溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章將為大家詳細講解有關PyTorch: Softmax多分類是什么,小編覺得挺實用的,因此分享給大家做個參考,希望大家閱讀完這篇文章后可以有所收獲。
多分類一種比較常用的做法是在最后一層加softmax歸一化,值最大的維度所對應的位置則作為該樣本對應的類。本文采用PyTorch框架,選用經典圖像數據集mnist學習一波多分類。
MNIST數據集
MNIST 數據集(手寫數字數據集)來自美國國家標準與技術研究所, National Institute of Standards and Technology (NIST). 訓練集 (training set) 由來自 250 個不同人手寫的數字構成, 其中 50% 是高中學生, 50% 來自人口普查局 (the Census Bureau) 的工作人員. 測試集(test set) 也是同樣比例的手寫數字數據。MNIST數據集下載地址:http://yann.lecun.com/exdb/mnist/。手寫數字的MNIST數據庫包括60,000個的訓練集樣本,以及10,000個測試集樣本。

其中:
train-images-idx3-ubyte.gz (訓練數據集圖片)
train-labels-idx1-ubyte.gz (訓練數據集標記類別)
t10k-images-idx3-ubyte.gz: (測試數據集)
t10k-labels-idx1-ubyte.gz(測試數據集標記類別)

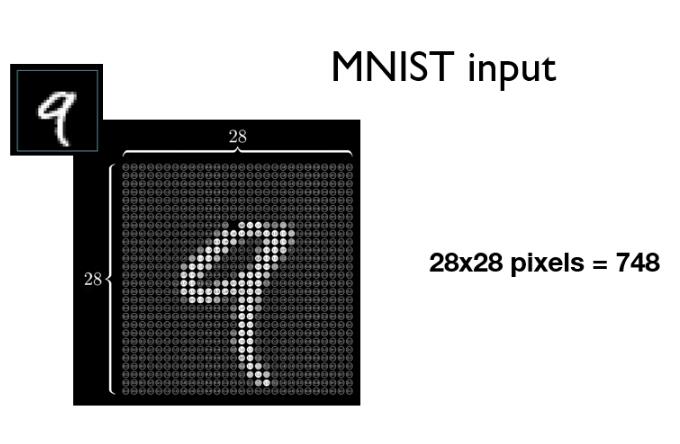
MNIST數據集是經典圖像數據集,包括10個類別(0到9)。每一張圖片拉成向量表示,如下圖784維向量作為第一層輸入特征。
Softmax分類
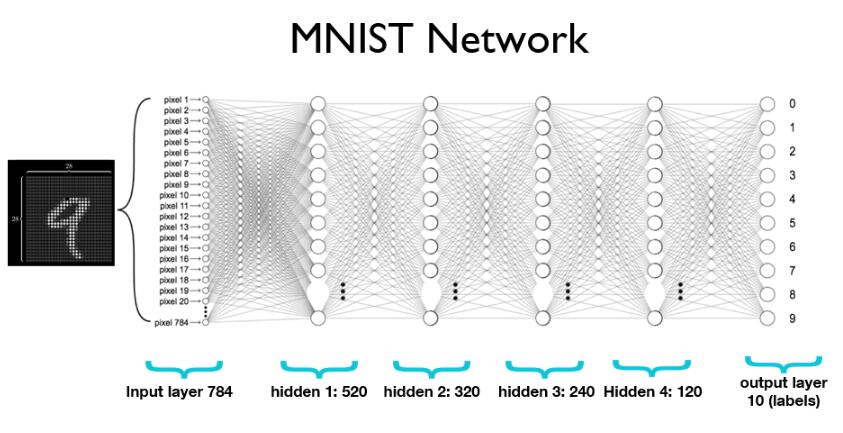
softmax函數的本質就是將一個K 維的任意實數向量壓縮(映射)成另一個K維的實數向量,其中向量中的每個元素取值都介于(0,1)之間,并且壓縮后的K個值相加等于1(變成了概率分布)。在選用Softmax做多分類時,可以根據值的大小來進行多分類的任務,如取權重最大的一維。softmax介紹和公式網上很多,這里不介紹了。下面使用Pytorch定義一個多層網絡(4個隱藏層,最后一層softmax概率歸一化),輸出層為10正好對應10類。
PyTorch實戰
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
from torch.autograd import Variable
# Training settings
batch_size = 64
# MNIST Dataset
train_dataset = datasets.MNIST(root='./mnist_data/',
train=True,
transform=transforms.ToTensor(),
download=True)
test_dataset = datasets.MNIST(root='./mnist_data/',
train=False,
transform=transforms.ToTensor())
# Data Loader (Input Pipeline)
train_loader = torch.utils.data.DataLoader(dataset=train_dataset,
batch_size=batch_size,
shuffle=True)
test_loader = torch.utils.data.DataLoader(dataset=test_dataset,
batch_size=batch_size,
shuffle=False)
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.l1 = nn.Linear(784, 520)
self.l2 = nn.Linear(520, 320)
self.l3 = nn.Linear(320, 240)
self.l4 = nn.Linear(240, 120)
self.l5 = nn.Linear(120, 10)
def forward(self, x):
# Flatten the data (n, 1, 28, 28) --> (n, 784)
x = x.view(-1, 784)
x = F.relu(self.l1(x))
x = F.relu(self.l2(x))
x = F.relu(self.l3(x))
x = F.relu(self.l4(x))
return F.log_softmax(self.l5(x), dim=1)
#return self.l5(x)
model = Net()
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.5)
def train(epoch):
# 每次輸入barch_idx個數據
for batch_idx, (data, target) in enumerate(train_loader):
data, target = Variable(data), Variable(target)
optimizer.zero_grad()
output = model(data)
# loss
loss = F.nll_loss(output, target)
loss.backward()
# update
optimizer.step()
if batch_idx % 200 == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
epoch, batch_idx * len(data), len(train_loader.dataset),
100. * batch_idx / len(train_loader), loss.data[0]))
def test():
test_loss = 0
correct = 0
# 測試集
for data, target in test_loader:
data, target = Variable(data, volatile=True), Variable(target)
output = model(data)
# sum up batch loss
test_loss += F.nll_loss(output, target).data[0]
# get the index of the max
pred = output.data.max(1, keepdim=True)[1]
correct += pred.eq(target.data.view_as(pred)).cpu().sum()
test_loss /= len(test_loader.dataset)
print('\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(
test_loss, correct, len(test_loader.dataset),
100. * correct / len(test_loader.dataset)))
for epoch in range(1,6):
train(epoch)
test()
輸出結果:
Train Epoch: 1 [0/60000 (0%)] Loss: 2.292192
Train Epoch: 1 [12800/60000 (21%)] Loss: 2.289466
Train Epoch: 1 [25600/60000 (43%)] Loss: 2.294221
Train Epoch: 1 [38400/60000 (64%)] Loss: 2.169656
Train Epoch: 1 [51200/60000 (85%)] Loss: 1.561276
Test set: Average loss: 0.0163, Accuracy: 6698/10000 (67%)
Train Epoch: 2 [0/60000 (0%)] Loss: 0.993218
Train Epoch: 2 [12800/60000 (21%)] Loss: 0.859608
Train Epoch: 2 [25600/60000 (43%)] Loss: 0.499748
Train Epoch: 2 [38400/60000 (64%)] Loss: 0.422055
Train Epoch: 2 [51200/60000 (85%)] Loss: 0.413933
Test set: Average loss: 0.0065, Accuracy: 8797/10000 (88%)
Train Epoch: 3 [0/60000 (0%)] Loss: 0.465154
Train Epoch: 3 [12800/60000 (21%)] Loss: 0.321842
Train Epoch: 3 [25600/60000 (43%)] Loss: 0.187147
Train Epoch: 3 [38400/60000 (64%)] Loss: 0.469552
Train Epoch: 3 [51200/60000 (85%)] Loss: 0.270332
Test set: Average loss: 0.0045, Accuracy: 9137/10000 (91%)
Train Epoch: 4 [0/60000 (0%)] Loss: 0.197497
Train Epoch: 4 [12800/60000 (21%)] Loss: 0.234830
Train Epoch: 4 [25600/60000 (43%)] Loss: 0.260302
Train Epoch: 4 [38400/60000 (64%)] Loss: 0.219375
Train Epoch: 4 [51200/60000 (85%)] Loss: 0.292754
Test set: Average loss: 0.0037, Accuracy: 9277/10000 (93%)
Train Epoch: 5 [0/60000 (0%)] Loss: 0.183354
Train Epoch: 5 [12800/60000 (21%)] Loss: 0.207930
Train Epoch: 5 [25600/60000 (43%)] Loss: 0.138435
Train Epoch: 5 [38400/60000 (64%)] Loss: 0.120214
Train Epoch: 5 [51200/60000 (85%)] Loss: 0.266199
Test set: Average loss: 0.0026, Accuracy: 9506/10000 (95%)
Process finished with exit code 0隨著訓練迭代次數的增加,測試集的精確度還是有很大提高的。并且當迭代次數為5時,使用這種簡單的網絡可以達到95%的精確度。
關于PyTorch: Softmax多分類是什么就分享到這里了,希望以上內容可以對大家有一定的幫助,可以學到更多知識。如果覺得文章不錯,可以把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





