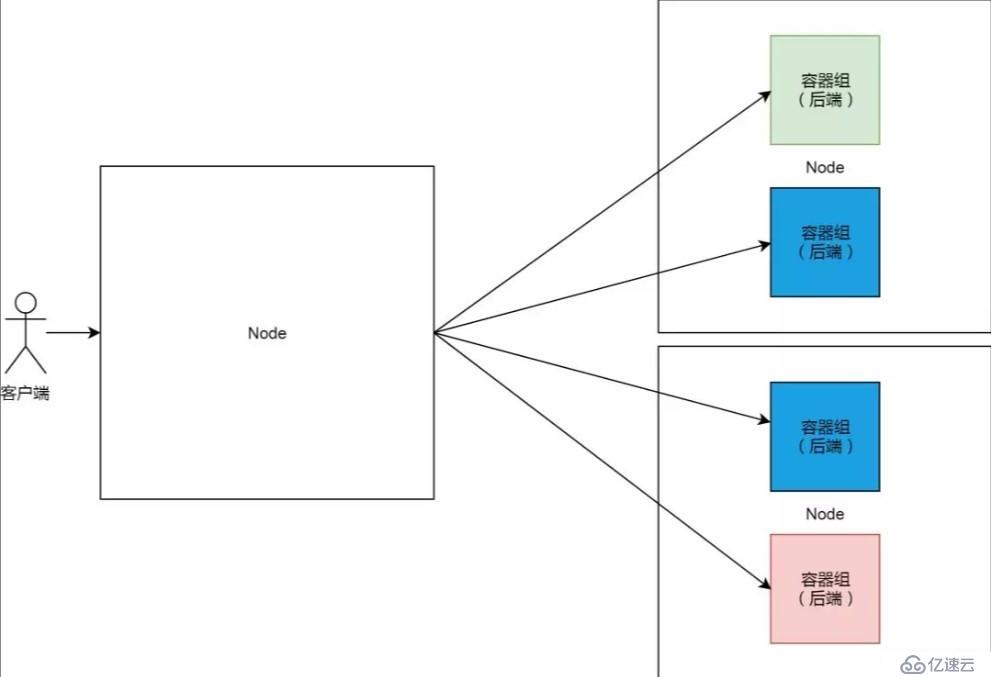
這樣的實現方法,有一個巨大的缺陷,就是單點問題。Kubernetes 集群是 Google 多年來自動化運維實踐的結晶,這樣的實現顯然與其智能運維的哲學相背離的。
邊車模式(Sidecar)是微服務領域的核心概念。邊車模式,換一句通俗一點的說法,就是自帶通信員。熟悉服務網格的同學肯定對這個很熟悉了。但是可能比較少人注意到,其實 Kubernetes 集群原始服務的實現,也是基于 Sidecar 模式的。
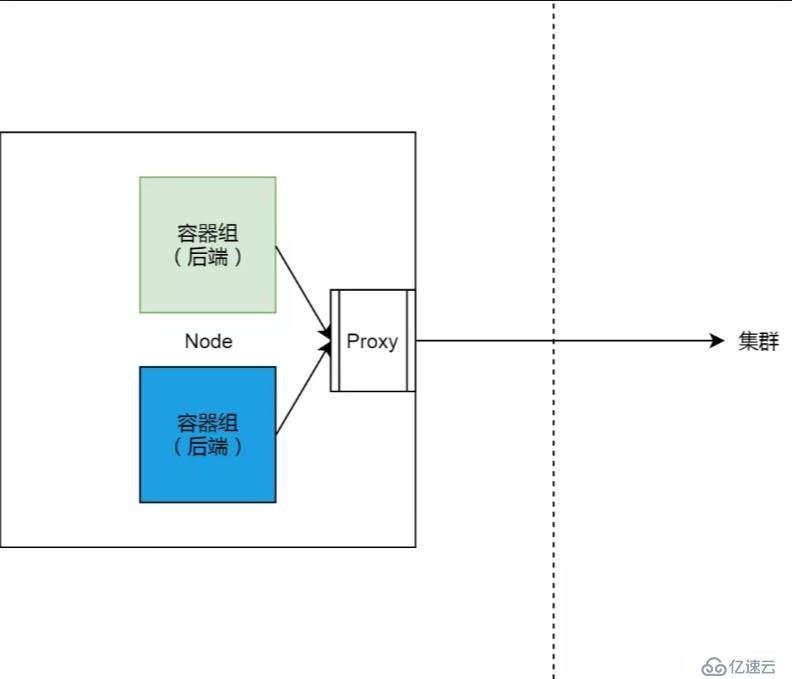
在 Kubernetes 集群中,服務的實現,實際上是為每一個集群節點上,部署了一個反向代理 Sidecar。而所有對集群服務的訪問,都會被節點上的反向代理轉換成對服務后端容器組的訪問。基本上來說,節點和這些 Sidecar 的關系如下圖所示。
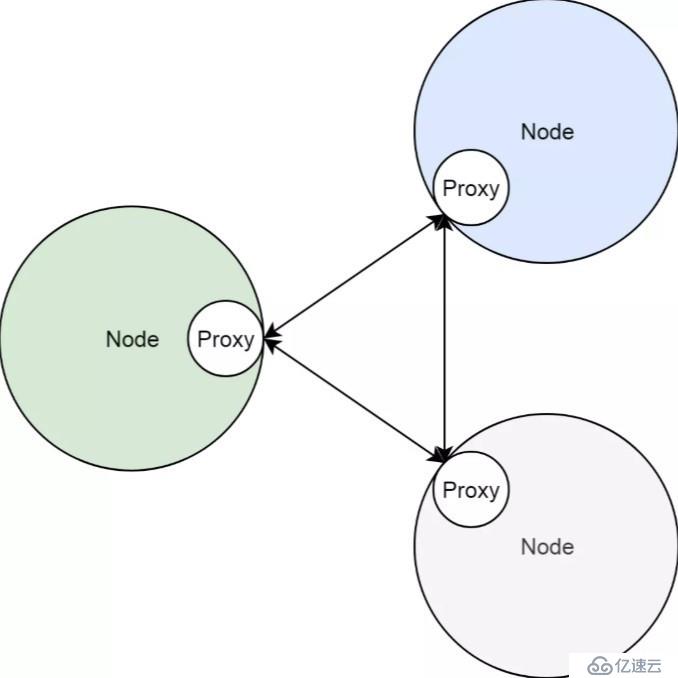
前邊兩節,我們看到了,Kubernetes 集群的服務,本質上是負載均衡,即反向代理;同時我們知道了,在實際實現中,這個反向代理,并不是部署在集群某一個節點上,而是作為集群節點的邊車,部署在每個節點上的。
在這里把服務照進反向代理這個現實的,是 Kubernetes 集群的一個控制器,即 kube-proxy。關于 Kubernetes 集群控制器的原理,請參考我另外一篇關于控制器的文章。簡單來說,kube-proxy 作為部署在集群節點上的控制器,它們通過集群 API Server 監聽著集群狀態變化。當有新的服務被創建的時候,kube-proxy 則會把集群服務的狀態、屬性,翻譯成反向代理的配置。
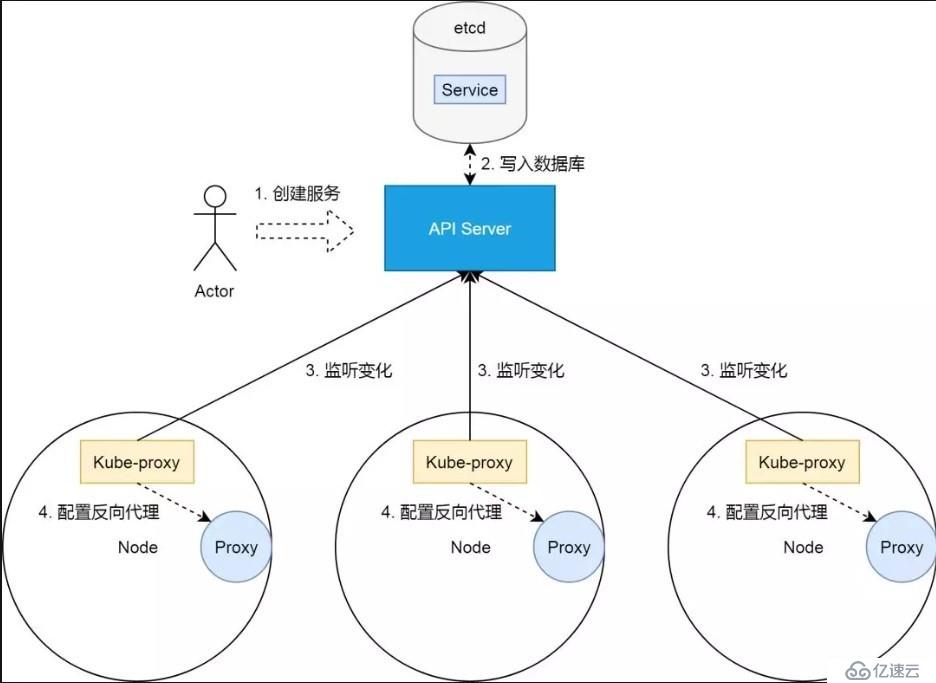
那剩下的問題,就是反向代理,即上圖中 Proxy 的實現。
Kubernetes 集群節點實現服務反向代理的方法,目前主要有三種,即 userspace、iptables 以及 IPVS。今天我們只深入分析 iptables 的方式,底層網絡基于阿里云 Flannel 集群網絡。
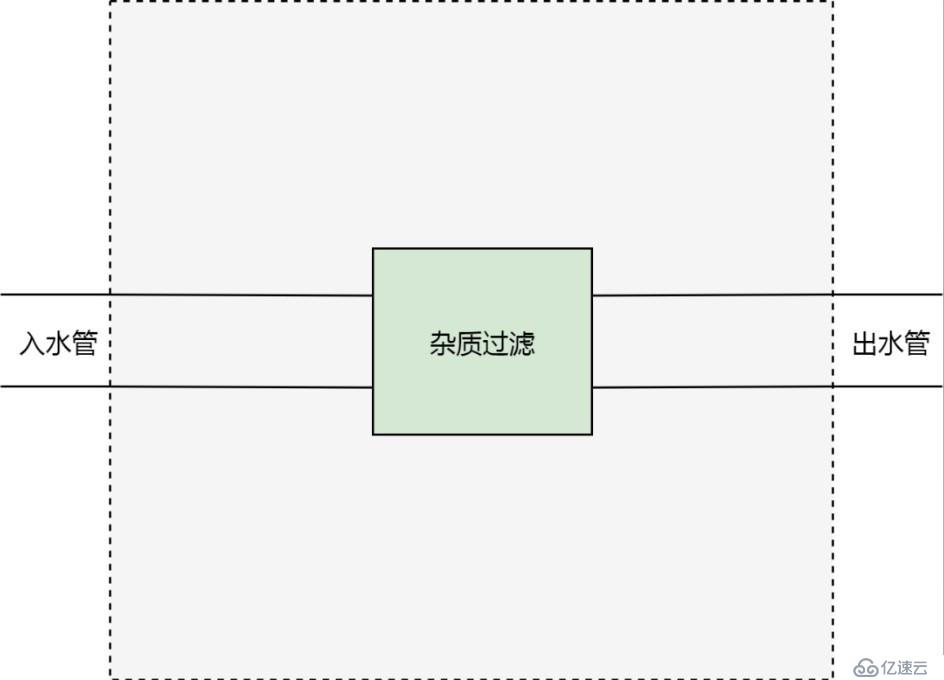
現在,我們來設想一種場景。我們有一個屋子。這個屋子有一個入水管和出水管。從入水管進入的水,是不能直接飲用的,因為有雜質。而我們期望,從出水管流出的水,可以直接飲用。為了達到目的,我們切開水管,在中間加一個雜質過濾器。
過了幾天,我們的需求變了,我們不止要求從屋子里流出來的水可以直接飲用,我們還希望水是熱水。所以我們不得不再在水管上增加一個切口,然后增加一個加熱器。
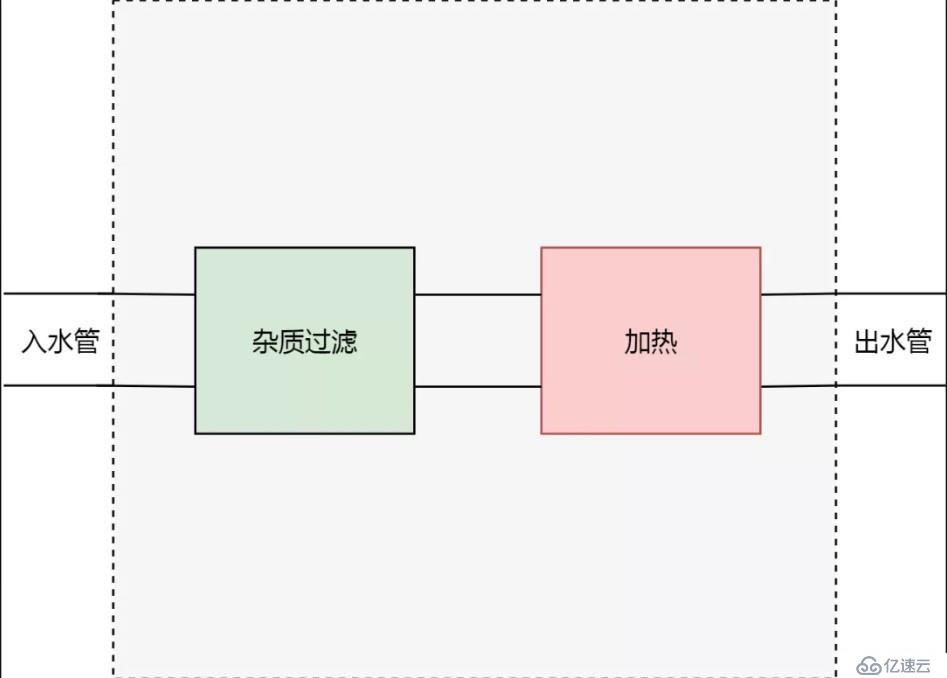
很明顯,這種切開水管,增加新功能的方式是很丑陋的。因為需求可能隨時會變,我們甚至很難保證,在經過一年半載之后,這跟水管還能找得到可以被切開的地方。
所以我們需要重新設計。首先我們不能隨便切開水管,所以我們要把水管的切口固定下來。以上邊的場景為例,我們確保水管只能有一個切口位置。其次,我們抽象出對水的兩種處理方式:物理變化和化學變化。
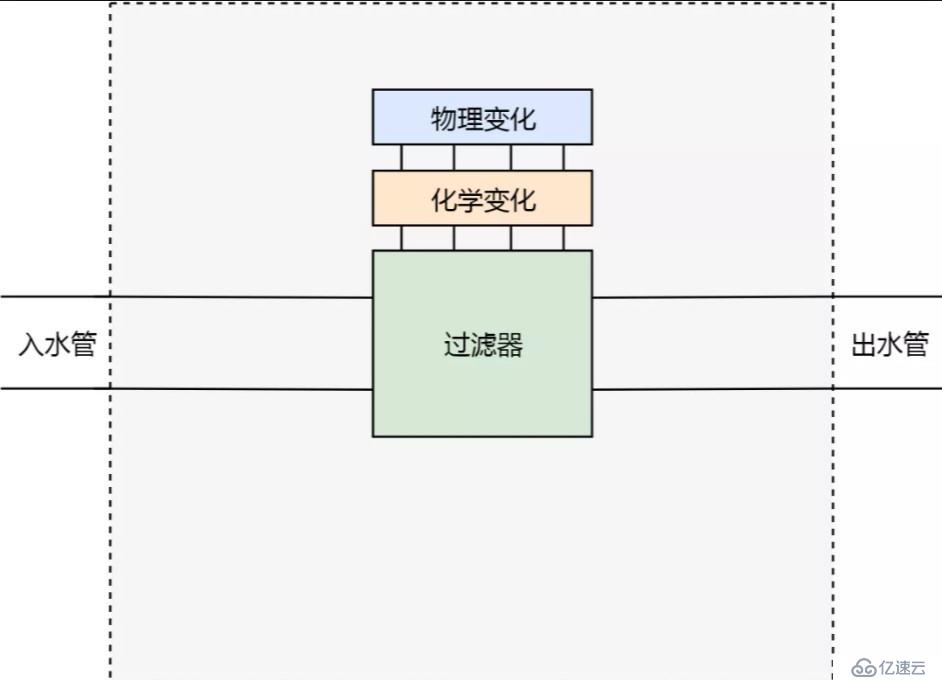
基于以上的設計,如果我們需要過濾雜質,就可以在化學變化這個功能模塊里增加一條過濾雜質的規則;如果我們需要增加溫度的話,就可以在物理變化這個功能模塊里增加一條加熱的規則。
以上的過濾器框架,顯然比切水管的方式,要優秀很多。設計這個框架,我們主要做了兩件事情,一個是固定水管切口位置,另外一個是抽象出兩種水處理方式。
理解這兩件事情之后,我們可以來看下 iptables,或者更準確的說法,netfilter 的工作原理。netfilter 實際上就是一個過濾器框架。netfilter 在網絡包收發及路由的管道上,一共切了 5 個口,分別是 PREROUTING,FORWARD,POSTROUTING,INPUT 以及 OUTPUT;同時 netfilter 定義了包括 nat、filter 在內的若干個網絡包處理方式。
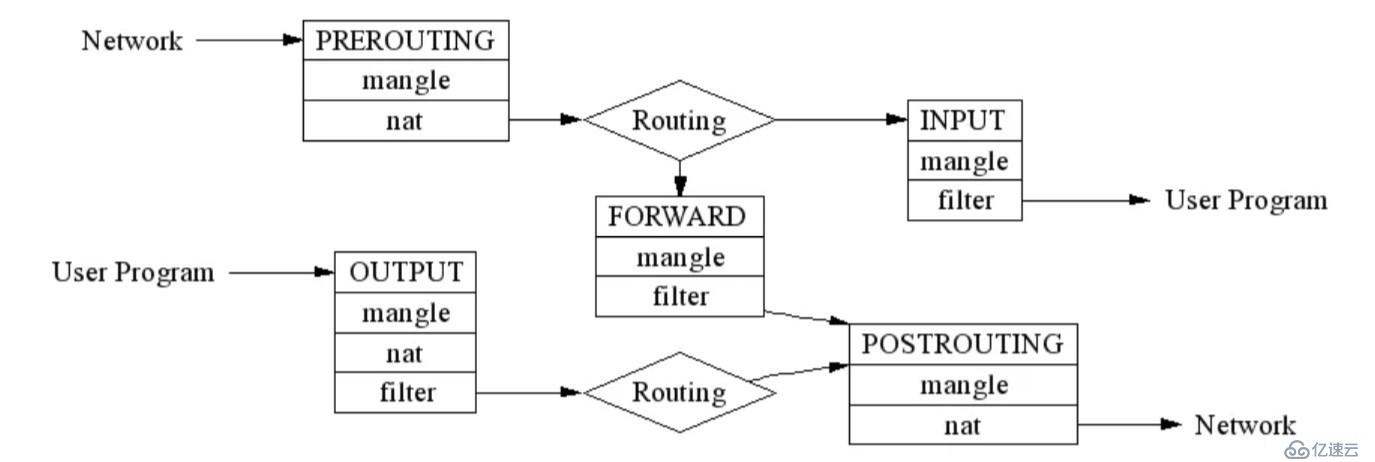
需要注意的是,routing 和 forwarding 很大程度上增加了以上 netfilter 的復雜程度,如果我們不考慮 routing 和 forwarding,那么 netfilter 會變得跟我們的水質過濾器框架一樣簡單。
現在我們看一下 Kubernetes 集群節點的網絡全貌。橫向來看,節點上的網絡環境,被分割成不同的網絡命名空間,包括主機網絡命名空間和 Pod 網絡命名空間;縱向來看,每個網絡命名空間包括完整的網絡棧,從應用到協議棧,再到網絡設備。
在網絡設備這一層,我們通過 cni0 虛擬網橋,組建出系統內部的一個虛擬局域網。Pod 網絡通過 veth 對連接到這個虛擬局域網內。cni0 虛擬局域網通過主機路由以及網口 eth0 與外部通信。
在網絡協議棧這一層,我們可以通過編程 netfilter 過濾器框架,來實現集群節點的反向代理。
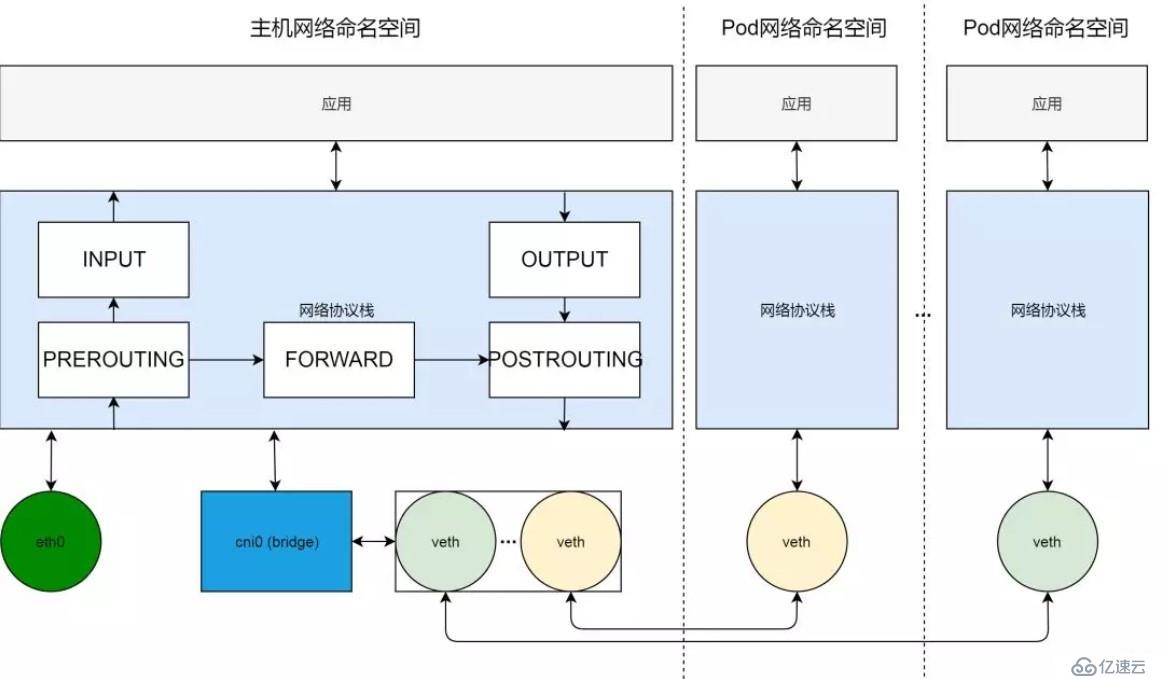
實現反向代理,歸根結底,就是做 DNAT,即把發送給集群服務 IP 和端口的數據包,修改成發給具體容器組的 IP 和端口。
參考 netfilter 過濾器框架的圖,我們知道,在 netfilter 里,可以通過在 PREROUTING,OUTPUT 以及 POSTROUGING 三個位置加入 NAT 規則,來改變數據包的源地址或目的地址。
因為這里需要做的是 DNAT,即改變目的地址,這樣的修改,必須在路由(ROUTING)之前發生以保證數據包可以被路由正確處理,所以實現反向代理的規則,需要被加到 PREROUTING 和 OUTPUT 兩個位置。
其中,PREOURTING 的規則,用來處理從 Pod 訪問服務的流量。數據包從 Pod 網絡 veth 發送到 cni0 之后,進入主機協議棧,首先會經過 netfilter PREROUTING 來做處理,所以發給服務的數據包,會在這個位置做 DNAT。經過 DNAT 處理之后,數據包的目的地址變成另外一個 Pod 的地址,從而經過主機路由,轉發到 eth0,發送給正確的集群節點。
而添加在 OUTPUT 這個位置的 DNAT 規則,則用來處理從主機網絡發給服務的數據包,原理也是類似,即經過路由之前,修改目的地址,以方便路由轉發。
在過濾器框架一節,我們看到 netfilter 是一個過濾器框架。netfilter 在數據“管到”上切了 5 個口,分別在這 5 個口上,做一些數據包處理工作。雖然固定切口位置以及網絡包處理方式分類已經極大的優化了過濾器框架,但是有一個關鍵的問題,就是我們還是得在管道上做修改以滿足新的功能。換句話說,這個框架沒有做到管道和過濾功能兩者的徹底解耦。
為了實現管道和過濾功能兩者的解耦,netfilter 用了表這個概念。表就是 netfilter 的過濾中心,其核心功能是過濾方式的分類(表),以及每種過濾方式中,過濾規則的組織(鏈)。
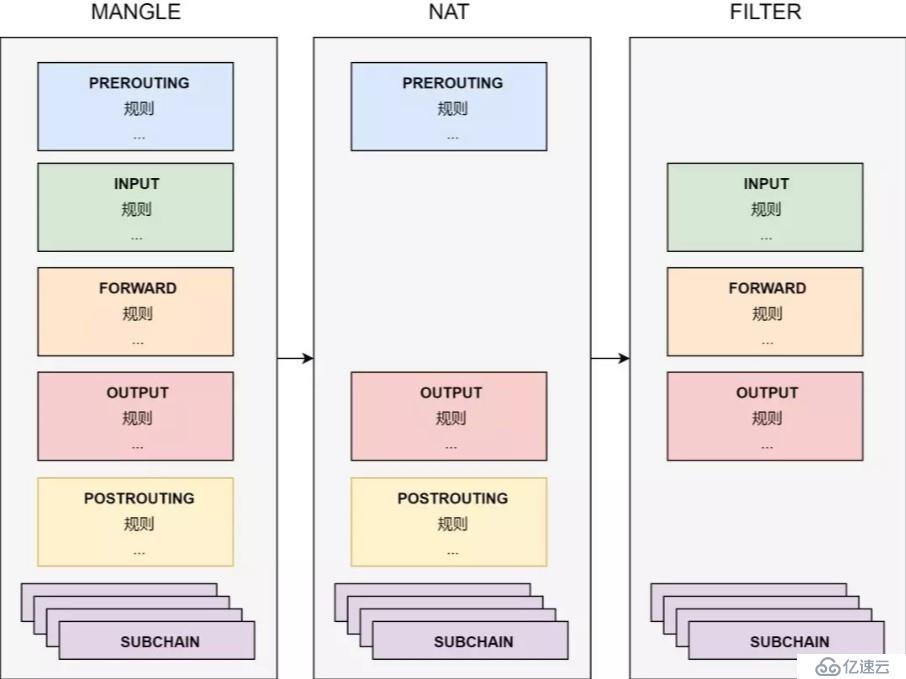
把過濾功能和管道解耦之后,所有對數據包的處理,都變成了對表的配置。而管道上的5個切口,僅僅變成了流量的出入口,負責把流量發送到過濾中心,并把處理之后的流量沿著管道繼續傳送下去。
如上圖,在表中,netfilter 把規則組織成為鏈。表中有針對每個管道切口的默認鏈,也有我們自己加入的自定義鏈。默認鏈是數據的入口,默認鏈可以通過跳轉到自定義鏈來完成一些復雜的功能。這里允許增加自定義鏈的好處是顯然的。為了完成一個復雜過濾功能,比如實現 Kubernetes 集群節點的反向代理,我們可以使用自定義鏈來模塊化我們規則。
集群服務的反向代理,實際上就是利用自定義鏈,模塊化地實現了數據包的 DNAT 轉換。KUBE-SERVICE 是整個反向代理的入口鏈,其對應所有服務的總入口;KUBE-SVC-XXXX 鏈是具體某一個服務的入口鏈,KUBE-SERVICE 鏈會根據服務 IP,跳轉到具體服務的 KUBE-SVC-XXXX 鏈;而 KUBE-SEP-XXXX 鏈代表著某一個具體 Pod 的地址和端口,即 endpoint,具體服務鏈 KUBE-SVC-XXXX 會以一定算法(一般是隨機),跳轉到 endpoint 鏈。
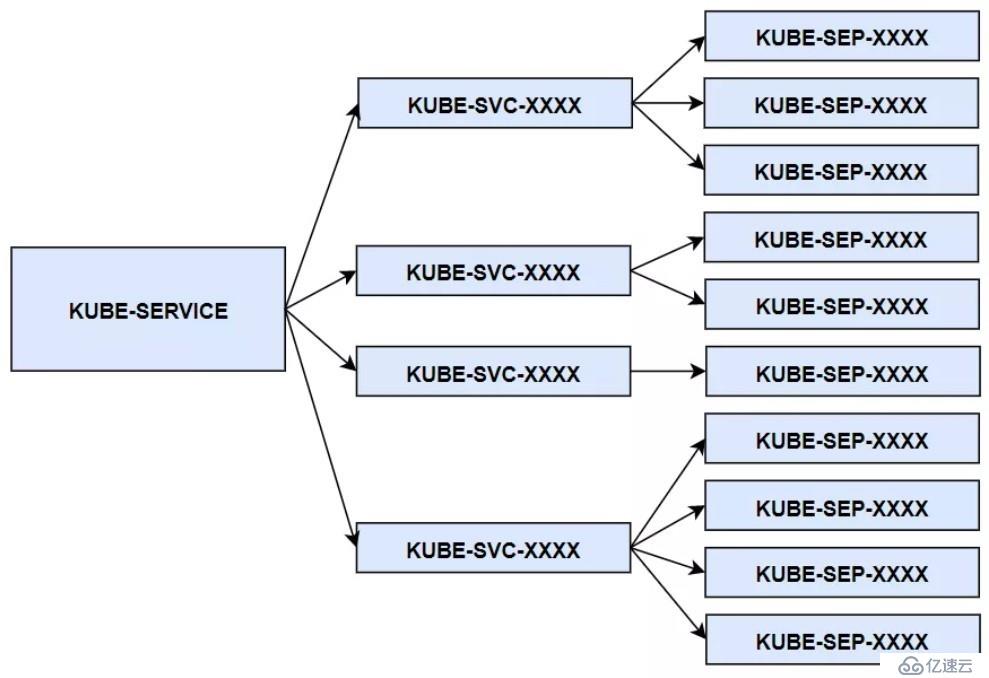
而如前文中提到的,因為這里需要做的是 DNAT,即改變目的地址,這樣的修改,必須在路由之前發生以保證數據包可以被路由正確處理。所以 KUBE-SERVICE 會被 PREROUTING 和 OUTPUT 兩個默認鏈所調用。
通過這篇文章,大家應該對 Kubernetes 集群服務的概念以及實現,有了更深層次的認識。我們基本上需要把握三個要點:
原文鏈接:https://yq.aliyun.com/articles/710873
“ 阿里巴巴云原生微信公眾號(ID:Alicloudnative)關注微服務、Serverless、容器、Service Mesh等技術領域、聚焦云原生流行技術趨勢、云原生大規模的落地實踐,做最懂云原生開發者的技術公眾號。”
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





